
- 1使用idea 把一个git分支的部分提交记录合并到另一个git分支上_idea 将一部分提交同步到其他项目
- 2【OpenCV】给图像添加噪声_翻转,切割,增加噪声
- 3python批量命名教程_《自拍教程69》Python 批量重命名音频文件,AV专家必备!
- 4四年背的单词 笔记目录_119.23.244.79:8081/topic/frame/race/login.html
- 5pip安装pandas
- 6Kafka:什么是kafka? ①_kafka kafka
- 7Linux如何创建文件在指定的目录?_在指定目录下创建文件
- 8Unity_VRTK 3.2.1_UI手柄射线检测点击事件的问题_unity htc vrtk 射线 点击ui
- 9YOLOV5源码的详细解读_yolov5代码详解
- 10资深SRE带你看阿里云香港故障_sre故障复盘需要关注的问题
基于ChatYuan-large-v2 微调训练 医疗问答 任务
赞
踩
一、ChatYuan-large-v2
上篇基于ChatYuan-large-v2 语言模型 Fine-tuning 微调训练了广告生成任务,总体生成效果还可以,但上篇文章的训练是微调的模型全部的参数,本篇文章还是以 ChatYuan-large-v2 作为基础模型,继续探索仅训练解码器层参数,并在医疗问答任务上的效果如何。
下面是上篇文章的地址:
二、数据集处理
数据集这里使用 GitHub 上的 Chinese-medical-dialogue-data 中文医疗对话数据集。
GitHub 地址如下:
数据分了 6 个科目类型:
数据格式如下所示:

其中 ask 为病症的问题描述,answer 为病症的回答。
整体加起来数据比较多,这里为了演示效果,只训练 内科、肿瘤科、儿科、外科 四个科目的数据,并且每个科目取前 10000 条数据进行训练、2000 条数据进行验证:
import json
import pandas as pd
data_path = [
"./data/Chinese-medical-dialogue-data-master/Data_数据/IM_内科/内科5000-33000.csv",
"./data/Chinese-medical-dialogue-data-master/Data_数据/Oncology_肿瘤科/肿瘤科5-10000.csv",
"./data/Chinese-medical-dialogue-data-master/Data_数据/Pediatric_儿科/儿科5-14000.csv",
"./data/Chinese-medical-dialogue-data-master/Data_数据/Surgical_外科/外科5-14000.csv",
]
train_json_path = "./data/train.json"
val_json_path = "./data/val.json"
# 每个数据取 10000 条作为训练
train_size = 10000
# 每个数据取 2000 条作为验证
val_size = 2000
def doHandler():
train_f = open(train_json_path, "a", encoding='utf-8')
val_f = open(val_json_path, "a", encoding='utf-8')
for path in data_path:
data = pd.read_csv(path, encoding='ANSI')
train_count = 0
val_count = 0
for index, row in data.iterrows():
ask = row["ask"]
answer = row["answer"]
line = {
"content": ask,
"summary": answer
}
line = json.dumps(line, ensure_ascii=False)
if train_count < train_size:
train_f.write(line + "\n")
train_count = train_count + 1
elif val_count < val_size:
val_f.write(line + "\n")
val_count = val_count + 1
else:
break
print("数据处理完毕!")
