
- 1【转】 数学建模竞赛的准备、技巧、选题、写作等各方面得总结_数学建模只写了6页少不少
- 2数据安全,中小微企业的刚需
- 3FPGA之串口收发字符串控制HMI串口屏之(一)——发送模块_fpga串口收发字符串控制hmi
- 4第二届中国生成式 AI 创新应用挑战赛号角吹响,来中国峰会现场一起为梦想加速!...
- 5STM32驱动步进电机;步进电机的驱动;步进电机驱动板的使用;STM32输出不同频率的波形;_步进电机ref current
- 6第九周:AIPM面试准备
- 7Web3 游戏周报(4.14-4.20)
- 8Pytorch 的数据处理 学习笔记_pytorch处理图片数据集
- 9当虚拟机报错:以独占方式锁定此配置文件失败,另一个正在运行的VMware进程可能正在使用配置文件
- 10在Linux上安装Nginx + Nginx 的基本配置_nginx 添加 mjs文件类型
ALOHA论文翻译:Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
赞
踩
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
学习用低成本硬件进行精细双手操作
这是ALOHA 翻译,别搞混了。
Mobile ALOHA 论文翻译,请移步:Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
文章目录
- Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
- 学习用低成本硬件进行精细双手操作

图1:ALOHA:一种用于双手远程操作的低成本开源硬件系统。整个系统使用现成的机器人和3D打印组件,总成本不到20,000美元。左图:用户通过反向驱动领导机器人进行远程操作,从而使跟随机器人模仿运动。右图:ALOHA能够执行精准、接触丰富且动态的任务。我们展示了远程操作和学习技能的示例。
Abstract
摘要
Abstract—Fine manipulation tasks, such as threading cable ties or slotting a battery, are notoriously difficult for robots because they require precision, careful coordination of contact forces, and closed-loop visual feedback. Performing these tasks typically requires high-end robots, accurate sensors, or careful calibration, which can be expensive and difficult to set up. Can learning enable low-cost and imprecise hardware to perform these fine manipulation tasks? We present a low-cost system that performs end-to-end imitation learning directly from real demonstrations, collected with a custom teleoperation interface. Imitation learning, however, presents its own challenges, particularly in highprecision domains: errors in the policy can compound over time, and human demonstrations can be non-stationary. To address these challenges, we develop a simple yet novel algorithm, Action Chunking with Transformers (ACT), which learns a generative model over action sequences. ACT allows the robot to learn 6 difficult tasks in the real world, such as opening a translucent condiment cup and slotting a battery with 80-90% success, with only 10 minutes worth of demonstrations. Project website: tonyzhaozh.github.io/aloha
精细操纵任务,如穿线束扎带或插入电池,对于机器人而言常常具有挑战性,因为它们需要精确性、对接触力的仔细协调以及闭环视觉反馈。执行这些任务通常需要高端机器人、准确的传感器或精细的校准,这可能昂贵且难以设置。学习是否能让低成本和不精确的硬件执行这些精细操纵任务?我们提出了一个低成本系统,直接从真实演示中进行端到端模仿学习,这些演示是使用定制的远程操作界面收集的。然而,模仿学习在高精度领域中也面临着挑战:策略中的错误可能随时间而累积,人类演示可能是非静态的。为了解决这些问题,我们开发了一种简单而新颖的算法,称为Action Chunking with Transformers(ACT),它在动作序列上学习生成模型。ACT使机器人能够在真实世界中学习6项困难任务,例如打开半透明的调味品杯和插入电池,成功率达到80-90%,仅需10分钟的演示。项目网站:tonyzhaozh.github.io/aloha。
I. INTRODUCTION
I. 引言
Fine manipulation tasks involve precise, closed-loop feedback and require high degrees of hand-eye coordination to adjust and re-plan in response to changes in the environment. Examples of such manipulation tasks include opening the lid of a condiment cup or slotting a battery, which involve delicate operations such as pinching, prying, and tearing rather than broad-stroke motions such as picking and placing. Take opening the lid of a condiment cup in Figure 1 as an example, where the cup is initialized upright on the table: the right gripper needs to first tip it over, and nudge it into the opened left gripper. Then the left gripper closes gently and lifts the cup off the table. Next, one of the right fingers approaches the cup from below and pries the lid open. Each of these steps requires high precision, delicate hand-eye coordination, and rich contact. Millimeters of error would lead to task failure.
精细操纵任务涉及精确的闭环反馈,需要高度的手眼协调能力,以便根据环境的变化进行调整和重新规划。此类操纵任务的示例包括打开调味品杯的盖子或插入电池,涉及到精细的操作,如捏、撬和撕裂,而不是像拾取和放置这样的大范围运动。以图1中打开调味品杯盖子为例,杯子首先在桌子上直立初始化:右抓手需要先将其倾斜,然后轻推到已打开的左抓手中。接着,左抓手轻轻合上并将杯子从桌子上抬起。然后,右手指之一从下方接近杯子,撬开盖子。这些步骤都需要高度的精确性、精细的手眼协调和丰富的接触。毫米级的误差将导致任务失败。
Existing systems for fine manipulation use expensive robots and high-end sensors for precise state estimation [29, 60, 32, 41]. In this work, we seek to develop a low-cost system for fine manipulation that is, in contrast, accessible and reproducible. However, low-cost hardware is inevitably less precise than high-end platforms, making the sensing and planning challenge more pronounced. One promising direction to resolve this is to incorporate learning into the system. Humans also do not have industrial-grade proprioception [71], and yet we are able to perform delicate tasks by learning from closed-loop visual feedback and actively compensating for errors. In our system, we therefore train an end-to-end policy that directly maps RGB images from commodity web cameras to the actions. This pixel-to-action formulation is particularly suitable for fine manipulation, because fine manipulation often involves objects with complex physical properties, such that learning the manipulation policy is much simpler than modeling the whole environment. Take the condiment cup example: modeling the contact when nudging the cup, and also the deformation when prying open the lid involves complex physics on a large number of degrees of freedom. Designing a model accurate enough for planning would require significant research and task specific engineering efforts. In contrast, the policy of nudging and opening the cup is much simpler, since a closed-loop policy can react to different positions of the cup and lid rather than precisely anticipating how it will move in advance.
现有的精细操纵系统使用昂贵的机器人和高端传感器进行精确的状态估计[29, 60, 32, 41]。在这项工作中,我们致力于开发一种低成本的精细操纵系统,与之相反,该系统既易于获取又可复制。然而,低成本硬件不可避免地比高端平台不够精确,这使得感知和规划的挑战更加明显。解决这个问题的一个有前途的方向是将学习纳入系统。人类也没有工业级的本体感知[71],但我们能够通过从闭环视觉反馈中学习并积极补偿错误来执行精细任务。因此,在我们的系统中,我们训练一个端到端策略,直接将来自通用网络摄像头的RGB图像映射到动作上。这种从像素到动作的表述特别适用于精细操纵,因为精细操纵通常涉及具有复杂物理特性的对象,学习操纵策略比对整个环境建模要简单得多。以调味品杯为例:在轻推杯子时建模接触,以及在撬开盖子时建模变形,涉及大量自由度上的复杂物理。设计一个足够准确的用于规划的模型将需要大量的研究和任务特定的工程工作。相比之下,轻推和打开杯子的策略要简单得多,因为闭环策略可以对杯子和盖子的不同位置做出反应,而不是精确地预测它们将如何提前移动。
Training an end-to-end policy, however, presents its own challenges. The performance of the policy depends heavily on the training data distribution, and in the case of fine manipulation, high-quality human demonstrations can provide tremendous value by allowing the system to learn from human dexterity. We thus build a low-cost yet dexterous teleoperation system for data collection, and a novel imitation learning algorithm that learns effectively from the demonstrations. We overview each component in the following two paragraphs.
然而,训练端到端策略也面临着自己的挑战。策略的性能在很大程度上取决于训练数据的分布,在精细操纵的情况下,高质量的人类演示可以通过让系统从人类的灵巧中学习提供巨大的价值。因此,我们建立了一个低成本但灵巧的远程操作系统进行数据收集,并采用一种新颖的模仿学习算法,能够有效地从演示中学习。我们将在接下来的两段中概述每个组件。
Teleoperation system. We devise a teleoperation setup with two sets of low-cost, off-the-shelf robot arms. They are approximately scaled versions of each other, and we use jointspace mapping for teleoperation. We augment this setup with 3D printed components for easier backdriving, leading to a highly capable teleoperation system within a $20k budget. We showcase its capabilities in Figure 1, including teleoperation of precise tasks such as threading a zip tie, dynamic tasks such as juggling a ping pong ball, and contact-rich tasks such as assembling the chain in the NIST board #2 [4].
远程操作系统。 我们设计了一个远程操作设置,其中包括两组低成本的现成机器人手臂。它们大致是彼此的缩小版本,我们使用关节空间映射进行远程操作。我们通过3D打印组件来增强这个设置,使其更容易进行反向驱动,从而在20000美元的预算内建立了一个非常强大的远程操作系统。我们在图1中展示了其能力,包括精确任务的远程操作,如穿过拉链扎带,动态任务,如抛接乒乓球,以及接触丰富的任务,如在NIST板 #2 中组装链条。
Imitation learning algorithm. Tasks that require precision and visual feedback present a significant challenge for imitation learning, even with high-quality demonstrations. Small errors in the predicted action can incur large differences in the state, exacerbating the “compounding error” problem of imitation learning [47, 64, 29]. To tackle this, we take inspiration from action chunking, a concept in psychology that describes how sequences of actions are grouped together as a chunk, and executed as one unit [35]. In our case, the policy predicts the target joint positions for the next k timesteps, rather than just one step at a time. This reduces the effective horizon of the task by k-fold, mitigating compounding errors. Predicting action sequences also helps tackle temporally correlated confounders [61], such as pauses in demonstrations that are hard to model with Markovian single-step policies. To further improve the smoothness of the policy, we propose temporal ensembling, which queries the policy more frequently and averages across the overlapping action chunks. We implement action chunking policy with Transformers [65], an architecture designed for sequence modeling, and train it as a conditional VAE (CVAE) [55, 33] to capture the variability in human data. We name our method Action Chunking with Transformers (ACT), and find that it significantly outperforms previous imitation learning algorithms on a range of simulated and real-world fine manipulation tasks.
模仿学习算法。 需要精确性和视觉反馈的任务即使在有高质量演示的情况下,也对模仿学习构成了重大挑战。在预测动作中出现的小错误可能导致状态出现较大差异,加剧了模仿学习中“复合误差”问题[47, 64, 29]。为了解决这个问题,我们受到了心理学中描述动作序列如何作为一个“块”分组并作为一个单元执行的“动作分块”概念的启发[35]。在我们的情况下,策略预测接下来k个时间步的目标关节位置,而不仅仅是一次预测一个步骤。这将任务的有效视野减少了k倍,有助于减轻复合错误。预测动作序列还有助于解决时间上相关的混淆因素[61],例如演示中的暂停,这在使用马尔可夫单步策略难以建模。为了进一步提高策略的平滑性,我们提出了时间集成,它更频繁地查询策略并对重叠的动作块进行平均。我们使用为序列建模设计的Transformers [65]实现了动作分块策略,并将其训练为有条件的变分自编码器(CVAE)[55, 33]以捕捉人类数据的变异性。我们将我们的方法命名为Action Chunking with Transformers (ACT),并发现在一系列模拟和真实世界的精细操纵任务中,它明显优于先前的模仿学习算法。
The key contribution of this paper is a low-cost system for learning fine manipulation, comprising a teleoperation system and a novel imitation learning algorithm. The teleoperation system, despite its low cost, enables tasks with high precision and rich contacts. The imitation learning algorithm, Action Chunking with Transformers (ACT), is capable of learning precise, close-loop behavior and drastically outperforms previous methods. The synergy between these two parts allows learning of 6 fine manipulation skills directly in the real-world, such as opening a translucent condiment cup and slotting a battery with 80-90% success, from only 10 minutes or 50 demonstration trajectories.
本文的主要贡献是一种用于学习精细操纵的低成本系统,包括一个远程操作系统和一种新颖的模仿学习算法。尽管远程操作系统成本低廉,但它能够执行高精度和接触丰富的任务。模仿学习算法,即Action Chunking with Transformers (ACT),能够学习精确的闭环行为,并在性能上远超过先前的方法。这两部分之间的协同作用使得能够直接在现实世界中学习6项精细操纵技能,例如成功率达到80-90%的打开半透明的调味品杯和插入电池,仅需10分钟或50次演示轨迹。
II. RELATED WORK
II. 相关工作
Imitation learning for robotic manipulation. Imitation learning allows a robot to directly learn from experts. Behavioral cloning (BC) [44] is one of the simplest imitation learning algorithms, casting imitation as supervised learning from observations to actions. Many works have then sought to improve BC, for example by incorporating history with various architectures [39, 49, 26, 7], using a different training objective [17, 42], and including regularization [46]. Other works emphasize the multi-task or few-shot aspect of imitation learning [14, 25, 11], leveraging language [51, 52, 26, 7], or exploiting the specific task structure [43, 68, 28, 52]. Scaling these imitation learning algorithms with more data has led to impressive systems that can generalize to new objects, instructions, or scenes [15, 26, 7, 32]. In this work, we focus on building an imitation learning system that is low-cost yet capable of performing delicate, fine manipulation tasks. We tackle this from both hardware and software, by building a high-performance teleoperation system, and a novel imitation learning algorithm that drastically improves previous methods on fine manipulation tasks.
