
- 1NLP--ChatGPT的API参数总结【实践】_chatgpt api 参数
- 2nginx配置https访问
- 3Python画矩阵关系图(多变量联合分布图)_python联合分布图
- 4【抓取】6-DOF GraspNet 论文解读_6-dof graspnetcsdn
- 5【CSS】阿里iconfont的使用方法(另附font-family引入方法)_iconfont.css
- 6威纶通,威纶通UI,WEINVIEW UI,HMI 模板,人机界面模板,WEINVIEW_威纶通ui模板
- 7第1章 计算机网络体系结构-1.1计算机网络概述
- 8用vs编译动态库需要注意的问题,全局变量初始化_动态库 全局变量初始化两次
- 9python安装库的方法linalg_numpy基础教程之np.linalg
- 10JavaFx: ChoiceBox,选择器的使用方式_choicebox javafx
【单视重建】RealFusion:单张图像到任何对象的360°重建
赞
踩
项目主页:https://lukemelas.github.io/realfusion
文章:RealFusion:360◦ Reconstruction of Any Object from a Single Image
摘要
采用一个基于扩散模型的条件图像生成器,并设计一个提示,鼓励它“想出”物体的新视图,从单一图像重建一个完整的360◦模型,使用最近的 DreamFusion 方法,我们将给定的输入视图、条件先验和其他正则化器融合到一个最终的、一致的重建中。重建提供了输入视图的忠实匹配,以及对其外观和三维形状的合理预测,包括物体不可见的一面。
一、前言
挑战在于,单个图像不包含足够的信息来进行三维重建。但可以通过利用人类对自然世界和其中所包含的物体的丰富知识来做到这一点,以弥补图像中缺失的信息。
为了解决问题,必须将视觉几何 与一个强大的三维世界统计模型结合起来。最近,DALL-E [36]、Imagen [42]和stable diffusion[40]等二维图像生成器,通过扩散,可以解决高度模糊的生成任务,从文本描述、语义映射、部分完整图像或随机噪声中获得可信的二维图像。显然,这些模型具有高质量的先验。虽然人们可以访问数十亿个的2D图像,但对于3D数据则不可以。
训练三维扩散模型的另一种方法是从现有的二维模型中提取三维信息。最近的一个例子是DreamFusion [33],它仅从文本描述就可以生成高质量的3D模型。
