
- 1Arduino开发 esp32cam+opencv人脸识别距离+语音提醒_esp32 arduino摄像头代码
- 2python-def函数的定义_def定义函数
- 3Vue开发实例(11)之el-menu实现左侧菜单导航
- 4前端(VUE)在el-table上实现懒加载_el-table懒加载如何使用
- 5github项目创建, git常用指令,git项目实操_github 在目录下新建项目命令
- 6Transformer 完整代码实现_transformer完整代码
- 7常见的前端面试题【90道】
- 8Day:006(1) | Python爬虫:高效数据抓取的编程技术(爬虫工具)
- 9Redis 可视化客户端工具、fastgithub 加速器_redis客户端工具
- 10使用autodl服务器,在A40显卡上运行, Yi-34B-Chat-int4模型,并使用vllm优化加速,显存占用42G,速度18 words/s_yi34b autodl
Hadoop3 - 集群搭建_hadoop3集群搭建
赞
踩
一、Hadoop
上篇文章对 Hadoop 进行了简单的介绍,并搭建了单机版的 HDFS ,本篇文章继续搭建集群版本的 HDFS 以及 YARN,下面是上篇文章地址:
Hadoop 集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:NameNode、DataNode、SecondaryNameNode
YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:ResourceManager、NodeManager