机器人操纵的模仿学习。 模仿学习允许机器人直接从专家那里学习。行为克隆(BC)[44]是最简单的模仿学习算法之一,将模仿视为从观察到动作的监督学习过程。许多工作随后试图改进BC,例如通过使用不同的架构来纳入历史信息[39, 49, 26, 7],采用不同的训练目标[17, 42],以及引入正则化[46]。其他工作强调了模仿学习的多任务或少样本学习方面[14, 25, 11],利用语言[51, 52, 26, 7],或者利用特定任务结构[43, 68, 28, 52]。使用更多数据扩展这些模仿学习算法已经导致了令人印象深刻的系统,能够推广到新的对象、指令或场景[15, 26, 7, 32]。在这项工作中,我们专注于构建一个低成本的模仿学习系统,能够执行精细、精细的操纵任务。我们从硬件和软件两方面解决这个问题,通过构建一个高性能的远程操作系统,以及一种新颖的模仿学习算法,该算法在精细操纵任务上显著改进了先前的方法。
Addressing compounding errors. A major shortcoming of BC is compounding errors, where errors from previous timesteps accumulate and cause the robot to drift off of its training distribution, leading to hard-to-recover states [47, 64]. This problem is particularly prominent in the fine manipulation setting [29]. One way to mitigate compounding errors is to allow additional on-policy interactions and expert corrections, such as DAgger [47] and its variants [30, 40, 24]. However, expert annotation can be time-consuming and unnatural with a teleoperation interface [29]. One could also inject noise at demonstration collection time to obtain datasets with corrective behavior [36], but for fine manipulation, such noise injection can directly lead to task failure, reducing the dexterity of teleoperation system. To circumvent these issues, previous works generate synthetic correction data in an offline manner [16, 29, 70]. While they are limited to settings where lowdimensional states are available, or a specific type of task like grasping. Due to these limitations, we need to address the compounding error problem from a different angle, compatible with high-dimensional visual observations. We propose to reduce the effective horizon of tasks through action chunking, i.e., predicting an action sequence instead of a single action, and then ensemble across overlapping action chunks to produce trajectories that are both accurate and smooth.
解决复合误差。 BC的一个主要缺点是复合误差,即来自先前时间步的错误会累积并导致机器人偏离其训练分布,导致难以恢复的状态[47, 64]。在精细操纵的环境中,这个问题尤为突出[29]。减轻复合误差的一种方法是允许额外的在线交互和专家纠正,例如DAgger [47]及其变体[30, 40, 24]。然而,专家注释在使用远程操作界面时可能耗时且不自然[29]。也可以在演示收集时注入噪声以获得具有纠正行为的数据集[36],但对于精细操纵而言,这种噪声注入可能直接导致任务失败,降低了远程操作系统的灵巧性。为了绕过这些问题,先前的工作以离线方式生成合成的纠正数据[16, 29, 70]。尽管它们局限于具有低维状态或特定类型任务(如抓取)的情境。由于这些限制,我们需要从不同的角度解决复合误差问题,使其兼容高维度的视觉观察。我们提出通过动作分块来减小任务的有效视野,即预测一个动作序列而不是单个动作,然后在重叠的动作块上进行集成,以产生既准确又平滑的轨迹。
Bimanual manipulation. Bimanual manipulation has a long history in robotics, and has gained popularity with the lowering of hardware costs. Early works tackle bimanual manipulation from a classical control perspective, with known environment dynamics [54, 48], but designing such models can be timeconsuming, and they may not be accurate for objects with complex physical properties. More recently, learning has been incorporated into bimanual systems, such as reinforcement learning [9, 10], imitating human demonstrations [34, 37, 59, 67, 32], or learning to predict key points that chain together motor primitives [20, 19, 50]. Some of the works also focus on fine-grained manipulation tasks such as knot untying, cloth flattening, or even threading a needle [19, 18, 31], while using robots that are considerably more expensive, e.g. the da Vinci surgical robot or ABB YuMi. Our work turns to low-cost hardware, e.g. arms that cost around $5k each, and seeks to enable them to perform high-precision, closed-loop tasks. Our teleoperation setup is most similar to Kim et al. [32], which also uses joint-space mapping between the leader and follower robots. Unlike this previous system, we do not make use of special encoders, sensors, or machined components. We build our system with only off-the-shelf robots and a handful of 3D printed parts, allowing non-experts to assemble it in less than 2 hours.
双手操纵。 在机器人学中,双手操纵有着悠久的历史,并随着硬件成本的降低而变得越来越受欢迎。早期的工作从经典控制的角度处理双手操纵,考虑已知环境动态[54, 48],但设计这样的模型可能耗时,并且对于具有复杂物理性质的物体可能不准确。最近,学习已经被纳入到双手系统中,例如强化学习[9, 10],模仿人类演示[34, 37, 59, 67, 32],或学习预测将运动基元连接起来的关键点[20, 19, 50]。一些工作还专注于精细的操纵任务,如解开结、展平布料,甚至穿过针孔[19, 18, 31],同时使用显著更昂贵的机器人,例如 da Vinci 外科机器人或 ABB YuMi。我们的工作转向低成本硬件,例如每只手臂成本约为5000美元,并试图使它们能够执行高精度、闭环任务。我们的远程操作设置与 Kim 等人的工作[32]最为相似,也使用了领导机器人和跟随机器人之间的关节空间映射。与先前的系统不同,我们没有使用特殊的编码器、传感器或加工部件。我们的系统仅使用现成的机器人和少量3D打印部件构建,使非专业人员能够在不到2小时内组装它。
III. ALOHA: A LOW-COST OPEN-SOURCE HARDWARE SYSTEM FOR BIMANUAL TELEOPERATION
III. ALOHA: 一个用于双手远程操作的低成本开源硬件系统
We seek to develop an accessible and high-performance teleoperation system for fine manipulation. We summarize our design considerations into the following 5 principles.
1) Low-cost: The entire system should be within budget for most robotic labs, comparable to a single industrial arm.
2) Versatile: It can be applied to a wide range of fine manipulation tasks with real-world objects.
3) User-friendly: The system should be intuitive, reliable, and easy to use.
4) Repairable: The setup can be easily repaired by researchers, when it inevitably breaks.
5) Easy-to-build: It can be quickly assembled by researchers, with easy-to-source materials.
我们致力于开发一个易于获取且高性能的用于精细操纵的远程操作系统。我们将我们的设计考虑总结为以下5个原则。
1)低成本: 整个系统应在大多数机器人实验室的预算范围内,与单个工业机械臂相当。
2) 多功能: 可以应用于各种真实世界对象的精细操纵任务。
3) 用户友好: 系统应直观、可靠且易于使用。
4) 可修复: 当系统不可避免地发生故障时,研究人员可以轻松修复设置。
5) 易建造: 可以由研究人员快速组装,使用易获得的材料。
When choosing the robot to use, principles 1, 4, and 5 lead us to build a bimanual parallel-jaw grippers setup with two ViperX 6-DoF robot arms [1, 66]. We do not employ dexterous hands due to price and maintenance considerations. The ViperX arm used has a working payload of 750g and 1.5m span, with an accuracy of 5-8mm. The robot is modular and simple to repair: in the case of motor failure, the low-cost Dynamixel motors can be easily replaced. The robot can be purchased off-the-shelf for around $5600. The OEM fingers, however, are not versatile enough to handle fine manipulation tasks. We thus design our own 3D printed “see-through” fingers and fit it with gripping tape (Fig 3). This allows for good visibility when performing delicate operations, and robust grip even with thin plastic films
在选择要使用的机器人时,原则1、4和5引导我们构建了一个带有两个 ViperX 6-DoF 机械臂的双手并行爪夹设置[1, 66]。由于价格和维护方面的考虑,我们没有使用灵巧的手。所选用的 ViperX 机械臂的工作负载为750克,跨度为1.5米,精度为5-8毫米。该机器人是模块化的,易于维修:在发生电机故障的情况下,可以轻松更换低成本的 Dynamixel 电机。这款机器人可以在市场上以约5600美元的价格购买。然而,原厂提供的手指不够多功能,不能处理精细的操纵任务。因此,我们设计了自己的3D打印“透明”的手指,并配以握持胶带(图3)。这样在执行精细操作时,能够保持良好的可见性,并且即使在薄膜塑料上也能牢固抓取。
We then seek to design a teleoperation system that is maximally user-friendly around the ViperX robot. Instead of mapping the hand pose captured by a VR controller or camera to the end-effector pose of the robot, i.e. task-space mapping, we use direct joint-space mapping from a smaller robot, WidowX, manufactured by the same company and costs $3300 [2]. The user teleoperates by backdriving the smaller WidowX (“the leader”), whose joints are synchronized with the larger ViperX (“the follower”). When developing the setup, we noticed a few benefits of using joint-space mapping compared to task-space. (1) Fine manipulation often requires operating near singularities of the robot, which in our case has 6 degrees of freedom and no redundancy. Off-the-shelf inverse kinematics (IK) fails frequently in this setting. Joint space mapping, on the other hand, guarantees high-bandwidth control within the joint limits, while also requiring less computation and reducing latency. (2) The weight of the leader robot prevents the user from moving too fast, and also dampens small vibrations. We notice better performance on precise tasks with jointspace mapping rather than holding a VR controller. To further improve the teleoperation experience, we design a 3D-printed “handle and scissor” mechanism that can be retrofitted to the leader robot (Fig 3). It reduces the force required from the operator to backdrive the motor, and allows for continuous control of the gripper, instead of binary opening or closing. We also design a rubber band load balancing mechanism that partially counteracts the gravity on the leader side. It reduces the effort needed from the operator and makes longer teleoperation sessions (e.g. >30 minutes) possible. We include more details about the setup in the project website.
然后,我们致力于设计一个围绕 ViperX 机器人的操作系统,使其在最大程度上易于使用。与使用 VR 控制器或摄像头捕捉的手部姿势映射到机器人的末端执行器姿势(即任务空间映射)不同,我们使用直接从一个较小的机器人 WidowX 到 ViperX 的关节空间映射,WidowX 由同一公司制造,成本为3300美元 [2]。用户通过反向驱动较小的 WidowX(“领导者”)进行远程操作,其关节与较大的 ViperX(“跟随者”)同步。在开发设置时,与任务空间相比,我们注意到使用关节空间映射的一些优势。 (1) 精细操纵通常需要在机器人的奇异点附近操作,在我们的情况下,机器人有6个自由度且没有冗余。现成的逆运动学(IK)在这种情况下经常失败。另一方面,关节空间映射在关节限制内保证了高带宽控制,同时需要较少的计算并减少延迟。(2) 领导机器人的重量阻止用户移动得太快,并且还减缓小的振动。与持握 VR 控制器相比,我们注意到关节空间映射在精细操纵任务中的性能更好。为了进一步改善远程操作体验,我们设计了一个可以安装在领导机器人上的3D打印的“手柄和剪刀”机构(图3)。它降低了操作者反向驱动电机所需的力量,并允许对夹持器进行连续控制,而不是二进制的打开或关闭。我们还设计了一个橡皮筋负载平衡机构,部分抵消了领导机器人一侧的重力。它减轻了操作者的努力,并使更长时间的远程操作会话(例如超过30分钟)成为可能。我们在项目网站上提供了有关设置的更多详细信息。

Fig. 3: Left: Camera viewpoints of the front, top, and two wrist cameras, together with an illustration of the bimanual workspace of ALOHA. Middle: Detailed view of the “handle and scissor” mechanism and custom grippers. Right: Technical spec of the ViperX 6dof robot [1].
图3:左侧:前置摄像头、顶置摄像头和两个手腕摄像头的视点,以及ALOHA双手操作区域的示意图。中间: “手柄和剪刀” 机构和定制夹持器的详细视图。右侧:ViperX 6自由度机器人的技术规格[1]。
The rest of the setup includes a robot cage with 20×20mm aluminum extrusions, reinforced by crossing steel cables. There is a total of four Logitech C922x webcams, each streaming 480×640 RGB images. Two of the webcams are mounted on the wrist of the follower robots, allowing for a close-up view of the grippers. The remaining two cameras are mounted on the front and at the top respectively (Fig 3). Both the teleoperation and data recording happen at 50Hz.
设置的其余部分包括一个由20×20mm铝挤压件构成的机器人笼,通过交叉的钢索加固。总共有四台Logitech C922x网络摄像头,每台都会传输480×640的RGB图像。其中两台摄像头安装在跟随机器人的手腕上,允许近距离观察夹爪。另外两台摄像头分别安装在前面和顶部(图3)。远程操作和数据记录都以50Hz的频率进行。
With the design considerations above, we build the bimanual teleoperation setup ALOHA within a 20k USD budget, comparable to a single research arm such as Franka Emika Panda. ALOHA enables the teleoperation of: • Precise tasks such as threading zip cable ties, picking credit cards out of wallets, and opening or closing ziploc bags. • Contact-rich tasks such as inserting 288-pin RAM into a computer motherboard, turning pages of a book, and assembling the chains and belts in the NIST board #2 [4] • Dynamic tasks such as juggling a ping pong ball with a real ping pong paddle, balancing the ball without it falling off, and swinging open plastic bags in the air.