train_f.close()
val_f.close()
if __name__ == '__main__':
doHandler()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
处理之后可以看到两个生成的文件:
下面基于上面的数据格式构建 Dataset :
from torch.utils.data import Dataset, DataLoader, RandomSampler, SequentialSampler
import torch
import json
class SummaryDataSet(Dataset):
def __init__(self, json_path: str, tokenizer, max_length=300):
self.tokenizer = tokenizer
self.max_length = max_length
self.content_data = []
self.summary_data = []
with open(json_path, "r", encoding='utf-8') as f:
for line in f:
if not line or line == "":
continue
json_line = json.loads(line)
content = json_line["content"]
summary = json_line["summary"]
self.content_data.append(content)
self.summary_data.append(summary)
print("data load , size:", len(self.content_data))
def __len__(self):
return len(self.content_data)
def __getitem__(self, index):
source_text = str(self.content_data[index])
target_text = str(self.summary_data[index])
source = self.tokenizer.batch_encode_plus(
[source_text],
max_length=self.max_length,
pad_to_max_length=True,
truncation=True,
padding="max_length",
return_tensors="pt",
)
target = self.tokenizer.batch_encode_plus(
[target_text],
max_length=self.max_length,
pad_to_max_length=True,
truncation=True,
padding="max_length",
return_tensors="pt",
)
source_ids = source["input_ids"].squeeze()
source_mask = source["attention_mask"].squeeze()
target_ids = target["input_ids"].squeeze()
target_mask = target["attention_mask"].squeeze()
return {
"source_ids": source_ids.to(dtype=torch.long),
"source_mask": source_mask.to(dtype=torch.long),
"target_ids": target_ids.to(dtype=torch.long)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
三、模型训练
构建训练过程,注意这里只训练解码层参数,因此需要将其他层的参数进行冻结:
# 只训练解码层
for name, param in model.named_parameters():
if "decoder" not in name:
param.requires_grad = False
- 1
- 2
- 3
- 4
整体训练过程如下:
# -*- coding: utf-8 -*-
import pandas as pd
import torch
from torch.utils.data import DataLoader
import os, time
from transformers import T5Tokenizer, T5ForConditionalGeneration
from gen_dataset import SummaryDataSet
def train(epoch, tokenizer, model, device, loader, optimizer):
model.train()
time1 = time.time()
for _, data in enumerate(loader, 0):
y = data["target_ids"].to(device, dtype=torch.long)
y_ids = y[:, :-1].contiguous()
lm_labels = y[:, 1:].clone().detach()
lm_labels[y[:, 1:] == tokenizer.pad_token_id] = -100
ids = data["source_ids"].to(device, dtype=torch.long)
mask = data["source_mask"].to(device, dtype=torch.long)
outputs = model(
input_ids=ids,
attention_mask=mask,
decoder_input_ids=y_ids,
labels=lm_labels,
)
loss = outputs[0]
# 每100步打印日志
if _ % 100 == 0 and _ != 0:
time2 = time.time()
print(_, "epoch:" + str(epoch) + "-loss:" + str(loss) + ";each step's time spent:" + str(
float(time2 - time1) / float(_ + 0.0001)))
optimizer.zero_grad()
loss.backward()
optimizer.step()
def validate(tokenizer, model, device, loader, max_length):
model.eval()
predictions = []
actuals = []
with torch.no_grad():
for _, data in enumerate(loader, 0):
y = data['target_ids'].to(device, dtype=torch.long)
ids = data['source_ids'].to(device, dtype=torch.long)
