
- 1通过CDN使用Vue_通过 cdn 使用 vue
- 2SpringBoot 26 分布式和RPC_springboot rpc
- 3项目前端结合node部署_node部署前端项目
- 4centos部署python flask_用Dockerfile部署你的Flask Web应用
- 5如何在Linux运行RStudio Server并实现Web浏览器远程访问_linux远程浏览器
- 6Unity 脚本编译完成检测_unity 判断脚本生成完毕
- 7【STM32 HAL库实战】串口DMA + 空闲中断 实现不定长数据接收_hal_uartex_receivetoidle_dma
- 8unity中3dUI始终面向摄像机,跟随摄像机视角旋转而旋转_unity ui摄像机
- 9计算机网络学习笔记(汇总)_计算机网络笔记整理
- 10不使用+或-运算符,计算两数之和
不知道如何提高视觉语言大模型?浙大与联汇研究院提出新型多维度评测框架...
赞
踩

前言
视觉语言预训练(VLP)模型最近成功地促进了许多跨多模态的下游任务。大多数现有工作通过比较微调的下游任务性能来评估其系统。然而,只有平均下游任务精度很难评判一个 VLP 模型的优点和缺点。另外,下游任务千千万万,相信很多小伙伴们和我一样,对众多下游任务了解不多,更不用说用具体的下游任务去评测模型啦。今天就给大家安利一款不需要下游任务也能评测预训练模型的工具吧,感兴趣的小伙伴们赶紧去文末上手试用吧!

为什么需要一个统一的评测工具?
视觉语言预训练是多机器学习研究的一项基本任务。最近,由于多模态 Transformer 的出现和大型匹配图像文本语料库的可用性,VLP 取得了快速进展。许多的 VLP 模型有助于实现各种下游多模态任务的最先进性能,包括视觉 QA、多模态检索、视觉 Grounding 等。另一方面,当前评估 VLP 模型的实际方法是通过比较其微调的下游任务性能。然而,基于下游任务的基准 VLP 模型有许多局限性:
1. 可解释性差:下游任务很复杂,依赖于许多相互交织的能力,因此它只提供一个黑盒子得分,很难解释。例如,目前仍然不清楚如何改进在视觉 QA 方面表现出色但在图像检索中表现不佳的 VLP 模型。
2. 不可比较的结果:不同的工作可能会选择不同的任务进行评估,这使得比较困难。这是因为一些 VLP 模型与某些任务不兼容,例如 CLIP 无法直接针对视觉 QA 进行微调。
3. 数据偏置:下游数据分布不全面,因此实际性能可能被高估。此外,不能知道模型是否对输入噪声具有鲁棒性,例如用同义词替换动词。
既然基于下游任务的评测方法有这么多局限性,那有没有什么办法来解决呢?那当然有啦!本文就提出了 VL-CheckList 方法,这是一个可解释的框架,全面评估 VLP 模型,有助于加深理解并激发新的改进想法。VLCheckList 的核心原则主要有三点:
1. 评估VLP模型的基本能力,而不是下游应用的性能:基于这一点,作者选择图像文本匹配(ITM)作为主要评估目标,因为它可能是所有VLP方法中最有效的预训练目标。
2. 将能力分解为更易于分析的相对独立的变量:基于这一点,作者提出了一种分类法,将 VLP 系统的功能分为三类:对象、属性和关系。然后将每个类进一步划分为更细粒度的变量,例如属性由颜色、材料和大小等组成。
3. 语言感知的负样本采样策略,以创建难例负样本:这用于验证 VLP 模型对输入空间中微小变化的识别能力。
最后,基于以上几点,作者提出了预训练模型的测评工具 VL-CheckList,研究者都可以轻松地插入他们的评估预训练模型。在本文中,作者通过分析 7 种流行的 VLP 模型验证了所提出的方法,包括双编码器模型、基于区域的 VLP 模型和端到端 VLP 模型。作者采用了四个数据集(VG、SWIG、VAW 和 HAKE)来生成能力特定评估测试集。
实验结果揭示了一些关于这些模型的有趣见解(心急的小伙伴可以先跳到实验部分看看这些见解吧),这些见解很难从下游任务分数中获得。本文的研究表明,与端到端方法相比,基于区域的方法在谓语推理中的性能更强;交叉注意力模型优于双编码器,尤其是对于较小和边缘对象。(大家可以在“评测结果”这一节中看到更多的有意思的结果哦!)

这个评测工具内部是怎么运行的呢?