基于以上的设计考虑,我们在20,000美元的预算内构建了双手远程操作系统ALOHA,这与Franka Emika Panda等单个研究机械臂的预算相当。ALOHA使得远程操作变得可能,包括:
精确任务,如穿线拉紧电缆束,从钱包中取出信用卡,以及打开或关闭拉链袋。
富有接触的任务,如将288针的RAM插入计算机主板,翻书的书页,以及在NIST板#2中组装链条和皮带[4]。
动态任务,如用真正的乒乓球拍玩乒乓球,平衡球而不让其掉下,以及在空中挥动塑料袋。
Skills such as threading a zip tie, inserting RAM, and juggling ping pong ball, to our knowledge, are not available for existing teleoperation systems with 5-10x the budget [21, 5]. We include a more detailed price & capability comparison in Appendix A, as well as more skills that ALOHA is capable of in Figure 9. To make ALOHA more accessible, we open-source all software and hardware with a detailed tutorial covering 3D printing, assembling the frame to software installations. You can find the tutorial on the project website.
据我们了解,穿线拉紧电缆束、插入内存条以及玩乒乓球等技能,在具有5-10倍预算的现有远程操作系统中是无法实现的[21, 5]。我们在附录A中提供了更详细的价格和能力比较,以及ALOHA可以实现的更多技能在图9中展示。为了使ALOHA更易于获取,我们将所有软件和硬件开源,并提供了详细的教程,包括3D打印、组装框架到软件安装。您可以在项目网站上找到教程。
IV. ACTION CHUNKING WITH TRANSFORMERS
IV. 利用Transformer的动作分块算法
As we will see in Section V, existing imitation learning algorithms perform poorly on fine-grained tasks that require high-frequency control and closed-loop feedback. We therefore develop a novel algorithm, Action Chunking with Transformers (ACT), to leverage the data collected by ALOHA. We first summarize the pipeline of training ACT, then dive into each of the design choices.
正如我们将在第V节中看到的,现有的模仿学习算法在需要高频控制和闭环反馈的精细操纵任务上表现不佳。因此,我们开发了一种新颖的算法,即Action Chunking with Transformers (ACT),以利用ALOHA收集的数据。我们首先总结ACT训练的流程,然后深入讨论每个设计选择。
To train ACT on a new task, we first collect human demonstrations using ALOHA. We record the joint positions of the leader robots (i.e. input from the human operator) and use them as actions. It is important to use the leader joint positions instead of the follower’s, because the amount of force applied is implicitly defined by the difference between them, through the low-level PID controller. The observations are composed of the current joint positions of follower robots and the image feed from 4 cameras. Next, we train ACT to predict the sequence of future actions given the current observations. An action here corresponds to the target joint positions for both arms in the next time step. Intuitively, ACT tries to imitate what a human operator would do in the following time steps given current observations. These target joint positions are then tracked by the low-level, high-frequency PID controller inside Dynamixel motors. At test time, we load the policy that achieves the lowest validation loss and roll it out in the environment. The main challenge that arises is compounding errors, where errors from previous actions lead to states that are outside of training distribution.
为了在新任务上训练ACT,我们首先使用ALOHA收集人类演示。我们记录领导机器人的关节位置(即来自人类操作员的输入)并将其用作动作。使用领导机器人的关节位置而不是跟随机器人的位置是重要的,因为通过低级PID控制器,施加的力量量是由它们之间的差异隐式定义的。观察包括跟随机器人的当前关节位置和来自4个摄像头的图像流。接下来,我们训练ACT以在给定当前观察的情况下预测未来动作的序列。这里的一个动作对应于下一个时间步中两只手臂的目标关节位置。直观地说,ACT试图模仿在给定当前观察的情况下人类操作员在接下来的时间步中会做什么。这些目标关节位置然后由Dynamixel电机内部的低级、高频PID控制器进行跟踪。在测试时,我们加载实现最低验证损失的策略,并在环境中进行模拟。出现的主要挑战是“累积误差”,即先前动作的误差导致状态超出了训练分布。
A.Action Chunking and Temporal Ensemble
A. 动作分块和时间集成
To combat the compounding errors of imitation learning in a way that is compatible with pixel-to-action policies (Figure II), we seek to reduce the effective horizon of long trajectories collected at high frequency. We are inspired by action chunking, a neuroscience concept where individual actions are grouped together and executed as one unit, making them more efficient to store and execute [35]. Intuitively, a chunk of actions could correspond to grasping a corner of the candy wrapper or inserting a battery into the slot. In our implementation, we fix the chunk size to be k: every k steps, the agent receives an observation, generates the next k actions, and executes the actions in sequence (Figure 5). This implies a k-fold reduction in the effective horizon of the task. Concretely, the policy models πθ(at:t+k|st) instead of πθ(at|st). Chunking can also help model non-Markovian behavior in human demonstrations. Specifically, a single-step policy would struggle with temporally correlated confounders, such as pauses in the middle of a demonstration [61], since the behavior not only depends on the state, but also the timestep. Action chunking can mitigate this issue when the confounder is within a chunk, without introducing the causal confusion issue for history-conditioned policies [12].
为了应对模仿学习中的累积误差,以与像素到动作策略(图II)兼容的方式,我们试图降低以高频率采集的长轨迹的有效视野。我们受到了动作分块的启发,这是一种神经科学概念,其中将个体动作组合在一起并作为一个单元执行,使它们更有效地存储和执行[35]。直观地说,一个动作块可能对应于抓住糖纸的一角或将电池插入插槽中。在我们的实现中,我们将块大小固定为k:每k步,代理接收一个观察,生成接下来的k个动作,并按顺序执行这些动作(图5)。这意味着任务的有效视野减小了k倍。具体而言,策略建模为πθ(at:t+k|st),而不是πθ(at|st)。分块还有助于模拟人类演示中的非马尔可夫行为。具体来说,单步策略将难以处理时间相关的混淆因素,例如演示过程中的暂停[61],因为行为不仅取决于状态,还取决于时间步长。当混淆因素在一个块内时,动作分块可以减轻这个问题,而不会引入对历史条件策略的因果混淆问题[12]。
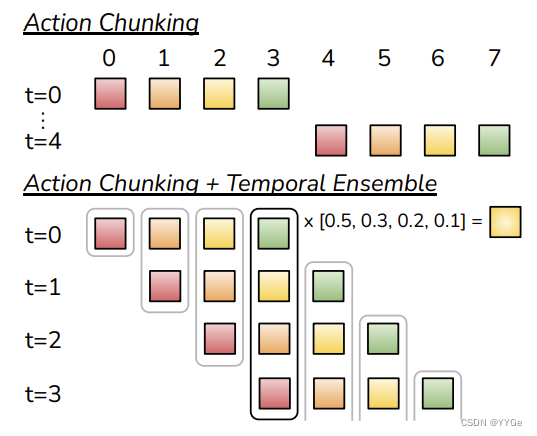
Fig. 5: We employ both Action Chunking and Temporal Ensembling when applying actions, instead of interleaving observing and executing.
图5:在应用动作时,我们同时使用动作分块和时间集成,而不是交替观察和执行。
A naïve implementation of action chunking can be suboptimal: a new environment observation is incorporated abruptly every k steps and can result in jerky robot motion. To improve smoothness and avoid discrete switching between executing and observing, we query the policy at every timestep. This makes different action chunks overlap with each other, and at a given timestep there will be more than one predicted action. We illustrate this in Figure 5 and propose a temporal ensemble to combine these predictions. Our temporal ensemble performs a weighted average over these predictions with an exponential weighting scheme wi = exp(−m ∗ i), where w0 is the weight for the oldest action. The speed for incorporating new observation is governed by m, where a smaller m means faster incorporation. We note that unlike typical smoothing, where the current action is aggregated with actions in adjacent timesteps, which leads to bias, we aggregate actions predicted for the same timestep. This procedure also incurs no additional training cost, only extra inference-time computation. In practice, we find both action chunking and temporal ensembling to be important for the success of ACT, which produces precise and smooth motion. We discuss these components in more detail in the ablation studies in Subsection VI-A.
动作分块的天真实现可能不够优化:每k步突然合并新的环境观察,可能导致机器人运动不流畅。为了提高平滑度并避免执行和观察之间的离散切换,我们在每个时间步查询策略。这使得不同的动作块彼此重叠,在给定的时间步中将会有多个预测动作。我们在图5中进行了说明,并提出了一种时间集成方法来组合这些预测。我们的时间集成对这些预测执行加权平均,使用指数加权方案wi = exp(−m ∗ i),其中w0是最老动作的权重。引入新观察的速度由m控制,其中较小的m意味着更快的合并。需要注意的是,与典型的平滑方法不同,典型的平滑方法将当前动作与相邻时间步的动作聚合在一起,这可能导致偏差,我们聚合在同一时间步预测的动作。这个过程也不会增加额外的训练成本,只会增加推理时的计算量。在实践中,我们发现动作分块和时间集成对于ACT的成功非常重要,它产生了精确而平滑的运动。我们在VI-A小节的消融研究中更详细地讨论了这些组件。
B. Modeling human data
B. 建模人类数据
Another challenge that arises is learning from noisy human demonstrations. Given the same observation, a human can use different trajectories to solve the task. Humans will also be more stochastic in regions where precision matters less [38]. Thus, it is important for the policy to focus on regions where high precision matters. We tackle this problem by training our action chunking policy as a generative model. Specifically, we train the policy as a conditional variational autoencoder (CVAE) [55], to generate an action sequence conditioned on current observations. The CVAE has two components: a CVAE encoder and a CVAE decoder, illustrated on the left and right side of Figure 4 respectively. The CVAE encoder only serves to train the CVAE decoder (the policy) and is discarded at test time. Specifically, the CVAE encoder predicts the mean and variance of the style variable z’s distribution, which is parameterized as a diagonal Gaussian, given the current observation and action sequence as inputs. For faster training in practice, we leave out the image observations and only condition on the proprioceptive observation and the action sequence. The CVAE decoder, i.e. the policy, conditions on both z and the current observations (images + joint positions) to predict the action sequence. At test time, we set z to be the mean of the prior distribution i.e. zero to deterministically decode. The whole model is trained to maximize the log-likelihood of demonstration action chunks, i.e. minθ − P st,at:t+k∈D log πθ(at:t+k|st), with the standard VAE objective which has two terms: a reconstruction loss and a term that regularizes the encoder to a Gaussian prior. Following [23], we weight the second term with a hyperparameter β. Intuitively, higher β will result in less information transmitted in z [62]. Overall, we found the CVAE objective to be essential in learning precise tasks from human demonstrations. We include a more detailed discussion in Subsection VI-B.
另一个挑战是从嘈杂的人类演示中学习。在相同的观察下,人类可以使用不同的轨迹来完成任务。在精度不那么重要的区域,人类也会更加随机[38]。因此,对策略来说,重点放在需要高精度的区域非常重要。我们通过将我们的动作分块策略训练为生成模型来解决这个问题。具体而言,我们将策略训练为条件变分自动编码器(CVAE)[55],以在当前观察条件下生成动作序列。CVAE包括两个组件:CVAE编码器和CVAE解码器,分别在图4的左侧和右侧进行了说明。CVAE编码器仅用于训练CVAE解码器(策略),在测试时被丢弃。具体而言,CVAE编码器在给定当前观察和动作序列作为输入的情况下,预测样式变量z的分布的均值和方差,该分布被参数化为对角高斯。为了在实践中更快地进行训练,我们省略了图像观察,仅以固有观察和动作序列为条件。CVAE解码器,即策略,以z和当前观察(图像+关节位置)为条件来预测动作序列。在测试时,我们将z设置为先验分布的均值,即零,以确定性解码。整个模型的训练目标是最大化演示动作块的对数似然,即minθ − P st,at:t+k∈D log πθ(at:t+k|st),使用标准的VAE目标,包括重构损失和正则化编码器到高斯先验的项。根据[23],我们使用超参数β加权第二项。直观地说,较高的β将导致z中传递的信息更少[62]。总体而言,我们发现CVAE目标对从人类演示中学习精细任务至关重要。我们在VI-B小节中包含了更详细的讨论。
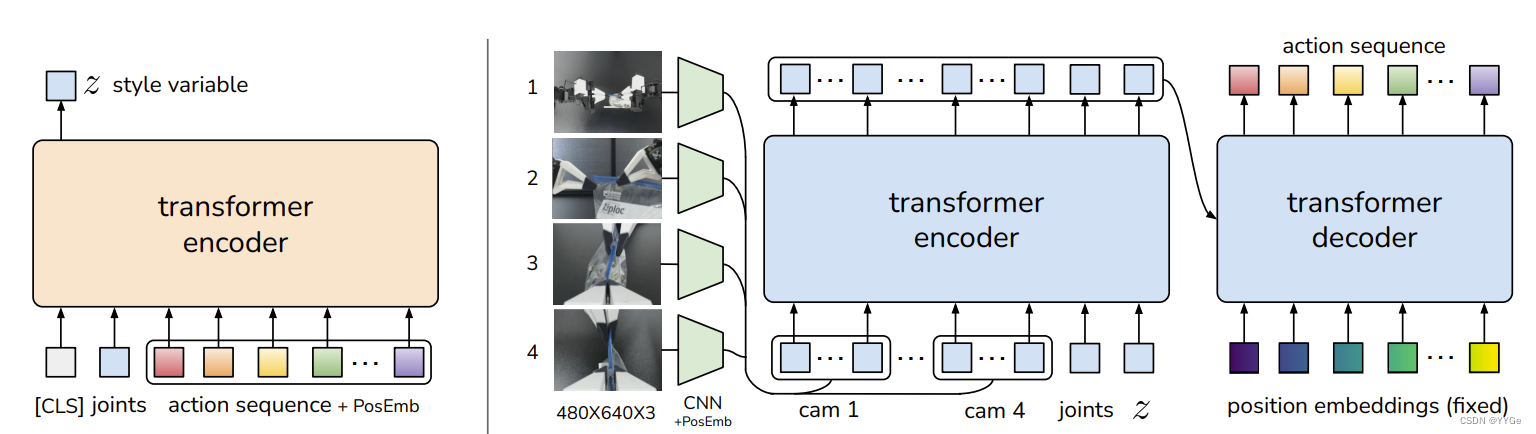
Fig. 4: Architecture of Action Chunking with Transformers (ACT). We train ACT as a Conditional VAE (CVAE), which has an encoder and a decoder. Left: The encoder of the CVAE compresses action sequence and joint observation into z, the style variable. The encoder is discarded at test time. Right: The decoder or policy of ACT synthesizes images from multiple viewpoints, joint positions, and z with a transformer encoder, and predicts a sequence of actions with a transformer decoder. z is simply set to the mean of the prior (i.e. zero) at test time.
