
- 1分享自己用的idea快速生成方法注释快捷键脚本
- 2Java wait() notify()方法使用实例讲解_java wait notify 例子
- 3沦为“取数工具”的那些日子,我懂得了这些道理_数据分析取数工具人
- 4Gradle Permission denied解决方案_gradle/5.6.4/filehashes/filehashes.lock: permissio
- 5一台电脑配置两个Git账号_一台电脑可以模拟两个git账户提交吗
- 6嵌入式项目分享 基于PID控制的智能平衡车 - stm32 物联网 单片机 超详细_stm32 pid 平衡车
- 7VMware 下载安装Ubuntu20.04详细图文教程_vmware17安装ubuntu 20.04
- 8Anaconda3环境使用TensorFlow报错解决记录 mistGPU_attributeerror: module 'tensorflow' has no attribu
- 9git使用操作_git只有获取没有拉取
- 10java毕业设计成品源码网站基于javaWeb停车场车辆管理系统的设计与实现|车位_java成品网站
hadoop3.3.0下载安装与配置
赞
踩
hadoop3.3.0下载安装与配置
hadoop个版本下载地址
http://archive.apache.org/dist/hadoop/common/
安装hadoop需要先安装jdk,配置java环境
jdk1.8下载链接
链接: https://pan.baidu.com/s/1pj4yAiA3tmWe-nO9780ITg?pwd=hp9d 提取码: hp9d
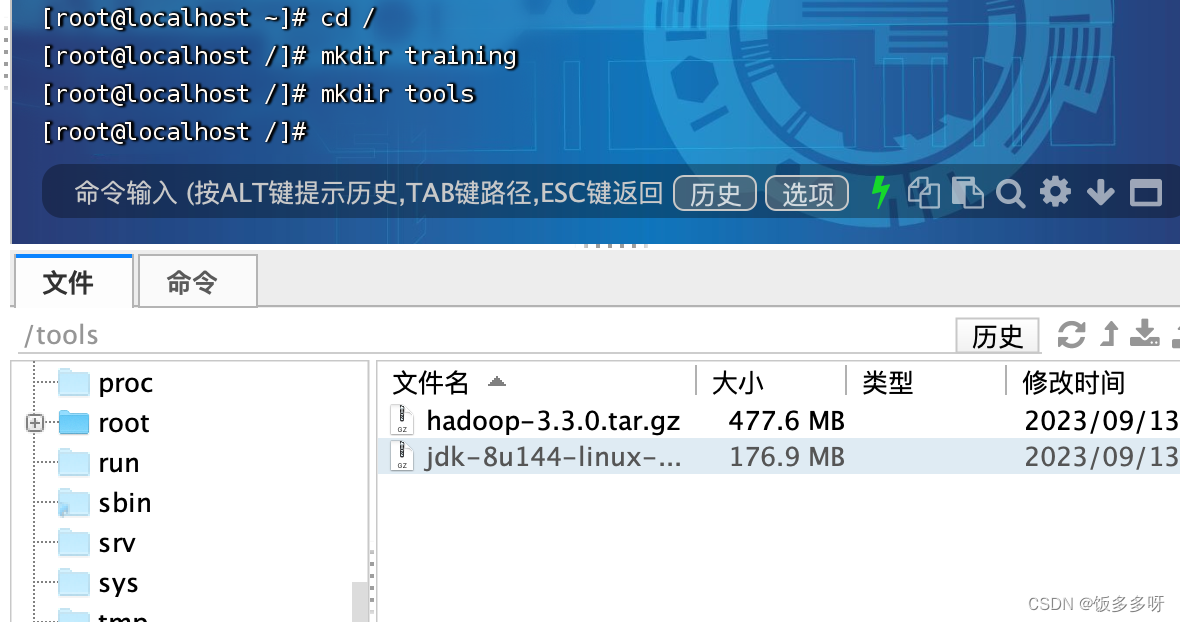
1.创建tools ,training文件夹
直接将jdk和hadoop安装包上传到tools中
2. 解压安装配置jdk
2.1解压
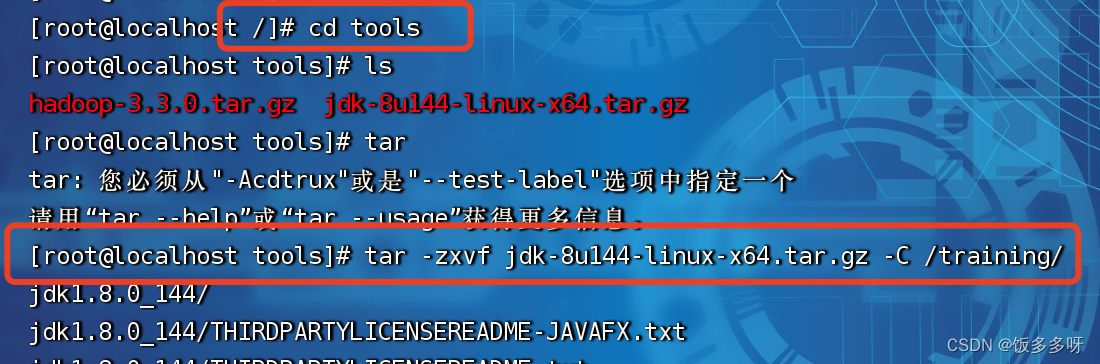
进入tools文件夹,将jdk解压到training文件夹下
[root@localhost /]# cd tools
[root@localhost tools]# ls
hadoop-3.3.0.tar.gz jdk-8u144-linux-x64.tar.gz
[root@localhost tools]# tar -zxvf jdk-8u144-linux-x64.tar.gz -C /training/
- 1
- 2
- 3
- 4
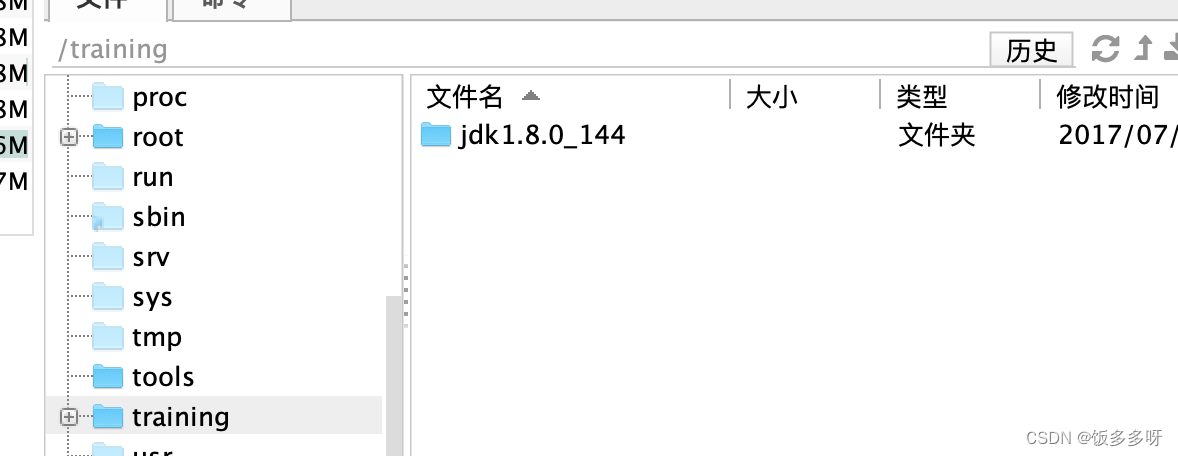
解压后去training文件夹下查看,已经解压完成
2.2配置
输入此命令进行环境变量配置
vi ~/.bash_profile
- 1
打开文件后是不可编辑状态,键盘输入 i 进入编辑状态
在文件中加入以下内容
#java
export JAVA_HOME=/training/jdk1.8.0_144
