
- 1详解MySQL事务原理_mysql acdi原理
- 2httprunner测试框架3--har2case录制脚本
- 3leetcode 27. 移除元素_leetcode 27 java
- 4SourceTree 教程文档(安装并设置SourceTree)
- 5C++(QT)调用snap7库连接西门子plc_c++ 对接plc 西门子s7-400
- 6python:pycharm虚拟解释器报错环境位置目录为空
- 7Ubuntu16.04 使用Python获取本机IP_ubuntu python 自动读取本地ip
- 8Install Python 3.7.*_conda install python==3.7.2 -n
- 9Oracle:左连接、右连接、全外连接、(+)号详解_左外连接和右外连接详解
- 10近义句子转换软件 - 同义词转换器软件
python基础知识点大全_萝卜蹲python
赞
踩
python知识点大全,基础阶段一篇到底
持续更新中…
更新日志:
- 2023-09-25 对部分代码片的缩进问题进行更正,后续不在进行变更了。
- 2023-04-04 修改了集合数据类型删除的笔误。
- 2022/10/4 更新了一些写错,以及上传CSDN造成的格式/排版/错别字等错误。
- 2022/9/8 常用模块章节因为时间关系,后续需要自行查阅相关资料。
- 2022/9/3 常用模块章节补充了os模块
声明:
- 本文采用大白话+个人理解的形式进行介绍,尽可能的快速了解,如 举的例子、理解的不对或者不专业、不恰当,请务必狠狠指出[doge]
卫星:liuyu719719
欢迎讨论交流
一、CPython
什么是CPython?
- CPython是特指C语言实现的Python,就是原汁原味的Python。
- 之所以使用CPython这个词,是因为Python还有一些其它的实现,比如Jython,就是Java版的Python,还有烧脑的PyPy,使用Python再把Python实现了一遍。
CPython
当我们从Python官方网站下载并安装好Python 3.5后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器,CPython是使用最广的Python解释器。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE,CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
- 1
PyPy
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。 绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
- 1
- 2
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
- 1
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
- 1
编译型与解释型编程语言
- 编译型相当于厨师直接做好一桌子菜,顾客来了直接开吃。
- 解释型就像吃火锅,厨师把菜洗好,顾客需要自己动手边煮边吃。
- 所以,效率上来说解释型语言自然比不过编译型语言,当然也不是绝对了。
Python(这里主要是指CPython)并不是严格的解释型语言,因为 Python 代码在运行前,会先编译(翻译)成中间代码,每个 .py 文件将被换转成 .pyc 文件,.pyc 就是一种字节码文件,它是与平台无关的中间代码,不管你放在 Windows 还是 Linux 平台都可以执行,运行时将由虚拟机逐行把字节码翻译成目标代码。
我们安装Python 时候,会有一个 Python.exe 文件,它就是 Python 解释器,你写的每一行 Python 代码都是由它负责执行,解释器由一个编译器和一个虚拟机(PVM)构成,编译器负责将源代码转换成字节码文件,而虚拟机负责执行字节码,所以,解释型语言其实也有编译过程,只不过这个编译过程并不是直接生成目标代码,而是中间代码(字节码),然后再通过虚拟机来逐行解释执行字节码。
一般认为,Python与Java都是解释型语言,只是不那么纯粹。也可以认为它们是先编译再解释的编程语言。并非所有高级语言都是要么是编译型语言,要么就是解释型语言。
python解释器、pycharm、IDE到底是什么?
- IDE是辅助程序员开发的应用软件。
- pycharm是IDE中用于辅助python程序员的软件之一。
- CPU不能直接处理Python语言,只能处理机器语言,所以python解释器,就是把python语言翻译成计算机CPU能听懂的机器指令语言。
python.exe解释器、pycharm、的下载及配置本文略。
二、 基本语法
2.1 print输出
函数名:
print()
- 1
作用:
- 用于控制台/命令行打印输出
代码示例:
print('你好,我是print') #输出结果:你好,我是print print(998) #输出结果:998
- 1
- 2
附:
- 本小节仅为初识print,更多用法请前往“内置函数”章节
2.2 变量、常量与垃圾回收机制
2.2.1 变量
什么是变量:
- 变量就是可以变化的量,量指的是事物的状态,比如人的年龄、性别,游戏角色的等级、金钱等等
为什么要有变量:
- 程序执行的本质就是一系列状态的变化,“变”是程序执行的直接体现,所以我们需要有一种机制能够反映或者说是保存下来程序执行时状态,以及状态的变化。
如何使用变量:
先定义,后使用
变量的定义由三部分组成:
变量名 = 值
- 1
变量名:相当于门牌号码,指向值所在的内存地址,是访问到值的唯一方式。
=: 等号为赋值符号,用来将变量值的内存地址绑定给变量名
值: 变量的值,就是我们存储的数据。代码示例:
name = 'liuyu' age = 22
- 1
- 2
变量的命名规范:
-
变量名只能是字母、数字或下划线的任意组合
-
变量名的第一个字符不能是数字
-
关键字不能声明为变量名,常用关键字如下
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from','global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']- 1
变量的命名风格
-
驼峰体
userName = 'liuyu' userAge = 22- 1
- 2
-
纯小写下划线(在python中,变量名的命名推荐使用该风格)
user_name = 'liuyu' user_age = 22- 1
- 2
变量具有的三大特性
- id,反应的是变量在内存中的唯一编号,内存地址不同id肯定不同。
- type,变量值的类型。
- value,变量值。
x='liuyu'
print(id(x),type(x),x)
# 输出结果:
2672014718640 <class 'str'> liuyu
# 内存地址 属于str字符串类 内存地址对应的值
- 1
- 2
- 3
- 4
- 5
可以多个变量一起赋值
a,b,c = 1,2,3
print(a,b,c)
# 输出结果: 1 2 3
a,b,c = [1,2,3] # 列表数据类型,后续介绍
print(a,b,c)
# 输出结果: 1 2 3 #拿到的是列表内对应索引的值
a,b,c = {'a':'A','b':'B','c':'C'} # 字典数据类型,后续介绍
print(a,b,c)
# 输出结果: a b c #拿到的是字典的Key,不是value。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.2.2 常量
什么是常量:
- 常量指在程序运行过程中不会改变的量
- 比如:圆周率 3.141592653…
如何使用常量:
- 在Python中没有一个专门的语法定义常量,约定俗成是用全部大写的变量名表示常量。如:PI=3.14159。所以单从语法层面去讲,常量的使用与变量完全一致。
2.2.3 内存指向
name = 'liuyu'
- 1
在这段代码中,我们定义了变量name,随后赋值为“liuyu”,那么我们的name和值是如何存储的呢?