图4:Action Chunking with Transformers (ACT)的架构。我们将ACT训练为条件变分自动编码器(CVAE),它有一个编码器和一个解码器。左侧:CVAE的编码器将动作序列和关节观察压缩成z,即样式变量。编码器在测试时被丢弃。右侧:ACT的解码器或策略使用变压器编码器从多个视点、关节位置和z合成图像,并使用变压器解码器预测一系列动作。在测试时,z简单地设置为先验的均值(即零)。
C. Implementing ACT
C. 实施ACT
We implement the CVAE encoder and decoder with transformers, as transformers are designed for both synthesizing information across a sequence and generating new sequences. The CVAE encoder is implemented with a BERT-like transformer encoder [13]. The inputs to the encoder are the current joint positions and the target action sequence of length k from the demonstration dataset, prepended by a learned “[CLS]” token similar to BERT. This forms a k+2 length input (Figure 4 left). After passing through the transformer, the feature corresponding to “[CLS]” is used to predict the mean and variance of the “style variable” z, which is then used as input to the decoder. The CVAE decoder (i.e. the policy) takes the current observations and z as the input, and predicts the next k actions (Figure 4 right). We use ResNet image encoders, a transformer encoder, and a transformer decoder to implement the CVAE decoder. Intuitively, the transformer encoder synthesizes information from different camera viewpoints, the joint positions, and the style variable, and the transformer decoder generates a coherent action sequence. The observation includes 4 RGB images, each at 480 × 640 resolution, and joint positions for two robot arms (7+7=14 DoF in total). The action space is the absolute joint positions for two robots, a 14-dimensional vector. Thus with action chunking, the policy outputs a k × 14 tensor given the current observation. The policy first process the images with ResNet18 backbones [22], which convert 480 × 640 × 3 RGB images into 15 × 20 × 512 feature maps. We then flatten along the spatial dimension to obtain a sequence of 300 × 512. To preserve the spatial information, we add a 2D sinusoidal position embedding to the feature sequence [8]. Repeating this for all 4 images gives a feature sequence of 1200 × 512 in dimension. We then append two more features: the current joint positions and the “style variable” z. They are projected from their original dimensions to 512 through linear layers respectively. Thus, the input to the transformer encoder is 1202×512. The transformer decoder conditions on the encoder output through cross-attention, where the input sequence is a fixed position embedding, with dimensions k × 512, and the keys and values are coming from the encoder. This gives the transformer decoder an output dimension of k × 512, which is then down-projected with an MLP into k × 14, corresponding to the predicted target joint positions for the next k steps. We use L1 loss for reconstruction instead of the more common L2 loss: we noted that L1 loss leads to more precise modeling of the action sequence. We also noted degraded performance when using delta joint positions as actions instead of target joint positions. We include a detailed architecture diagram in Appendix C.
我们使用transformers实现了CVAE编码器和解码器,因为transformers被设计用于在序列之间合成信息和生成新的序列。CVAE编码器采用了类似BERT的transformer编码器 [13]。编码器的输入包括当前的关节位置和来自演示数据集的长度为k的目标动作序列,前面加上一个学习到的“[CLS]”标记,类似于BERT。这形成了一个长度为k+2的输入(见图4左侧)。通过transformer后,与“[CLS]”对应的特征被用来预测“样式变量”z的均值和方差,然后作为解码器的输入。CVAE解码器(即策略)以当前的观察和z作为输入,并预测接下来的k个动作(见图4右侧)。我们使用ResNet图像编码器、一个transformer编码器和一个transformer解码器来实现CVAE解码器。直观地说,transformer编码器从不同的摄像机视点、关节位置和样式变量中合成信息,而transformer解码器生成一个连贯的动作序列。观察包括4个RGB图像,每个图像分辨率为480 × 640,以及两个机器人手臂的关节位置(总共14个自由度)。动作空间是两个机器人的绝对关节位置,是一个14维的向量。因此,使用动作分块,策略在给定当前观察的情况下输出一个k × 14的张量。策略首先使用ResNet18骨干网络 [22]处理图像,将480 × 640 × 3的RGB图像转换为15 × 20 × 512的特征图。然后我们沿着空间维度展平,得到一个300 × 512的序列。为了保留空间信息,我们向特征序列添加了一个二维正弦位置嵌入 [8]。对所有4个图像重复这个过程,得到一个维度为1200 × 512的特征序列。然后我们添加两个额外的特征:当前的关节位置和“样式变量”z。它们分别通过线性层投影到512维。因此,transformer编码器的输入是1202×512。transformer解码器通过交叉注意力在编码器输出上进行条件化,其中输入序列是一个固定的位置嵌入,维度为k × 512,而键和值来自编码器。这使得transformer解码器的输出维度为k × 512,然后通过MLP进行下投影,得到k × 14,对应于接下来k步的目标关节位置。我们使用L1损失进行重建,而不是更常见的L2损失:我们注意到L1损失能够更精确地建模动作序列。我们还注意到,与使用目标关节位置相比,使用增量关节位置作为动作会导致性能下降。我们在附录C中包含了详细的架构图。
We summarize the training and inference of ACT in Algorithms 1 and 2. The model has around 80M parameters, and we train from scratch for each task. The training takes around 5 hours on a single 11G RTX 2080 Ti GPU, and the inference time is around 0.01 seconds on the same machine.
我们在算法1和算法2中总结了ACT的训练和推理。模型有大约80M个参数,我们为每个任务从头开始训练。在单个11G RTX 2080 Ti GPU上,训练大约需要5个小时,推理时间在同一台机器上约为0.01秒。

V. EXPERIMENTS
V. 实验
We present experiments to evaluate ACT’s performance on fine manipulation tasks. For ease of reproducibility, we build two simulated fine manipulation tasks in MuJoCo [63], in addition to 6 real-world tasks with ALOHA. We provide videos for each task on the project website.
我们进行了实验,以评估ACT在精细操作任务上的性能。为了便于重现,我们在MuJoCo [63]中构建了两个模拟的精细操作任务,此外还有使用ALOHA进行的6个真实世界任务。我们在项目网站上为每个任务提供了视频。
A. Tasks
A. 任务
All 8 tasks require fine-grained, bimanual manipulation, and are illustrated in Figure 6. For Slide Ziploc, the right gripper needs to accurately grasp the slider of the ziploc bag and open it, with the left gripper securing the body of the bag. For Slot Battery, the right gripper needs to first place the battery into the slot of the remote controller, then using the tip of fingers to delicately push in the edge of the battery, until it is fully inserted. Because the spring inside the battery slot causes the remote controller to move in the opposite direction during insertion, the left gripper pushes down on the remote to keep it in place. For Open Cup, the goal is to open the lid of a small condiment cup. Because of the cup’s small size, the grippers cannot grasp the body of the cup by just approaching it from the side. Therefore we leverage both grippers: the right fingers first lightly tap near the edge of the cup to tip it over, and then nudge it into the open left gripper. This nudging step requires high precision and closing the loop on visual perception. The left gripper then closes gently and lifts the cup off the table, followed by the right finger prying open the lid, which also requires precision to not miss the lid or damage the cup. The goal of Thread Velcro is to insert one end of a velcro cable tie into the small loop attached to other end. The left gripper needs to first pick up the velcro tie from the table, followed by the right gripper pinching the tail of the tie in mid-air. Then, both arms coordinate to insert one end of the velcro tie into the other in mid-air. The loop measures 3mm x 25mm, while the velcro tie measures 2mm x 10-25mm depending on the position. For this task to be successful, the robot must use visual feedback to correct for perturbations with each grasp, as even a few millimeters of error during the first grasp will compound in the second grasp mid-air, giving more than a 10mm deviation in the insertion phase. For Prep Tape, the goal is to hang a small segment of the tape on the edge of a cardboard box. The right gripper first grasps the tape and cuts it with the tape dispenser’s blade, and then hands the tape segment to the left gripper mid-air. Next, both arms approach the box, the left arm gently lays the tape segment on the box surface, and the right fingers push down on the tape to prevent slipping, followed by the left arm opening its gripper to release the tape. Similar to Thread Velcro, this task requires multiple steps of delicate coordination between the two arms. For Put On Shoe, the goal is to put the shoe on a fixed manniquin foot, and secure it with the shoe’s velcro strap. The arms would first need to grasp the tongue and collar of the shoe respectively, lift it up and approach the foot. Putting the shoe on is challenging because of the tight fitting: the arms would need to coordinate carefully to nudge the foot in, and both grasps need to be robust enough to counteract the friction between the sock and shoe. Then, the left arm goes around to the bottom of the shoe to support it from dropping, followed by the right arm flipping the velcro strap and pressing it against the shoe to secure. The task is only considered successful if the shoe clings to the foot after both arms releases. For the simulated task Transfer Cube, the right arm needs to first pick up the red cube lying on the table, then place it inside the gripper of the other arm. Due to the small clearance between the cube and the left gripper (around 1cm), small errors could result in collisions and task failure. For the simulated task Bimanual Insertion, the left and right arms need to pick up the socket and peg respectively, and then insert in mid-air so the peg touches the “pins” inside the socket. The clearance is around 5mm in the insertion phase. For all 8 tasks, the initial placement of the objects is either varied randomly along the 15cm white reference line (real-world tasks), or uniformly in 2D regions (simulated tasks). We provide illustrations of both the initial positions and the subtasks in Figure 6 and 7. Our evaluation will additionally report the performance for each of these subtasks.
这8个任务都需要精细的、双手的操作,如图6所示。对于Slide Ziploc任务,右夹具需要精确抓住拉链袋的滑块并打开,左夹具则固定袋子的主体。对于Slot Battery任务,右夹具首先需要将电池放入遥控器的插槽中,然后使用指尖轻柔地推动电池的边缘,直到完全插入。由于电池插槽内的弹簧在插入过程中使遥控器朝相反方向移动,左夹具会向下按压遥控器以保持其位置。对于Open Cup任务,目标是打开小调味杯的盖子。由于杯子尺寸较小,夹具不能仅通过从侧面接近杯子来抓住杯子的主体。因此,我们利用两个夹具:右手指首先轻轻敲击杯子边缘以使其倾斜,然后将其挤入打开的左夹爪。这个挤压步骤需要高精度和对视觉感知的封闭循环。然后左夹具轻轻关闭并将杯子从桌子上抬起,接着右手指撬开盖子,这也需要精确操作以防错过盖子或损坏杯子。Thread Velcro任务的目标是将维可粘扎带的一端插入附在另一端的小环中。左夹具首先需要从桌子上拿起维可粘扎带,然后右夹具捏住带子的尾部。接下来,两只手臂协调工作,将维可粘扎带的一端插入另一端。环的尺寸为3mm x 25mm,而维可粘扎带的尺寸为2mm x 10-25mm,具体取决于位置。为了使任务成功,机器人必须使用视觉反馈来纠正每次抓取时的摄动,因为即使在第一次抓取时有几毫米的误差,在第二次抓取时也会叠加,导致插入阶段的偏差超过10mm。Prep Tape任务的目标是将一小段胶带悬挂在纸板箱的边缘。右夹爪首先抓住胶带并用胶带切割器的刀片切断,然后将胶带片段递交给左夹具。接下来,两只手臂靠近纸箱,左臂轻轻将胶带片段放在纸箱表面,右手指按下胶带以防止滑动,然后左臂打开夹具以释放胶带。与Thread Velcro类似,该任务需要两只手臂之间的多个步骤的精细协调。Put On Shoe任务的目标是将鞋子穿在一个固定的模特脚上,并用鞋带固定。手臂首先需要分别抓住鞋子的舌头和领口,将其提起并靠近脚。穿鞋子的任务具有挑战性,因为鞋子的紧身程度:手臂需要仔细协调以将脚轻轻推入,而且两次抓取都需要足够强壮,以抵消袜子和鞋子之间的摩擦。然后,左臂绕到鞋子底部以支撑它不掉落,接着右臂翻转魔术贴并将其按在鞋子上以固定。只有在两只手臂释放后鞋子紧贴脚上,任务才被认为成功。对于模拟任务Transfer Cube,右臂需要首先拾起放在桌子上的红色立方体,然后将其放入另一只手臂的夹爪中。由于立方体与左夹具之间的空间很小(约1cm),小错误可能导致碰撞和任务失败。对于模拟任务Bimanual Insertion,左右手臂需要分别拾起插座和销钉,然后在半空中插入,使销钉触及插座内的“引脚”。插入阶段的间隙约为5mm。对于所有8个任务,对象的初始放置位置要么是沿着15cm白色参考线随机变化的(真实任务),要么是在2D区域均匀分布的(模拟任务)。我们在图6和7中提供了对象的初始位置和子任务的插图。我们的评估还将报告每个子任务的性能。

Slide Ziploc任务:打开站立在桌子上的ziploc袋。袋子沿着15厘米的白线随机放置。它从离桌面约5厘米的高度掉落,以随机化变形,影响袋子的高度和外观。左臂首先抓住袋子主体(子任务#1 抓取),然后右臂捏住拉链滑块(子任务#2 捏取)。接着右臂向右移动以解开袋子(子任务#3 打开)。

Slot Battery任务:将电池插入遥控器。遥控器沿着15厘米的白线随机放置。电池的初始位置大致相同,但有不同的旋转。右臂首先抓住电池(子任务#1 抓取),然后将其放入插槽(子任务#2 放置)。左臂按压遥控器,防止其滑动,而右臂推动电池进入插槽(子任务#3 插入)。

Open Cup 任务:拿起并打开一个半透明的调味品杯盖。杯子沿着15厘米的白线随机放置。两只手臂接近杯子,右手轻轻翻倒杯子(子任务#1 翻倒)并将其推到左臂的夹爪中。然后,左臂轻轻闭合夹爪并将杯子从桌子上提起(子任务#2 抓取)。接下来,右手从下面接近杯盖,打开盖子。

Thread Velcro 任务:拿起维可粘扣条并将一端插入另一端的小环中。维可扣条沿着15厘米的白线随机放置。左臂首先通过夹近塑料环的方式拾起维可扣条(子任务#1 抬起)。右臂在空中夹住维可扣条的尾部(子任务#2 夹持)。接下来,两只手臂协调工作,变形维可扣条并将其一端插入另一端的塑料环中。

Prep Tape 任务:在盒子的边缘挂一小段胶带。胶带切割器沿着15厘米的白线随机放置。首先,右爪从侧面夹住胶带(子任务#1 夹持)。然后,它抬起胶带并拉动以展开它,然后用切割器切断(子任务#2 切割)。接下来,右爪在空中将胶带段交给左爪(子任务#3 交接),然后两只手臂朝着文具纸板盒的角落移动。左臂然后将胶带段平放在盒子表面,而右爪向下推压胶带以防止滑动。左臂然后打开其夹持器以释放胶带(子任务#4 挂)。

Put On Shoe 任务:给一个固定的模特脚穿上一只魔术贴鞋。鞋的位置沿着15厘米的白线随机放置。首先,左右两个夹持器都抓住鞋子(子任务#1 抬起)。然后,两只手臂协调一致地将鞋子穿上,让鞋跟与鞋后跟相接触(子任务#2 插入)。接下来,左臂移动以支撑鞋子(子任务#3 支撑),然后右臂固定魔术贴带(子任务#4 固定)。
Fig. 6: Real-World Task Definitions. For each of the 6 real-world tasks, we illustrate the initializations and the subtasks.