VLP 最关键的特点是其多模态数据的对齐能力。评估多模态的直观方法之一是检查模型是否正确预测不同模态之间的对齐。为了评估视觉和语言之间的多模态,作者选择图像-文本匹配(ITM),原因如下:首先,ITM 损失通常是所有 VLP 模型中最有效和最普遍的。其次,ITM 也是模型不可知的,适用于所有融合架构。因此,作者选择使用 ITM 公平地比较 VLP 模型,而无需将其调整到下游任务。
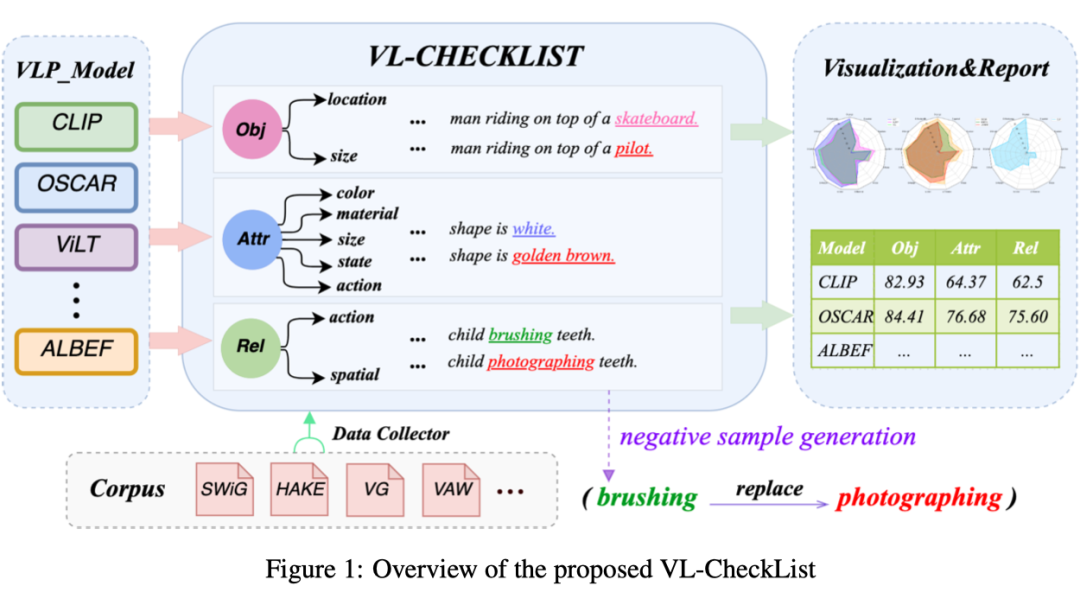
VL-CheckList 的总体流程描述如上图所示,具体来说分为以下几步:
(1)通过将样本分类为三个类(对象、属性和关系)来转换图像-文本配对数据集。
(2)重写每个图像的成对文本,以生成每个类的负样本。
(3)使用 VLP 模型的 ITM 头来区分给定图像的正文本和负文本。
(4)生成各方面模型的综合分析报告。
2.1 VL-CheckList的分类
评估类型通常根据常见错误或频繁使用来选择。基于 VLP 模型中的常见问题,该框架将三个输入属性(对象、属性和关系)作为评估分类的顶层。
2.1.1 对象
一个强大的 VLP 模型应该能够识别文本中提到的对象是否存在于图像中。因此,如果用其他一些随机名词短语替换正确文本中的宾语,VLP 模型的 ITM 分数应该低于原始句子。此外,一个强大的 VLP 模型应该能够识别物体的存在,无论其位置和大小。因此,通过测试位置不变性(例如,中心、中间和边缘)和大小不变性(例如,小、大、中)来进一步评估鲁棒性对象 ITM,具体如下:

其中,是完整图像的对角线的一半长度。 是它的中心点和整个图像的中心点之间的距离。
为了获得对象的大小,作者使用了对象区域信息(即高度的边界框乘以宽度)。

其中,, S 表示小尺寸,M 表示中等尺寸。本文设置 S=1024,M=9216。
2.1.2 属性
确定任何物体的特定属性都是非常具有挑战性的。如果替换了文本中的正确属性,则一个视觉语言预训练模型的 ITM 头应分配较低的分数。属性通常包含颜色、材质、大小、状态和动作。
大小:用另一个替换大小表达式,如 small、big 和 medium。(例如,大苹果和小苹果)。
材料:替换句子中的材料词(例如,金属盒与木盒)。
状态:替换状态表达,例如干净、新鲜(例如,一个头发干的男人与一个头发湿的男人)。
动作:替换文本中与动作相关的单词(例如,站着的人与坐着的人)。
颜色:替换文本中的颜色词(例如,红苹果和绿苹果)。
2.1.3 关系
关系关注两个对象之间的交互。它包括在三元组中替换谓词(例如,主语、谓词、宾语),其中主语和宾语都是图像中的对象。强大的 ITM 头应该为匹配成对对象交互的文本分配更高的分数。此外,作者将预测分为空间预测和动作预测。如果谓词是空间介词之一(例如 in、on、at 等),则将其细分为“空间”,否则将其标记为“动作”。
空间:模型可以预测两个对象之间的空间关系(例如,<cat,on,table> 与 <cat,under,table>)。
动作:模型可以预测空间介词以外的其他关系,通常是动作动词,如 run、jump、kick、eat、break、cry 或 smile(例如,<cat,catch,fish> 与 <cat,eat,fish>)。
2.2 负采样生成
负采样生成是对原始文本描述的一组转换。提出的 VL-CheckList 侧重于方向性期望测试,在该测试中,标签预计会以某种方式发生变化。例如,照片中有一只黑熊,文字描述为“一只黑熊拿着一根棍子”。可以应用集中变换(例如,<一只黑熊→ 一只红熊>,<一根棍子→ 一个苹果>,<拿着→ 投掷>,等等)。负采样策略是无偏评估的关键步骤。
为了生成难例负样本,作者使用结构化文本描述数据集,例如 Visual Genome(VG)、SWiG 和 Human Activity Knowledge Engine(HAKE)。VG 提供属性、关系和区域图,这些图可以通过替换图像中关系中的一个属性来生成难例样本。SWiG 数据集提供图像及其角色的结构化语义摘要。通过替换文本描述中的一个角色来生成难例负样本,使其与图像不匹配。HAKE 数据集提供了实例活动和身体部位状态之间的关系。
对于 VG 数据集,作者首先根据句子 Transformer 中的余弦相似性将每个属性、对象和关系分配给对应类型。对于对象和关系,作者以 0.5 的余弦相似阈值随机采样相应的实例。对于属性,作者从同一属性类中随机抽取一个对应实例,其余弦相似性阈值为 0.5。

这个评测工具的评测指标是什么?
