
- 1绕过Cloudflare五秒盾,穿云API抓取网页不再等待_五秒盾会检测ip吗
- 2Kettle 使用详解_kettle工具
- 3基于C51的语音智能车(含循迹/跟随/避障/测速屏显/蓝牙WIFI4G控制等功能)_51单片机蓝牙遥控小车
- 4ChatGLM推出第三代基座大模型在论文阅读、文档摘要和财报分析等方面提升超过50%推理成本降低一半
- 53.3Java全栈开发前端+后端(全栈工程师进阶之路)-前端框架VUE3框架-企业级应用-Vue组合式API
- 6第十六届“华中杯”大学生数学建模挑战赛(B题)深度剖析|建模完整过程+详细思路+代码全解析_华中杯b题
- 7经典Java面试题汇总及答案解析_java问题解析思路面试题
- 8python中count函数的用法_counts在python中的用法
- 9ue引擎游戏开发笔记(26)——处理角色死亡敌人仍攻击bug
- 10大数据毕业设计:python股票数据分析可视化系统 股票预测 Arima预测算法(时间序列预测算法) Flask 框架(源码)✅_基于python的股票数据可视化与预测系统用什么算法
28. Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis
赞
踩
目录
3.2 BART-based Generative Framework
4.4 In-depth Analysis of Pre-training Tasks
模型简称:VLP-MABSA
- Author
,
,and
- Institutions
School of Computer Science and Engineering,
Nanjing University of Science and Technology, China (南京理工大学)
Abstract
作为情感分析的一个重要子任务,多模态情感分析 MABSA (Multimodal Aspect-Based Sentiment Analysis)近些年,引起了广泛的关注。然而,以前的方法要么(i)分别使用预先训练的视觉和文本模型,它们忽略了跨模态对齐,要么(ii)使用预先训练的一般预训练任务的视觉语言模型 (vision-language models),这不足以识别细粒度 (fine-grained)的属性、情感及其跨模态的对齐。
为了解决这些限制,针对MABSA任务,我们提出了一个特定任务的视觉-文本 (vision-language)预训练框架,其是一个通用的编码、解码框架,适用于所有的预训练和下游任务 (downstream tasks)。此外,针对文本、视觉、和多模态,我们分别设计了三种特定任务的预训练任务。实验结果证明:我们的方法在三个MABSA任务上,均优于当前的sota模型。进一步的分析也证明了我们方法的有效性。
作者开源了源码,地址为:https://github.com/NUSTM/ VLP-MABSA.
1. Introduction
近些年,多模态情感分析任务(MABSA任务又叫做Target-Origented Multimodal Sentiment Analysis 或Entity-Based Muitimodal Sentiment Analysis)发展迅猛。先前的研究主要针对MATE(Multimodal Aspect Term Extraction:多模态属性抽取)和MASC(Multimodal Aspect-oriented Sentiment Classification:多模态属性情感分析)两个子任务。这两个任务互相联系。
任务定义:
给定一个text-image对作为输入,MATE任务是抽取文本中提到的属性词。MASC任务是对每一个抽取的属性词进行情感分类。
最近,Ju等人介绍了联合多模态属性情感分析JMASA(Joint Multimodal Aspect-Sentiment Analysis)任务。JMASA旨在同时抽取属性词极其相对应的情感词(成对抽取)。如下图1,JMASA任务是识别出所有的属性-情感词对,在下图中,JMASA的抽取结果是:(Seigio Ramos, Positive), (UCL,Netural).