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
- 1
- 2
- 3
- 4
- 5
注意 jdk路径和版本号要和自己的实际路径和版本号一致
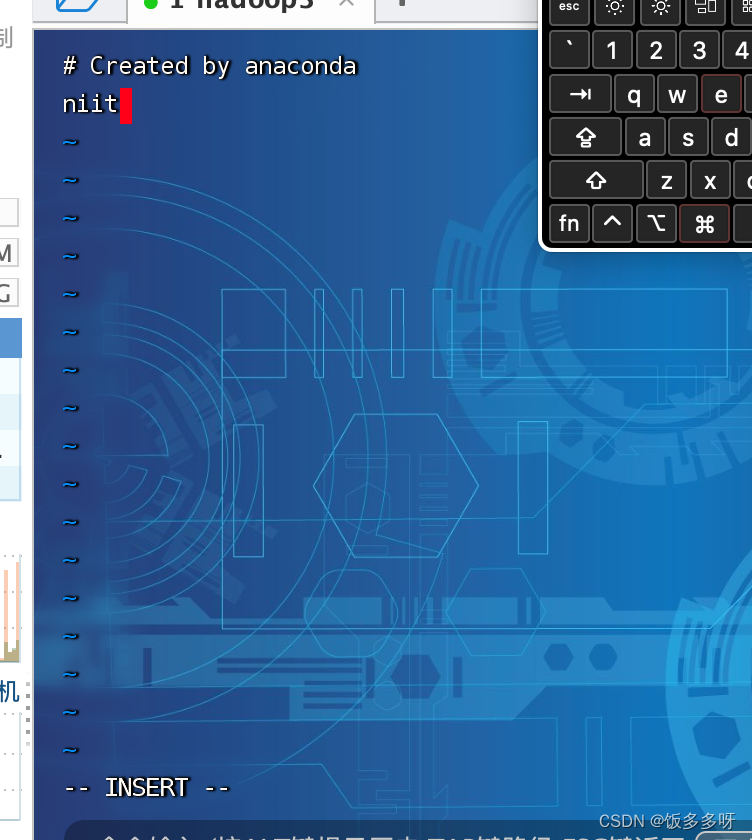
输入完成后,点击键盘上的ESC键退出输入模式
输入模式如下,文件末尾显示的有INSERT
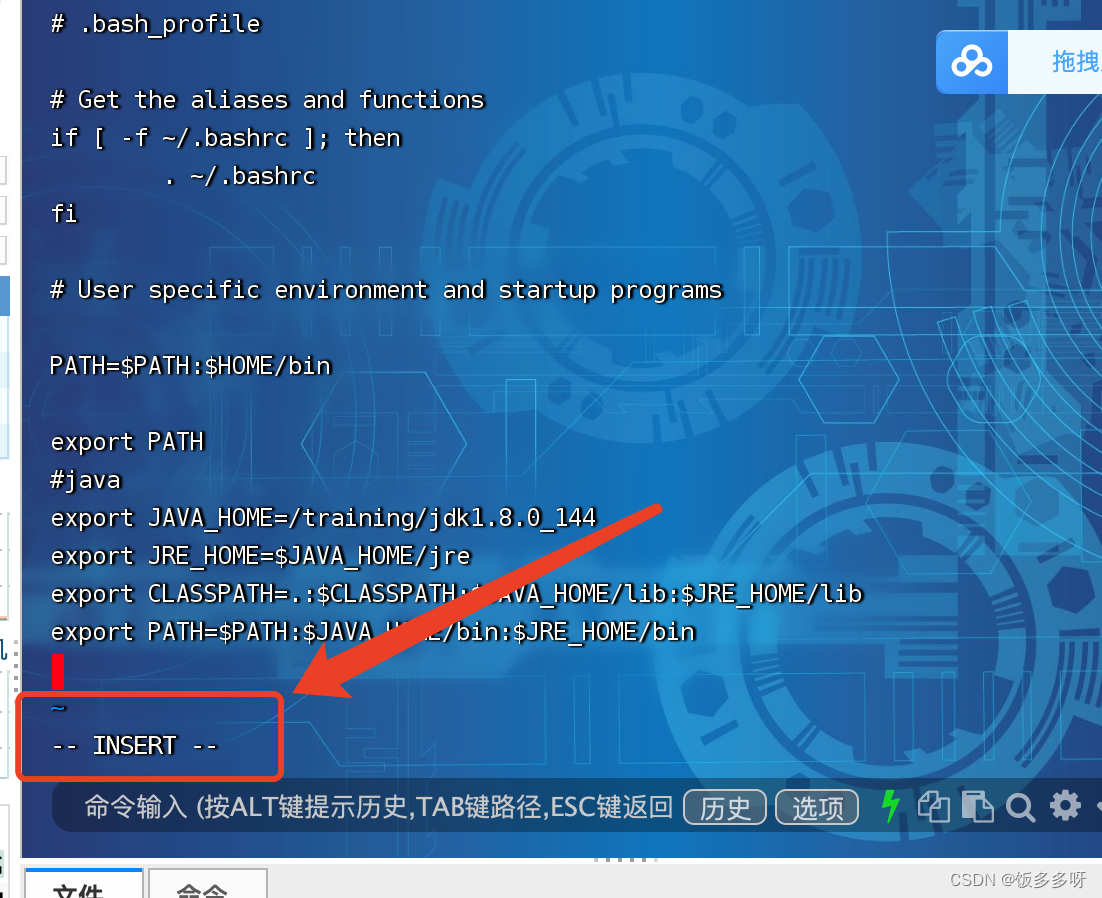
点击ESC之后,文件末尾的INSERT会消失
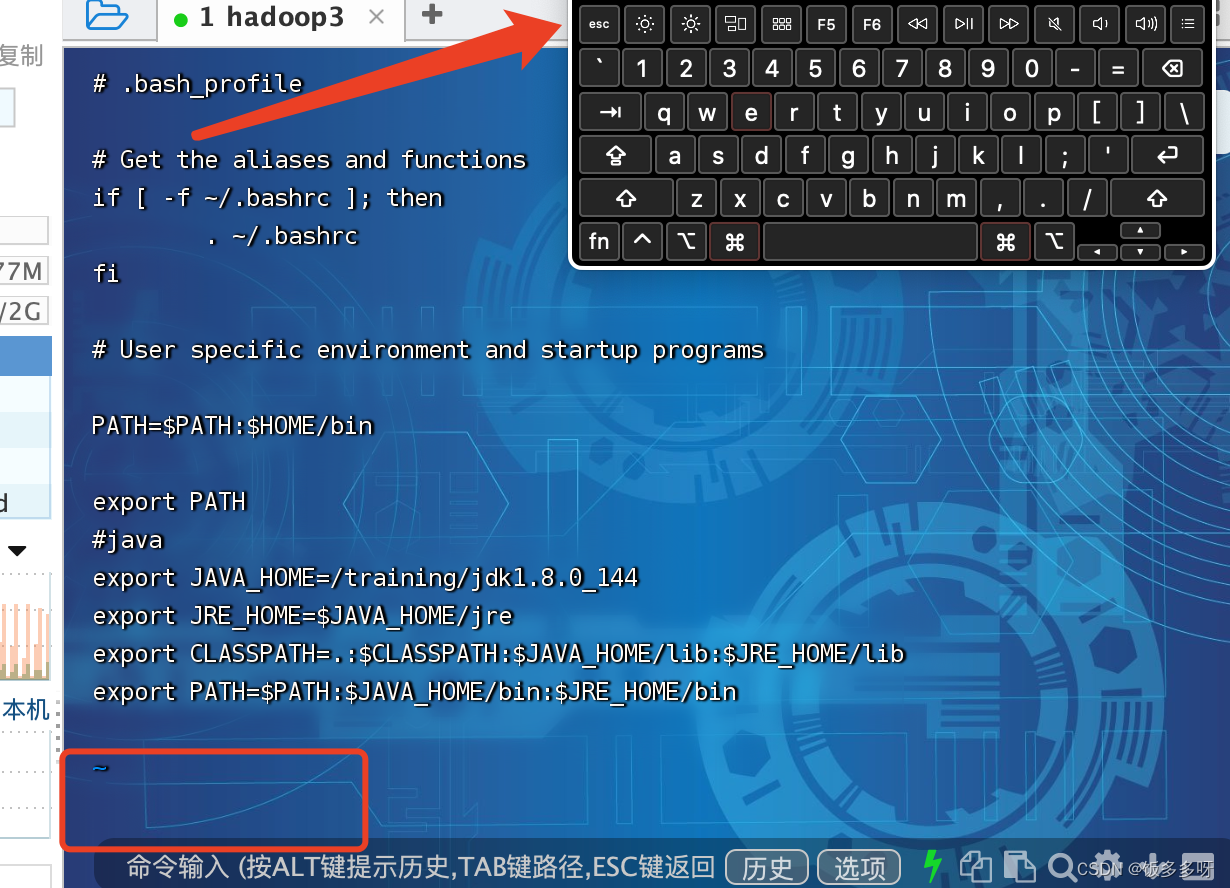
然后输入:wq 回车保存退出即可
:wq保存退出:q!不保存强制退出
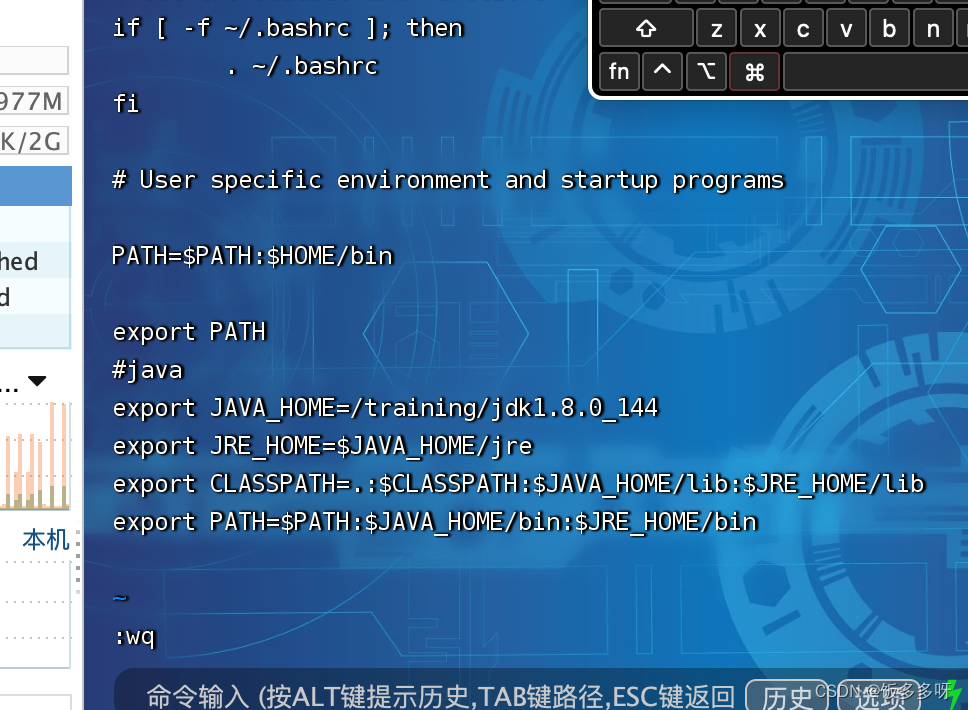
输入以下命令使环境变量生效
source ~/.bash_profile
- 1
2.3查看是否配置成功
输入以下命令查看是否配置成功
java -version
- 1

3.安装hadoop
3.1配置主机名
最后面niit为要修改的主机名,也可根据自己的需要自由设置
hostnamectl --static set-hostname niit
- 1
3.2配置ip主机名映射关系
修改hosts文件,配置映射关系
输入以下命令进行修改
vi /etc/hosts
- 1

在文件中键入以下内容(输入i进入编辑模式,:wq保存退出)
前面是你自己的本机ip地址 后者会刚才配置的主机名,一定要以自己的实际ip和主机名一致!!!