下面准备在三台服务器上安装 HDFS集群和YARN集群,安装架构:
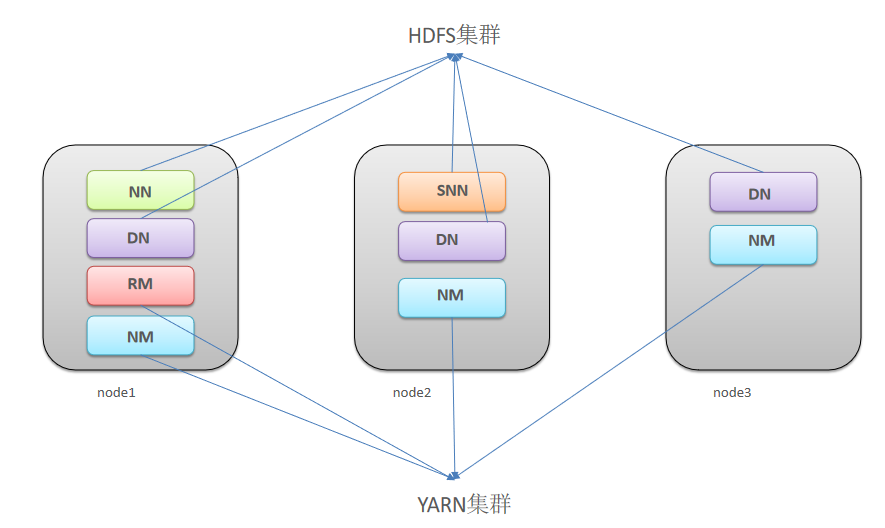
| 主机 | 规划设置主机名 | 角色 |
|---|---|---|
| 192.168.40.172 | node1 | NameNode、DataNode、ResourceManager、NodeManager |
| 192.168.40.173 | node2 | SecondaryNameNode、DataNode、NodeManager |
| 192.168.40.174 | node3 | DataNode、NodeManager |
三台主机需具备 Java 环境。
二、集群安装
1. 环境准备
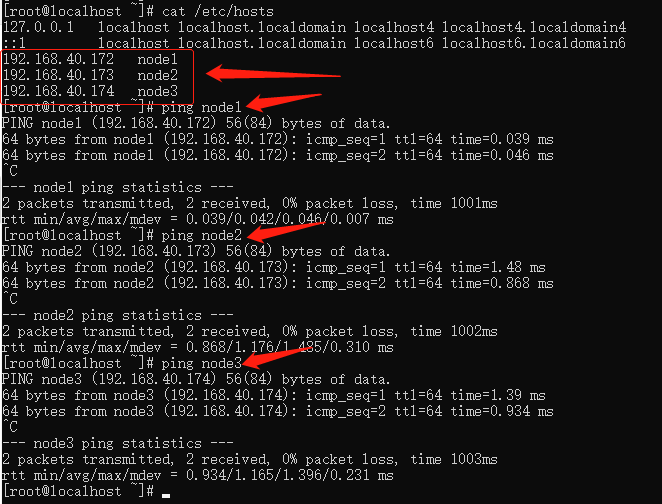
- 修改 /etc/hosts 增加映射
vi /etc/hosts
- 1
192.168.40.172 node1
192.168.40.173 node2
192.168.40.174 node3
- 1
- 2
- 3
- 关闭防火墙
#关闭防火墙
systemctl stop firewalld.service
#禁止防火墙开启自启
systemctl disable firewalld.service
- 1
- 2
- 3
- 4
- ssh免密登录(node1执行 -> node1|node2|node3)
#4个回车 生成公钥、私钥
ssh-keygen
# 将公钥给三台主机
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
- 1
- 2
- 3
- 4