Fig. 6: “现实世界任务定义”。对于这6个真实世界的任务,我们说明了初始化和子任务。
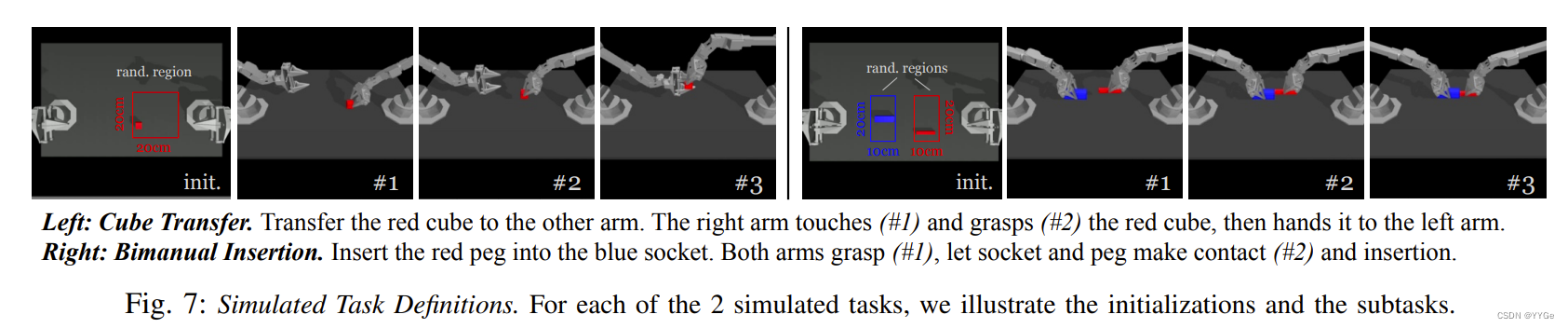
左图:立方体传递。将红色立方体传递给另一只手臂。右臂触摸(#1)和抓取(#2)红色立方体,然后将其交给左臂。
右图:双手插入。将红色插销插入蓝色插槽。两只手臂抓取(#1),使插槽和插销接触(#2),然后插入。
Fig. 7: Simulated Task Definitions. For each of the 2 simulated tasks, we illustrate the initializations and the subtasks.
图7:模拟任务定义。对于2个模拟任务中的每一个,我们说明了初始化和子任务。
In addition to the delicate bimanual control required to solve these tasks, the objects we use also present a significant perception challenge. For example, the ziploc bag is largely transparent, with a thin blue sealing line. Both the wrinkles on the bag and the reflective candy wrappers inside can vary during the randomization, and distract the perception system. Other transparent or translucent objects include the tape and both the lid and body of the condiment cup, making them hard to perceive precisely and ill-suited for depth cameras. The black table top also creates a low-contrast against many objects of interest, such as the black velcro cable tie and the black tape dispenser. Especially from the top view, it is challenging to localize the velcro tie because of the small projected area.
除了解决这些任务所需的精细双手控制之外,我们使用的物体还带来了相当大的感知挑战。例如,ziploc袋主要是透明的,有一条薄薄的蓝色密封线。袋子上的褶皱和内部反光的糖果包装在随机化过程中可能会变化,分散感知系统的注意力。其他透明或半透明的物体包括胶带、调味品杯的盖子和本体,使它们难以精确定位,不适合深度摄像头。黑色桌面与许多感兴趣的物体形成低对比度,例如黑色的Velcro电缆扎带和黑色的胶带切割器。特别是从顶部视图来看,由于投影面积小,很难定位Velcro扎带。
B. Data Collection
B. 数据收集
For all 6 real-world tasks, we collect demonstrations using ALOHA teleoperation. Each episode takes 8-14 seconds for the human operator to perform depending on the complexity of the task, which translates to 400-700 time steps given the control frequency of 50Hz. We record 50 demonstrations for each task, except for Thread Velcro which has 100. The total amount for demonstrations is thus around 10-20 minutes of data for each task, and 30-60 minutes in wall-clock time because of resets and teleoperator mistakes. For the two simulated tasks, we collect two types of demonstrations: one type with a scripted policy and one with human demonstrations. To teleoperate in simulation, we use the “leader robots” of ALOHA to control the simulated robot, with the operator looking at the real-time renderings of the environment on the monitor. In both cases, we record 50 successful demonstrations.
对于所有6个真实世界的任务,我们使用ALOHA远程操作进行演示数据的收集。每个episode由人类操作员执行,耗时8-14秒,具体取决于任务的复杂性,这对应于50Hz的控制频率下的400-700个时间步。我们为每个任务记录了50次演示,Thread Velcro任务记录了100次。因此,每个任务的演示总量约为10-20分钟的数据,由于重置和远程操作员的错误,墙上时间为30-60分钟。对于两个模拟任务,我们收集了两种类型的演示:一种是使用脚本策略,另一种是使用人类演示。为了在模拟中进行远程操作,我们使用ALOHA的“leader robots”来控制模拟机器人,操作员通过监视器实时查看环境的渲染。在两种情况下,我们记录了50次成功的演示。
We emphasize that all human demonstrations are inherently stochastic, even though a single person collects all of the demonstrations. Take the mid-air hand handover of the tape segment as an example: the exact position of the handover is different across each episode. The human has no visual or haptic reference to perform it in the same position. Thus to successfully perform the task, the policy will need to learn that the two grippers should never collide with each other during the handover, and the left gripper should always move to a position that can grasp the tape, instead of trying to memorize where exactly the handover happens, which can vary across demonstrations.
我们强调所有人类演示都是固有的随机的,即使是同一个人进行了所有的演示。以在空中交接胶带段的操作为例:每个episode中交接的确切位置都是不同的。人类在执行此操作时没有视觉或触觉参考来在相同位置执行它。因此,为了成功执行任务,策略将需要学习两个夹具在交接过程中不应碰撞,而左夹具应始终移动到可以抓取胶带的位置,而不是试图记住交接发生的确切位置,这在演示之间可能有所不同。
C.Experiment Results
C.实验结果
We compare ACT with four prior imitation learning methods. BC-ConvMLP is the simplest yet most widely used baseline [69, 26], which processes the current image observations with a convolutional network, whose output features are concatenated with the joint positions to predict the action. BeT [49] also leverages Transformers as the architecture, but with key differences: (1) no action chunking: the model predicts one action given the history of observations; and (2) the image observations are pre-processed by a separately trained frozen visual encoder. That is, the perception and control networks are not jointly optimized. RT-1 [7] is another Transformerbased architecture that predicts one action from a fixed-length history of past observations. Both BeT and RT-1 discretize the action space: the output is a categorical distribution over discrete bins, but with an added continuous offset from the bincenter in the case of BeT. Our method, ACT, instead directly predicts continuous actions, motivated by the precision required in fine manipulation. Lastly, VINN [42] is a non-parametric method that assumes access to the demonstrations at test time. Given a new observation, it retrieves the k observations with the most similar visual features, and returns an action using weighted k-nearest-neighbors. The visual feature extractor is a pretrained ResNet finetuned on demonstration data with unsupervised learning. We carefully tune the hyperparameters of these four prior methods using cube transfer. Details of the hyperparameters are provided in Appendix D.
我们将ACT与四种先前的模仿学习方法进行比较。BC-ConvMLP是最简单但也是最广泛使用的基线之一[69, 26],它使用卷积网络处理当前的图像观察,其输出特征与关节位置连接以预测动作。BeT [49]也利用了变压器作为架构,但存在关键差异:(1)没有动作分块:该模型根据观察历史预测一个动作;(2)图像观察经过一个单独训练的冻结视觉编码器的预处理。也就是说,感知和控制网络没有联合优化。RT-1 [7]是另一种基于Transformer的架构,它从固定长度的过去观察历史中预测一个动作。BeT和RT-1都对动作空间进行离散化:输出是离散区间上的分类分布,但在BeT的情况下,还添加了相对于区间中心的连续偏移。我们的方法ACT相反,直接预测连续动作,这是因为在精细操纵中需要高精度。最后,VINN [42]是一种非参数方法,假定在测试时可以访问演示。对于给定的新观察,它检索具有最相似视觉特征的k个观察,并使用加权k最近邻返回一个动作。视觉特征提取器是在演示数据上进行无监督学习的预训练ResNet。我们使用立方体传输仔细调整这四种先前方法的超参数。有关超参数的详细信息请参见附录D。
As a detailed comparison with prior methods, we report the average success rate in Table I for two simulated and two real tasks. For simulated tasks, we average performance across 3 random seeds with 50 trials each. We report the success rate on both scripted data (left of separation bar) and human data (right of separation bar). For real-world tasks, we run one seed and evaluate with 25 trials. ACT achieves the highest success rate compared to all prior methods, outperforming the second best algorithm by a large margin on each task. For the two simulated tasks with scripted or human data, ACT outperforms the best previous method in success rate by 59%, 49%, 29%, and 20%. While previous methods are able to make progress in the first two subtasks, the final success rate remains low, below 30%. For the two real-world tasks Slide Ziploc and Slot Battery, ACT achieves 88% and 96% final success rates respectively, with other methods making no progress past the first stage. We attribute the poor performance of prior methods to compounding errors and non-Markovian behavior in the data: the behavior degrades significantly towards the end of an episode, and the robot can pause indefinitely for certain states. ACT mitigates both issues with action chunking. Our ablations in Subsection VI-A also shows that chunking can significantly improve these prior methods when incorporated. In addition, we notice a drop in performance for all methods when switching from scripted data to human data in simulated tasks: the stochasticity and multi-modality of human demonstrations make imitation learning a lot harder
作为与先前方法的详细比较,我们在表I中报告了两个模拟任务和两个真实任务的平均成功率。对于模拟任务,我们在每个随机种子上进行了50次试验,然后平均性能。我们报告了在脚本数据(分隔线左侧)和人类数据(分隔线右侧)上的成功率。对于真实任务,我们使用一个随机种子运行并在25次试验中评估。与所有先前方法相比,ACT在每个任务上都取得了最高的成功率,比第二好的算法在每个任务上都要好很多。对于具有脚本或人类数据的两个模拟任务,ACT在成功率上超过了先前方法中的最佳方法,分别为59%、49%、29%和20%。虽然先前的方法能够在前两个子任务中取得进展,但最终的成功率仍然很低,低于30%。对于两个真实任务Slide Ziploc和Slot Battery,ACT的最终成功率分别达到了88%和96%,而其他方法在第一阶段之后无法取得进展。我们将先前方法的表现不佳归因于数据中的复合误差和非马尔可夫行为:在一个episode结束时,行为会显著恶化,机器人可能会在某些状态下无限期地停顿。ACT通过动作分块缓解了这两个问题。我们在第VI-A小节的消融实验中还显示,当引入分块时,先前的方法的性能显著提高。此外,我们注意到在从脚本数据切换到模拟任务中的人类数据时,所有方法的性能都有所下降:人类演示的随机性和多模态性使得模仿学习变得更加困难。
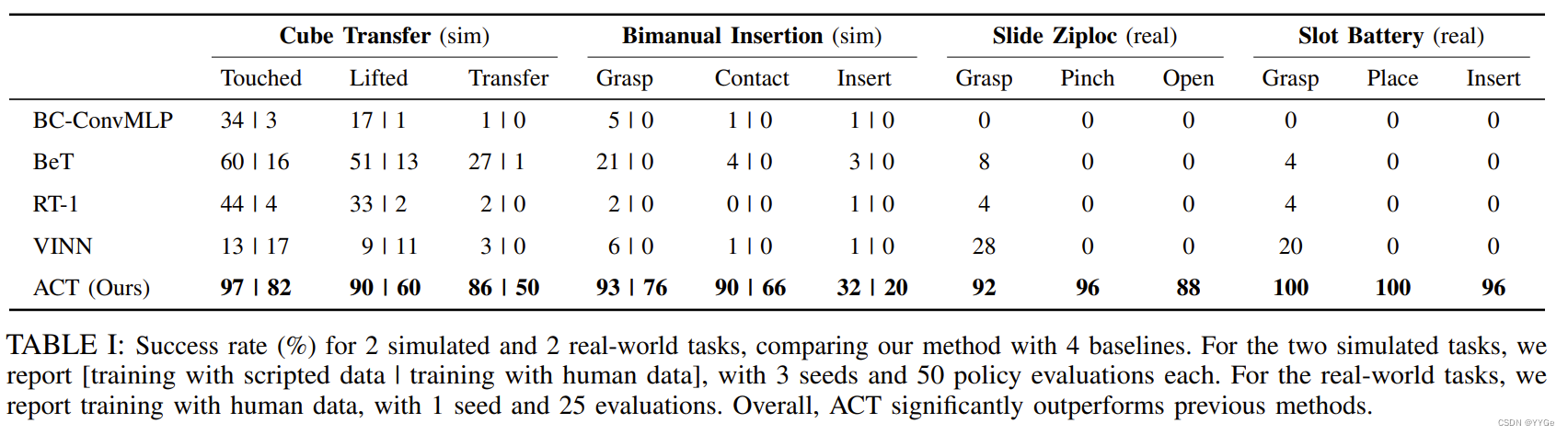
表格 I: 2个模拟任务和2个真实任务的成功率(%),将我们的方法与4个基线进行比较。对于两个模拟任务,我们报告[使用脚本数据训练 | 使用人类数据训练],每个有3个种子和50次策略评估。对于真实任务,我们报告使用人类数据训练,每个有1个种子和25次评估。总体而言,ACT明显优于先前的方法。
We report the success rate of the 3 remaining real-world tasks in Table II. For these tasks, we only compare with BeT, which has the highest task success rate so far. Our method ACT reaches 84% success for Cup Open, 20% for Thread Velcro, 64% for Prep Tape and 92% for Put On Shoe, again outperforming BeT, which achieve zero final success on these challenging tasks. We observe relatively low success of ACT in Thread Velcro, where the success rate decreased by roughly half at every stage, from 92% success at the first stage to 20% final success. The failure modes we observe are 1) at stage 2, the right arm closes its gripper too early and fails to grasp the tail of the cable tie mid-air, and 2) in stage 3, the insertion is not precise enough and misses the loop. In both cases, it is hard to determine the exact position of the cable tie from image observations: the contrast is low between the black cable tie and the background, and the cable tie only occupies a small fraction of the image. We include examples of image observations in Appendix B.