- 内存中分为栈区和堆区。
- 栈区用来存放变量指向的内存地址,这个内存地址相当于值的门牌号,可以通过这个门牌号找到堆区的值。
name2 = 'liuyu'
- 1
此时重新定义一个变量name2,值也为’liuyu’,那么此时内存中是如何存储的呢?
-
因为liuyu这个值,还在被name变量所指向,所以还存在内存中。
-
当name2变量的值与name相同时,不再重新开辟空间,而是直接将name2指向name的值。
栈区 堆区 name ---- name=0xfff001 ---- 0xfff001='liuyu' | | name2 ---- name=0xfff001 --------- 1
- 2
- 3
- 4
- 5
2.2.4 垃圾回收机制
解释器在执行到定义变量的语法时,会申请内存空间来存放变量的值,而内存的容量是有限的,这就涉及到变量值所占用内存空间的回收问题,当一个变量值没有用了(简称垃圾)就应该将其占用的内存给回收掉。
那什么样的变量值是没有用的呢?
- 由于变量名是访问到变量值的唯一方式,所以当一个变量值不再关联任何变量名时,我们就无法再访问到该变量值了,该变量值就是没有用的,就应该被当成一个垃圾回收。
什么是垃圾回收机制
- 垃圾回收机制(简称GC)是Python解释器自带一种机,专门用来回收不可用的变量值所占用的内存空间
为什么要有垃圾回收机制
- 程序运行过程中会申请大量的内存空间,而对于一些无用的内存空间如果不及时清理的话会导致内存使用殆尽(内存溢出),导致程序崩溃,因此管理内存是一件重要且繁杂的事情,而python解释器自带的垃圾回收机制把程序员从繁杂的内存管理中解放出来。
垃圾回收机制原理分析
Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用的问题,并且通过“分代回收”(generation collection)以空间换取时间的方式来进一步提高垃圾回收的效率。
- 引用计数
- 标记清除
- 分代回收
了解即可,这个不需要程序员自己去操作。
2.3 input输入
函数名:
input('提示信息') # 运行该代码,会弹出'提示信息',然后等待输入数据,输入之后该函数会将输入的数据返回,所以应该定义变量去接收,变量接收的数据为字符串类型
- 1
- 2
作用:
- 用于获取输入的信息
代码示例:
str1 = input("你叫什么名字?") #输入:liuyu str2 = input("你几年几岁了") #输入: 22 print("你是"+str1,"今年"+str2) #打印字符串拼接之后的结果:你是liuyu 今年22 # 字符串拼接后续有介绍
- 1
- 2
- 3
注意:
- 返回的数据为字符串数据类型(数据类型详情见下一章节),如果有数字计算,一定要转换数据格式。
三、数据类型
3.1 int整型与float浮点型
int整型
作用:
- 用来记录人的年龄,出生年份,学生人数等整数相关的状态 。
定义:
age=18 birthday=1990 student_count=48
- 1
- 2
- 3
- 4
- 5
float浮点型
作用:
- 用来记录人的身高,体重,薪资等小数相关的状态
定义:
height=172.3 weight=103.5 salary=15000.89
- 1
- 2
- 3
- 4
- 5
应用:数学计算
height=172.3
height2 = 180
print(height+height2)
# 输出结果: 352.3
- 1
- 2
- 3
- 4
3.1.1 int与str相互转换
在有些情况时,可能会需要将字符串1与字符串2进行数值相加,但因为是字符串数据类型,最后的结果是拼接而非数值相加。
所以我们可以利用数据类型之间的转换,将str转int,那么反过来,我们也会有很多种情况,是需要将int转成str的。
int转str
- 函数名str()
num = 998 num_str = str(num) print(num_str,type(num_str)) # 998 <class 'str'>
- 1
- 2
- 3
str转int
- 函数名int()
str1 = '100' num = int(str1) print(num,type(num)) # 100 <class 'int'>
- 1
- 2
- 3
3.2 str字符串
作用:
- 用来记录人的名字,家庭住址,性别等描述性质的状态
定义:
name = 'liuyu' address = '上海市徐汇区' sex = '男'
- 1
- 2
- 3
字符串的特点:
使用
单引号、双引号、三引号包裹起来的文本。另外,三引号可以折行
a = 'AAA' #单引号 b = "BBB" #双引号 # 三引号 abcd = """ 床前明月光, 你是头上慌。 """ print(abcd) # 输出结果: # 床前明月光, # 你是头上慌。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
字符串的应用
-
字符串可以拼接
a = '加油' b = '吧' c = a + b #字符串拼接 print(c) # 输出结果: 加油吧- 1
- 2
- 3
- 4
-
字符串可以做运算
print('坚强'*8) # 输出结果:坚强坚强坚强坚强坚强坚强坚强坚强- 1
-
字符串可以嵌套
第一种
print("my name is '迪迦'") #输出结果: my name is '迪迦'- 1
第二种
print('my name is \'迪迦\'') #输出结果: my name is '迪迦'- 1
另外,双引号可以内嵌单引号的内容,同时单引号也可以内嵌双引号的内容。
print("我真的'栓Q'。") #输出结果:我真的'栓Q'。- 1
也可以使用“\”反斜杠,来屏蔽后面字符的特殊含义,使其变成普通的引号。
print('\'测试\'') #输出结果:'测试'- 1
3.2.1 str的切片
作用:
- 在字符串中,切取自己想要的“片段”,就是切片。
格式:
取单个元素
str[索引] # 索引的值是根据str的最小元素位数来定义的。
- 1
- 2
取一段元素
str[起始索引:结束索引:步长]
- 1
步长: 表示每隔多少个元素取值
特点:
- 顾头不顾腚,当切片时最后一位不取,会取最后一位之前的。
引子:
#这是个字符串,他的最小元素是 a b c d
a = 'abcd'
#a在整个字符串从左到右的第一位 b在第二位 c在第三位 d在第四位