192.168.149.128 niit
- 1
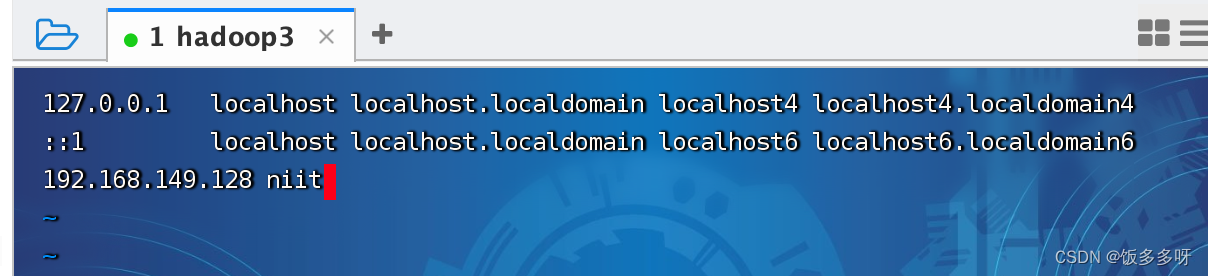
配置另一个映射文件
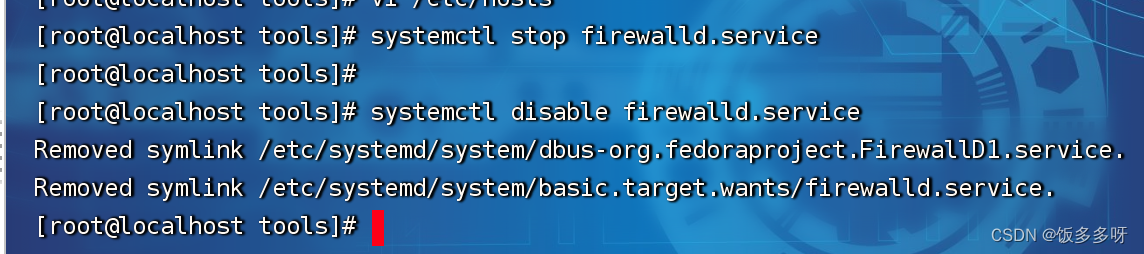
3.3 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
- 1
- 2
3.4解压hadoop
进入tools文件夹,将hadoop解压到training文件夹中
cd tools
tar -zxvf hadoop-3.3.0.tar.gz -C /training/
- 1
- 2

3.5 配置hadoop环境变量
vi ~/.bash_profile
- 1
打开文件后键入以下内容即可 (输入i进入编辑模式,:wq保存退出)
#hadoop
export HADOOP_HOME=/training/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 1
- 2
- 3
使环境变量生效
source ~/.bash_profile
- 1