- 5
- 6
- 集群时间同步(3台机器)
yum -y install ntpdate
ntpdate ntp4.aliyun.com
- 1
- 2
- 创建统一工作目录(3台机器)
mkdir -p {/export/server/,/export/data/,/export/software/}
- 1
- 下载官方安装包,这里我使用的为
3.1.4版本,将下载好的安装包,先上传至node1服务器上/export/server/下,修改完配置后再同步到另两台机器中:
2. 集群配置修改
- 进入到
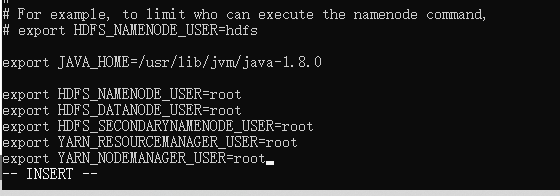
/export/server/hadoop-3.1.4/etc/hadoop/下,此处存放的为hadoop的配置文件,修改hadoop-env.sh:
文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
vi hadoop-env.sh
- 1
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 修改
core-site.xml
hadoop 的核心配置文件,有默认的配置项 core-default.xml。
core-default.xml与core-site.xml的功能是一样的,如果在core-site.xml里没有配置的属性,则会自动会获取core-default.xml里的相同属性的值。
vi core-site.xml
- 1
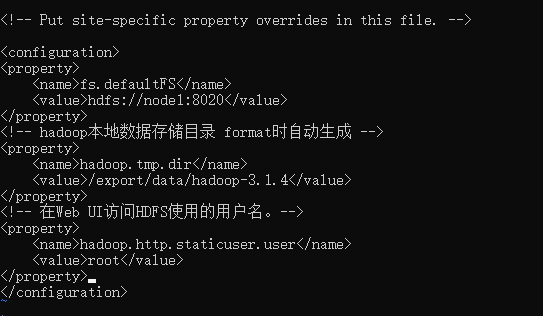