print(a[1]) #输出结果为 b
- 1
- 2
- 3
- 4
疑问:
- 明明我要输出的是a这个字符串的第一位元素a啊,为什么最后结果是第二位元素b啊。
答:
- 因为str切片是按照索引的,而索引的值是从0开头的,而我们刚刚是从1开头的,所以要想print的结果为a,则需要减一,即a的索引为0、b的索引为1、c的索引为2、d的索引为3
- 如果一个字符串特别长,又不想从前往一直数到末尾,-1可以表示最后一位。
代码示例:
a = 'abcd'
print(a[0]) #输出结果为 a
print(a[3]) #输出结果为 d
str = '你好特别,就是么有钱,我们不合适'
str1 = str[0] + str[2] + str[7]
print(str1) #输出结果:你特么
learn = '学着好特么累啊你还学不'
learn2 = learn[0] + learn[-1] #取第一位和最后一位,并拼接为一个字符串。
print(learn2) #输出结果:学不
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
以上为单个切片取值,那么我要取一小段或倒着取该怎么操作呢。
learn = '学着好特么累啊你还学不'
print(learn[2:-1]) #输出结果:好特么累啊你还学
- 1
- 2
注:
-
因为切片有个规则顾头不顾尾,即取起始索引,到结束索引之前那一段的内容,但不包括结束索引的。
-
所以在上述案例中,最后以为的"不"字,并没有通过切片取到。
-
要想获取到最后以为,可以不写结束索引,如下
learn = '学着好特么累啊你还学不' print(learn[2:]) #输出结果: 好特么累啊你还学不- 1
- 2
- 3
步长的运用
learn = '学着好特么累啊你还学不'
print(learn[2:7:2]) # 最后一个2为步长,表示每隔2个再取值。
#输出结果:好么啊
print(learn[3:0:-1]) #当步长为‘-1’时为倒着取,所以开始索引要比结束索引靠后,并且0这一位因为变成了末尾,所以取不到,只能取到索引为1的。
#输出结果:特好着
print(learn[5]) #取单个时,不会受到‘顾头不顾腚’规则的影响
#输出结果:累
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.2.2 str的常用方法
汇总一览:(点击可进行跳转)
| 用法 | 作用 |
|---|---|
| bool(str) | str转bool,字符串为空转为False,不为空转为True |
| ‘连接符’.join([str1,str2,str3]) | 拼接字符串 |
| string.capitalize() | 字符串首字母大写 |
| string.upper() | 字符串字母全大写 |
| string.lower() | 字符串字母全小写 |
| string.swapcase() | 字符串字母大小写反转 |
| string.title() | 以空格或特殊字符分开的首字母大写 |
| string.center(x,“填充物”) | 总长度为x字符串居中,当x大于str的长度时用填充物填充 |
| string.startswith(‘xxx’,起始索引,结束索引) | 判断字符串是否以xxx开头,也可以切片再进行判断 |
| string.endswith(‘xxx’) | 判断字符串是否以xxx结尾 |
| string.find(‘xxx’,起始索引,结束索引) | 查找字符串的元素并返回索引,可切片查找 |
| string.strip() | 去掉字符串首尾的空格 |
| string.count(‘xxx’) | 计算元素xxx出现的次数 |
| string.split(“xxx”) | 以xxx分割,字符串分割之后返回的数据类型为列表 |
| string.format() | 字符串的格式化 |
| string.replace(‘旧字符’,‘新字符’,‘替换到第几次停止’) | 字符串替换 |
| len(str) | 计算元素个数 |
| max(str) | 返回最大元素 |
| min(str) | 返回最小元素 |
注:
- str字符串为不可变数据类型,所以,本章节所有的字符串方法,并不会对原数据有任何修改,
str1为原字符串,str2为函数/方法处理之后返回的新值。
str类型转bool类型
函数名:
bool(string)
- 1
作用:
- 将字符串转为布尔值
- 字符串为空,则转为False,不为空转为True,主要用于if判断。
代码示例:
str1 = 'a' print(bool(str1)) #输出结果:True str1 = ' ' print(bool(str1)) #输出结果:True 因为空格也是内容 str1 = '' print(bool(str1)) #输出结果:False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
附:
- int类型也可以使用bool方法进行判断,0为False,其他数值为True
使用Join方法进行字符串拼接
函数名:
'连接符'.join()
- 1
作用:
将多个字符串拼接成一个字符串。
在python中不推荐使用字符串拼接,推荐使用join
而有些语言会推荐使用字符串拼接的方式,比如JavaScript
代码示例:
a = 'www' b = 'baidu' c = 'com' new_str = '.'.join([a,b,c]) print(new_str) #输出结果: www.baidu.com
- 1
- 2
- 3
- 4
- 5
- 6
capitalize 首字母大写
函数名:
string.capitalize()
- 1
作用:
- 返回字符串首字母大写
- 对调用该方法的字符串,没有任何影响。
代码示例:
str1 = 'liu yu' print(str1.capitalize()) # 输出结果: Liu yu
- 1
- 2
该方法会返回处理好的字符串(首字母大写),并不会对原字符串产生影响。
upper 全大写
函数名:
string.upper()
- 1
作用:
- 返回字符串的全大写
代码示例:
str1 = 'liu yu' str2 = str1.upper() print(str2) # 输出结果: LIU YU
- 1
- 2
- 3
lower 全小写
函数名:
string.lower()