上述提及的大多数MABSA研究都是基于使用预训练模型,分别获得文本或视觉的特征(如使用BERT获取文本特征,使用ResNet获取图片特征)。分开的本文或视觉预训练模型忽略了文本和图片的对齐。因此,使用视觉-文本预训练模型是捕获交叉模型对齐是极其重要的。然而,针对MABSA任务的视觉-文本预训练模型是缺乏的。
据我们所知,很少有研究关注于MABSA子任务之一的视觉语言预训练。这些研究的一个主要的不足之处是:它们采用普遍的视觉-文本理解任务去捕获文本-图片对齐。这种一般的预训练不足以识别细粒度的属性词、情感以及它们跨语言和视觉模式的一致性。因此,设计特定于任务的视觉语言预训练,为MABSA任务建模各个属性词、情感及其对齐是很重要的。
为解决这个问题,本文提出了一个基于特定任务的VLP-MABSA (Vision-Language Pre-training framework for MABSA)。特别地,受鼓舞于基于BART生成模型的成功,我们首先构建一个基于BART的多模态生成框架 为视觉-语言预训练和下游MABSA任务。然后,我们提出三种类型的视觉-语言预训练任务,包括 1)针对文本的MLM (Masked Language Modeling)和AOE (Aspect-Opinion Extraction) ; 2) 针对视觉的MRM (Masked Region Modeling ) 和AOG (Aspect-Opinion Generation); 3)多模态的 MSP(Multimodal Sentiment Prediction)。
与一般的预训练方法相比较,本文的基于特定任务的预训练方法将属性词、情感词、情感监督融合在一起,这促使了预训练模型去捕获对MABSA任务来说重要的主观和客观的信息。
为了评估本文方法的有效性,我们使用一个广泛使用的Twitter数据集MVSA-Multi 实现粗粒度的文本-图片情感分析。然后,我们采用一些代表性的预训练模型和基于规则的方法去获取对我们的AOE和AOG任务的属性和情感监督。由于数据集为每条多模态推文提供了情绪标签,因此我们将它们作为MSP任务的监督。
本文的贡献如下:
1)针对MABSA任务,我们介绍了一个特定任务的视觉-语言预训练框架(VLP-MABSA), 其是一个通用的多模态编码解码结构,适用于所有的预训练和下游任务。
2)除了MLM和MRM任务,我们进一步介绍三种特定任务的预训练任务,包括Textual Aspect-Opinion Extraction, Visual Aspect-Opinion Generation, 和Multimodal Sentiment Prediction 分别抽取属性词、情感词和它们的对齐。
3)在MABSA三个子任务上的实验证明,我们的预训练方法获得了优于当前SOTA的性能。对监督和弱监督设置的进一步分析证明了每个预训练任务的有效性。
2 Related Work
此处不翻译了,感兴趣的自己去看原文。
3 Methodology
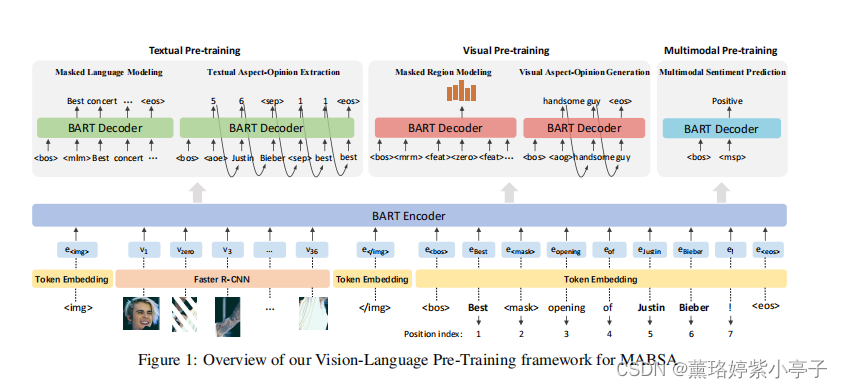
图1 是本文的架构,基准模型是BART, 其是一个用于序列到序列模型的去噪自动编码器。我们扩展了BART来编码文本和视觉输入,并解码来自不同模式的预训练和下游任务。在下面的小节中,我们首先介绍我们的特征提取器,然后说明我们的模型的编码器和解码器,然后描述三种类型的预训练任务和下游MABSA任务的细节。
3.1 Feature Extractor
Image Representation
Follow很多已有的视觉-语言预训练模型,本文利用Faster R-CNN 抽取视觉特征。具体来说,我们采用FasterR-CNN从输入图像中提取所有候选区域。
Text Representation
对于文本输入,我们首先将文本tokenizen,然后,将tokens喂入嵌入矩阵。 文本tokens的embeddings被用作文本特征。
3.2 BART-based Generative Framework
我们使用了一个BART-based的生成框架来执行视觉语言的预训练和下游的MABSA任务。
Encoder
我们模型的编码器是一个多层双向的Transformers (multi-layer bidirectional Transformers)。图上图所示,为了区分不同的输入,我们使用<img>表示图片特征的开始,使用</img>表示图片特征的结束, 使用<bos>和<eos>分别表示文本特征的开始和结束。
在本文中,我们将拼接之后的多模态输入表示为X
Decoder
我们模型的解码器也是一个多层的Transformers。与编码器的区别是:解码器在产生输出时是单向的,而编码器是双向的。由于所有的预训练任务共享相同的解码器,我们在解码器输入的开始插入两个特殊的tokens来指示不同的预训练任务。我们使用<bos>表示生成的开始,并且,使用一个基于特定任务的特殊token表示任务的类型。具体的,针对MLM,AOE,MRM,AOG,MSP任务,分别使用<bos><mlm>,<bos><aoe>,<bos><mrm>,<bos><msp>。
3.3 Pre-training Tasks
本文使用数据集是MVSA-Multi,数据统计情况如表2