在本文中,我们用一个神经辐射场来表示物体的三维几何形状和外观。训练则通过最小化通常的渲染损失来重建给定的输入图像。与此同时,我们随机采样物体的其他视图,并使用扩散先验,使用类似于 DreamFusion 的技术进行约束。这需要给扩散模型添加足够合理的 condition。其想法是配置先验给 “想象”或样本图像,其可能构成对象的其他视图。具体的,通过对给定图像做随机增强,来制造扩散的提示词。只有以这种方式,扩散模型才能提供足够强的约束条件。
除了正确设置提示,我们还添加了一些正则化器:阴影底层几何和随机删除纹理(也类似于dreamFusion),平滑表面的法线,并以粗到细的方式拟合模型,首先捕获对象的整体结构,然后只捕获细粒度的细节。效率方面,将模型基于 Instant NGP [29],实现小时内重建。
我们没有训练一个成熟的2d到3d模型,也不局限于特定对象;相反,我们在图像到图像的基础上,预训练2D生成器作为先验。在定量和定性上,超越以前的单图像重建器,包括 Shelf-Supervised Mesh Prediction[58](专门为三维重建定制了监督)。
贡献为:
(1) RealFusion无需假设物体图像类型或任何类型的三维监督;利用现有的二维扩散图像生成器进行新的单图像变换
(2) 引入了新的正则化器,并使用InstantNGP进行有效实现
二、相关工作
1. 基于图像的 外观和几何形状的重建
通过神经辐射场(NeRF:坐标MLP提供了一个紧凑而又可表达的三维域表示,可有效建模)的引入,光度和几何的重建问题得到了极大的复兴。Neus 使用符号距离函数(SDFs)来恢复更干净的几何图形。这些方法假设每个场景有数百个视图用于重建。其中,我们使用扩散模型来“想象”缺失的视图
2. 少视图重建
与我们工作密切相关的是NeRF-on-a-Diet [17],通过生成随机视图并通过CLIP嵌入[35]测量它们与可用视图的“语义兼容性”,减少了学习NeRF所需的图像数量,但它们仍然需要多个输入视图。
3. 单视图重建
从单个图像中恢复完整的辐射场,通常需要多视图数据来进行训练,以及特定于特定对象类别的学习模型。3D-R2N2 [5],Pix2Vox [55,55]和LegoFormer[57]学习重建简单物体的体积表示,主要利用合成数据(如ShapeNet)。最近,CodeNeRF [19]预测了一个完整的辐射场,包括重建物体的光度测量。
4.从2D 生成器中 提取3D模型
CLIP-Mesh 和Dream Fields 通过使用CLIP嵌入,可实现文本的3D生成。我们的模型建立在 DreamFusion 上(使用扩散模型)。【Novel view synthesis with diffusion models】提出直接生成一个对象的多个二维视图,然后使用类似nerf的模型进行三维重建。模型需要多视图数据来进行训练,只在合成数据上进行测试,并且需要显式地采样多个视图以进行重建。
