
- 1proxy(代理)用法_proxy()
- 2队列的链式表示和实现(C语言)_(1)定义一个整形的单链表队列。 (2)编写实现进队、出队、显示队元素等所有基本函
- 3windows7 系统Jenkins默认用户名,密码_jenkins window本地部署默认用户名和密码
- 4深度学习环境搭建中python、torch、torchvision、torchaudio、cuda的安装_torch-torchvision-python安装
- 5R语言系统教程(七):数据的分布(含多种图的绘制)_如何用r语言制作数据分布
- 6FPGA之多路复选器1
- 7【S32K】S32K144入门笔记(3) SPI(lpspi组件)_s32k144 如何缩短两个连续spi的间隔
- 8Unity 3D动态修改Shader状态,使物体透明等等_untiy 代码设置shader,并解决在手机上透明效果不对的问题
- 9结构体struct的定义和使用_struct定义
- 10python解最强大脑: 黑白迭代_最强大脑黑白重叠游戏原理
GPT/GP2/GPT3_gpt123区别
赞
踩
李沐的论文精读视频讲解的很好,我这里也只是做一些记录,看到GPT3以及衍生的一些应用,还是很震惊的,文本领域的预训练已经做到这种程度了,zero-shot、one-shot、few-shot还是真正能够落地的,在图像领域目前确实没有这样出众的工作。
GPT1用的解码的transformers,和bert用的编码的transformers是不同的,后者是双向的,前者是单向的,整体的架构还是pretraining+fine-tune的思路,bert也是这个思路,都是要在下游任务做fine-tuning的。

上图是如何迁移的任务的设计,这块还是挺有意思的,就是对现有任务进行一个任务的转换,比如第一个分类任务start+文本+extra之后的向量输入到transformers中,再送入线性分类器,比如十类,线性分类器的输出就是十类,然后得到最终的结果。
GPT2相对于GPT相对于bert之后想出来的一个升级版本,核心再zero-shot,不再下游做fine-tuning了,这是一个很好的思路,看GPT就是感觉作者强在不用在下游任务做fine-tuning,看起来更像是强人工智能了。GPT相较于bert和gpt1,参数更大,数据量更高,模型也更大。
GPT3的参数量进一步扩大,目前市面上很多的应用基于GPT3,比如微软的Copilot等等,在下游的子任务中是不需要更新梯度的,使用了few-shot的方法,one-shot就是给了一个正样本,few-shot就是将下游的仅有的一些提示组成一个长的序列进行判定,GPT3有1750亿参数,自己想训练肯定是不可能的,后续看看有没有白嫖的中文大模型拿来试试效果。
使用预训练好的语言模型,在进行微调,微调需要每个任务有一个任务相关的数据集以及和任务相关的微调,需要一个大的数据集并进行标号,当一个样本没有出现在数据分布中的时候,泛化性不见得比小模型好,当然了大模型的训练数据足够多,few-shot感觉有点像做语义检索的味道,在以训练的数据中找到了下游子任务的答案,然后输出,在copilot中的输出就有类似的案例,而且GPT3的网络训练数据更大。
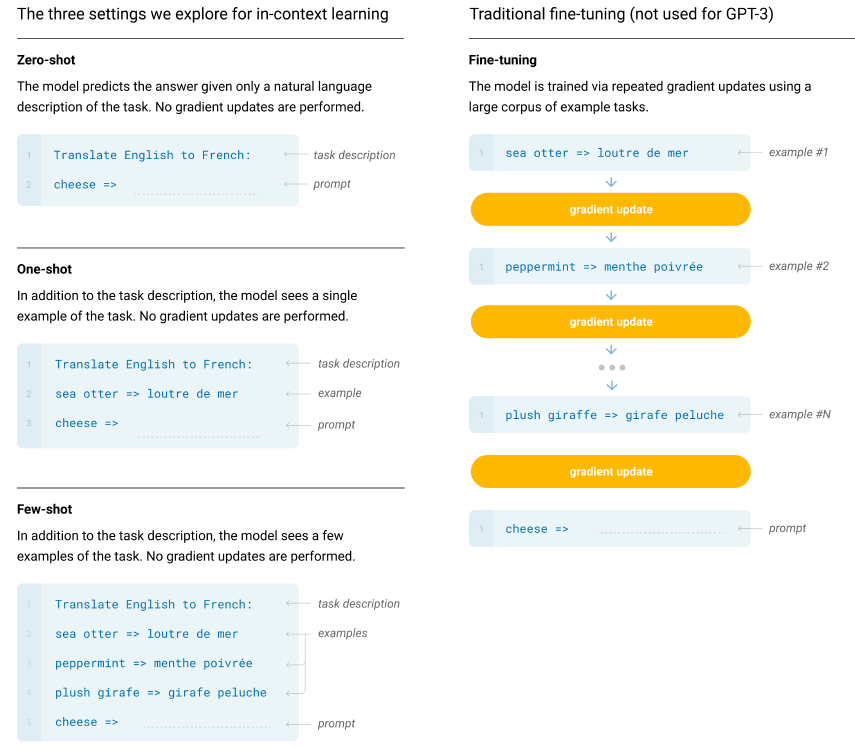
上图中左边提供了one-shot/few-shot/zero-shot的形式,GPT提出了一种in-context learning,给出任务的描述和一些参考案例的情况下,模型能根据当前的任务描述、参数案例明白到当前的语境,即使在下游任务和预训练的数据分布不一致的情况下,模型也能表现的很好,GPT没有利用示例进行fine-tuning,而是让示例成为输入的指导,帮助模型更好的完成任务。
在zero-shot的设置条件下:先给出任务的描述,之后给出一个测试数据对其进行测试,直接让预训练好的模型去进行任务测试。
在one-shot的设置条件下:在预训练和真正翻译的样本之间,插入一个样本做指导。好比说在预训练好的结果和所要执行的任务之间,给一个例子,告诉模型英语翻译为法语,应该这么翻译。
在few-shot的设置条件下:在预训练和真正翻译的样本之间,插入多个样本做指导。好比说在预训练好的结果和所要执行的任务之间,给多个例子,告诉模型应该如何工作。