<!-- 默认文件系统的名称。通过URI中schema区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs文件系统访问地址:http://nn_host:8020。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- hadoop本地数据存储目录 format时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.1.4</value>
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 修改
hdfs-site.xml
HDFS的核心配置文件,主要配置HDFS相关参数,有默认的配置项hdfs-default.xml。
hdfs-default.xml与hdfs-site.xml的功能是一样的,如果在hdfs-site.xml里没有配置的属性,则会自动会获取hdfs-default.xml里的相同属性的值。
vi hdfs-site.xml
- 1
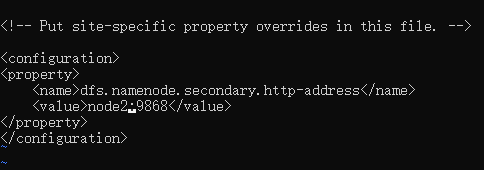
<!-- 设定SNN运行主机和端口。-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 修改
mapred-site.xml
MapReduce的核心配置文件,Hadoop默认只有个模板文件mapred-site.xml.template,需要使用该文件复制出来一份mapred-site.xml文件
vi mapred-site.xml
- 1
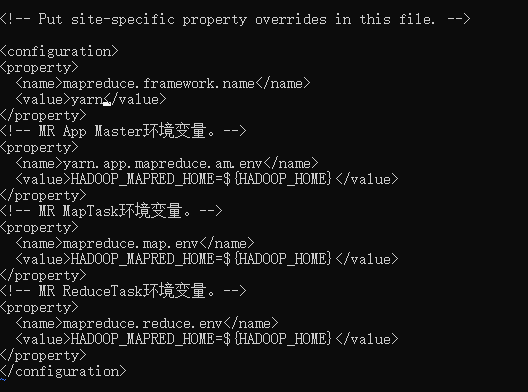