本文的方法返回文本描述和生成的负样本之间的模型输出分数。如果原始文本描述上的模型分数高于生成的负样本上的分数,将其视为正输出。精度(acc)计算如下:
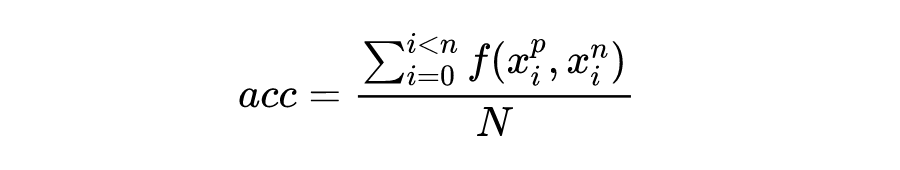
其中,如果 ,则 ,否则为 0。 表示第 i 个数据的正样本。 表示第 i 个数据的正样本。N 是正样本和负样本对的总数。 是第 I 个图像数据。

评测工具能评测哪些预训练模型?
理论上讲呢,VL-CheckList 能够评测所有预训练模型。在文章中,作者也是将目前的预训练模型分为了三类,并选择了其中的代表模型进行评测。感兴趣的小伙伴也可以在代码开源之后,测测更多的预训练模型吧。下面我们就来介绍一下,作者在文中测了哪些模型吧!
4.1 双编码器
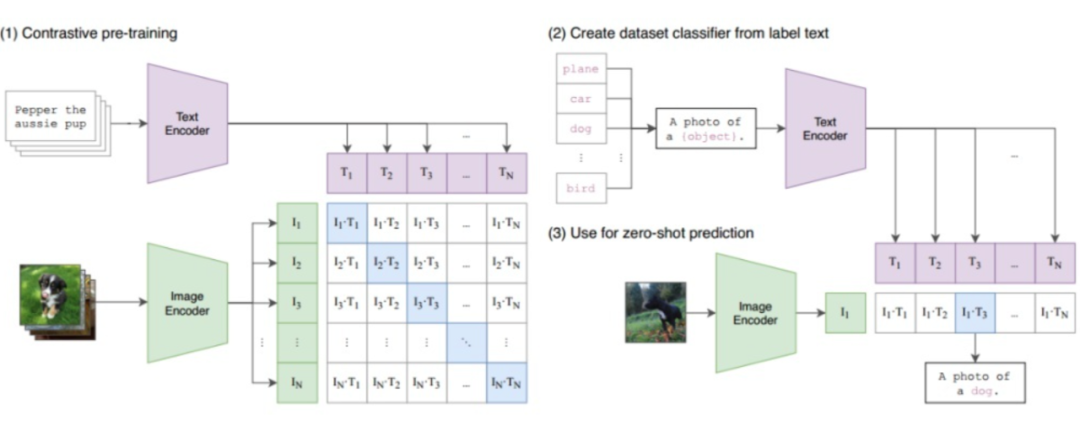
CLIP(模型结构见上图)在具有对比目标的 4 亿对(图像、文本)数据集上进行训练。CLIP 是一个简单的模型,其中两个 transformers 独立编码图像和文本。ITM 分数是两个嵌入之间的余弦距离。尽管 CLIP 结构简单,但它在许多下游任务中都取得了优异的性能。