- 1
作用:
- 返回字符串的全小写
代码示例:
str1 = 'LIU YU' str2 = str1.lower() print(str2) # 输出结果: liu yu
- 1
- 2
- 3
swapcase 大小写反转
函数名:
string.swapcase()
- 1
作用:
- 返回字符串的大小写反转
代码示例:
str1 = 'I Love You' str2 = str1.swapcase() print(str2) # 输出结果:i lOVE yOU
- 1
- 2
- 3
title以空格或特殊字符分开的首字母大写
函数名:
string.title()
- 1
作用:
- 返回字符串以空格或特殊字符分开的首字母大写
代码示例:
str1 = 'i love you' str2 = str1.title() print(str2) # 输出结果: I Love You str1 = 'i_love_you' str2 = str1.title() print(str2) # 输出结果: I_Love_You
- 1
- 2
- 3
- 4
- 5
- 6
- 7
center 居中
函数名:
string.center()
- 1
代码示例:
str1 = 'AA' str2 = str1.center(4,'-') print(str2) #输出结果: -AA-
- 1
- 2
- 3
center的第一个参数,是生成新字符串的最大长度,随后将调用该方法的字符串,也就是str1居中,剩余的空间用第二参数,也就是’-'填充。
startswith 以…开头,支持切片判断…
函数名:
string.startswith('xxx',起始索引,结束索引)
- 1
作用:
- 用于判断一个字符串是否以某某某开头。
- 也可以利用字符串切片再判断是否以某某某开头
代码示例:
str1 = 'GG爆,童话里做英雄' str2 = str1.startswith('g') # 区分大小写,所以结果应该是False print(str2) #输出结果: False str1 = 'GG爆,童话里做英雄' str2 = str1.startswith('童',4,7) #可进行切片判断 print(str2) #输出结果: True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
endswith 以…结尾
函数名:
string.endswith('xxx')
- 1
作用:
- 用于判断该字符串是否以某某某结尾
代码示例:
str1 = 'i love you' print(str1.endswith('you')) #输出结果: True
- 1
- 2
- 3
find 查找字符串的元素并返回索引
函数名:
string.find('xxx',起始索引,结束索引)
- 1
作用:
- 用于查找字符串中的元素,返回值为索引。
- 当没找到元素时,返回值为-1
- 支持切片查找
代码示例:
str1 = 'emo时间到' find_index = str1.find('o') print(find_index) #输出结果: 2 str1 = 'emo时间到' find_index = str1.find('r') print(find_index) #输出结果: -1 当find未找到元素时,返回值为-1 str1 = 'emo时间到' find_index = str1.find('时',2,-1) print(find_index) #输出结果: 3 支持切片查找(提高效率)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
strip 去掉首尾的空格或特殊字符
函数名:
string.strip('需要去掉的特殊字符,默认为空格')
- 1
作用:
- 返回字符串去掉首尾空格。
- 返回字符串去掉首尾特殊字符。
代码示例:
str1 = ' liu yu ' print(str1.strip()) #输出结果:liu yu str1 = '--liu-yu--' print(str1.strip('-')) #输出结果:liu-yu
- 1
- 2
- 3
- 4
- 5
- 6
因为strip方法只去掉首尾的特殊字符,但是中间的不管。
如果真的想把所有的空格或者特殊字符都去掉,可以写一个函数,后续直接调用
def remove_spaces_str(data,char): if type(data) is str: #判断是否为字符串 ret = '' #定义一个‘空’变量 for i in data: #挨个循环 ret = ret + i.strip(char) return ret else: return '请输入字符串' str1 = '--liu-yu--' str2 = remove_spaces_str(str1,'-') #参数1:需要操作的字符串。 参数2:需要删除的特殊字符 print(str2) #输出结果为:liuyu
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
count 计算元素出现的次数
函数名:
string.count('xxx')
- 1
作用:
- 用于计算元素出现的次数,这个元素可以是多个。
代码示例:
str1 = '萝卜蹲萝卜蹲,萝卜蹲完胡萝卜蹲' print(str1.count('萝卜')) #输出结果为: 4 print(str1.count('蹲')) #输出结果为:4
- 1
- 2
- 3
split 以…分割
函数名:
string.split("xxx")
- 1
作用:
- 以xxx分割,分割出来的元素组成列表并返回。
代码示例:
str1 = '高清:无码:葫芦娃&儿' str2 = str1.split(":") print(str2) #输出结果:['高清', '无码', '葫芦娃&儿'] 格式为列表
- 1
- 2
- 3
split方法还有一个
maxsplit参数,用于控制最大切片次数,示例如下:str1 = 'a:b:c:d:e:f:g' print(str1.split(':',maxsplit=2)) # 输出结果:['a', 'b', 'c:d:e:f:g']
- 1
- 2
format 格式化字符串
函数名:
string.format()
- 1
作用:
- 用于格式化字符串
三种用法:
- 利用位置进行替换
- 利用索引进行替换
- 利用关键字进行替换