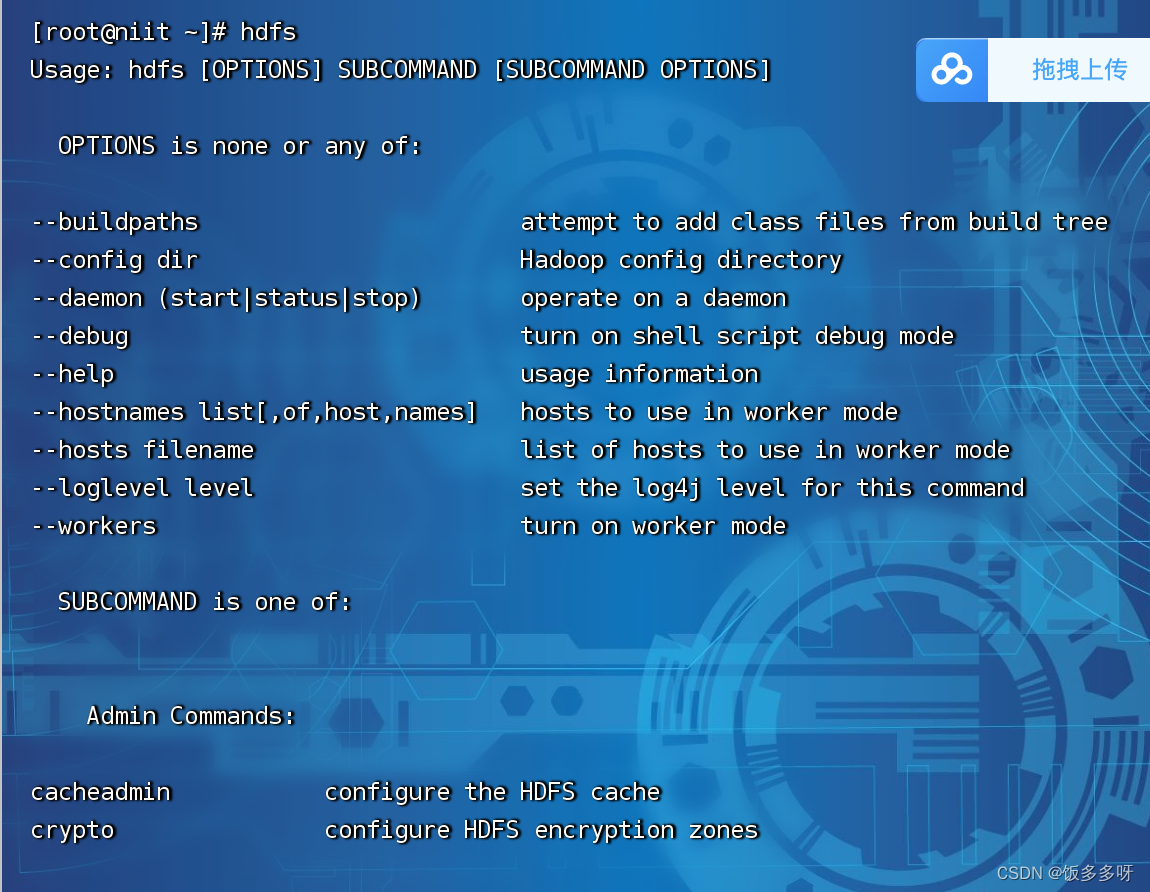
3.6输入hdfs检查hadoop是否安装成功
输入以下内容说明安装成功
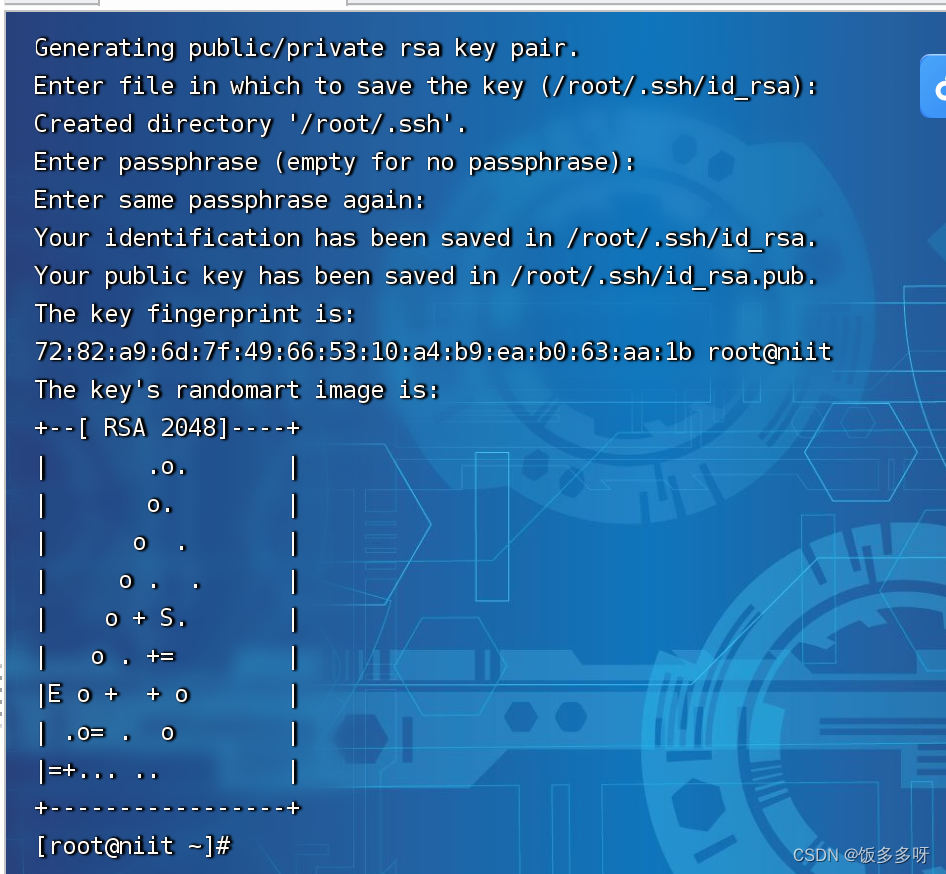
3.7 配置hadoop免密登录
在hadoop安装路径下创建一个tmp文件夹用于存放配置数据
mkdir /training/hadoop-3.3.0/tmp
- 1

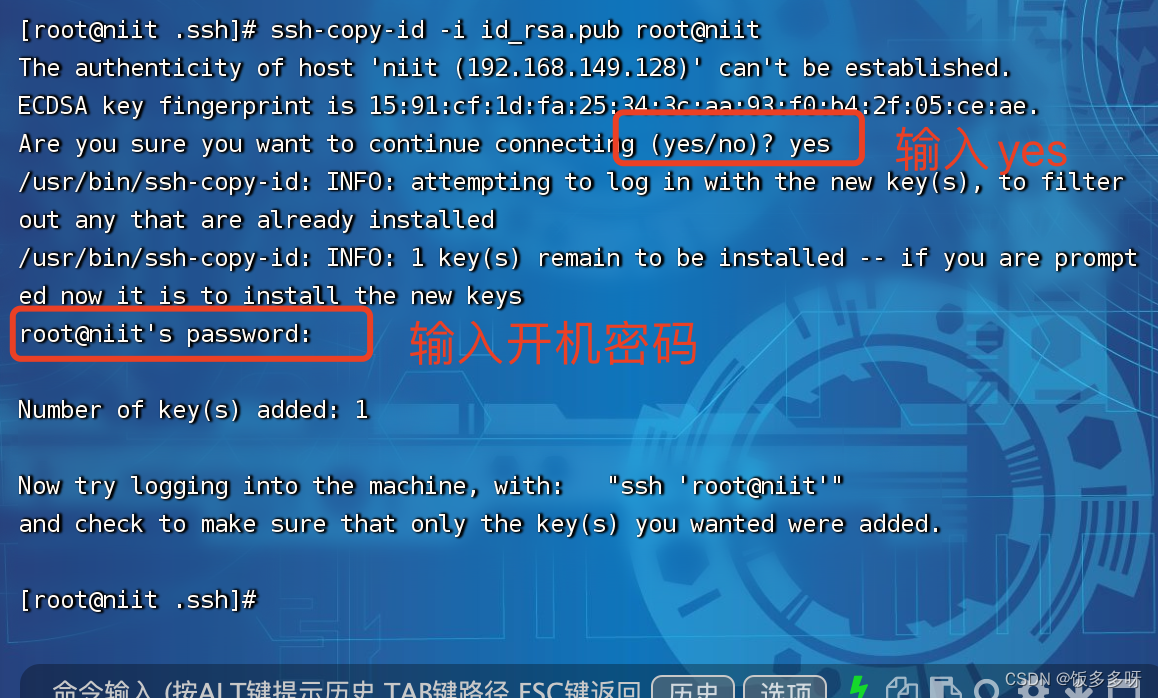
进行免密配置
输入以下代码,回车四次,什么都不要输入
输入以下命令
cd ~/.ssh/
ssh-copy-id -i id_rsa.pub root@niit
- 1
- 2
niit是自己本机的主机名
3.8配置hadoop配置文件
3.8.1 进入Hadoop配置文件地址
cd /training/hadoop-3.3.0/etc/hadoop/
- 1

- 配置hadoop-env.sh文件
vi hadoop-env.sh
- 1

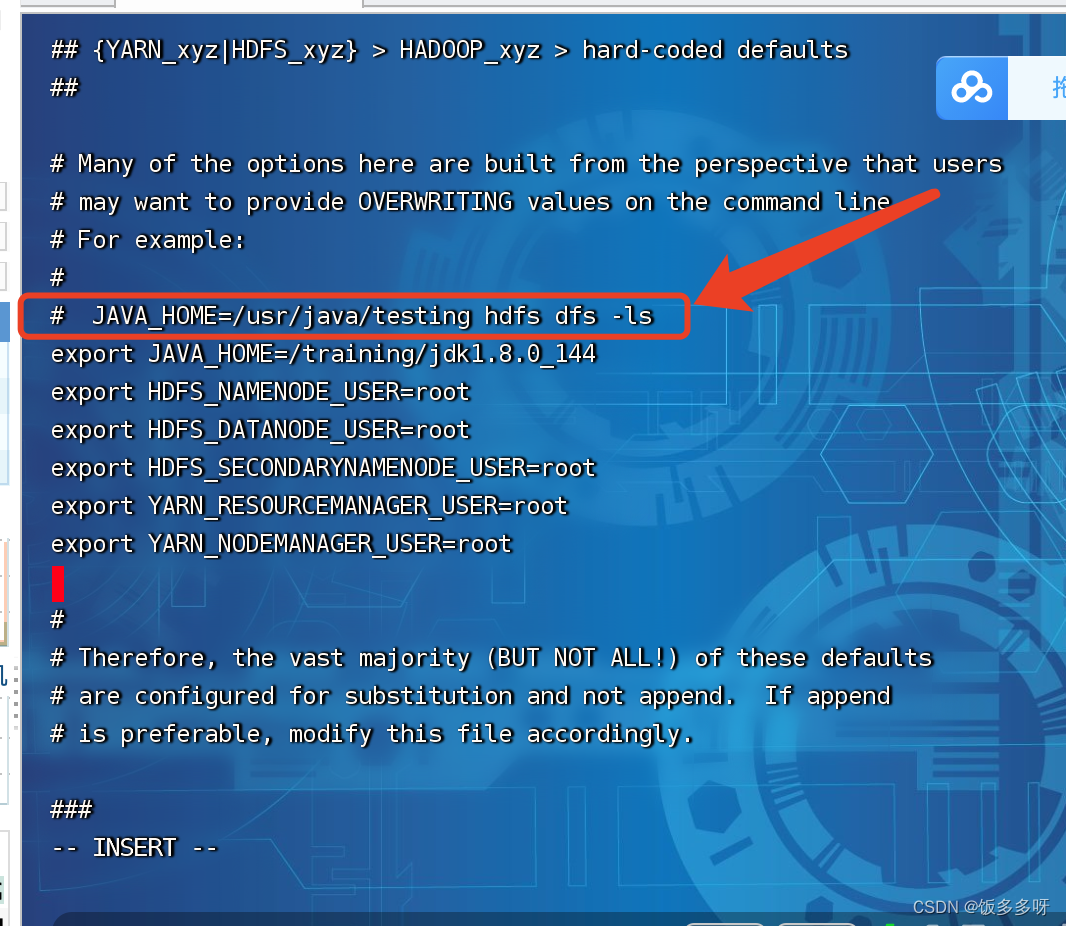