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 修改
yarn-site.xml我三台主机用的虚拟机,没有多大内存,如果资源充足可相应填大一些:
YARN的核心配置文件
vi yarn-site.xml
- 1
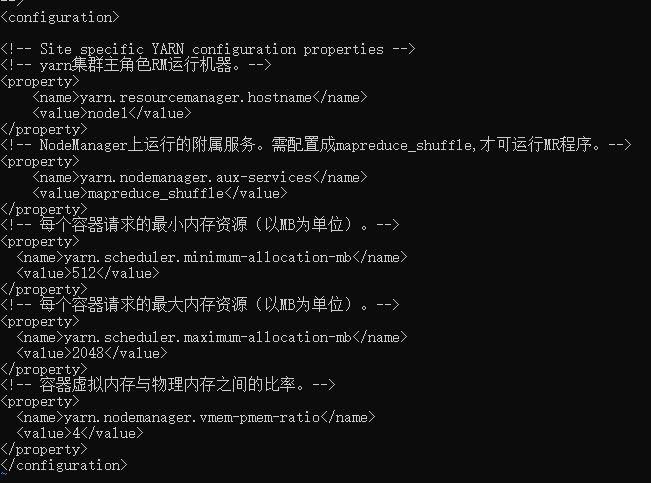
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 修改
workers
workers文件里面记录的是集群主机名。一般有以下两种作用:
- 配合一键启动脚本如
start-dfs.sh、stop-yarn.sh用来进行集群启动。这时候slaves文件里面的主机标记的就是从节点角色所在的机器。 - 可以配合
hdfs-site.xml里面dfs.hosts属性形成一种白名单机制。
dfs.hosts指定一个文件,其中包含允许连接到NameNode的主机列表。必须指定文件的完整路径名,那么所有在workers中的主机才可以加入的集群中。如果值为空,则允许所有主机。
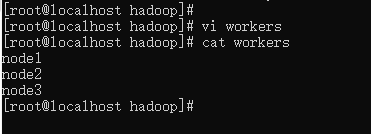
vi workers
- 1
node1
node2
node3
- 1
- 2
- 3
- 将修改后的安装包,上传至 node2、node3 主机:
cd /export/server/
scp -r hadoop-3.1.4 root@node2:/export/server/
scp -r hadoop-3.1.4 root@node3:/export/server/
- 1
- 2
- 3