代码示例:
#利用位置进行替换 test1 = '每个人身上都有{},让我为你唱{}'.format('毛毛','毛毛') #利用索引进行替换 test2 = '每个人身上都有{0},让我为你唱{1}'.format('毛毛','maomao') #利用关键字进行替换 test3 = '你叫什么叫,{sha}'.format(sha='不服你打我') print(test1) #输出结果: 每个人身上都有毛毛,让我为你唱毛毛 print(test2) #输出结果: 每个人身上都有毛毛,让我为你唱maomao print(test3) #输出结果: 你叫什么叫,不服你打我
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
replace 字符串替换
函数名:
string.replace('旧字符','新字符','替换到第几次停止')
- 1
作用:
- 返回字符串替换之后的
代码示例:
s = '主播你好我是小学生可以给我磕个头吗' s1 = s.replace('小学生','主播') #将小学生替换为主播 print(s1) #输出结果为: 主播你好我是主播可以给我磕个头吗 s2 = s1.replace('主播','小学生',1) #将主播替换为小学生,只替换一次 print(s2) #输出结果为: 小学生你好我是主播可以给我磕个头吗
- 1
- 2
- 3
- 4
- 5
- 6
len 计算元素个数
函数名:
len(str)
- 1
作用:
- 返回字符串的元素个数
代码示例:
test = 'abcd' print(len(test)) #输出结果为: 4 test2 = ['1','2','4'] print(len(test2)) #输出结果为: 3
- 1
- 2
- 3
- 4
- 5
max 返回最大元素
函数名:
max(str)
- 1
作用:
返回字符串中最大的元素,应该是按照ascii码来对比的,a-z,z最大。
ascii码对照表 https://ascii.org.cn/
同时也可用于列表,返回列表中最大的元素
代码示例:
test = 'azbjcd' print(max(test)) #输出结果为: z # ascii码对比 a:97 z:122,所以z最大。 # 该方法列表同样使用,只要是可迭代数据类型都可以,这些概念后续会介绍。 test2 = ['1','2','98','4'] print(max(test2)) #输出结果为: 98 # 当列表内字符串的元素为多个时,判断大小的依据为首个元素的大小。 lis = ['aby','bcf','cAA'] print(max(lis)) # 97+98+121 # 98+99+102 # 99+65+65 由于c的ascii码为99,后续的65虽然小于前面,但是开头大,就是大。 # 输出结果为:cAA
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
min返回最小的元素
函数名:
min(str)
- 1
作用:
- 与max()相反
代码示例:
test = 'azbjcd' print(min(test)) #输出结果为: a test2 = ['1','2','98','4'] print(min(test2)) #输出结果为: 1
- 1
- 2
- 3
- 4
3.2.3 字符串逻辑判断相关
| 方法名 | 作用 |
|---|---|
| isdigit | 判断是否为数字 |
| isalpha | 判断是否为字母 |
| isspace | 判断是否为空格 |
数据类型分为:
- str字符串、list列表、dict字典、tuple元组 、int数字
后续可通过type()函数,来进行判断是哪个数据类型,从而做出不同的操作。
应用:
- 该案例中使用了for循环,需要先去了解for循环,再回来观看。
#计算字符串中数字、字母、空格、特殊字符出现的次数 s = 'd.an123slfn a.ndwlkand312321k an nkl/klraw' number = 0 #数字 alpha = 0 #字母 space = 0 #空格 other = 0 #其他 for i in s: if i.isdigit(): #判断该字符串是否为数字 number += 1 elif i.isalpha(): #判断该字符串是否为字母 alpha += 1 elif i.isspace(): #判断该字符串是否为空格 space += 1 else: other += 1 print(number,alpha,space,other)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.2.4 str转list
两种方式:
第一种,利用内置函数list()
str1 = '123' lis = list(str1) print(lis) # ['1', '2', '3']
- 1
- 2
- 3
第二种,利用字符串方法split
str1 = '1-2-3' lis = str1.split('-') print(lis) # ['1', '2', '3']
- 1
- 2
- 3
3.3 list列表
作用:
- 列表可以⼀次性存储多个数据,且可以为不同数据类型,如:⼀个班级100位学⽣,每个⼈的姓名都要存储,那就需要声明100个变量,而现在有个数组,我们可以存入到一个数组里
定义:
student_list = ['张三','李四','王五','马六',]
- 1
列表的特点:
有序,可更改,可以有重复的元素。
可以存储多个不同数据类型的数据,每个数据元素之间用逗号隔开,列表整体为中括号包裹。
hobby_list = ['吃饭','睡觉','打游戏'] print(hobby_list) #输出结果: ['吃饭', '睡觉', '打游戏']
- 1
- 2
3.3.1 list的切片
列表切片
与字符串的切片基本上大同小异。
嵌套切片
lis = ['大白菜鸡毛菜','通心菜','油麦菜',['绿的菜白的菜','什么菜炒什么菜,']] print(lis[0]) #输出结果: 大白菜鸡毛菜 print(lis[3]) #输出结果: ['绿的菜白的菜', '什么菜炒什么菜,'] print(lis[3][1]) #输出结果: 什么菜炒什么菜
- 1
- 2
- 3
- 4
附:
- print(lis[3][1])此处需要分步,第一步 list[3] = [‘绿的菜白的菜’,‘什么菜炒什么菜,’]