我们在表II中报告了剩下的3个真实任务的成功率。对于这些任务,我们仅与BeT进行比较,因为它到目前为止拥有最高的任务成功率。我们的方法ACT在Cup Open达到84%的成功率,在Thread Velcro达到20%,在Prep Tape达到64%,在Put On Shoe达到92%,再次优于BeT,后者在这些具有挑战性的任务上取得了零的最终成功率。我们观察到ACT在Thread Velcro中的成功率相对较低,成功率每个阶段减少约一半,从第一个阶段的92%降至最终成功率的20%。我们观察到的失败模式是:1) 在第二阶段,右臂过早关闭夹持器,未能抓住空中的电缆扎的尾部;2) 在第三阶段,插入不够精确,错过了电缆扎的环。在这两种情况下,从图像观察中很难确定电缆扎的确切位置:黑色电缆扎与背景之间的对比度较低,并且电缆扎仅占图像的一小部分。我们在附录B中提供了图像观察的示例。

表格 II: 3个剩余真实任务的成功率(%)。我们只与表现最好的基线 BeT 进行比较。
V.ABLATIONS
V.消融实验
ACT employs action chunking and temporal ensembling to mitigate compounding errors and better handle non-Markovian demonstrations. It also trains the policy as a conditional VAE to model the noisy human demonstrations. In this section, we ablate each of these components, together with a user study that highlights the necessity of high-frequency control in ALOHA. We report results across a total of four settings: two simulated tasks with scripted or human demonstration.
ACT使用动作分块和时间集成来减轻复合错误,并更好地处理非马尔可夫演示。它还将策略训练为条件VAE,以模拟嘈杂的人类演示。在这一部分,我们将剖析每个组件,以及一项用户研究,强调ALOHA中高频控制的必要性。我们在总共四个设置中报告结果:两个使用脚本或人类演示的模拟任务。
A.Action Chunking and Temporal Ensembling
A. 动作分块和时间集成
In Subsection V-C, we observed that ACT significantly outperforms previous methods that only predict single-step actions, with the hypothesis that action chunking is the key design choice. Since k dictates how long the sequence in each “chunk” is, we can analyze this hypothesis by varying k. k = 1 corresponds to no action chunking, and k = episode_length corresponds to fully open-loop control, where the robot outputs the entire episode’s action sequence based on the first observation. We disable temporal ensembling in these experiments to only measure the effect of chunking, and trained separate policies for each k. In Figure 8 (a), we plot the success rate averaged across 4 settings, corresponding to 2 simulated tasks with either human or scripted data, with the blue line representing ACT without the temporal ensemble. We observe that performance improves drastically from 1% at k = 1 to 44% at k = 100, then slightly tapers down with higher k. This illustrates that more chunking and a lower effective horizon generally improve performance. We attribute the slight dip at k = 200, 400 (i.e., close to open-loop control) to the lack of reactive behavior and the difficulty in modeling long action sequences. To further evaluate the effectiveness and generality of action chunking, we augment two baseline methods with action chunking. For BC-ConvMLP, we simply increase the output dimension to k∗action_dim, and for VINN, we retrieve the next k actions. We visualize their performance in Figure 8 (a) with different k, showing trends consistent with ACT, where more action chunking improves performance. While ACT still outperforms both augmented baselines with sizable gains, these results suggest that action chunking is generally beneficial for imitation learning in these settings.
在第V-C小节中,我们观察到ACT明显优于先前仅预测单步动作的方法,假设动作分块是关键的设计选择。由于k决定了每个“块”中序列的长度,我们可以通过改变k来分析这一假设。k = 1对应于没有动作分块,而k = episode_length对应于完全开环控制,在这种情况下,机器人基于第一帧观察输出整个剧集的动作序列。在这些实验中,我们禁用了时间集成,只测量分块的效果,并为每个k训练了单独的策略。在图8(a)中,我们绘制了在4个设置中平均的成功率,对应于使用人类或脚本数据的两个模拟任务,蓝线代表没有时间集成的ACT。我们观察到,性能从k = 1的1%显著提高到k = 100的44%,然后在更高的k下略微下降。这说明更多的分块和较低的有效视野通常会提高性能。我们将在k = 200、400(即接近开环控制)处的轻微下降归因于缺乏反应性行为和建模长动作序列的困难。为了进一步评估动作分块的有效性和通用性,我们使用动作分块增强了两种基线方法。对于BC-ConvMLP,我们简单地将输出维度增加到k∗action_dim,而对于VINN,我们检索接下来的k个动作。我们在图8(a)中可视化它们的性能,显示出与ACT一致的趋势,即更多的动作分块有助于提高性能。虽然ACT在性能上仍然优于这两种增强的基线,但这些结果表明在这些设置中,动作分块通常是模仿学习有益的。
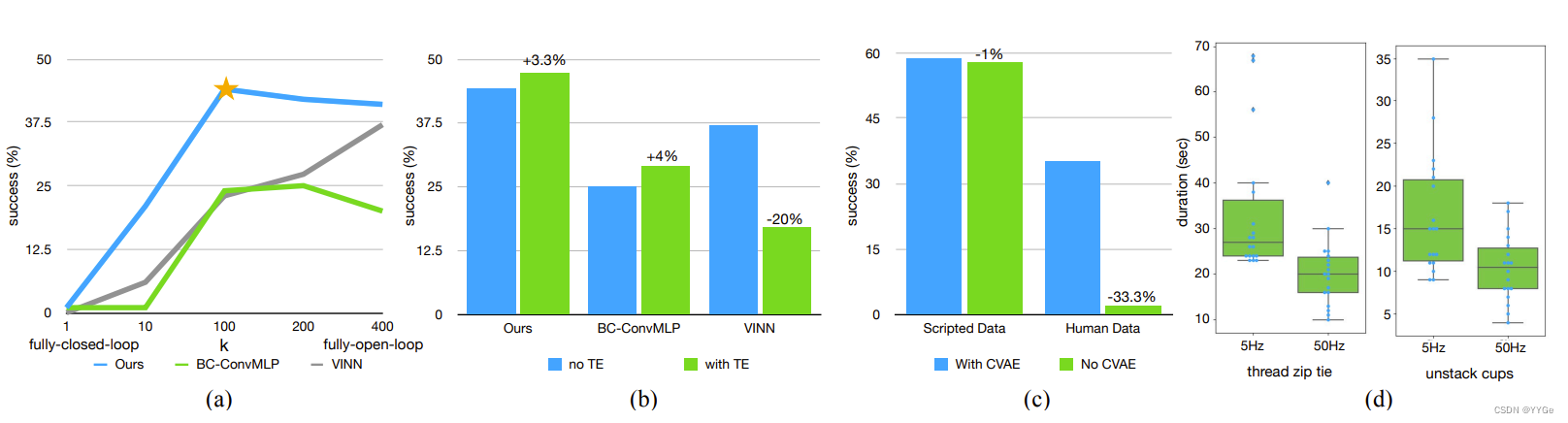
Fig. 8: (a) We augment two baselines with action chunking, with different values of chunk size k on the x-axis, and success rate on the y-axis. Both methods significantly benefit from action chunking, suggesting that it is a generally useful technique. (b) Temporal Ensemble (TE) improves our method and BC-ConvMLP, while hurting VINN. © We compare with and without the CVAE training, showing that it is crucial when learning from human data. (d) We plot the distribution of task completion time in our user study, where we task participants to perform two tasks, at 5Hz or 50Hz teleoperation frequency. Lowering the frequency results in a 62% slowdown in completion time.
图 8: (a) 我们使用不同的块大小 k 对两个基线进行了块化操作,x 轴表示块大小 k,y 轴表示成功率。两种方法都从块化操作中受益良多,这表明这是一种通用有效的技术。(b) 时间集成(TE)提高了我们的方法和 BC-ConvMLP,但对 VINN 有害。© 我们比较了使用和不使用 CVAE 训练,结果显示从人类数据中学习时这是至关重要的。(d) 我们绘制了用户研究中任务完成时间的分布,参与者被要求以5Hz或50Hz的远程操作频率执行两个任务。降低频率导致完成时间减缓了62%。
B. Training with CVAE
B. 使用CVAE训练
We train ACT with CVAE objective to model human demonstrations, which can be noisy and contain multi-modal behavior. In this section, we compare with ACT without the CVAE objective, which simply predicts a sequence of actions given current observation, and trained with L1 loss. In Figure 8©, we visualize the success rate aggregated across 2 simulated tasks, and separately plot training with scripted data and with human data. We can see that when training on scripted data, the removal of CVAE objective makes almost no difference in performance, because dataset is fully deterministic. While for human data, there is a significant drop from 35.3% to 2%. This illustrates that the CVAE objective is crucial when learning from human demonstrations.
我们使用CVAE目标对ACT进行训练,以建模人类演示,这可能是嘈杂的,并包含多模态行为。在这一部分,我们将其与没有CVAE目标的ACT进行比较,后者仅仅在给定当前观察时预测一系列动作,并使用L1损失进行训练。在图8©中,我们可视化了在两个模拟任务中汇总的成功率,并分别绘制了使用脚本数据和使用人类数据进行训练的情况。我们可以看到,在使用脚本数据进行训练时,删除CVAE目标几乎不影响性能,因为数据集是完全确定性的。而对于人类数据,从35.3%下降到2%。这说明CVAE目标在从人类演示中学习时至关重要。
C. Is High-Frequency Necessary?
C. 是否需要高频率?
Lastly, we conduct a user study to illustrate the necessity of high-frequency teleoperation for fine manipulation. With the same hardware setup, we lower the frequency from 50Hz to 5Hz, a control frequency that is similar to recent works that use high-capacity deep networks for imitation learning [7, 70]. We pick two fine-grained tasks: threading a zip cable tie and un-stacking two plastic cups. Both require millimeterlevel precision and closed-loop visual feedback. We perform the study with 6 participants who have varying levels of experience with teleoperation, though none had used ALOHA before. The participants were recruited from among computer science graduate students, with 4 men and 2 women aged 22-25 The order of tasks and frequencies are randomized for each participant, and each participant was provided with a 2 minutes practice period before each trial. We recorded the time it took to perform the task for 3 trials, and visualize the data in Figure 8 (d). On average, it took 33s for participants to thread the zip tie at 5Hz, which is lowered to 20s at 50Hz. For separating plastic cups, increasing the control frequency lowered the task duration from 16s to 10s. Overall, our setup (i.e. 50Hz) allows the participants to perform highly dexterous and precise tasks in a short amount of time. However, reducing the frequency from 50Hz to 5Hz results in a 62% increase in teleoperation time. We then use “Repeated Measures Designs”, a statistical procedure, to formally verify that 50Hz teleoperation outperforms 5Hz with p-value <0.001. We include more details about the study in Appendix E.