4.2 基于区域的交叉注意力模型
这类模型的共同特点是,输入图像通过现成的对象检测器来获得显著的对象和区域特征。
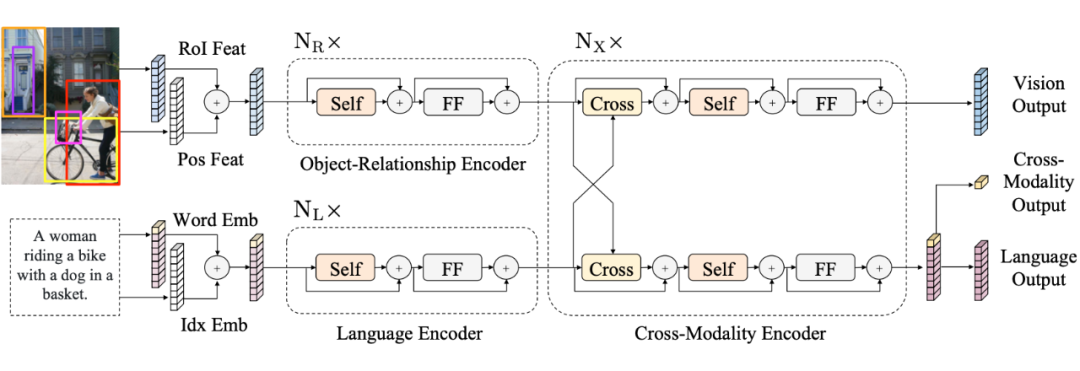
LXMERT(模型结构见上图)是一个具有三个 Transformer 的双流模型。对象关系编码器对输入对象及其位置进行编码;BERT 编码器对文本进行编码;跨模态编码器融合了这两种模态。该模型用 ITM 和其他三个目标进行了预训练。
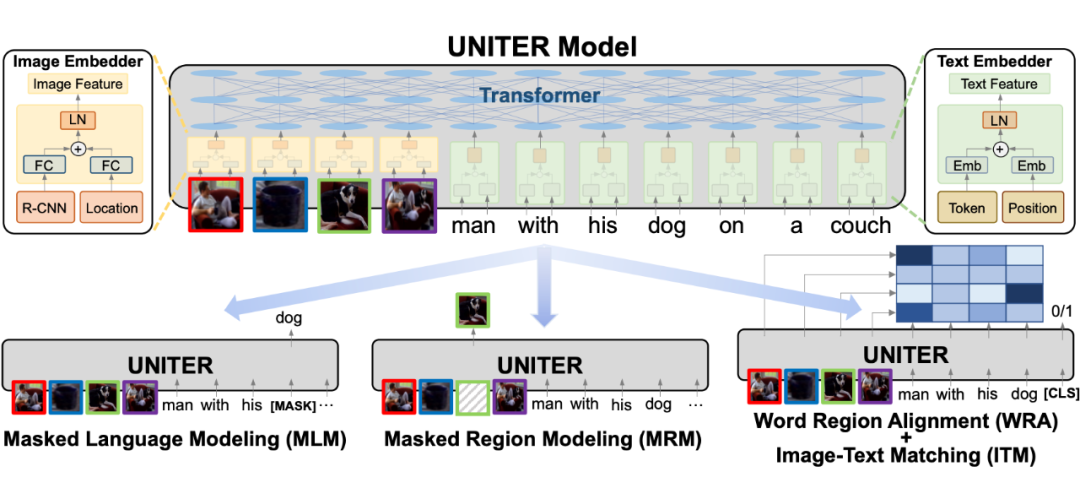
UNITER(模型结构见上图)是一个单流模型,预训练有四个目标。UNITER 与 LXMERT 的不同之处在于其单流设计,其中共享的 Transformer 在早期阶段融合了视觉和语言信息。
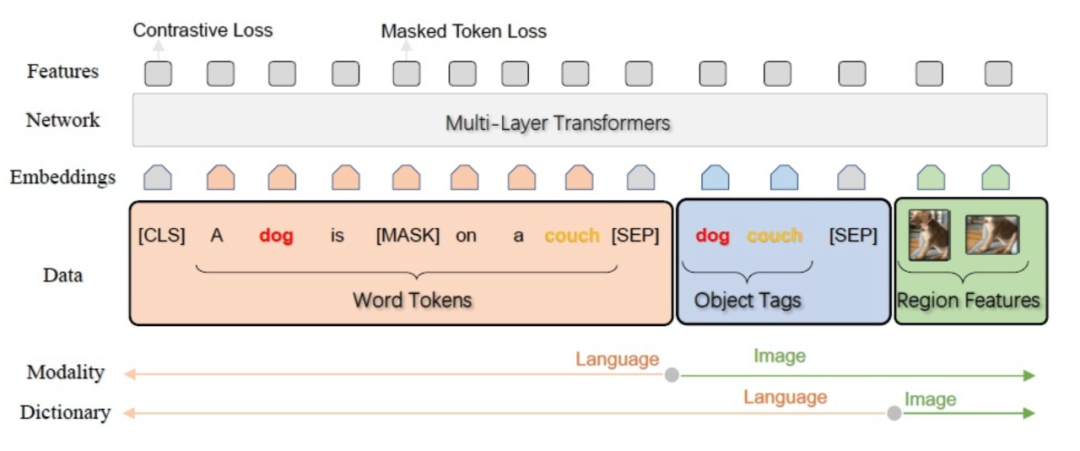
OSCAR(模型结构见上图)是一个单流模型,在 650 万个文本图像标签三元组上使用 mask token 损失和对比损失进行训练。其独特之处在于:(1)具有更好的对象检测器,能够识别更多类型(2)包括以图像和文本作为输入特征的对象 tag。