- 第二步,lis[3][1] = [‘绿的菜白的菜’,‘什么菜炒什么菜,’][1] = 什么菜炒什么菜
# 练习,下列会输出什么 print(lis[3][1][1]) #结果:么
- 1
- 2
3.3.2 list的增删改查
汇总一览:
| 语法 | 作用 |
|---|---|
| list.append(‘数据’) | 列表添加元素,添加到最后面 |
| list.insert(索引,‘数据’) | 将数据插入到指定的索引处 |
| list.extend(‘数据’) | 将数据拆分成最小元素,随后插入到列表的最后面 |
| list.pop(索引) | 按照索引删除,默认删除最后一位 |
| list.remove(‘元素’) | 按照元素删除 |
| list.clear() | 清空列表 |
| list.del() | 删除列表,或批量(切片)删除元素 |
| list[索引] = “新值” | 利用重新赋值的方式,修改列表 |
注:列表为可变数据类型,所以很多方法都时在原列表的基础之上进行修改的。
append添加列表元素
格式:
list.append()
- 1
与str类型不同,list的方法有很多都是作用于原列表之上,对原数据进行更改,如append,就是在调用该方法的列表中,添加新的元素(值)
代码示例:
lis = ['xixihaha'] lis.append('chichihehe') print(lis) #输出结果:['xixihaha', 'chichihehe']
- 1
- 2
- 3
insert插入元素
格式:
list.insert(index,data) # 索引为必选参数,表示数据插入到指定索引处
- 1
- 2
代码示例:
lis = ['嘻嘻哈哈', '吃吃喝喝'] lis.insert(1,'睡觉觉') # 将数据插入到所以为1的位置 print(lis) #输出结果:['嘻嘻哈哈', '睡觉觉', '吃吃喝喝']
- 1
- 2
- 3
- 4
extend迭代插入最小元素
格式:
list.extend(data)
- 1
代码示例:
lis = ['嘻嘻哈哈', '吃吃喝喝'] lis.extend('睡觉觉') print(lis) #输出结果:['嘻嘻哈哈', '吃吃喝喝', '睡', '觉', '觉'] lis.extend(['刷抖音']) print(lis) #输出结果:['嘻嘻哈哈', '吃吃喝喝', '睡', '觉', '觉', '刷抖音']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
pop按照索引删除列表元素
格式:
list.pop([index]) # 中括号表示可选参数
- 1
- 2
默认删除末尾的元素,当传入index参数时,删除该索引的元素
该方法会返回被删除的元素
代码示例:
lis = ['a','b','c','d'] str1 = lis.pop() #索引为空默认删除最后一位,该方法会返回被删除的元素。 str2 = lis.pop(0) #删除索引为0的元素 print(lis,str1,str2) #输出结果: ['b', 'c'] d a
- 1
- 2
- 3
- 4
remove按照元素删除列表元素
格式:
list.remove('元素值')
- 1
该方法与pop不同,remove没有返回值。
代码示例:
lis = ['a','b','c','d'] str1 = lis.remove('a') print(str1,lis)
- 1
- 2
- 3
clear清空列表所有元素
lis.clear()
print(lis) #返回结果为:[]
- 1
- 2
del 删除列表
格式:
del list # 或 del list[起始索引:结束索引]
- 1
- 2
- 3
代码示例:
del lis print(lis) #报错,因为没有lis这个列表了 lis = ['a','b','c','d'] del lis[2:] #索引2及以后的都删除 print(lis) #['a', 'b']
- 1
- 2
- 3
- 4
- 5
- 6
利用重新赋值的方式,修改列表
格式:
list[索引] = 值 # 或 list[起始索引:结束索引] = 值
- 1
- 2
- 3
代码示例:
lis = ['a','b','c','d'] lis[0] = 'ABC' # 将列表的0号索引的元素修改为 ‘ABC’ print(lis) # ['ABC', 'b', 'c', 'd'] lis = ['a','b','c','d'] lis[1:3] = 'ABC' #将b-c这个区间的元素替换为'ABC'的每个最小元素 print(lis) # ['a', 'A', 'B', 'C', 'd']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.3.3 list其他常用方法
汇总一览:
- 注意,与字符串不同,列表的有些方法是直接对原列表进行操作的。
| 语法 | 作用 |
|---|---|
| len(list) | 查询列表最小元素的个数 |
| list.count(元素值) | 查询元素出现的次数 |
| list.index(元素) | 查找元素的索引值 |
| list.sort([reverse=True]) | 正向排序,默认从小到大,传入参数reverse=True时,从大到小 |
| list.reverse() | 列表反向排列 |
| list.copy() | 复制列表 |
| ‘连接符’.join(列表) | 列表转字符串 |
len() 查询列表最小元素的个数
lis = ['a','b','c',[1,'2',3]]
print(len(lis)) # 4
- 1
- 2
count()查询元素出现的次数
lis = ['a','b','c',[1,'2',3]]
a = lis.count('a')
print(a) # 1
- 1
- 2
- 3
index()查找元素的索引值
lis = ['a','b','c',[1,'2',3]]
a = lis.index('c')
print(a) # 2
- 1
- 2
- 3
sort()正反向大小排序
- 注意:该函数无返回值,直接对原列表进行操作。
# 正向排序 从小到大
lis = [1,4,7,2,3,8,6]
lis.sort()
print(lis) # [1, 2, 3, 4, 6, 7, 8]