2.扩散模型
扩散去噪概率模型是一类基于迭代反转马尔可夫噪声过程的生成模型。在视觉中,早期的工作将问题表述为学习变分下界[14],或将其定义为优化基于分数的生成模型[45,46]或连续随机过程[47]的离散化。最近的改进包括使用更快和确定性的抽样[14,25,52],类条件模型[7,46],文本条件模型[32],以及在潜在空间[41]中建模。
三、本文方法
3.1.辐射场和 DreamFusion(预备知识)
- Radiance fields.
辐射场(RF)是一对函数(σ(x),c (x)),将3D点x∈R3 映射到不透明度值σ(x)∈R+ 和颜色值c (x)∈R3。I (u)∈R3 是像素 u 的颜色,通过射线进行提渲染(详情可见博客【NeRF原理】):
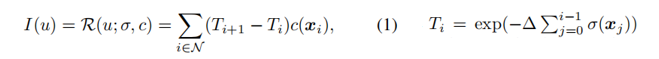
损失函数图如下: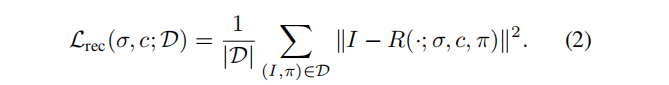
- 扩散模型
见博客【DDPM概率扩散模型】,损失函数为:
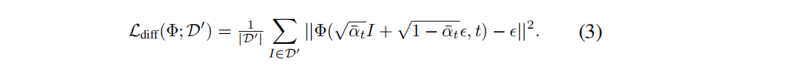
该模型可以很容易地扩展到从提示 e条件下的分布p(x|e)中提取样本。通过添加e作为网络Φ的额外输入来获得对提示符的条件采样,并且条件作用的强度可以通过无分类器的引导[7]来控制。
- DreamFusion 和SDS(分数蒸馏采样)
给定一个二维扩散模型 p(I|e) 和一个提示词 e,DreamFusion 利用RF(σ,c) 从该模型中提取相应概念的三维表示。它通过随机采样一个相机参数π,利用RF渲染相应的视图 Iπ ,并基于模型 p( Iπ |e) 生成的视图,来评估其与渲染视图的相似性,更新RF来增加模型渲染视图的真实性。
DreamFusion 使用去噪网络作为冻结的评判器,并采取梯度步骤:
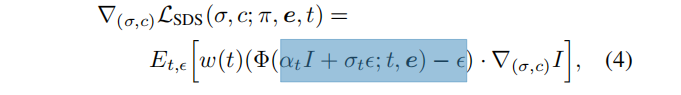
其中 I = R(·; σ, c, π),是从一个给定的视角π,和提示e渲染的图像。这个过程称为分馏采样(SDS)。等式(4)不同于简单地优化标准扩散模型目标,因为它不包括Φ的雅可比项。在实践中,删除这个术语既提高了生成质量,又减少了计算和内存需求。
DreamFusion 的最后一个方面对于理解我们在下一节中的贡献是必不可少的:为了获得良好的三维形状,有必要使用非常高的无分类器指导器的权重[7](比如100),这比图像采样要大得多。 因此,生成的多样性往往有限;对于给定的提示,它们只产生最有可能的对象,这与我们重建任何给定对象的目标不相容。
2.RealFusion(重点)
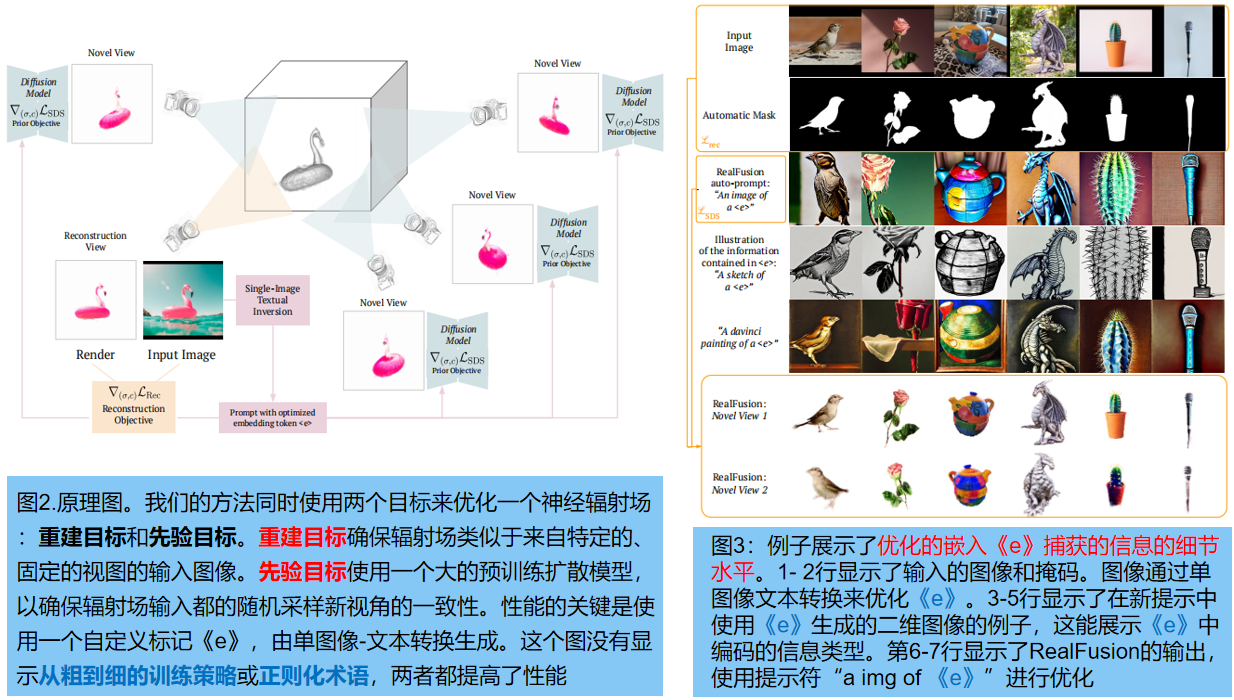