mask = data['source_mask'].to(device, dtype=torch.long)
generated_ids = model.generate(
input_ids=ids,
attention_mask=mask,
max_length=max_length,
num_beams=2,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in
generated_ids]
target = [tokenizer.decode(t, skip_special_tokens=True, clean_up_tokenization_spaces=True) for t in y]
if _ % 100 == 0:
print(f'Completed {_}')
predictions.extend(preds)
actuals.extend(target)
return predictions, actuals
def T5Trainer(train_json_path, val_json_path, model_dir, batch_size, epochs, output_dir, max_length=300):
tokenizer = T5Tokenizer.from_pretrained(model_dir)
model = T5ForConditionalGeneration.from_pretrained(model_dir)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 只训练解码层
for name, param in model.named_parameters():
if "decoder" not in name:
param.requires_grad = False
train_params = {
"batch_size": batch_size,
"shuffle": True,
"num_workers": 0,
}
training_set = SummaryDataSet(train_json_path, tokenizer, max_length=max_length)
training_loader = DataLoader(training_set, **train_params)
val_params = {
"batch_size": batch_size,
"shuffle": False,
"num_workers": 0,
}
val_set = SummaryDataSet(val_json_path, tokenizer, max_length=max_length)
val_loader = DataLoader(val_set, **val_params)
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-4)
for epoch in range(epochs):
train(epoch, tokenizer, model, device, training_loader, optimizer)
print("保存模型")
model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
# 验证
with torch.no_grad():
predictions, actuals = validate(tokenizer, model, device, val_loader, max_length)
# 验证结果存储
final_df = pd.DataFrame({"Generated Text": predictions, "Actual Text": actuals})
final_df.to_csv(os.path.join(output_dir, "predictions.csv"))
if __name__ == '__main__':
train_json_path = "./data/train.json"
val_json_path = "./data/val.json"
model_dir = "chatyuan_large_v2"
batch_size = 5
epochs = 5
max_length = 300
output_dir = "./model"
T5Trainer(
train_json_path,
val_json_path,
model_dir,
batch_size,
epochs,
output_dir,
max_length
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
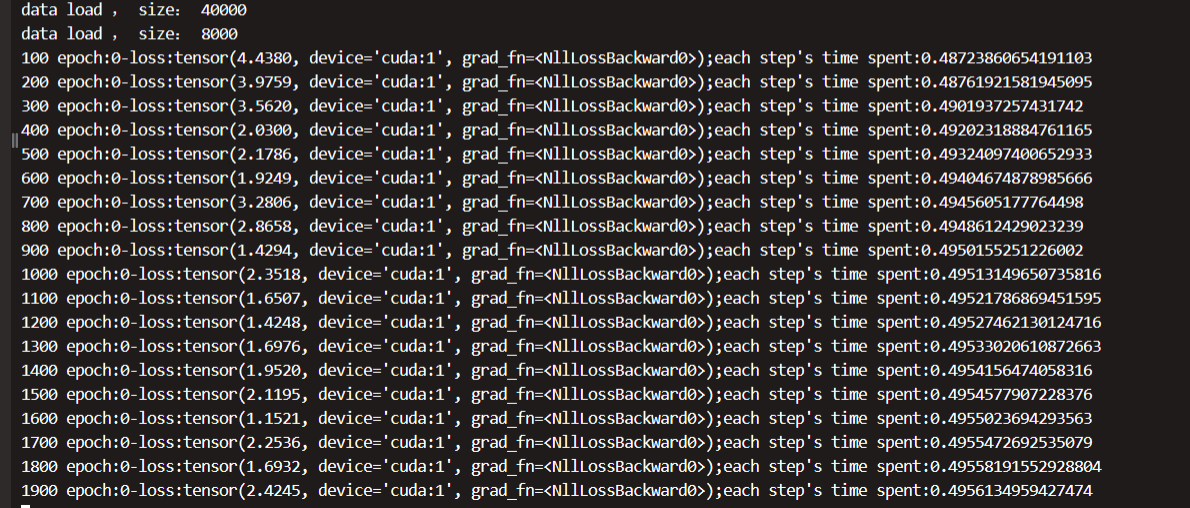
运行后可以看到如下日志打印,训练大概占用 21G 的显存,如果显存不够可以调低些 batch_size 的大小:
等待训练结束后:
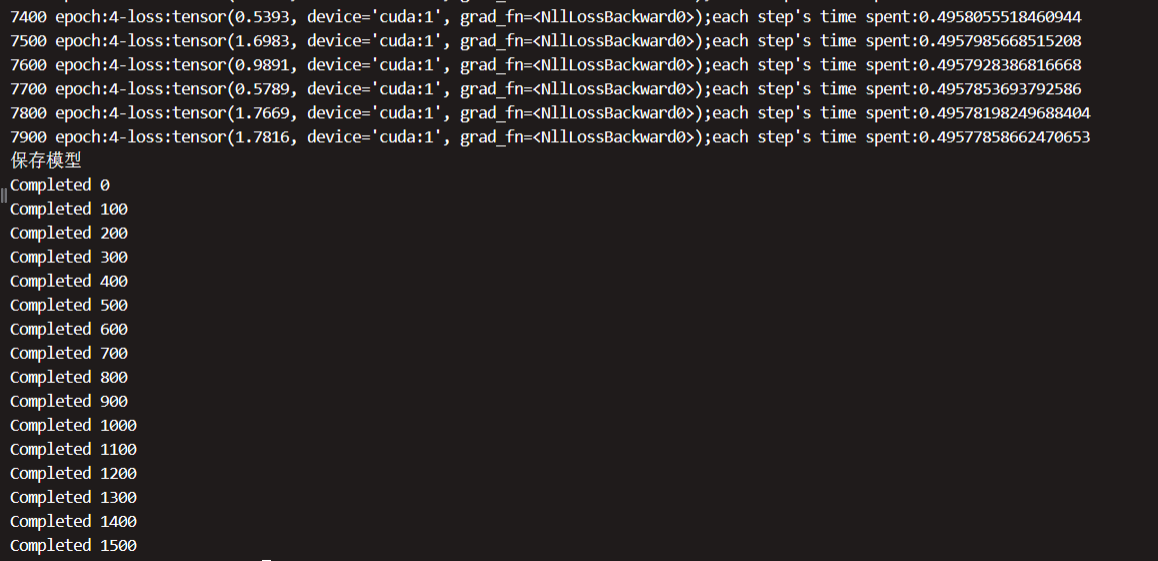
可以在 model 下看到保存的模型:
这里可以看到 predictions.csv 验证集的效果:

四、模型测试
# -*- coding: utf-8 -*-
from transformers import T5Tokenizer, T5ForConditionalGeneration
import torch
# 这里是模型下载的位置
model_dir = './model'
tokenizer = T5Tokenizer.from_pretrained(model_dir)
model = T5ForConditionalGeneration.from_pretrained(model_dir)
while True:
text = input("请输入内容: \n ")
if not text or text == "":
continue
if text == "q":
break
encoded_input = tokenizer(text, padding="max_length", truncation=True, max_length=300)
input_ids = torch.tensor([encoded_input['input_ids']])
attention_mask = torch.tensor([encoded_input['attention_mask']])
generated_ids = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_length=300,
num_beams=2,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
reds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in
generated_ids]
print(reds)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
1. 我准备过两天去看我叔叔,顺便带些人参,但是他有高血压,您好人参高血压可以吃吗?