这个数据集提供了文本-图片成对输入,以及关于其的粗粒度情感。
3.3.1 Textual Pre-training
Textual Pre-training 包含两个任务:一个常见的用于构建文本和图片特征对齐的MLM任务,及从文本中抽取属性词和情感词的特定任务的文本 AOE任务。
Masked Language Modeling (MLM)
在MLM任务中,我们使用与BERT相同的策略,随机mask 15%的tokens。 MLM任务的目标是基于图片和masked 文本生成原始文本。MLM损失函数公式如下:
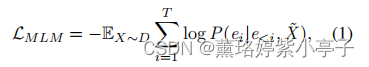
Textual Aspect-Opinion Extraction (AOE)
AOE任务是从文本中抽取出属性词和情感词。因为MVSA-Multi数据集并没有标注属性词和情感词,因此,我们采用预训练的方法实现属性词标注,使用基于规则的方法实现情感词标注。具体来说,对于属性提取,我们使用了来自一个著名的命名实体识别(NER)工具的预训练模型对数据集中的每条推文执行NER,并将已识别的实体视为属性词。在进行情感抽取时,我们使用了一个广泛使用的情感词汇SentiWordNet来获取情感词汇词典。对每一个给定的推文,如果它的子序列能够与字典中的单词匹配,我们就将其标记为情感词。 (in word: 针对未标记属性词和情感词的MVSA-Multi数据集,如何实现数据标注工作)
我们使用表示多模态拼接输入过编码器之后的输出,
表示
的文本部分,
表示
的视觉部分。解码器将多模态编码输出
和先前解码器的输出
作为输入,使用下面的公式预测每一个token的概率分布:

3.3.2 Visual Pre-training
Visual Pre-training包含两个任务:一个常见的MRM和一个特定任务的AOG任务,AOG捕获图片的主观和客观信息。
Masked Region Modeling (MRM)
MRM任务旨在预测掩蔽区域的语义类分布。如图1所示,针对每一个输入,我们随机mask 15%的图片区域,将被masked的区域用0向量替换。对解码器的输入,我们首先加入两个特殊的token:<bos> <mrm>,每一个被masked的区域使用<zero>表示, 每一个保留的区域使用<feat>表示。将输入喂入编码器之后, 使用MLP分类器预测语义类分布。使用表示z-th个masked 区域的类分布,使用
表示使用Faster-CNN之后检测到的类分布。MRM的损失函数是最小化两个类分布的KL散度(KL divergence)。
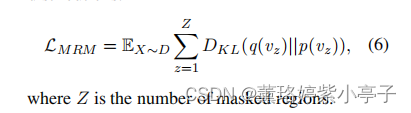
Visual Aspect-Opinion Generation (AOG)
AOG任务旨在从给定的图片中,生成属性-情感对。
3.3.3 Multimodal Pre-training
Multimodal Pre-training又一个任务,称为MSP(Multimodal Sentiment Prediction)。与上述的监督信号仅来自一种模态的预训练任务不同,MSP的监督信号来自多模态,它可以增强模型来识别语言和视觉中的主观信息,并捕获它们丰富的对齐。
Multimodal Sentiment Prediction (MSP)
MVSA-Multi提供了粗粒度的情感标记。我们使用其情感标记作为我们MSP任务的监督信号。我们将MSP任务看作一个分类任务。我们将两个特殊的tokens<bos><msp>喂入解码器,使用如下的公式预测情感分布P(s):