4.3 端到端交叉注意力模型
这类模型通过直接编码图像,端到端模型不依赖于目标检测器。
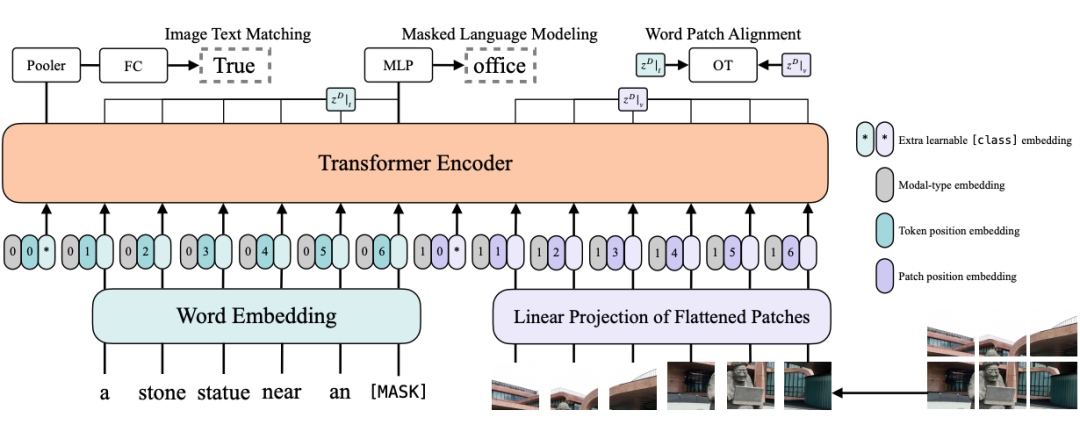
ViLT(模型结构见上图)是一种有效的单流模型。输入图像被分割成小 patch 并与文字连接。然后,Transformer 对组合序列进行编码。ViLT 是第一个在不使用区域特征的情况下实现良好性能的 VLP 模型。
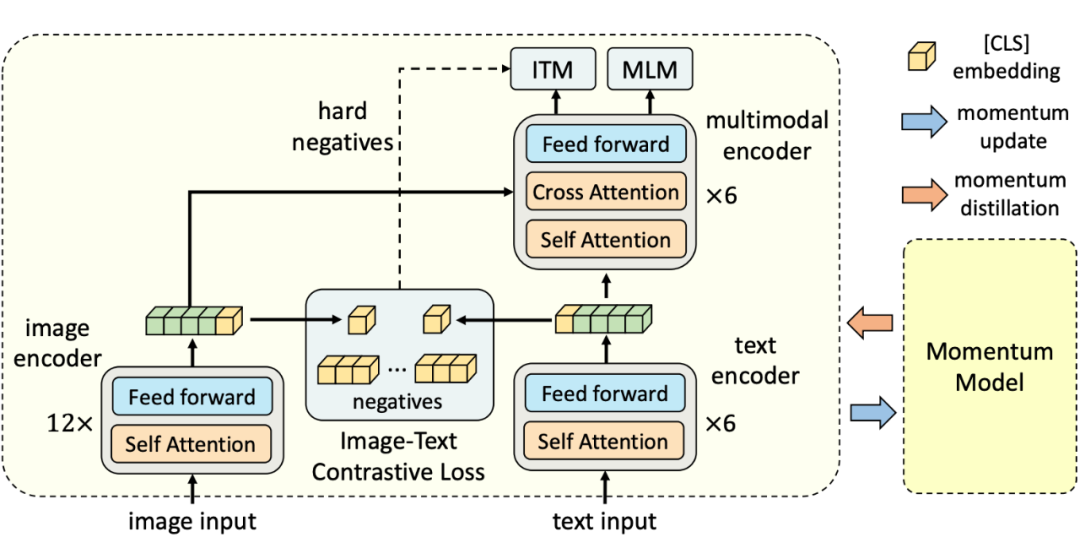
ALBEF(模型结构见上图)是一种双流模型。文本和图像分别通过 RoBERTa 和 ViT 进行编码。然后使用跨模态 Transformer 来融合这两种模态。此外,为了从噪声图像-文本对中学习更好的表示,ALBEF 从动量模型产生的伪目标中学习。
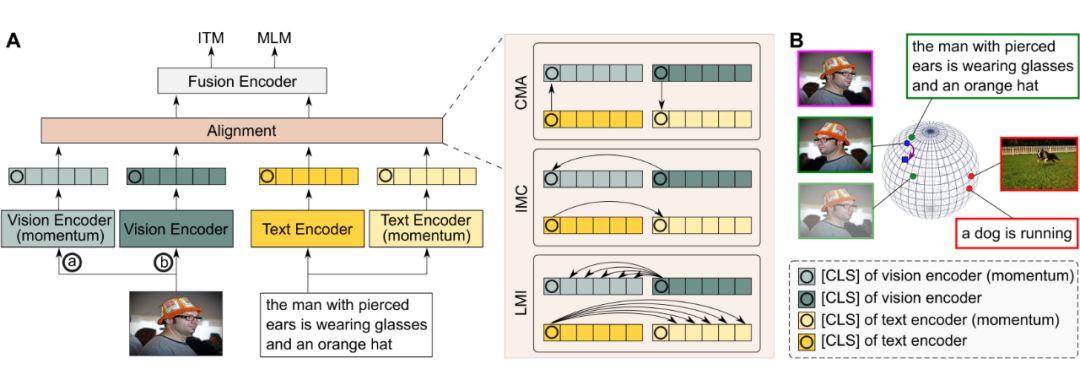
TCL(模型结构见上图)是 ALBEF 的改进版本。TCL 引入了三个对比模块:跨模态对齐(CMA)、模态内对比(IMC)和局部 MI 最大化(LMI),分别旨在最大化匹配图像和文本之间的互信息,最大化全局互信息。

测评工具涉及到哪些数据集?
