
热门标签
热门文章
- 1三轴陀螺仪解算姿态(四元数)_陀螺仪四元数
- 2未来10年,最具颠覆性的5大指数型技术(附应用建议)
- 3python验证码 识别代码不准_python 验证码识别示例(二) 复杂验证码识别
- 4【风电功率预测】卷积神经网络结合注意力机制的长短记忆网络CNN-LSTM-Attention风电功率回归预测(多输入单输出)【含Matlab源码 2807期】
- 5【代码管理】Git删除仓库中的大文件压缩仓库大小_git清理大文件
- 6git clone各种类型之间的区别
- 7C++最长连续不重复子序列_c+最长连续不重复子序列
- 8Yolov5之矩形推理_yolov5怎么resize
- 9C++路线(全网20篇高赞文章总结)_c++学习路线
- 10前端安全性问题以及防御措施_前端安全性问题解决方案
当前位置: article > 正文
大模型必备 - 中文最佳向量模型 acge_text_embedding
作者:羊村懒王 | 2024-05-05 20:16:54
赞
踩
大模型必备 - 中文最佳向量模型 acge_text_embedding
近期,上海合合信息科技股份有限公司发布的文本向量化模型 acge_text_embedding 在中文文本向量化领域取得了重大突破,荣获 Massive Text Embedding Benchmark (MTEB) 中文榜单(C-MTEB)第一名的成绩。这一成就标志着该模型将在大模型领域的应用中发挥更加迅速和广泛的影响。

MTEB概述
假设你需要了解如何在家中自制咖啡,可能会在搜索引擎中输入‘家庭咖啡制作方法’。如果没有Embedding模型,传统的引擎会简单地匹配包含关键词的文章,提供一些表面相关的内容而非实用的指南。”团队成员提到,借助Embedding模型,引擎便能更准确地理解用户意图,从而提供包括但不限于选择咖啡豆、磨豆技巧、不同的冲泡方法等更专业的内容。
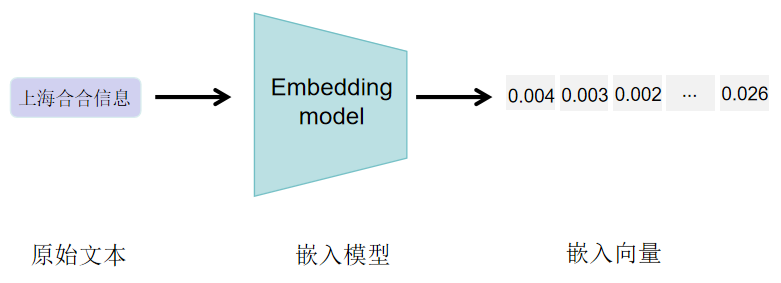
Text Embeddings 文本嵌入是一种将文本转化为包含语义信息的向量表示,因为机器处理信息需要数值输入,因此文本嵌入在许多自然语言处理(NLP)应用中起着至关重要的作用。例如,谷歌就利用文本嵌入来提升其搜索引擎的效能。此外,文本嵌入也可以用于通过聚类发现大量文本中的模式,或作为文本分类模型的输入。然而,文本嵌入的质量高度依赖于所使用的嵌入模型。
为此,Massive Text Embedding Benchmark(MTEB)旨在帮助用户在多种任务中找到最佳的嵌入模型。
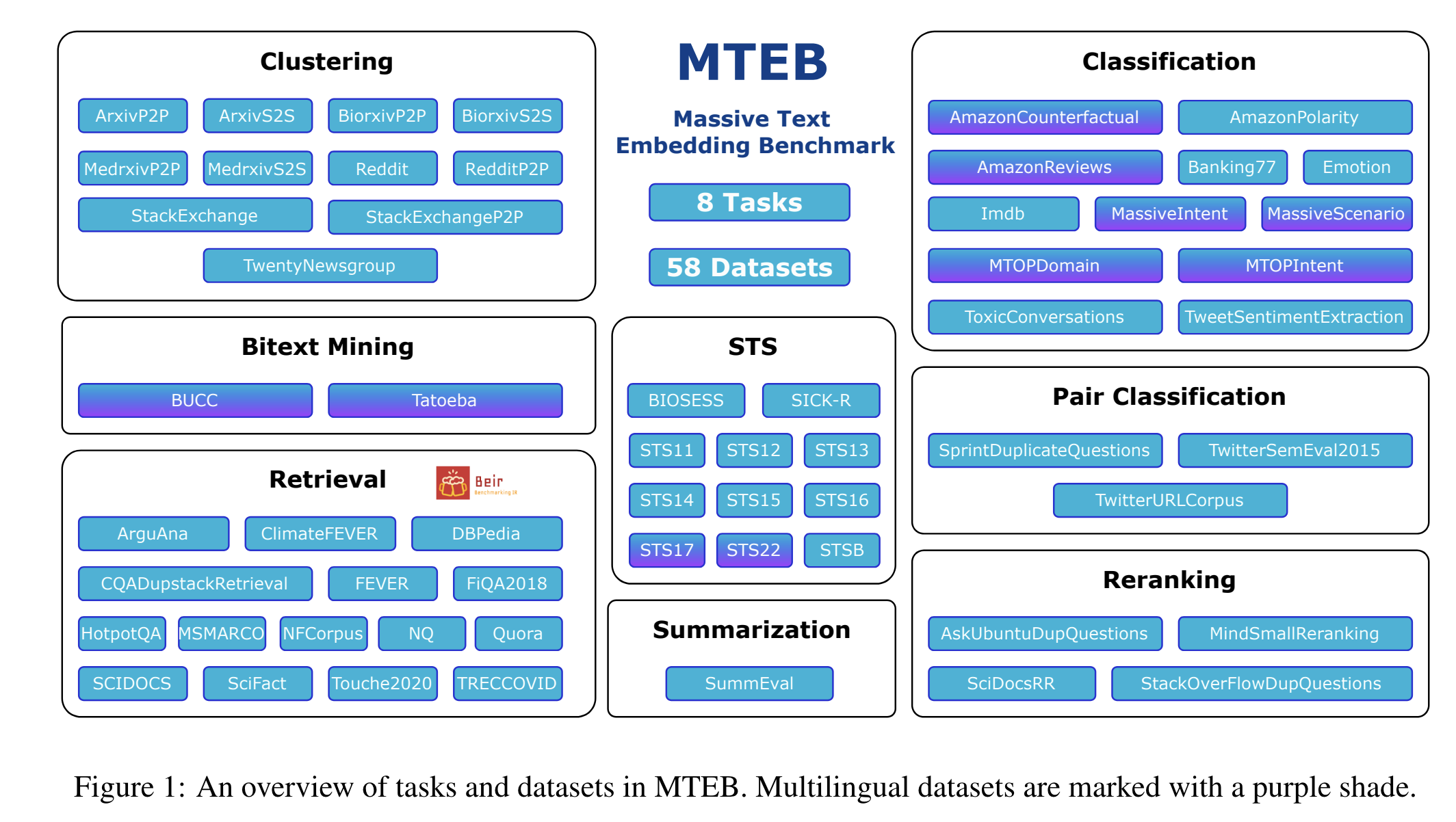
MTEB具备以下特点:
- 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/540636
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