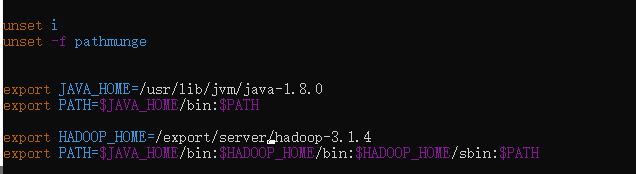
- 添加 Hadoop 的环境变量,修改
/etc/profile
vim /etc/profile
- 1
export HADOOP_HOME=/export/server/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 1
- 2
- 将修改后的环境变量同步至 node2,node3 主机
scp /etc/profile root@node2:/etc/
scp /etc/profile root@node3:/etc/
- 1
- 2
- 重新加载环境变量(3台机器都需要操作)
source /etc/profile
- 1
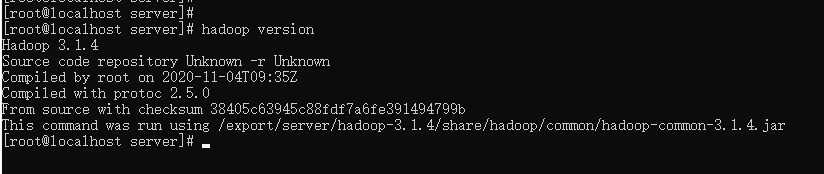
- 验证环境是否生效:
hadoop version
- 1
3. 集群安装
- 格式化 NameNode,首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的。
hdfs namenode -format
- 1
注意点:
- 首次启动之前需要format操作
- format只能进行一次 后续不再需要
- 如果多次format除了造成数据丢失外
- 还会导致hdfs集群主从角色之间互不识别
- 通过删除所有机器hadoop.tmp.dir目录重新forma解决
出现下面日志则格式化成功:

4. 集群启动
集群启动有两种方式,一种是在每台主机中启动相应的组件,另一种 hadoop 为我们提供了一键启停脚本,前提是配置好机器之间的SSH免密登录和workers文件。