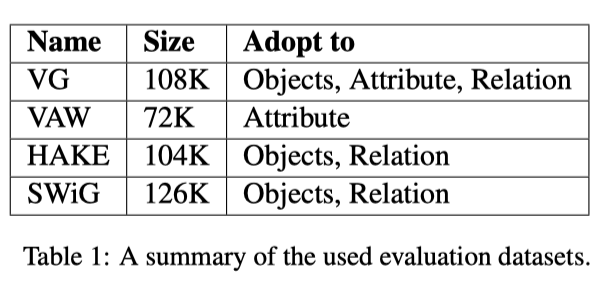
作者使用了四个语料库,VG、SWiG、VAW 和 HAKE,为本文框架中的每个能力测试构建基准数据集。上表是测试数据集总结。然后,采用这些语料库创建 VL-CheckList 评估,步骤如下:
对象:关于对象,评估语料库是从 SWiG、VG 和 HAKE 数据集转换而来的。将对象分为两个评价指标:大小和位置。前者侧重于模型对图片中对象大小的理解,而后者侧重于模型对对象在图片中位置的关注。
属性:从 VG 和 VAW 数据集转换属性的评估语料库。根据 VAW 的属性分类,将属性分为五个评估指标:颜色、材料、大小、状态和动作。
关系:对于关系,评估语料库由 VG、SWiG 和 HAKE 数据集转换而来。根据谓词是否为介词,将关系分为动作关系和空间关系。动作可以更好地反映模型对高级动词的理解,而空间更侧重于模型对空间关系的理解。

测评结果
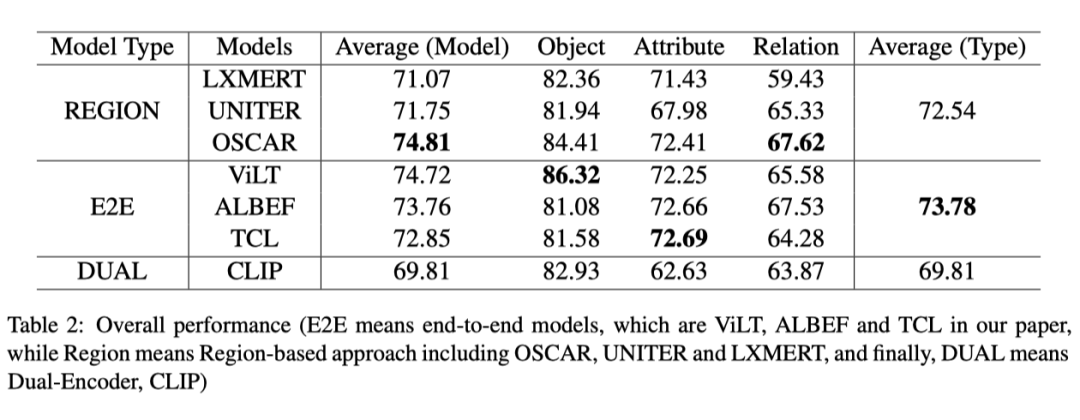
上表显示了比较模型在对象、关系和属性方面的总体性能。无论采用何种模型,对象得分都高于属性和关系得分,这表明理解关系和属性比对象更难。ViLT 在对象上取得了最好的分数。OSCAR 获得的分数比其他模型都高,所有 E2E 模特在一个属性上的分数都相似。TCL 略高于其他模型。
6.1 对象(Object)上的测评
上表显示了不同尺寸和位置对模型性能的影响。具体来说,可以观察到所有模型在大和中心点的得分最高,这表明 VLP 模型倾向于关注较大的对象和中心点的对象。当从大到小以及从中心到边缘移动时,CLIP 的性能下降幅度最大(分别为 13.13% 和 11.87%)。此外,端到端(E2E)模型(ViLT、ALBEF 和 TCL)比其他模型对位置方差更具鲁棒性。平均而言,他们的得分从中间到边缘只下降了 2.82%,而基于区域的模型(OSCAR、UNITER 和 LXMERT)和 CLIP 的平均得分分别为 6.8% 和 11.87%。
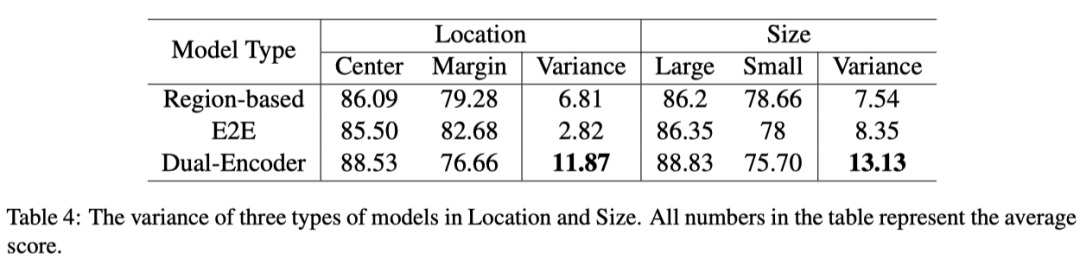