进入编辑模式后找到JAVA_HOME,在此列下面添加如下代码
(输入i进入编辑模式,:wq保存退出)
export JAVA_HOME=/training/jdk1.8.0_144
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 1
- 2
- 3
- 4
- 5
- 6
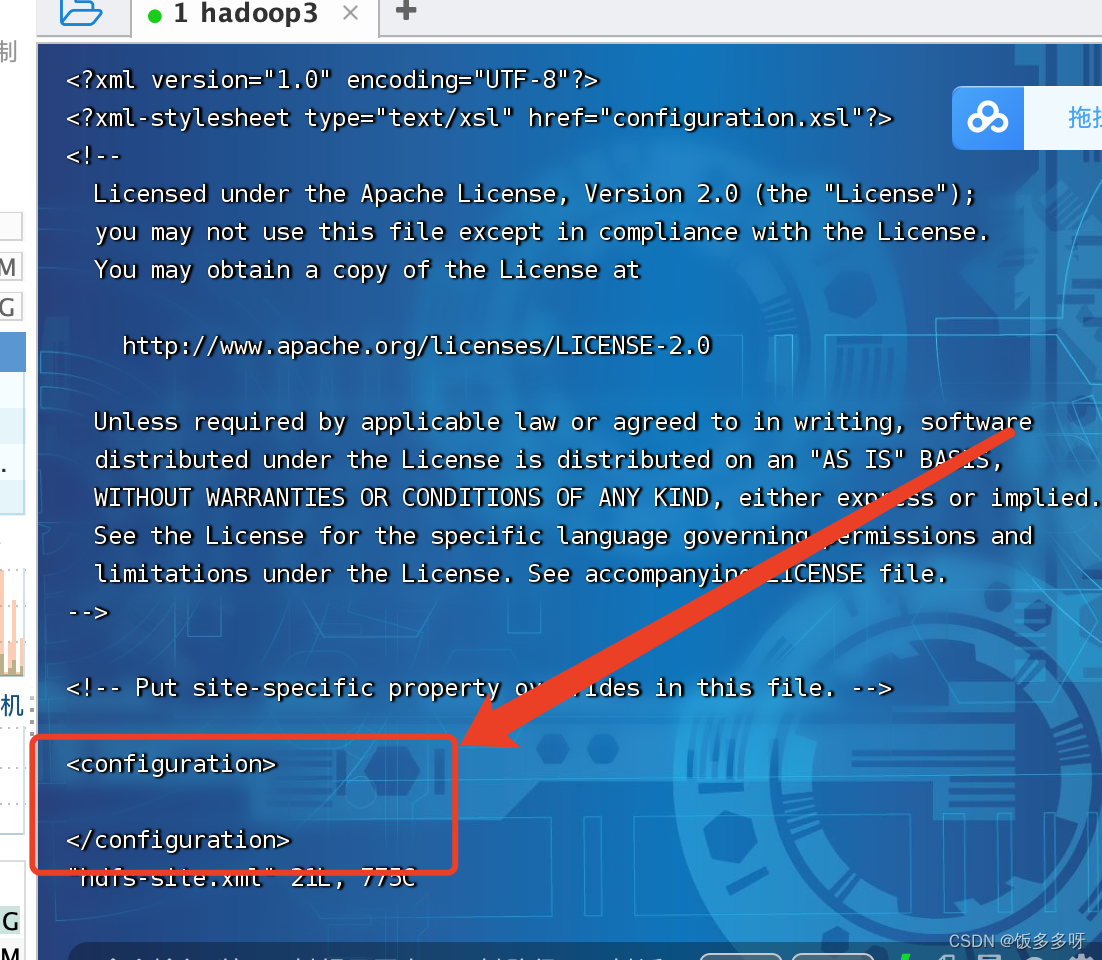
2. 配置hdfs-site.xml文件
vi hdfs-site.xml
- 1
进去之后在两个configuration标签下加入以下配置 (输入i进入编辑模式,:wq保存退出)
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.配置core-site.xml文件
进入文件
vi core-site.xml
- 1
进去之后在两个configuration标签下加入以下配置 (输入i进入编辑模式,:wq保存退出)
其中niit为主机名,要与自己的实际主机名一致
<property>