在每台主机上单独启动组件
启动为 start ,停止为 stop:
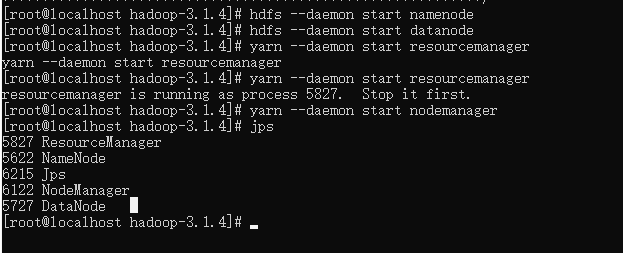
- node1 节点启动:
hdfs --daemon start namenode
hdfs --daemon start datanode
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
- 1
- 2
- 3
- 4
- node2 节点启动:
hdfs --daemon start secondarynamenode
hdfs --daemon start datanode
yarn --daemon start nodemanager
- 1
- 2
- 3
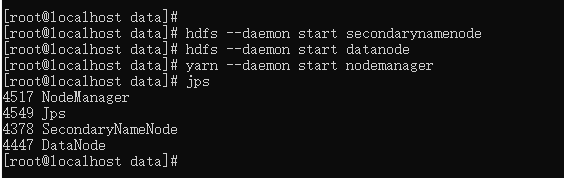
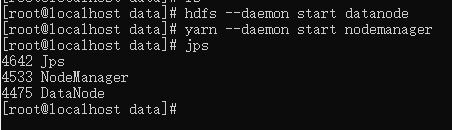
- node3 节点启动:
hdfs --daemon start datanode
yarn --daemon start nodemanager
- 1
- 2
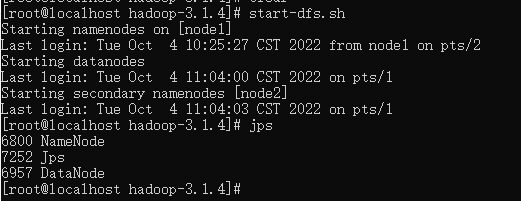
通过脚本一键启动
- HDFS集群
# 启动
start-dfs.sh
# 关闭
stop-dfs.sh
- 1
- 2
- 3
- 4
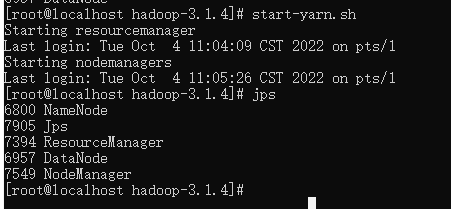
- YARN集群
# 启动
start-yarn.sh
# 关闭
stop-yarn.sh
- 1
- 2
- 3
- 4
- Hadoop集群,启停 HDFS 和 YARN