# 倒序 从大到小
lis.sort(reverse=True)
print(lis) # [8, 7, 6, 4, 3, 2, 1]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
附: 其实,sort函数还可以指定一个参数key,该函数可以改变排序。
比如: 按照绝对值的大小进行排序,那就需要将key=abs,将key赋值为内置函数abs的内存地址,可将sort函数每次迭代出来的值,先交给abs函数进行求绝对值,随后返回再进行sort排序。
l = [1,-4,6,5,-9,-2]
l.sort(key=abs)
# 输出结果: [1, -2, -4, 5, 6, -9]
- 1
- 2
- 3
reverse()列表反向排列
- 与sort一样,都是直接对原列表进行操作的。
lis = [1,4,7,2,3,8,6]
lis.reverse()
print(lis) # [6, 8, 3, 2, 7, 4, 1]
- 1
- 2
- 3
copy()复制列表
注:
- 如果被复制的列表里面嵌套有多层,则原列表修改之后,新的列表可能会发生改变。
- 具体请见
深浅拷贝
abc = ['1','2','4']
abc2 = abc.copy()
print(abc2) # ['1', '2', '4']
- 1
- 2
- 3
join()列表转字符串
lis = ['接着奏乐','接着舞','dengdengdeng',['我打了一辈子','仗']]
str1 = '_'.join(lis[:3]) + '_' + '_'.join(lis[3])
print(str1)
#打印结果:接着奏乐_接着舞_dengdengdeng_我打了一辈子_仗
lis2 = ['大白菜','鸡毛菜','通心菜','油麦菜']
str2 = '*'.join(lis2)
print(str2)
#打印结果:大白菜*鸡毛菜*通心菜*油麦菜
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.3.4 列表嵌套练习
列表为:
lis = ['接着奏乐','接着舞','dengdengdeng',['我打了一辈子','仗']]
- 1
需求1:将’dengdengdeng’改为大写
lis[2] = lis[2].upper() #或者 lis[2] = 'DENGDENGDENG' print(lis) #输出结果: ['接着奏乐', '接着舞', 'DENGDENGDENG', ['我打了一辈子', '仗']]
- 1
- 2
- 3
需求2:将‘仗’改为‘飞机’
lis[3][1] = lis[3][1].replace('仗','飞机') #或者 lis[3][1] = '飞机' print(lis) #输出结果:['接着奏乐', '接着舞', 'dengdengdeng', ['我打了一辈子', '飞机']]
- 1
- 2
- 3
注:
字符串属于不可修改类型,变量指向的是字符串值的内存地址,我们只能修改指向,也就是重新赋值,老的值因为没有变量引用,GC机制会清理。
所以字符串的方法不能修改列表内字符串的内容,只会返回处理好的字符串。
此时我们再重新赋值即可。
3.3.5 逻辑判断相关
关键词:
- in 、 not in
作用:
- 判断指定数据在某个列表序列,如果在返回True,否则返回False,返回的True或False后续可做if判断
代码示例:
in
abc = ['1','2','4'] print('3' in abc) #False print('4' in abc) #True
- 1
- 2
- 3
not in
abc = ['1','2','4'] print('3' not in abc) #True print('4' not in abc) #False
- 1
- 2
- 3
3.3.6 深浅copy
引子:
定义列表,并利用两种拷贝方式对列表list1进行复制
list1 = ['liuyu','22',['中国地质大学','beijing']]
list2 = list1
list3 = list1.copy()
- 1
- 2
- 3
三个列表变量在内存中的存储如下:
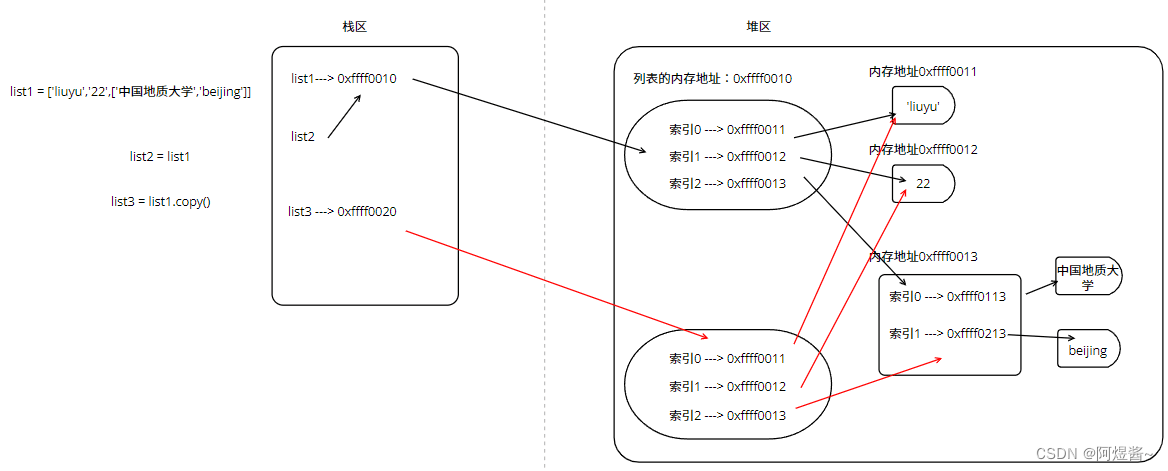
如图可见:
- list2与list1指向的内存地址是相同的,所以当原列表list1对任何数据进行修改时,list2会跟着改变。
- list3重新在堆区开辟了空间用来存放每个索引对应值的内存地址。
- 因为字符串为不可变数据类型,所以原列表对字符串进行修改时,会重新开辟空间并指向,所以影响不到list3中的字符串,因为list3始终指向的是原来拷贝过来的内存地址,
- 而可变数据类型列表是个例外,如原列表索引2的元素(列表),因为list3指向的内存地址与list1是一样的,所以当list[2]这个内部列表的数据发生变化时,list3会受到影响,可以理解为,list1与list3指向的都是一个水瓶,里面的水换成可乐,那么都一起喝可乐。
验证:
list1 = ['liuyu','22',['中国地质大学','beijing']] list2 = list1 list3 = list1.copy() list1[1] = '24' list1[2][1] = 'shanghai' print(list1) print(list2) print(list3) # 只有list3[1]元素,没有受到原列表更改的影响。 print(id(list1[0]),id(list1[1]),id(list1[2])) print(id(list2[0]),id(list2[1]),id(list2[2])) print(id(list3[0]),id(list3[1]),id(list3[2])) # 打印内存地址,也证实了list3[2]与list1[2]指向的是同一个内存地址。 '''输出结果: ['liuyu', '24', ['中国地质大学', 'shanghai']] ['liuyu', '24', ['中国地质大学', 'shanghai']] ['liuyu', '22', ['中国地质大学', 'shanghai']] 2280379554864 2280382155440 2280423454464 2280379554864 2280382155440 2280423454464 2280379554864 2280379249712 2280423454464 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