<name>fs.defaultFS</name>
<value>hdfs://niit:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/training/hadoop-3.3.0/tmp</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
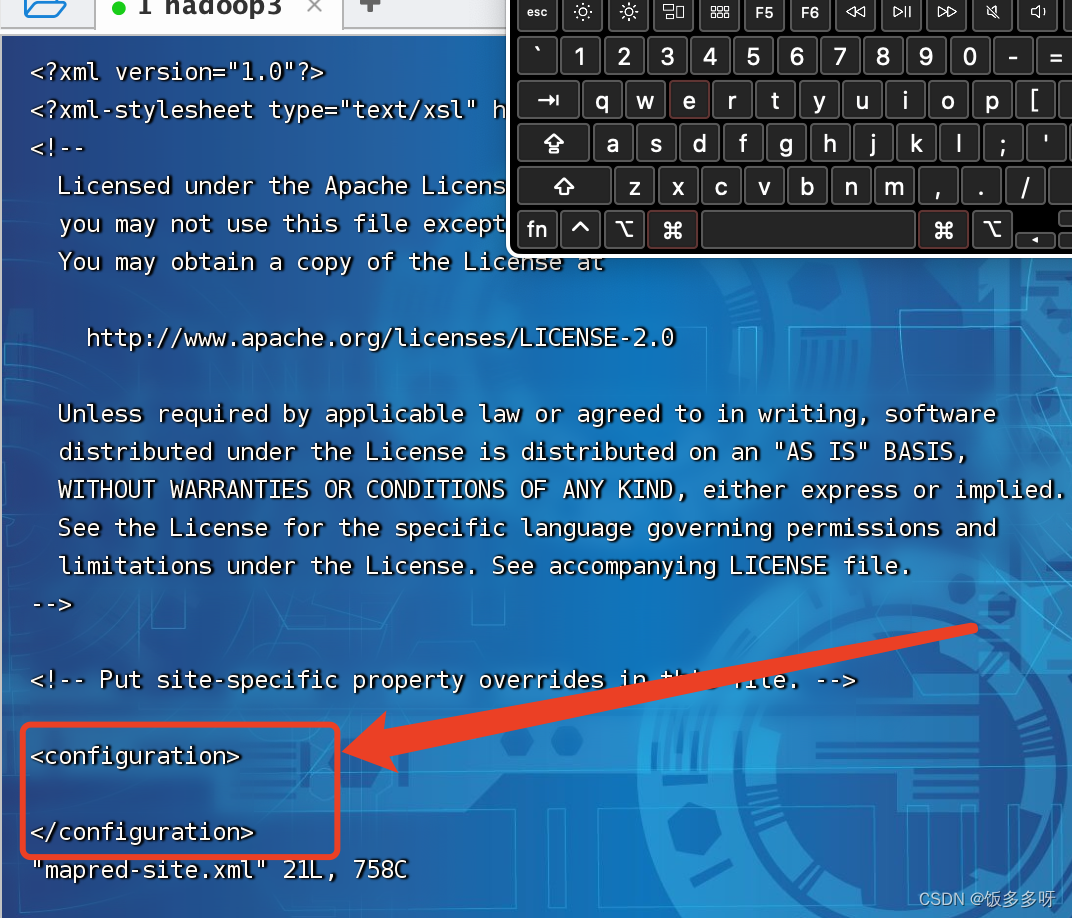
4.配置mapred-site.xml文件
进去之后在两个configuration标签下加入以下配置 (输入i进入编辑模式,:wq保存退出)
vi mapred-site.xml
- 1
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 1
- 2
- 3
- 4
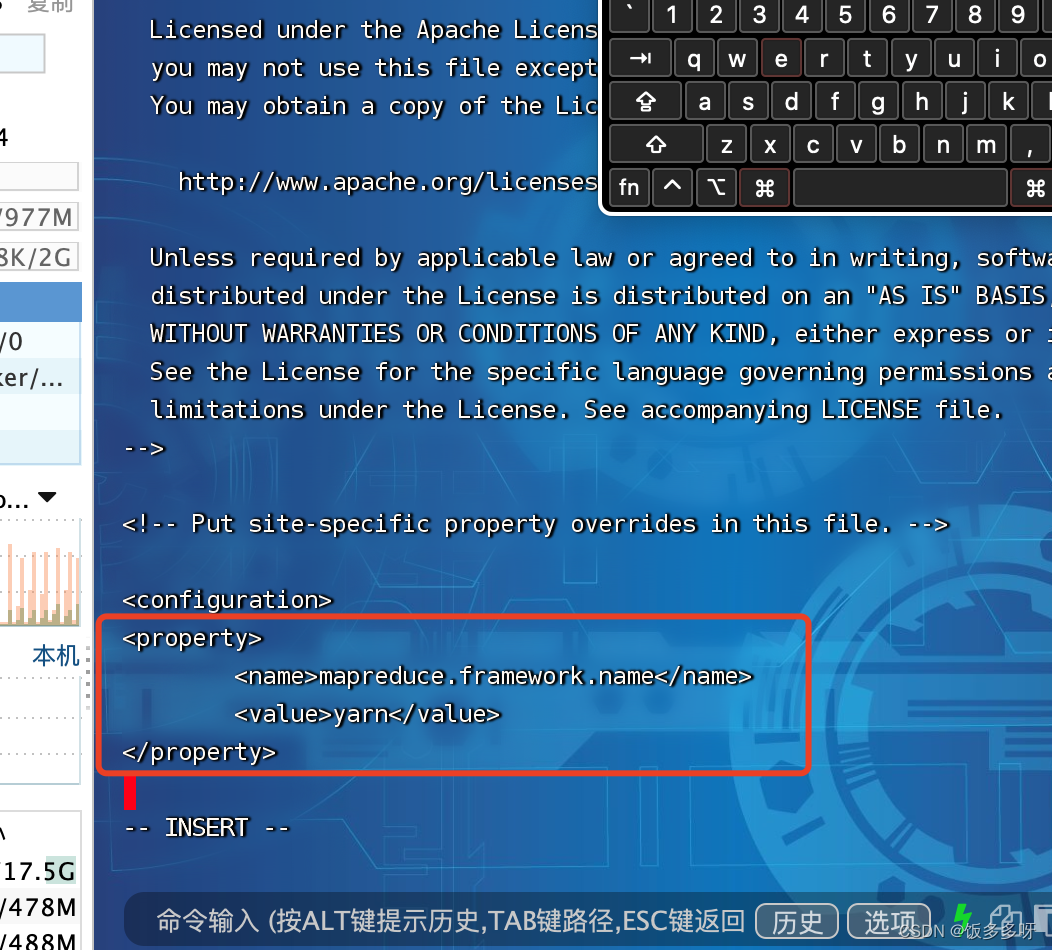
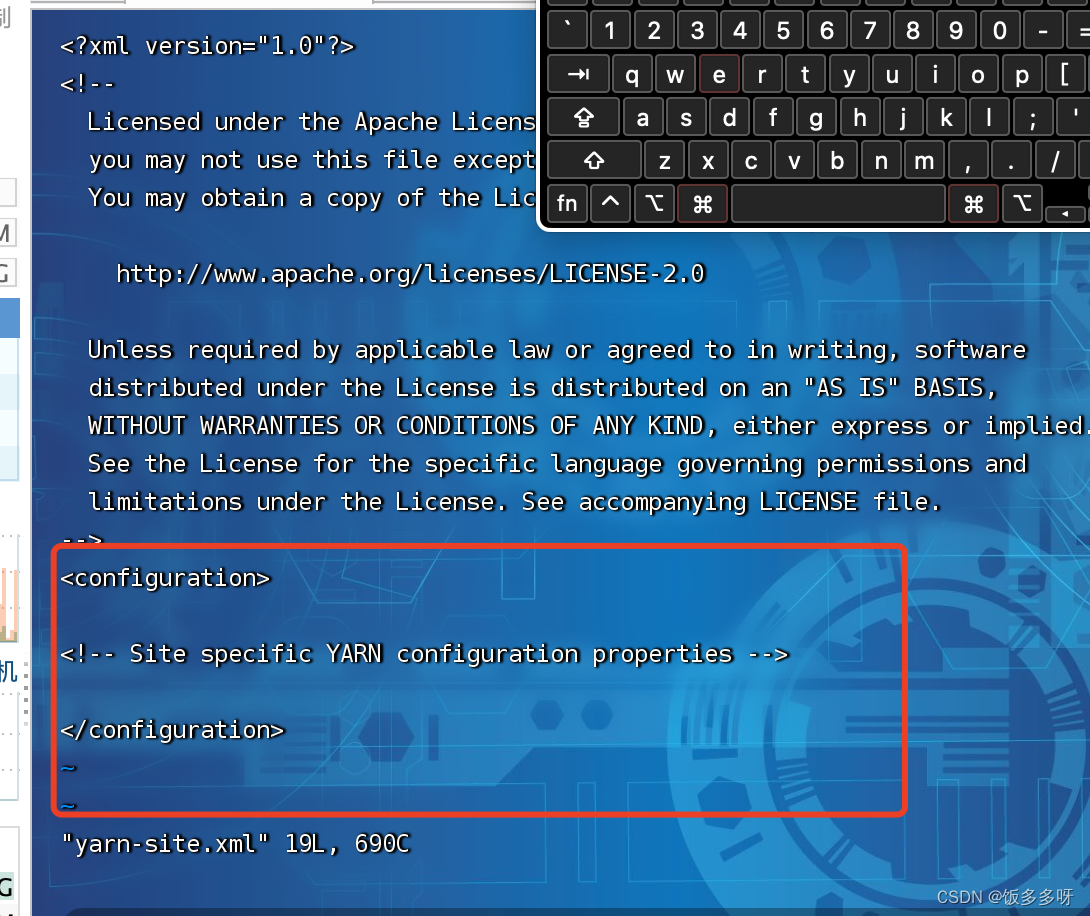
- 配置yarn-site.xml文件
vi yarn-site.xml
- 1