# 启动
start-all.sh
# 关闭
stop-all.sh
- 1
- 2
- 3
- 4
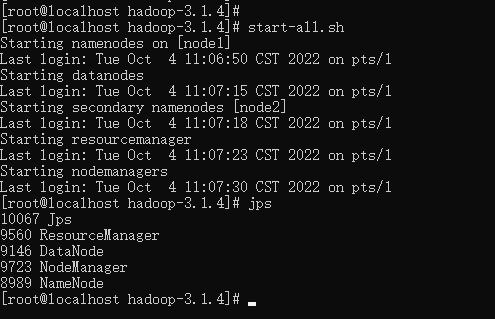
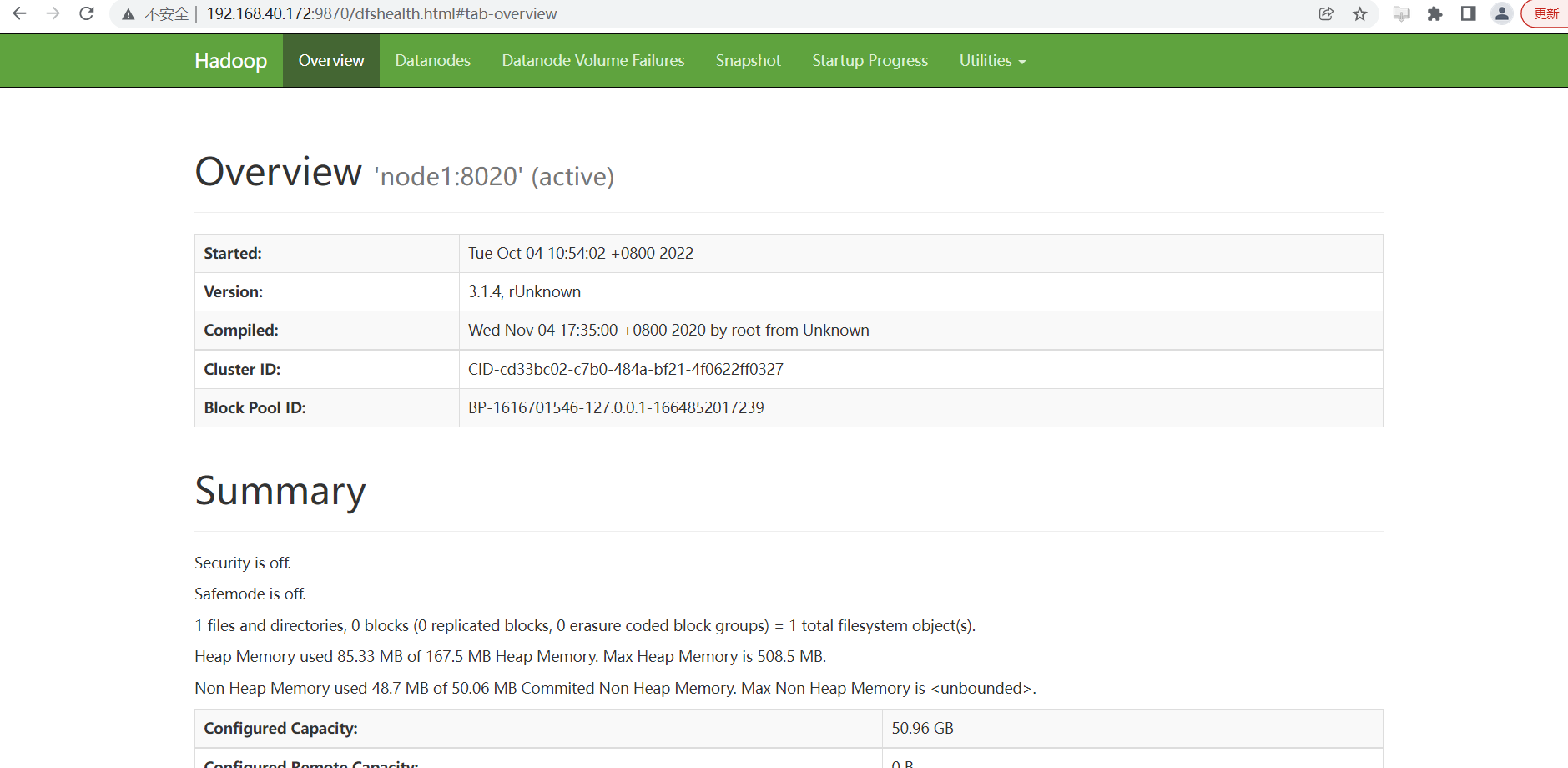
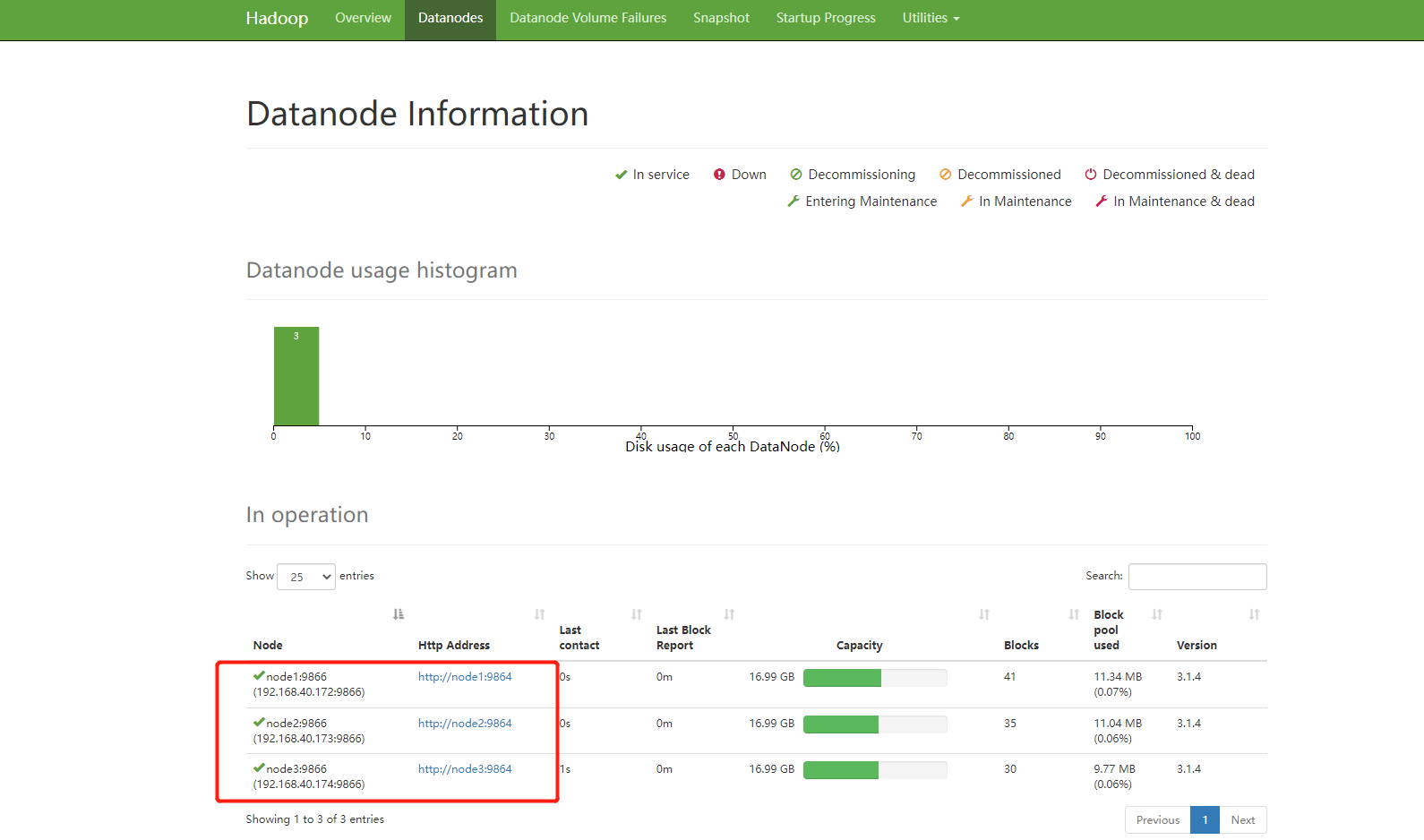
5. 可视化页面验证集群是否安装成功
- HDFS UI页面
访问地址:http://192.168.40.172:9870
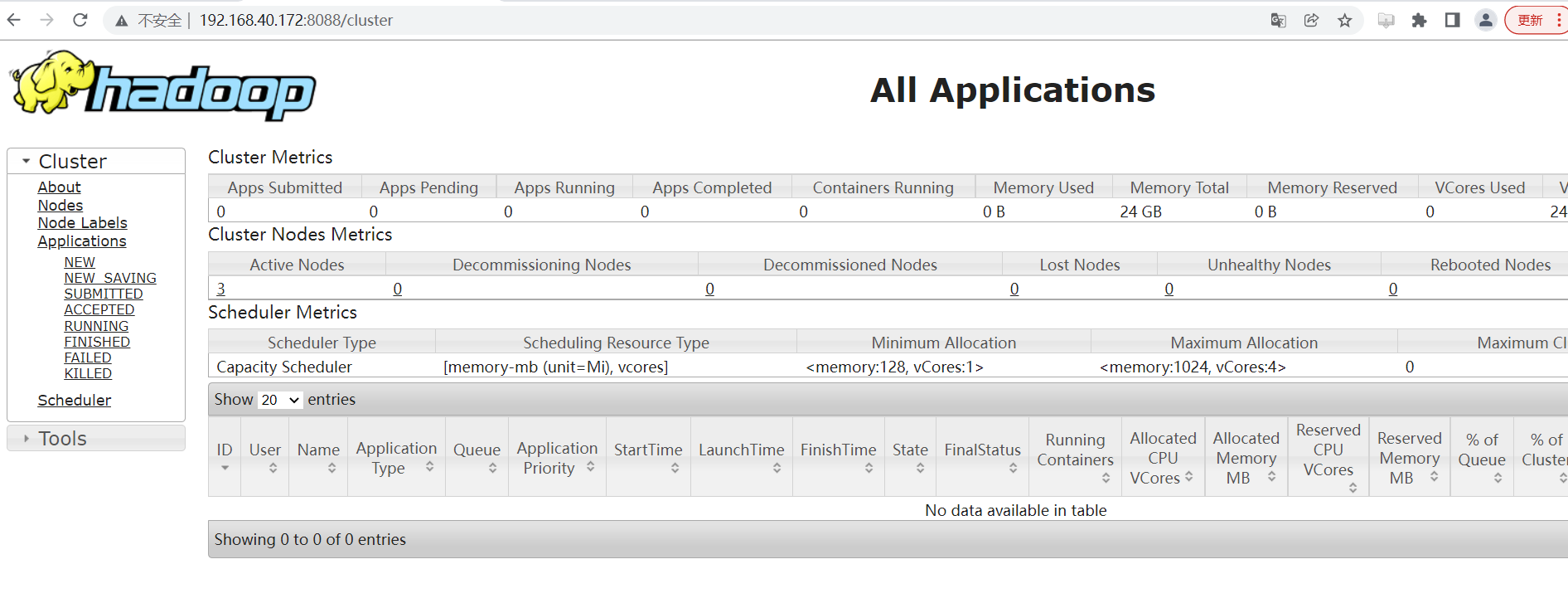
- YARN集群 UI页面
访问地址:http://192.168.40.172:8088
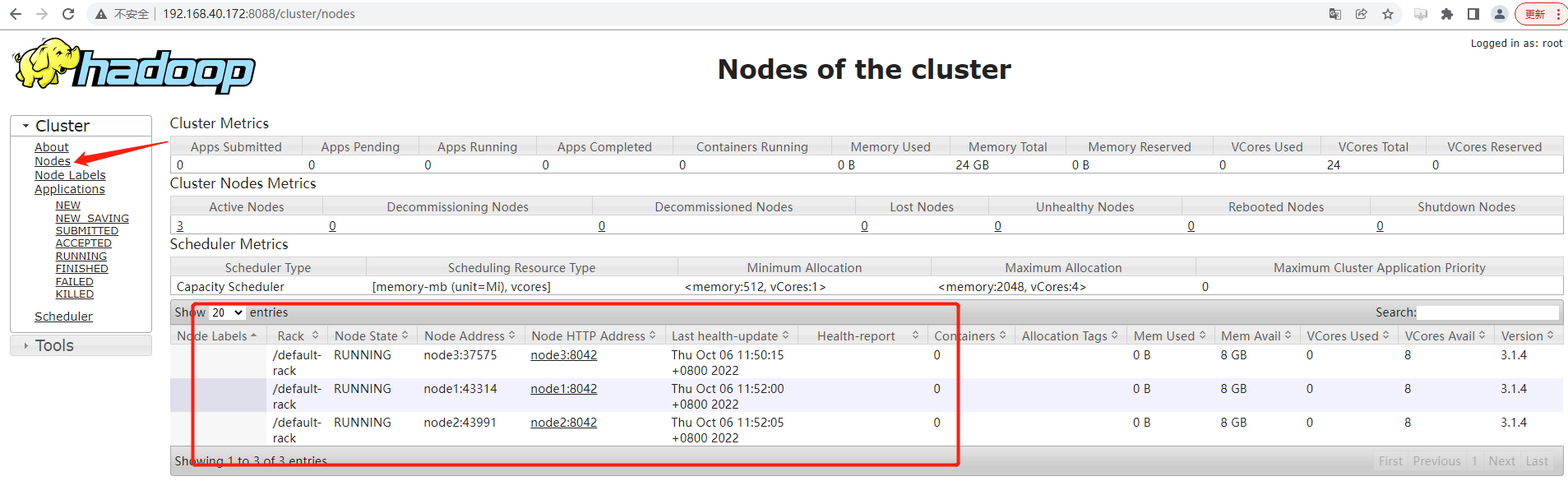
三、测试
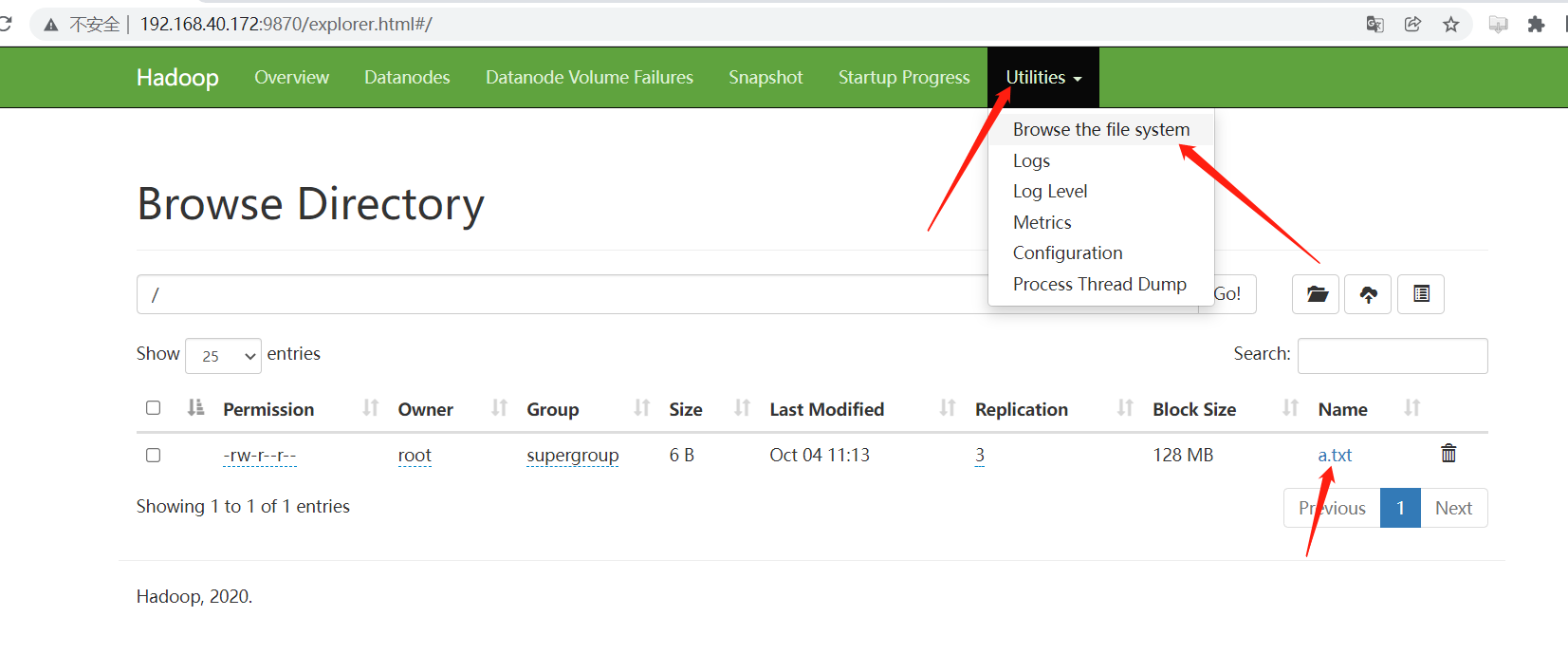
- 测试上传文件:
创建一个 txt 文件,将其上传至 HDFS 中:
echo "hello" > a.txt
- 1
上传 a.txt
hadoop fs -put a.txt /bxc
- 1

web 页面查看是否上传成功:
- 运行
mapreduce程序
在Hadoop安装包的share/hadoop/mapreduce下有官方自带的mapreduce程序。我们可以使用如下的命令进行运行测试。(示例程序jar:hadoop-mapreduce-examples-3.1.4.jar计算圆周率)
yarn jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 2 50
- 1


