
- 1在shell脚本中创建动态变量,并引用存储在动态变量中的值_shell 动态变量
- 2vue2.0 -- 打包后打开为空白页::::_vue2.0打包后页面空白
- 3如何在win10设置gcc编辑器环境变量_gcc添加环境变量
- 4HBuilderX安卓离线打包教程全一览——5+app_hbuilderx离线打包
- 5java 实现蓝桥杯模拟空地长草 DFS_蓝桥杯:长草 dfs
- 6【web安全】——XXE漏洞快速入门_web常见漏洞之xxe(靶场篇)-阿里云开发者社区
- 7C++类-构造函数的重载_c++构造函数重载
- 8Mac版Jmeter安装与使用&模拟分布式环境
- 9中专学计算机可以考清华吗,职高能考清华吗 职高怎么考清华
- 10LeetCode.21. 合并两个有序链表_本题要求实现一个合并两个有序链表的简单函数mergelists,函数参数list1和list2是
python识别数字论文_Python3使用tesserocr识别字母数字验证码的实现
赞
踩
一、背景
最近有个需求是从一个后台的留言网站爬取留言数据,后台管理网站必然涉及到了登录,登录就有个验证码的问题必须得解决,由于验证码是从后端生成的,并且不了解其生成规则,那就只能通过图像识别技术来做验证码识别了!通过查阅资料发现Python中的的tesserocr这个库好像使用的比较多,所以对这个库进行了一番研究,并且实现了那个后台网站验证码的识别。
二、准备工作
1. 安装tesserocr
由于我使用的Python版本是python3.5,所以一下所有操作都是基于python3的,如果有python2的同学,可以找找其他教程~~
首先需要下载tesseract,它为tesserocr提供底层支持。具体下载官方路径:https://github.com/UB-Mannheim/tesseract/wiki,选择对应的系统版本,可以选择一个相对不带dev的稳定版本下载,如:tesseract-ocr-setup-3.05.02-20180621.exe。然后一路安装,唯一记得勾选Additional language data(download),勾选可能会用到的语言tessdata,如简体、繁体中文,数学模块等,不需要全选,下载tessdata的时间会比较长。
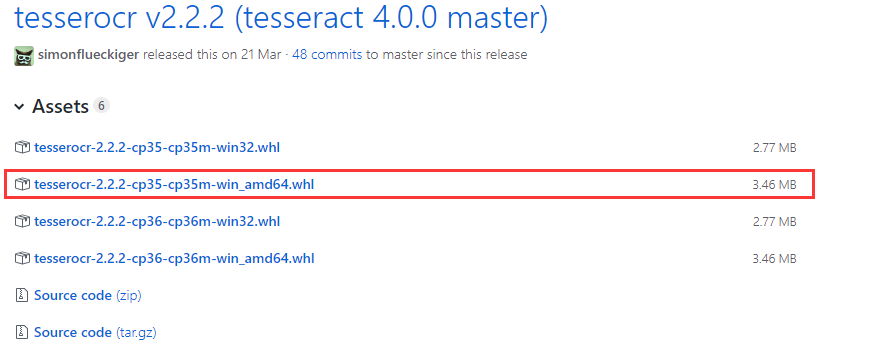
然后安装python3对应的tesserocr库,通常我们安装库的方法是使用命令pip install tesserocr,但是这里会报错:“error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools",这个时候不宜直接去下载Microsoft Visual C++ Build Tools,而是使用原始的whl文件方式安装。tesserocr 的whl官方文件下载路径:https://github.com/simonflueckiger/tesserocr-windows_build/releases,下载本地环境对应的whl文件,如我的是window64位系统,python版本是3.5。下载完后,使用cd跳转到whl文件所在目录,然后 执行 ”pip installtesserocr-2.2.2-cp35-cp35m-win_amd64.whl“,即可轻松完成安装。
紧接着用例子验证如何使用:我们找到一个验证码图片:image.jpg,下载到本地磁盘,用代码进行验证:
import tesserocr
from PIL import Image
image=Image.open('image.jpg')
print(tesserocr.image_to_text(image))
不出意外,首次运行总是不顺利,相信我遇到的坑大多数人都会遇到,大抵错误类似:
Traceback (most recent call last):
File "G:\pythonSources\my12306/obtain_message\test.py", line 4, in
print(tesserocr.image_to_text(image))
File "tesserocr.pyx", line 2400, in tesserocr._tesserocr.image_to_text
RuntimeError: Failed to init API, possibly an invalid tessdata path: “本地某个路径”
有个比较简单粗暴的解决方法是把安装好的Tesseract-OCR下的tessdata文件夹整个拷贝到提示的那个路径中,亲测有效。