进去之后在两个configuration标签下加入以下配置 (输入i进入编辑模式,:wq保存退出)
<property>
<name>yarn.resourcemanager.hostname</name>
<value>niit</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.9 Hadoop格式化主节点
hdfs namenode -format
- 1
4.0 hadoop启动与关闭
启动
start-all.sh
- 1
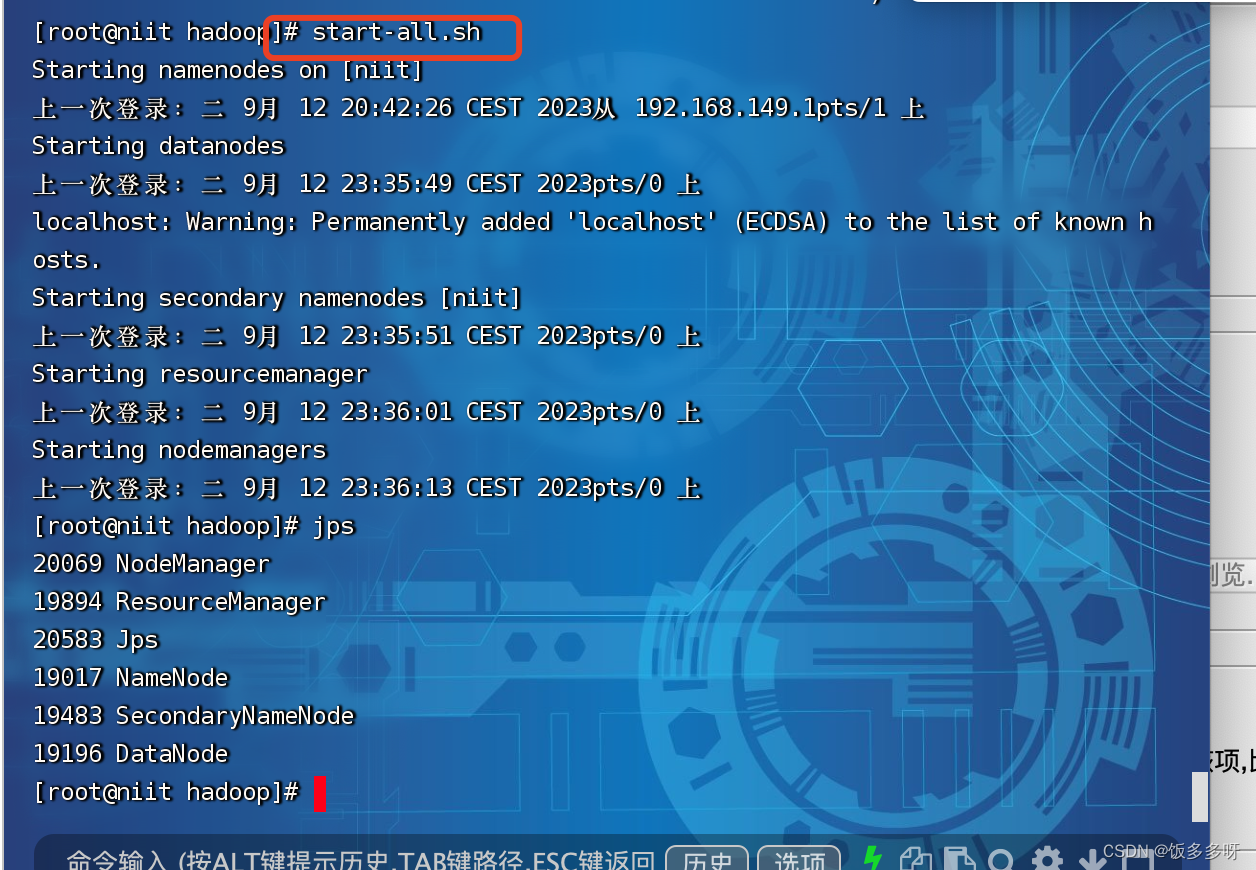
查看进程
jps
- 1
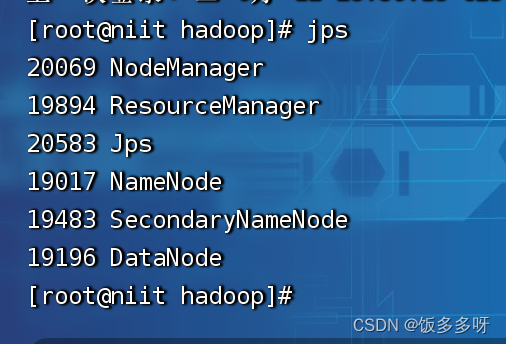
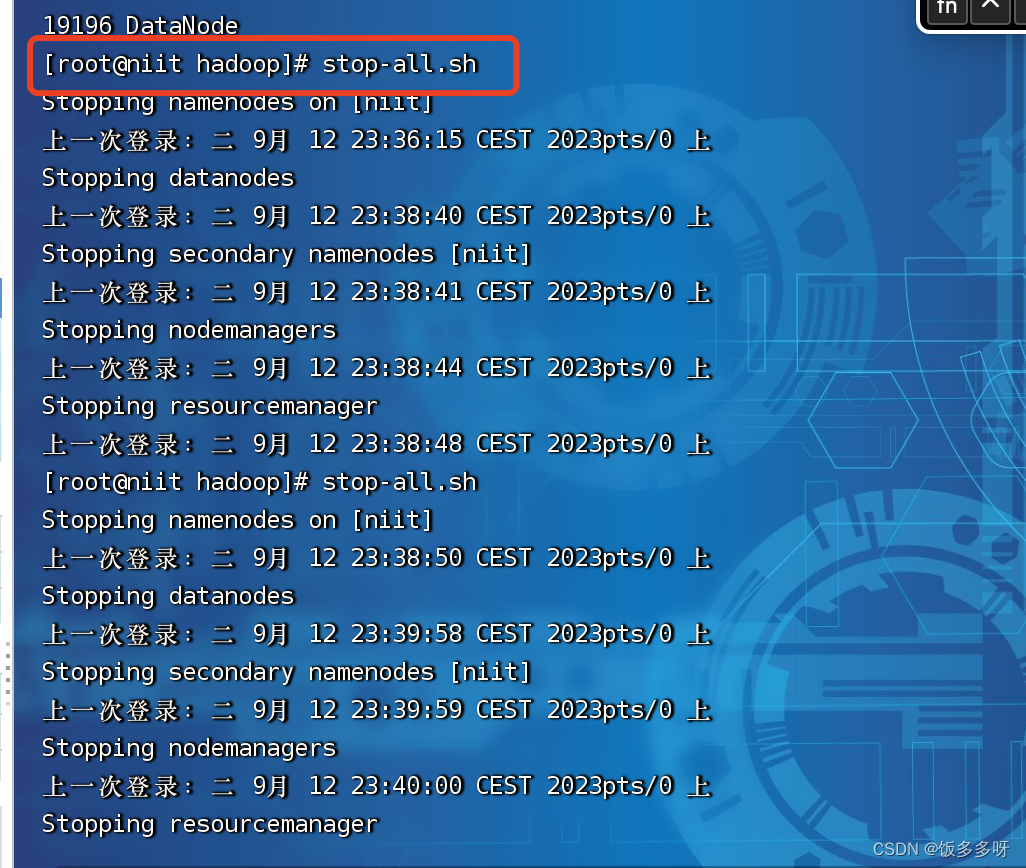
关闭hadoop
stop-all.sh
查看进程
jps
- 1
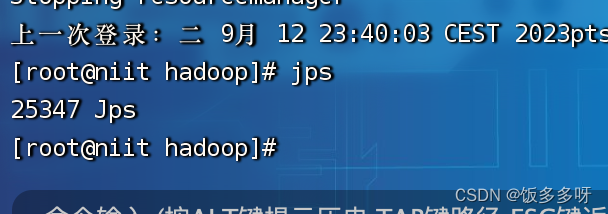
以上如果全都正常,说明安装成功,如果缺少进程,说明是某个配置文件有问题,查看配置文件修改即可