上表显示了模型在位置变化方面的性能退化。显然,E2E 模型比基于区域的模型更稳定。作者推测其原因是图像级的自注意力机制可以帮助 E2E 模型灵活地聚焦于图像的任何区域。另一方面,基于区域的模型仅限于对象检测器的性能(例如Faster R-CNN),对于图像的某些区域,其检测性能可能会下降。此外,物体检测器往往忽略位于图像边缘的不完整物体,因此这些边缘物体不会被送到跨模态 Transformer 中。因此,基于区域的模型容易遗漏边缘中的一些有用信息。本文的假设可以通过图 6 和图 7 中的注意力图可视化得到支持。

如图 6(a)所示,其描述性文本为:wheel on car,car 是负样本中替换的单词。因此,作者希望该模型将重点放在汽车上,以实现良好的预测,但图 6(b)显示,物体检测器无法识别图像顶部的汽车。另一方面,E2E 模型正确地将注意力集中在汽车区域,如图 6(c)和 6(d)所示。另一个示例如图 7 所示,其描述性文本为:boy has pants,pants 是替换的单词。图 7(b)显示,物体检测器无法检测裤子,因为该物体在视觉上不清晰。作者观察到,基于区域的模型无法识别裤子,而 E2E 模型成功识别它(图 7(c)和 7(d))。
6.2 关系(Relation)上的测评
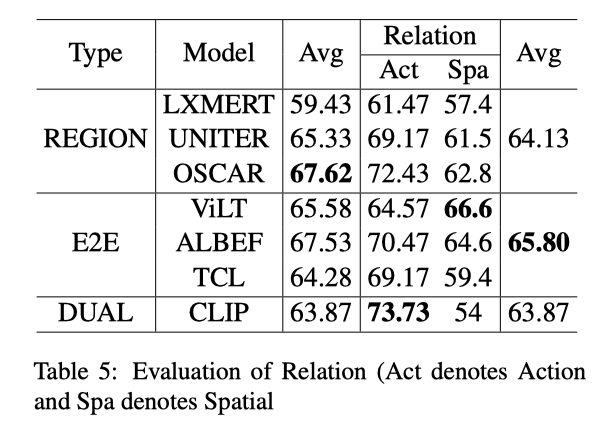
所有模型的关系性能通常较低(见上表),这表明检测关系是一个较难的问题。几乎所有模型的动作得分都高于空间得分,这表明学习相对空间更难。作者发现,E2E 方法的得分高于基于区域的方法。此外,CLIP 在动作上表现最好,ViLT 在空间上表现最好,OSCAR 获得了最佳的平均分。
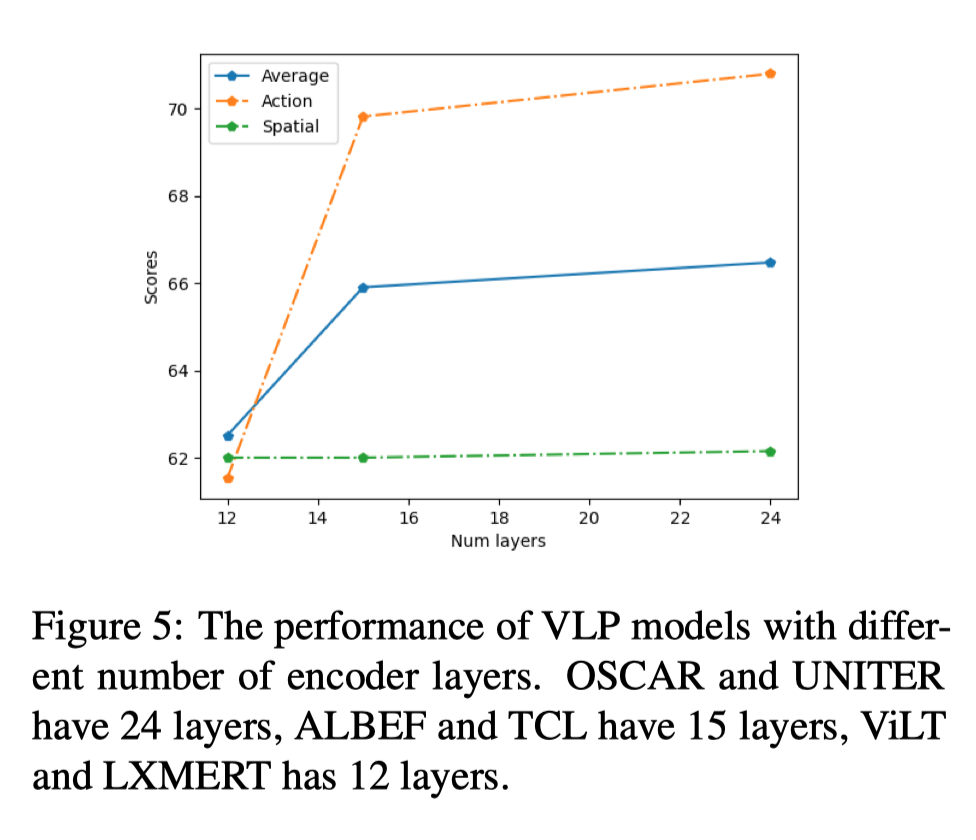
作者进一步研究了编码器层数与关系之间的相关性。将单个模态层计算为半个多模态层,因此 OSCAR 和 UNITER 的编码器层数为 24,ALBEF 和 TCL 的编码器层数为 15,ViLT 和 LXMERT 的编码器层数为 12。可以观察到,动作性能随着层数的增加而增加,而对空间没有影响(上图)。另一方面,判断负样本仅替换介词不需要有很深的编码层。在空间上,具有 24 层的模型略优于具有 15 层的模型。