最后,我们进行了一项用户研究,以说明对于精细操纵,高频率远程操作的必要性。在相同的硬件设置下,我们将频率从50Hz降低到5Hz,这是一种与最近使用高容量深度网络进行模仿学习的工作类似的控制频率[7, 70]。我们选择了两个需要毫米级精度和闭环视觉反馈的细粒度任务:穿线电缆扎带和解开两个塑料杯子。我们与6名参与者进行了这项研究,他们在远程操作方面具有不同程度的经验,尽管没有人在此之前使用过ALOHA。参与者是计算机科学研究生中的研究员,其中有4名男性和2名女性,年龄在22-25岁之间。每位参与者的任务和频率顺序都是随机分配的,每次试验前都为每位参与者提供了2分钟的练习时间。我们记录了完成3次任务所需的时间,并在图8(d)中可视化了这些数据。平均而言,参与者在5Hz下穿线扎带需要33秒,而在50Hz下减少到20秒。对于分离塑料杯,增加控制频率将任务持续时间从16秒降低到10秒。总体而言,我们的设置(即50Hz)允许参与者在短时间内执行高度灵巧和精准的任务。然而,将频率从50Hz降低到5Hz导致远程操作时间增加了62%。然后,我们使用“Repeated Measures Designs”这一统计程序,正式验证50Hz的远程操作优于5Hz,p值小于0.001。我们在附录E中提供了有关该研究的更多细节。
VI.LIMITATIONS AND CONCLUSION
VI. 限制和结论
We present a low-cost system for fine manipulation, comprising a teleoperation system ALOHA and a novel imitation learning algorithm ACT. The synergy between these two parts allows us to learn fine manipulation skills directly in the realworld, such as opening a translucent condiment cup and slotting a battery with a 80-90% success rate and around 10 min of demonstrations. While the system is quite capable, there exist tasks that are beyond the capability of either the robots or the learning algorithm, such as buttoning up a dress shirt. We include a more detailed discussion about limitations in Appendix F. Overall, we hope that this low-cost open-source system represents an important step and accessible resource towards advancing fine-grained robotic manipulation.
我们提出了一个用于精细操纵的低成本系统,包括远程操作系统ALOHA和一种新颖的模仿学习算法ACT。这两个部分之间的协同作用使我们能够直接在现实世界中学习精细操纵技能,例如以80-90%的成功率打开半透明的调味杯和插入电池,仅需大约10分钟的演示。虽然该系统非常强大,但仍存在一些任务超出了机器人或学习算法的能力,比如系扣衬衫按钮。有关限制的更详细讨论,请参见附录F。总体而言,我们希望这个低成本的开源系统是迈向推动精细操纵的一个重要步骤和可访问的资源。
ACKNOWLEDGEMENT
致谢
We thank members of the IRIS lab at Stanford for their support and feedback. We also thank Siddharth Karamcheti, Toki Migimatsu, Staven Cao, Huihan Liu, Mandi Zhao, Pete Florence and Corey Lynch for helpful discussions. Tony Zhao is supported by Stanford Robotics Fellowship sponsored by FANUC, in addition to Schmidt Futures and ONR Grant N00014-21-1-2685.
我们感谢斯坦福大学IRIS实验室成员对我们的支持和反馈。我们还感谢Siddharth Karamcheti、Toki Migimatsu、Staven Cao、Huihan Liu、Mandi Zhao、Pete Florence和Corey Lynch的有益讨论。Tony Zhao得到了由FANUC赞助的斯坦福机器人学奖学金的支持,此外还得到了Schmidt Futures和ONR Grant N00014-21-1-2685的支持。
APPENDIX
附录
A.Comparing ALOHA with Prior Teleoperation Setups
A. 将ALOHA与先前的远程操作设置进行比较
In Figure 9, we include more teleoperated tasks that ALOHA is capable of. We stress that all objects are taken directly from the real world without any modification, to demonstrate ALOHA’s generality in real life settings
在图9中,我们包括了更多ALOHA能够完成的远程操作任务。我们强调所有对象均直接来自现实世界,没有进行任何修改,以展示ALOHA在真实生活场景中的通用性。
ALOHA exploits the kinesthetic similarity between leader and follower robots by using joint-space mapping for teleoperation. A leader-follower design choice dates back to at least as far as 1953, when Central Research Laboratories built teleoperation systems for handling hazardous material [27]. More recently, companies like RE2 [3] also built highly dexterous teleoperation systems with joint-space mapping. ALOHA is similar to these previous systems, while benefiting significantly from recent advances of low-cost actuators and robot arms. It allows us to achieve similar levels of dexterity with much lower cost, and also without specialized hardware or expert assembly.
ALOHA通过使用关节空间映射实现领导者和跟随者机器人之间的动作相似性。领导者-跟随者的设计选择可以追溯到至少1953年,当时中央研究实验室为处理危险材料构建了远程操作系统[27]。最近,像RE2 [3]这样的公司也构建了具有关节空间映射的高度灵巧的远程操作系统。ALOHA与这些先前的系统相似,但同时受益于低成本执行器和机械臂的最新进展。它使我们能够以更低的成本实现类似的灵巧水平,而且无需专门的硬件或专业的装配。
Next, we compare the cost of ALOHA to recent teleoperation systems. DexPilot [21] controls a dexterous hand using image streams of a human hand. It has 4 calibrated Intel Realsense to capture the point cloud of a human hand, and retarget the pose to an Allegro hand. The Allegro hand is then mounted to a KUKA LBR iiwa7 R800. DexPilot allows for impressive tasks such as extracting money from a wallet, opening a penut jar, and insertion tasks in NIST board #1. We estimate the system cost to be around $100k with one arm+hand. More recent works such as Robotic Telekinesis [53, 6, 45] seek to reduce the cost of DexPilot by using a single RGB camera to detect hand pose, and retarget using learning techniques. While sensing cost is greatly reduced, the cost for robot hand and arm remains high: a dexterous hand has more degrees of freedom and is naturally pricier. Moving the hand around would also require an industrial arm with at least 2kg payload, increasing the price further. We estimate the cost of these systems to be around $18k with one arm+hand. Lastly, the Shadow Teleoperation System is a bimanual system for teleoperating two dexterous hands. Both hands are mounted to a UR10 robot, and the hand pose is obtained by either a tracking glove or a haptic glove. This system is the most capable among all aforementioned works, benefitted from its bimanual design. However, it also costs the most, at at least $400k. ALOHA, on the other hand, is a bimanual setup that costs $18k ($20k after adding optional add-ons such as cameras). Reducing dexterous hands to parallel jaw grippers allows us to use light-weight and low-cost robots, which can be more nimble and require less service.
接下来,我们将ALOHA的成本与最近的远程操作系统进行比较。DexPilot [21]使用人手的图像流来控制一只灵巧的手。它配备了4个校准的Intel Realsense摄像头,用于捕捉人手的点云,并将其姿态转移到Allegro手上。然后,Allegro手被安装到KUKA LBR iiwa7 R800上。DexPilot可以完成一些令人印象深刻的任务,如从钱包中取钱,打开花生酱罐,以及在NIST板#1上进行插入任务。我们估计该系统的成本约为10万美元,包括一个手臂。最近的作品,如Robotic Telekinesis [53, 6, 45],试图通过使用单个RGB摄像头检测手部姿态并利用学习技术进行重新定位,来降低DexPilot的成本。虽然感知成本大大降低,但机器手和机械臂的成本仍然很高:灵巧手具有更多的自由度,因此价格较高。将手移动到不同位置还需要至少2kg有效载荷的工业机械臂,进一步增加了价格。我们估计这些系统的成本约为1.8万美元,包括一个手臂。最后,Shadow Teleoperation System是一个用于远程操作两只灵巧手的双手系统。两只手都安装在UR10机器人上,手部姿态可以通过跟踪手套或触觉手套获得。这个系统是所有上述作品中最强大的,受益于其双手设计。然而,它的成本也是最高的,至少为40万美元。另一方面,ALOHA是一个成本为1.8万美元(添加了可选附件如摄像头后为2万美元)的双手设置。将灵巧手替换为平行爪夹允许我们使用轻量且低成本的机器人,更为灵活,需要更少的维护。
Finally, we compare the capabilities of ALOHA with previous systems. We choose the most capable system as reference: the Shadow Teleoperation System [5], which costs more than 10x of ALOHA. Specifically, we found three demonstration videos [56, 57, 58] that contain 15 example use cases of the Shadow Teleoperation System, and seek to recreate them using ALOHA. The tasks include playing “beer pong”, “jenga,” and a rubik’s cube, using a dustpan and brush, twisting open a water bottle, pouring liquid out, untying velcro cable tie, picking up an egg and a light bulb, inserting and unplugging USB, RJ45, using a pipette, writing, twisting open an aluminum case, and in-hand rotation of Baoding balls. We are able to recreate 14 out of the 15 tasks with similar objects and comparable amount of time. We cannot recreate the Baoding ball in-hand rotation task, as our setup does not have a hand.
最后,我们将ALOHA与先前的系统进行比较。我们选择最强大的系统作为参考:Shadow Teleoperation System [5],其成本超过ALOHA的10倍。具体而言,我们找到了三个演示视频 [56, 57, 58],其中包含了Shadow Teleoperation System的15个示例用例,我们试图使用ALOHA来重新创建它们。任务包括玩“啤酒乒乓球”、“掀翻木块”和魔方,使用簸箕和刷子,扭开水瓶盖,倒出液体,解开尼龙绳束扎,拿起鸡蛋和灯泡,插拔USB、RJ45插头,使用吸管,书写,扭开铝制盒子,以及对宝钢球进行手中旋转。我们能够使用类似的物体和相似的时间完成其中的14个任务。由于我们的设置没有手部,我们无法重新创建宝钢球手中旋转任务。
B.Example Image Observations
B. 示例图像观察
We include example image observations taken during policy execution time in Figure 10, for each of the 6 real tasks. From left to right, the 4 images are from top camera, front camera, left wrist, and right wrist respectively. The top and front cameras are static, while the wrist cameras move with the robots and give detailed views of the gripper. We also rotate the front camera by 90 degrees to capture more vertical space. For all cameras, the focal length is fixed with auto-exposure on to adjust for changing lighting conditions. All cameras steam at 480 × 640 and 30fps.
我们在图10中包含了在执行策略时拍摄的每个真实任务的示例图像观察。从左到右,这4张图片分别来自顶部摄像头、前置摄像头、左手腕和右手腕。顶部和前置摄像头是静态的,而手腕摄像头随机器人移动并提供夹爪的详细视图。我们还将前置摄像头旋转90度,以捕捉更多的垂直空间。对于所有摄像头,焦距是固定的,自动曝光用于调整光照条件。所有摄像头以480 × 640和30fps的速度进行拍摄。

图10:5个真实世界任务的图像观察示例。四列分别是[顶部摄像头,前置摄像头,左手腕摄像头,右手腕摄像头]。我们将前置摄像头旋转90度以捕捉更多的垂直空间。
C.Detailed Architecture Diagram
C. 详细的架构图
We include a more detailed architecture diagram in Figure 11. At training time, we first sample tuples of RGB images and joint positions, together with the corresponding action sequence as prediction target (Step 1: sample data). We then infer style variable z using CVAE encoder shown in yellow (Step 2: infer z). The input to the encoder are 1) the [CLS] token, which consists of learned weights that are randomly initialized, 2) embedded joint positions, which are joint positions projected to the embedding dimension using a linear layer, 3) embedded action sequence, which is the action sequence projected to the embedding dimension using another linear layer. These inputs form a sequence of (k + 2) × embedding_dimension, and is processed with the transformer encoder. We only take the first output, which corresponds to the [CLS] token, and use another linear network to predict the mean and variance of z’s distribution, parameterizing it as a diagonal Gaussian. A sample of z is obtained using reparameterization, a standard way to allow back-propagating through the sampling process so the encoder and decoder can be jointly optimized [33].