目标:利用扩散模型Φ中的先验,重建单个图像 I0中对象的三维模型。通过同时实现两个目标来优化一个辐射场,实现这一点:
- 一个固定角度的重建目标:等式(2)
- 在每次迭代中随机抽样的新视图 的 基于sds的先验目标等式(4)
1.单图-文本转换,作为多视图的替代品
使用 图像–文本转换( single-image textual inversion) 来替代多视图。由于无法从分布:: p(I | I0) 直接采样新图像,所以专门为输入图像 I0 合成一个文本提示符e(Io),作为多视图p(I | I0)的近似值**。
对输入图像做随机增强 g (I0),g∈G 来实现这一点,作为伪替代视图。我们使用这些增强器作为一个迷你数据集 D’={g(I0)}g∈G,并优化等式(3)关于提示词 e(Io)的扩散损失 Ldiff(Φ(·;e(Io))),同时冻结文本嵌入和模型参数《e》。
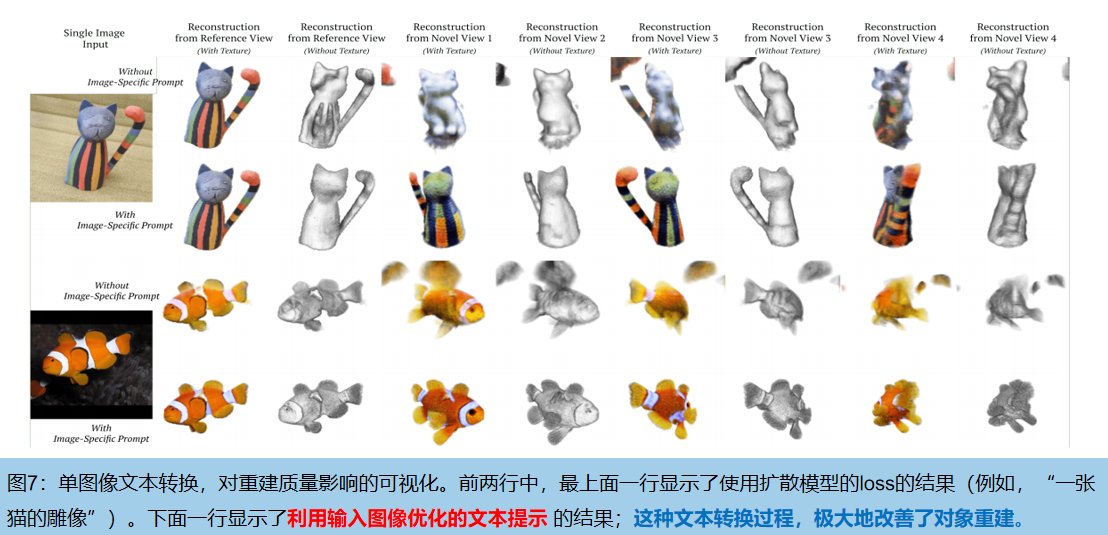
在实践中,提示符从 “an image of a 《e》” 模板自动导出,其中《e》= g (I0) 是一个新token,引入到扩散模型的文本编码器的词汇表中。优化过程反映和推广了最近提出的 [10:An image is worth one word] 的文本转换方法。
文本嵌入《e》包含了原图的知识:如果用通用的文本提示符 “一条鱼的图像” 来重建鱼的图像,利用公式(3)和(4)的损失。但是,这通常会产生一个输入的角度看起来像输入的鱼,但从背面看起来像一些不同的、更一般的鱼。相比之下,使用提示符 “一条《e》的图像” ,重建从各个角度都类似于输入的鱼。图7显示了一个确切的例子。
2. 由粗到细的训练
RF模型:InstantNGP是一个基于网格的模型,它在多分辨率的特征网格 {Gi}Li=1 的顶点上存储特征,有高的计算效率和训练速度。然而,优化过程偶尔会在物体的表面产生小的不规则现象。我们发现,从粗到细的训练有助于缓解这些问题:在训练的前半部分,我们只优化了低分辨率的特征网格 {Gi}L/2i=1 ,然后在训练的后半部分,我们优化了所有的特征网格 {Gi}Li=1 。利用这种策略,我们获得了高效的训练和高质量的结果的好处。
3. 法向量正则化
由于观察到我们的RF 模型偶尔会产生具有低水平伪影的噪声表面。因此引入一个新的正则化项,以鼓励我们的RF的几何有光滑的法线。注意是在 2D 而不是在3D 中执行这种正则化。
在每次迭代中,除了计算RGB和不透明度值外,我们还计算沿射线的每个点的法线,并通过射线行进方程进行聚合,得到法线N∈RH×W×3。
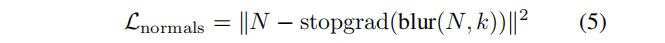