此外,作者生成热力图以显示 VLP 模型关注关系的位置(见上图)。图像的描述性文本是:这位女士正在办公桌上的电脑上工作,作者为单词“工作”生成了四种不同模型的热力图。一般来说,当谈到这个单词时,人类会关注女性用手在键盘上打字的区域。因此,OSCAR 和 ALBEF 做对了,而 LXMERT 对手和键盘的关注较少。ViLT 在纸和书上有注意力,但在人身上没有,这会导致预测失误。
6.3 属性(Attribute)上的测评
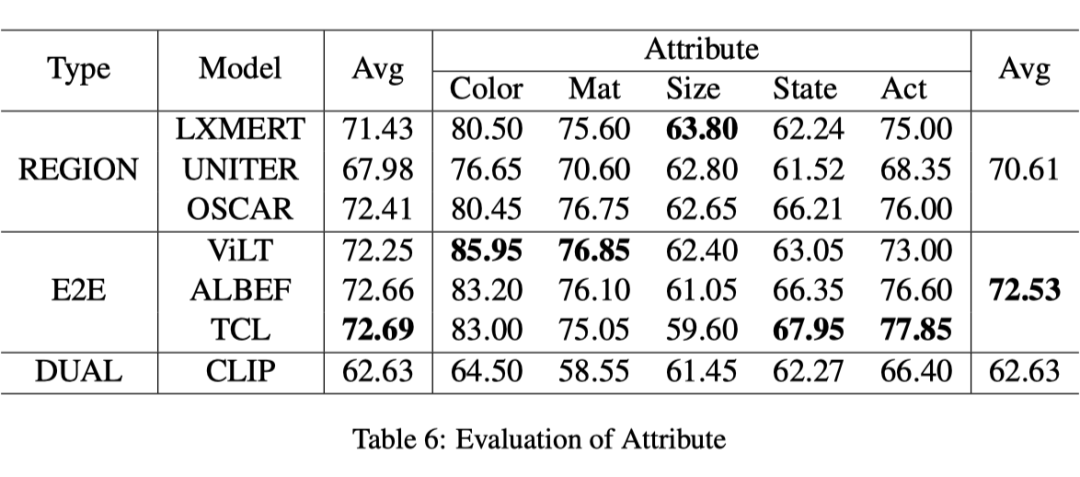
所有模型在颜色和材质上得分相对较高,在尺寸、状态和动作上得分较低,在尺寸上表现最差(见上表)。多模态属性识别需要文本和复杂场景之间的语义关联。认知往往无法识别。例如,材料不仅是形状、大小和颜色的问题,而且是视觉无法识别的东西。当人类看到图像(例如,塑料草坪)时,很难判断草坪是由植物还是塑料制成的。
作者怀疑理解大小的挑战是由于自然语言中的主观性。例如,自然语言中的大小不能转化为图像中的绝对像素大小。在预训练期间,VLP 模型在各种数据集上训练,其中大小词(例如小、大、巨)在视觉大小方面可能不一致。此外,对象大小的表达式因相机角度、背景或标注的个人视图而异。动作的性能也很低,因为没有任何帧序列(例如,开门与关门),无法判断某些动作。因此,对视频语言多模态的研究得到了积极探索。
与其他模型相比,CLIP 在所有属性指标上得分最低。E2E 方法比基于区域的方法实现更好的性能。在颜色和材质的结果中,与其他基于注意力的特征融合模型相比,CLIP 更容易受到复杂场景(对于 VG 数据集)的干扰。

论文和代码地址
论文的地址和代码就放在下面啦,各位感兴趣的小伙伴们可以玩起来啦!
论文地址:
https://arxiv.org/abs/2207.00221
代码地址:
https://github.com/om-ai-lab/vl-checklist
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