2. 安装opencv
由于验证码需要做一些优化处理,方便更加容易被tesserocr识别,所以需要使用opencv来做一些特殊的处理,安装opencv比较简单,直接pip install opencv-python即可。
三、识别过程
1. 将图片变成黑白图片
我需要爬取数据的这个后台网站验证码是黄底白字的,这种色差较小的tesserocr识别起来比较困难,稍微试了一下,基本上没怎么识别对过。。。所以我们需要先将图片变成色差最大的黑白图片。初始图片见下图:
首先,将图片变成灰色,并将灰色图片保存起来方便后续做对比,变成灰色以后的图片如下:
变成灰色后,通过像素点的颜色值将灰色部分的背景变成白色,白色的具体内容变成黑色,这样白底黑字的黑白图片就有了:
处理成黑白图片的实现代码如下:
img = Image.open(self.code_path)
# 将图片变成灰色
img_gray = img.convert('L')
img_gray.save('../images/code_gray.png')
# 转成黑白图片
img_black_white = img_gray.point(lambda x: 0 if x > 200 else 255)
img_black_white.save('../images/code_black_white.png')
2. 去除图片噪点
图片转成黑白以后,一些杂点也随着我们的主体内容变成了黑色的点,这样对识别的效果也有较大的影响,所以需要想办法将这些干扰点去掉。这里就需要借助opencv的功能了,在使用opencv去除噪点之前,需要先将图片做灰值化以及二值化处理,具体代码如下所示:
# opencv处理
img_cv = cv2.imread('../images/code_black_white.png')
# 灰值化
im = cv2.cvtColor(img_cv, cv2.COLOR_BGR2GRAY)
# 二值化
cv2.adaptiveThreshold(im, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 1)
基本处理之后,就需要消除噪点了,消除噪点的原理也比较简单,就是遍历图片的每一个像素点,找到其上下左右四个像素点位置的颜色,如果这四个点中白色点的数量大于2则说明这个点是噪点,需要将该点的颜色直接置为白色点,在边框位置的像素点也直接置为白色,因为主要内容一般都是在图片中间的。以下为处理噪点的代码:
# 噪点处理
def interference_point(img):
filename = '../images/code_result.png'
h, w = img.shape[:2]
# 遍历像素点进行处理
for y in range(0, w):
for x in range(0, h):
# 去掉边框上的点
if y == 0 or y == w - 1 or x == 0 or x == h - 1:
img[x, y] = 255
continue
count = 0
if img[x, y - 1] == 255:
count += 1
if img[x, y + 1] == 255:
count += 1
if img[x - 1, y] == 255:
count += 1
if img[x + 1, y] == 255:
count += 1
if count > 2:
img[x, y] = 255
cv2.imwrite(filename, img)
return img, filename
噪点处理完毕之后,就是一张非常清晰的图片了:
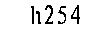
这个时候就可以直接使用tesserocr来识别了,具体识别的方式如下:
tesserocr.image_to_text(img_result)
识别测试结果如下:
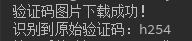
经过多次识别验证测试,另外也由于这个验证码的字体相对比较规范,所以成功率是相当的高了,即使偶尔的一次失败,我们也是可以进行重试就又成功了。哈哈, 差不多就是这个样子啦,欢迎大家指正文中的问题~~不多说了,我要去使用新学的技术去做“坏事”了!
到此这篇关于Python3使用tesserocr识别字母数字验证码的实现的文章就介绍到这了,更多相关Python3 tesserocr识别字母数字验证码内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!