其中,stopgrlad是一个停止梯度操作,blur(·, k) 是一个核大小为k的高斯模糊(我们使用k = 9)。虽然在三维中正则化法线更常见,但在二维中操作减少了正则化项的方差,产生更好的结果。
4. mask loss
除了输入图像,模型还利用了人们希望重建的对象的 mask。在实践中,我们使用一个现成的图像 matting 模型来获得图像 mask 。合并掩模的方式:在固定参考视点R(σ, π0) ∈RH×W 之间的差值上添加一个简单的L2损失项: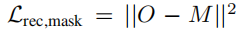
最终的优化目标包括四项,上面一行对应于先验目标,底行对应于重建目标:
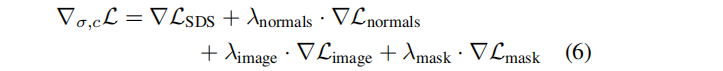
四、实验
1.设置
扩散模型先验,使用了文本-图像对的LAION [43]数据集上训练。Instant NGP模型使用具有16个分辨率级别,特征维度为2,最大分辨率为2048的模型,以粗到细的方式进行训练。
用于重建的照相机被放置在一个半径为1.8的球体上,以一个在平面上方15度的角度来观察原点。每次优化渲染,计算重建损失Lrec和Lrec,mask。λimage = 5.0、λmask = 0.5 , λnormal = 0.5。
2.定量结果
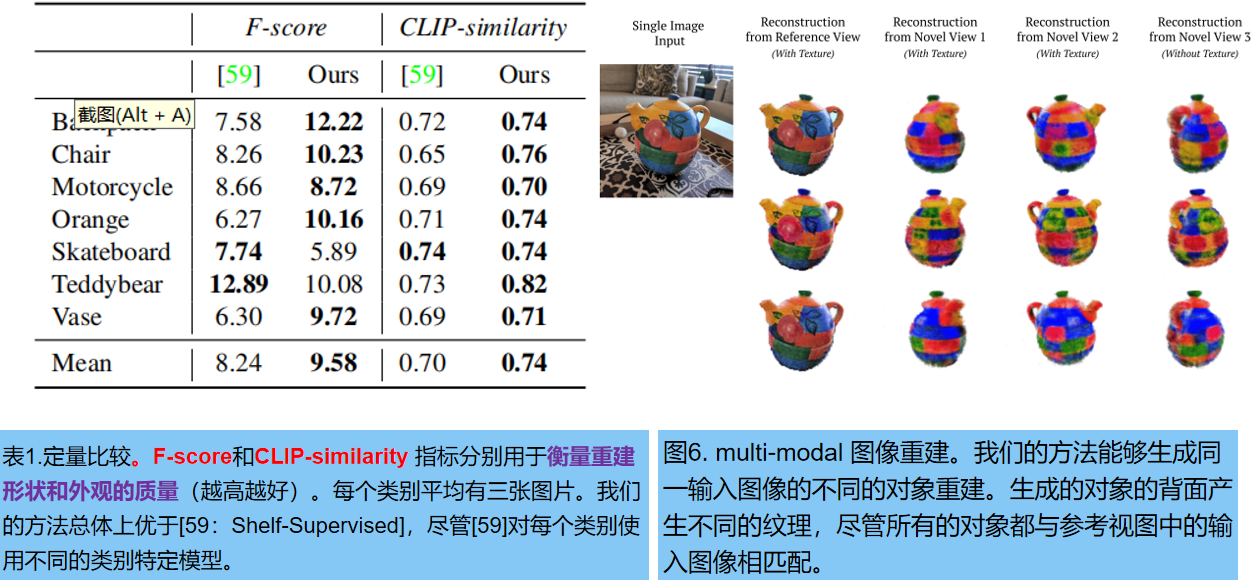
对比方法: 重建任意的三维对象方法 Shelf-Supervised Mesh Prediction[58](为OpenImages [23]中的50个不同类别提供了50个预训练模型)。我们评估了CO3D数据集[39]中的7个类别与相应的开放图像类别。每一类随机选择三张图像,并同时运行 RealFusion 和Shelf-Supervised,以获得重建。
我们测试图5中重建的3d质量。Shelf-Supervised 直接预测mesh。我们使用 marching cubes 从预测的辐射场中提取mesh。CO3D能够从多视几何图形,重建对象的稀疏点云。为了进行评估,我们从重建的mesh中采样点,并通过估计一个比例因子,使用ICP(迭代最近点),将它们与 GroundTruth 点云进行最优对齐。最后用阈值为0.05的 F-score 来测量预测的真实点云和地面真实点云之间的距离。渲染图在视觉上接近真实视图,因此我们还评估的 CLIP嵌入相似性 。结果如表1所示:
3.定性结果
图4显示了多视角定性结果:利用单一图像进行多次三维重建。图6探索了 同一输入图像开始,重复多次重建来采样可能解的空间的能力。在物体的正面重建中几乎没有差异,但背面有很大的差异。