我们在图11中包含了更详细的架构图。在训练时,我们首先采样RGB图像和关节位置的元组,以及相应的动作序列作为预测目标(步骤1:采样数据)。然后,我们使用图中显示的CVAE编码器推断样式变量z(步骤2:推断z)。编码器的输入包括:1)[CLS]标记,由随机初始化的学习权重组成,2)嵌入的关节位置,这是通过线性层将关节位置投影到嵌入维度的结果,3)嵌入的动作序列,这是通过另一个线性层将动作序列投影到嵌入维度的结果。这些输入形成了一个(k + 2)×嵌入维度的序列,并与变压器编码器一起处理。我们只取第一个输出,对应于[CLS]标记,并使用另一个线性网络来预测z分布的均值和方差,将其参数化为对角高斯分布。通过重新参数化得到z的样本,这是通过采样过程允许反向传播的标准方式,因此编码器和解码器可以共同优化[33]。
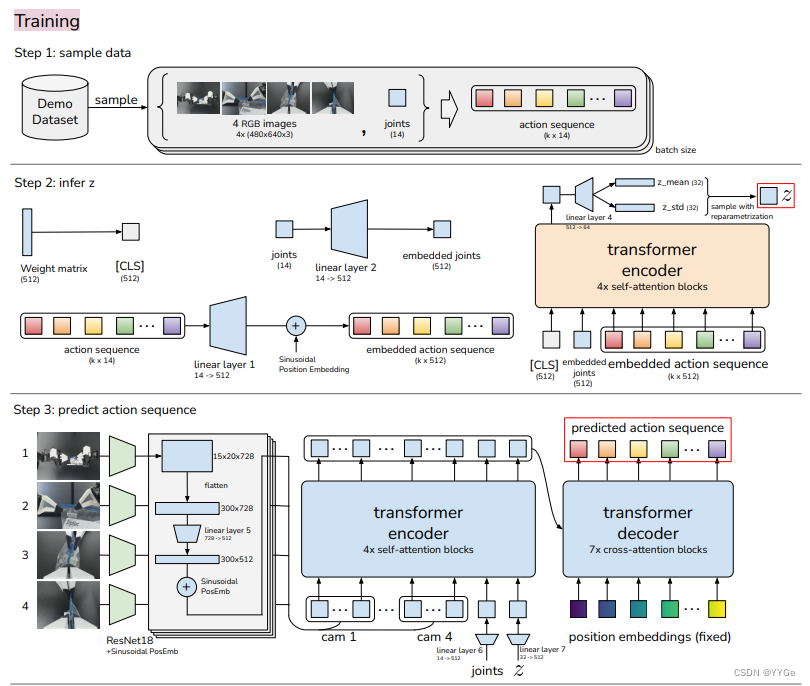
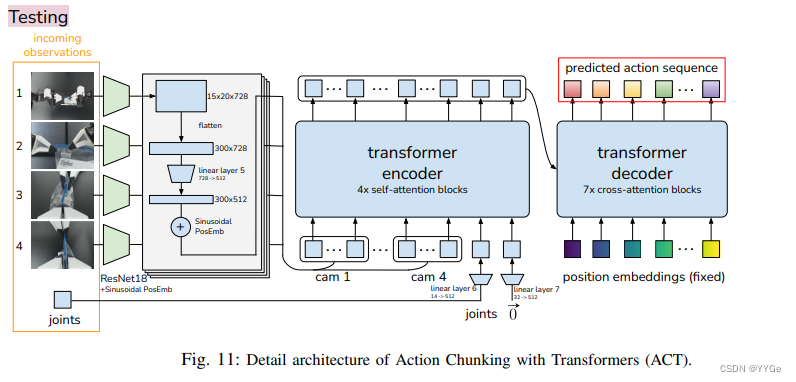
Next, we try to obtain the predicted action from CVAE decoder i.e. the policy (Step 3: predict action sequence). For each of the image observations, it is first processed by a ResNet18 to obtain a feature map, and then flattened to get a sequence of features. These features are projected to the embedding dimension with a linear layer, and we add a 2D sinusoidal position embedding to perserve the spatial information. The feature sequence from each camera is then concatenated to be used as input to the transformer encoder. Two additional inputs are joint positions and z, which are also projected to the embedding dimension with two linear layers respectively. The output of the transformer encoder are then used as both “keys” and “values” in cross attention layers of the transformer decoder, which predicts action sequence given encoder output. The “queries” are fixed sinusoidal embeddings for the first layer.
接下来,我们尝试从CVAE解码器获取预测的动作,即策略(步骤3:预测动作序列)。对于每个图像观察,首先通过ResNet18处理以获取特征图,然后将其展平以获得特征序列。这些特征使用线性层投影到嵌入维度,我们添加一个二维正弦位置嵌入以保留空间信息。来自每个摄像头的特征序列然后被连接以用作变压器编码器的输入。另外两个输入是关节位置和z,它们也分别通过两个线性层投影到嵌入维度。变压器编码器的输出然后用作变压器解码器的交叉注意力层中的“键”和“值”,该层根据编码器输出预测动作序列。对于第一层, “查询” 是固定的正弦嵌入。
At test time, the CVAE encoder (shown in yellow) is discarded and the CVAE decoder is used as the policy. The incoming observations (images and joints) are fed into the model in the same way as during training. The only difference is in z, which represents the “style” of the action sequence we want to elicit from the policy. We simply set z to a zero vector, which is the mean of the unit Gaussian prior used during training. Thus given an observation, the output of the policy is always deterministic, benefiting policy evaluation.
在测试时,CVAE编码器(显示为黄色)被丢弃,而CVAE解码器被用作策略。传入的观察(图像和关节)以与训练期间相同的方式输入模型。唯一的区别在于z,它表示我们希望从策略中引发的动作序列的“风格”。我们简单地将z设置为零向量,这是在训练期间使用的单位高斯先验的均值。因此,给定一个观察,策略的输出始终是确定性的,有利于策略评估。
D.Experiment Details and Hyperparameters
D. 实验细节和超参数
We carefully tune the baselines and include the hyperparameters used in Table III, IV, V, VI, VII. For BeT, we found that increasing history length from 10 (as in original paper) to 100 greatly improves the performance. Large hidden dimension also generally helps. For VINN, the k used when retrieving nearest neighbor is adaptively chosen with the lowest validation loss, same as the original paper. We also found that using joint position differences in addition to visual feature similarity improves performance when there is no action chunking, in which case we have state weight = 10 when retrieving actions. However, we found this to hurt performance with action chunking and thus set state weight to 0 for action chunking experiments.
我们仔细调整了基线,并在表III、IV、V、VI、VII中包含了使用的超参数。对于BeT,我们发现将历史长度从10(与原始论文中相同)增加到100可以显著提高性能。较大的隐藏维度通常也有助于性能提升。对于VINN,在检索最近邻时,我们选择了在验证损失最低的情况下自适应选择的k,与原始论文相同。我们还发现,在没有动作分块的情况下,除了视觉特征相似性外,使用关节位置差异也可以提高性能,在这种情况下,我们在检索动作时将状态权重设置为10。然而,我们发现在进行动作分块实验时,这对性能产生了负面影响,因此在动作分块实验中将状态权重设置为0。
E.User Study Details
E. 用户研究细节
We conduct the user study with 6 participants, recruited from computer science graduate students, with 4 men and 2 women aged 22-25. 3 of the participants had experience teleoperating robots with a VR controller, and the other 3 has no prior experience teleoperating. None of the participants used ALOHA before. To implement the 5Hz version of ALOHA, we read from the leader robot at 5Hz, interpolate in the joint space, and send the interpolated positions to the robot at 50Hz. We choose tasks that emphasizes high-precision and close-loop visual feedback. We include images of the objects used in Figure 12. For threading zip cable tie, the hole measures 4mm x 1.5mm, and the cable tie measures 0.8mm x 3.5mm with a pointy tip. It is initially lying flat on the table, and the operator needs to pick it up with one gripper, grasp the other end midair, then coordinate both hands to insert one end of the cable tie into the hole on the other end. For unstacking cup, we use two single-use plastic cups that has 2.5mm clearance between them when stacked. The teleoperator need to grasp the edge of upper cup, then either shake to separate or use the help from the other gripper. During the user study, we randomize the order in which operators attempt each task, and whether they use 50Hz or 5Hz controller first. We also randomize the initial position of the object randomly around the table center. For each setting, the operator has 2 minutes to adapt, followed by 3 consecutive attempts of the task with duration recorded.
我们进行了一项包括6名参与者的用户研究,这些参与者来自计算机科学研究生,其中有4名男性和2名女性,年龄在22-25岁之间。其中3名参与者有使用VR控制器远程操作机器人的经验,另外3名没有先前的远程操作经验。在研究开始时,没有任何参与者使用过ALOHA。为了实现5Hz版本的ALOHA,我们以5Hz的频率从领导机器人读取数据,在关节空间内进行插值,并将插值位置以50Hz的频率发送到机器人。我们选择强调高精度和闭环视觉反馈的任务。我们在图12中包含了使用的对象的图像。对于穿线拉链束扎,孔的尺寸为4mm x 1.5mm,束扎的尺寸为0.8mm x 3.5mm,具有尖锐的尖端。它最初平放在桌子上,操作者需要用一个夹爪将其抓起,将另一端悬空,然后协调双手将束扎的一端插入另一端的孔中。对于卸垛杯子,我们使用两个一次性塑料杯,当它们叠在一起时,它们之间有2.5mm的间隙。远程操作者需要抓住上杯的边缘,然后摇动以分开它们,或者利用另一夹爪的帮助。在用户研究过程中,我们随机排列运营者尝试每项任务的顺序,以及他们首先使用50Hz还是5Hz控制器。我们还随机化物体的初始位置,使其随机分布在桌子中心周围。对于每种设置,操作者有2分钟的时间适应,然后进行3次连续尝试,记录每次尝试的持续时间。
F.Limitations
F. 限制
We now discuss limitations of the ALOHA hardware and the policy learning with ACT.
我们现在讨论ALOHA硬件和ACT策略学习的限制。
Hardware Limitations. On the hardware front, ALOHA struggles with tasks that require multiple fingers from both hands, for example opening child-proof pill bottles with a push tab. To open the bottle, one hand needs to hold the bottle and pushes down on the push tab, with the other hand twisting the lid open. ALOHA also struggles with tasks that require high amount of forces, for example lifting heavy objects, twisting open a sealed bottle of water, or opening markers caps that are tightly pressed together. This is because the low-cost motors cannot generate enough torque to support these manipulations. Tasks that requires finger nails are also difficult for ALOHA, even though we design the grippers to be thin on the edge. For example, we are not able to lift the edge of packing tape when it is taped onto itself, or opening aluminum soda cans.
在硬件方面,ALOHA在需要双手多个手指的任务上存在困难,例如打开有推动标签的儿童安全药瓶。为了打开瓶子,一只手需要握住瓶子并按下推动标签,另一只手则扭开盖子。ALOHA在需要大量力量的任务上也面临困难,例如提起重物,扭开密封的水瓶,或打开紧密压在一起的记号笔盖。这是因为低成本的电机无法产生足够的扭矩来支持这些操纵。对于需要指甲的任务,即使我们设计夹爪在边缘较薄,ALOHA也面临困难。例如,我们无法在胶带粘在一起时抬起胶带的边缘,或者打开铝制汽水罐。
Policy Learning Limitations.On the software front, we report all 2 tasks that we attempted where ACT failed to learn the behavior. The first one is unwrapping candies. The steps involves picking up the candy from the table, pull on both ends of it, and pry open the wrapper to expose the candy. We collected 50 demonstrations to train the ACT policy. In our preliminary evaluation with 10 trials, the policy picks up the candy 10/10, pulls on both ends 8/10, while unwraps the candy 0/10. We attribute the failure to the difficulty of perception and lack of data. Specifically, after pulling the candy on both sides,the seam for prying open the candy wrapper could appear anywhere around the candy. During demonstration collection, it is difficult even for human to discern. The operator needs to judge by looking at the graphics printed on the wrapper and find the discontinuity. We constantly observe the policy trying to peel at places where the seam does not exist. To better track the progress, we attempted another evaluation where we give 10 trials for each candy, and repeat this for 5 candies. For this protocol, our policy successfully unwraps 3/5 candies.
策略学习的限制。在软件方面,我们报告了ACT未能学习行为的两个尝试的任务。第一个是打开糖果包装。步骤包括从桌子上拿起糖果,拉动两端,然后撬开包装以露出糖果。我们收集了50个演示来训练ACT策略。在我们的初步评估中进行了10次尝试,策略成功地拿起了糖果10/10次,拉动两端8/10次,但未能打开糖果包装0/10次。我们将这一失败归因于感知的难度和数据的不足。具体来说,在两侧拉动糖果后,用于撬开糖果包装的接缝可能出现在糖果的任何位置。在演示数据收集期间,即使对人类来说也很难辨别。操作者需要通过观察包装上的图形并找到不连续性来判断。我们经常观察到策略试图在接缝不存在的地方剥离。为了更好地跟踪进度,我们进行了另一次评估,其中我们为每种糖果提供了10次尝试,并为5种糖果重复了这个过程。按照此协议,我们的策略成功地打开了3/5个糖果的包装。
Another task that ACT struggles with is opening a small ziploc bag laying flat on the table. The right gripper needs to first pick it up, adjust it so that the left gripper can grasp firmly on the pulling region, followed by the right hand grasping the other side of the pulling region, and pull it open. Our policy trained with 50 demonstrations can consistently pick up the bag, while having difficulties performing the following 3 mid-air manipulation steps. We hypothesize that the bag is hard to perceive, and in addition, small differences in the pick up position can affect how the bag deforms, and result in large differences in where the pulling region ends up. We believe that pretraining, more data, and better perception are promising directions to tackle these extremely difficult tasks.
ACT在处理的另一个困难任务是打开平放在桌子上的小拉链袋。右夹爪首先需要将其拿起,调整位置,以便左夹爪可以牢固地抓住拉动区域,然后右手抓住拉动区域的另一侧,并将其打开。我们使用50个演示训练的策略可以始终拿起袋子,但在执行以下3个中空操作步骤时遇到困难。我们推测袋子难以感知,并且另外,拿起位置的微小差异可能会影响袋子的变形方式,并导致拉动区域最终停在何处产生较大差异。我们认为预训练、更多数据和更好的感知是解决这些极具挑战性任务的有前途的方向。