3.3.4 Full Pre-training Loss
为了最优化模型的所有参数,我们采用自动最优策略去自动最优化我们的五个预训练任务,函数如下:
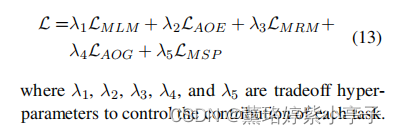
3.4 Downstream Tasks
我们将MABSA的三个子任务作为我们的下游任务,包括Joint Multimodal Aspect-Sentiment Analysis (JMASA), Multimodal Aspect Term Extraction (MATE), and Multimodal Aspect-oriented Sentiment Classifification (MASC)。三个子任务的输出如下:

4 Experiment
4.1 Settings


4.2 Compared System
在本节中,我们将介绍四种针对不同任务的比较系统。
具体不赘述,可参看论文。
4.3 Main Results
在本节中,我们将分析不同方法对MABSA的三个子任务的结果。
Results of JMASA
表4记录了JMASA不同方法的结果。

结论:
1)在所有的基于文本的方法中,BART取得了最优的性能,并且,它优于一些多模态的方法。
2)在多模态的方法中,JML取得了比先前方法更优的性能,主要是由于它辅助了图像和文本之间的关系检测。
3)在所有的方法中,VLP-MABSA在两个数据集中,性能都最优。
Results of MATE and MASC
表5和表6分别是MATE和MAS任务的结果。
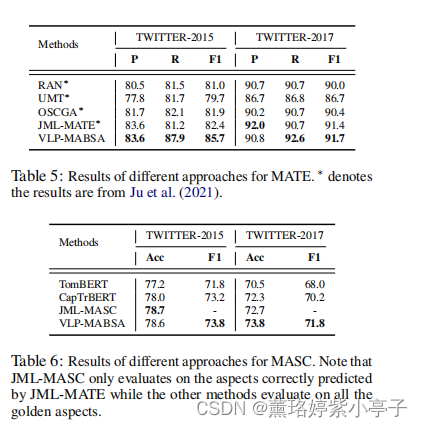
与JMASA子任务的趋势相似,我们可以清楚地观察到,我们提出的方法VLP-MABSA方法通常在两个数据集上取得最好的性能,除了twitter-2015的准确性度量。这些观察结果进一步证明了我们提出的训练前方法的一般有效性。
4.4 In-depth Analysis of Pre-training Tasks
为了探究每个预训练任务的影响,我们在使用完整训练数据集和弱监督设置下仅随机选择200个训练样本的全监督设置上进行了全面的消融研究进行微调。
Impact of Each Pre-training Task
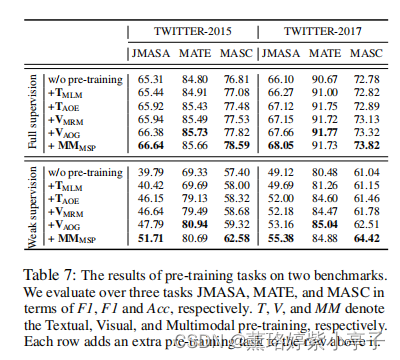
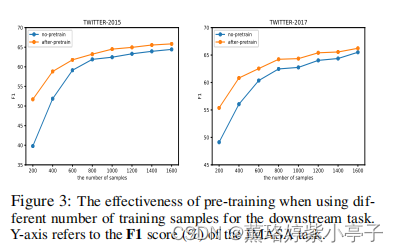
为了更好地理解预训练的影响,我们在采用不同数量的样本进行下游训练时,比较了有和没有预训练的结果。我们使用JMASA任务作为例子来观察其影响。如图3所示,当样本量较小时,预训练可以带来巨大的改进。相比之下,当样本量增大时,预训练带来的改进相对较小。这进一步说明了我们的训练前方法的鲁棒性和有效性,特别是在低资源的场景中。
5 Conclusion
在本文中,我们提出了一个特定任务的视觉语言预训练框架的多模态情绪分析(VLP-MABSA)。我们进一步从语言、视觉和多模态模式分别设计了三种预训练任务。实验结果表明,我们提出的方法在MABSA的三个子任务上通常优于现有的方法。我们的工作是迈向MABSA统一的视觉语言预培训框架的第一步。在未来,我们计划将我们的预训练方法应用于一个更大的数据集,并在我们的预训练框架中考虑图像和文本之间的关系。我们希望这项工作能够为MABSA的研究带来新的见解和前景。