模型回答:
人参具有补气的药物,高血压患者是可以吃人参的,但是需要有在医生的指导下口服,不能够盲目的口服,以免引来血压升高,平时要留意低盐低脂饮食,多吃许多新鲜的蔬菜和水果,不要熬夜,确保充足的深度睡眠,防止情绪震荡太大,不要生气或者是发火。调节身心健康,保持自身卫生.避免因抵抗力下降而导致细菌入侵。

2. 检测报告单五项指标乙肝表面抗原结果为阳性,抗体结果为阴性,e抗原为阳性e抗体为阴性,核心抗体为阳性。要有打预防工作疫苗么?
模型回答:
乙肝表面抗原阳性,抗体结果为阴性,e抗原为阳性,e抗体为阴性,核心抗体为阳性,证明既往传染过乙肝病毒,现在已经康复了,并且产生了保护性抗体。建议你到医院检查一下肝功能和HBV-DNA,如果都正常的话,就用不着打预防工作疫苗了,平时多留意歇息,别加班,别喝啤酒,不定期复检就可以了。患者直面乙肝困恼,我们应当积极采用救治措施,不要避忌就诊,如果乙肝久治不愈,那么就要及时对换治疗方案。

3. 男孩,11岁,上小学了,这一周,孩子一直扣耳朵,说痒,另外,偶尔还会有黄色的液体流出,另外,伴有一些低烧,请问:孩子中耳炎流黄水怎样治疗。
模型回答:
抗生素和消炎药是目前临床治疗小儿中耳炎的方法和药物,家长可对症进行选择,也可局部用药,比如给宝宝采取使用消炎类型的滴耳剂,孩子如果是以耳痛的症状为主的话,建议家长是可以适当的给点镇痛药缓解的,要是伴随发高烧的情况,那么根据孩子的症状使用药物,严重的情况请尽快去医院进行救治,以上方法都是目前治疗中耳炎比较常用的,此外要是出现耳膜穿孔的情况是需要及时的进行手术治疗的,与此同时也要注意给孩子安排合理的饮食和作息习惯,帮助疾病尽早康复。

4. 我家宝宝最近不知晓为什么脸上再次出现了湿疹的情况,而且好象还蛮严重的,宝宝看上去也不舒服,请问婴儿全身长湿疹怎么办
模型回答:
婴儿全身长湿疹,建议你先带孩子去正规的医院仔细检查下,根据医生指导恰当对症救治。平时要留意护理好孩子,始终保持皮肤的清洁干燥,防止搔抓,以免严重病情。患者日常要养成良好的生活习惯,规律作息,禁烟酒,多增加日常锻炼以此来提高患者免疫力,避免病情复发。

5. 我对我的身体情况一直都是比较重视的,所以隔段时间就会抽时间去了一医院检查一下,近来的时候患有了小肠气,小肠气是什么样的一种疾病,小肠气到哪治?
模型回答:
你好,您的情况是检查确诊疝气。需要手术治疗。疝气是临床上比较常见的疾病。多是由于腹壁存在薄弱环节,腹腔内压力增高引起。主要症状是腹部可复性肿物。直立或者腹内压增加肿物突出,平卧可以消失或者回纳。这种情况需要积极手术治疗。开腹手术或者腹腔镜微创手术都可以。同时避免腹内压增加因素,比如咳嗽,便秘,弯腰提重物,剧烈运动等,以免发生嵌顿或者术后复发。