上述这种拷贝方式,统称为浅拷贝
深拷贝
import copy
list1 = ['liuyu','22',['中国地质大学','beijing']]
list4 = copy.deepcopy(list1)
print(list4)
- 1
- 2
- 3
- 4
深拷贝示意图
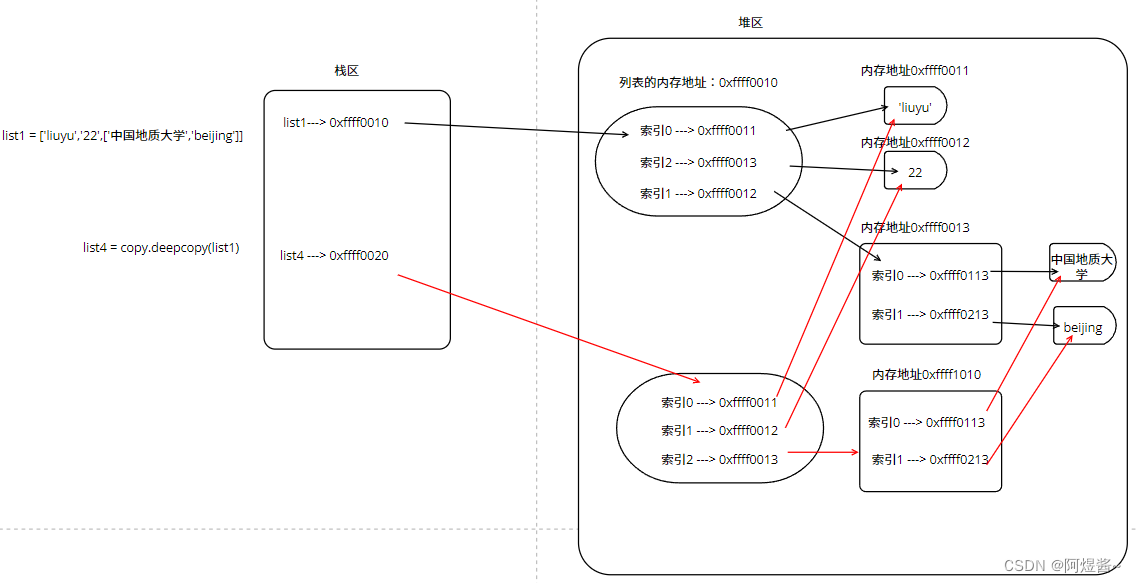
与浅拷贝的区别:
-
对于可变数据类型,重新开辟空间,与最终的值进行绑定。
-
因为字符串时不可变数据类型,所以即时原列表进行了数据修改,那也只是重新开辟空间存的新值而已,并没有对老的值进行什么操作,只是解绑了。 原列表解绑了,list4列表可没有,所以就不会受到任何影响了。
-
简单理解为,list4与list1指向的不是一个水瓶,当list1不想喝白开水,想换成芬达,那也只是把list1水瓶里面开白水掉掉,重新灌满芬达而已,不会影响list4中的白开水。
验证:
print(id(list1[0]),id(list1[1]),id(list1[2]),id(list1[2][0]),id(list1[2][1]))
print(id(list4[0]),id(list4[1]),id(list4[2]),id(list4[2][0]),id(list4[2][1]))
'''输出结果
2048401929136 2048404807024 2048446068480 2048401726576 2048404832688
2048401929136 2048404807024 2048445389376 2048401726576 2048404832688
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到,除了不可变数据类型的列表,是重新开辟了内存空间,其他指向的内存地址都是一样的。
3.3.7 列表转字符串、集合
列表转字符串
lis = ['Cai','Xu','Kun']
str1 = ''.join(lis)
print(str1) # CaiXuKun
- 1
- 2
- 3
列表转集合
内置函数set()
lis = [1,1,2,2,3,3]
set1 = set(lis)
print(set1,type(set1)) # {1, 2, 3} <class 'set'>
- 1
- 2
- 3
3.4 元组
作用:
- 与列表相似,不过元组内的数据是不能修改的。(因为压根就没有提供修改元素的方法)
定义:
tup = ('张三','李四','王五')
- 1
元祖的特点:
有序,不可更改,可以有重复的元素。
可以存储多个不同数据类型的数据,每个元素之间用逗号隔开,元祖整体为小括号包裹。
但是,当元祖内的元素为可变数据类型时,如列表,那么列表中的元素可以进行更改。
tup = ('张三','李四','王五',[1,2,3],{'name':'盖伦'}) print(tup) # ('张三', '李四', '王五', [1, 2, 3], {'name': '盖伦'}) tup[3][0] = 0 tup[4]['name'] = '嘉文四世' print(tup) # ('张三', '李四', '王五', [0, 2, 3], {'name': '嘉文四世'})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
元组的切片
tup = ('a','b','c','d')
# 按照索引取元素
print(tup[1]) # 输出结果:b
# 切片
print(tup[1:3]) # 输出结果:('b', 'c')
- 1
- 2
- 3
- 4
- 5
- 6
3.4.1 元组常用方法
| 边界符 | 说明 |
|---|---|
| tuple.index(元素) | 返回通过元素找到的索引值 |
| tuple.count(元素) | 返回通过元素,查找该元素出现的次数 |
| len(tuple) | 统计元素总共的个数 |
tup = (7,1,9,10,24,1)
res = tup.index(10)
print(res) #输出结果: 3
res = tup.count(1)
print(res) #输出结果: 2
res = len(tup)
print(res) #输出结果: 6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.4.2 元组的多种定义方式
python崇尚简介,所以在上述的代码中,并没有先定义变量的数据类型,然后再赋值,本小结主要扩展下元组的其他定义方式,赋值和定义算成一步了。
# 一下多种赋值方式都是为元组。
a = 1,
b = (1,)
c = 1,2
d = (1,2)
print(type(a)) # <class 'tuple'>
print(type(b)) # <class 'tuple'>
print(type(c)) # <class 'tuple'>
print(type(d)) # <class 'tuple'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.5 字典
作用:
- 用于存放一组有对应关系的数据,如姓名与身份证号、游戏ID与游戏道具列表,等等等。
定义:
dict1 = {'name':'盖伦','age':76,'addr':'德玛西亚'} #冒号前⾯的为键(key),简称k;冒号后⾯的为值(value),简称v。
- 1
- 2
字符串的特点:
无序(不能人为排序),可更改,有索引,没有重复的key。
{}大括号包裹,数据为键值对,每个键值对中间用逗号隔开。
键值对的格式为 key:value,其中key可以对value有描述性的功能
dict1 = { 'name':'liuyu', 'age':22, 'school':'中国地质大学(北京)' }
- 1
- 2
- 3
- 4
- 5
3.5.1 增加属性
方式一:通过赋值的方式
首先,如何获取字典字典的值?
格式:
dict[key] # 返回为该key的value
- 1
所以当我们需要修改字典某个key的value时,可以重新赋值达到修改的效果,如:
dict1 = {'name':'liuyu','age':22,'school':'中国地质大学(北京)'}
dict1['age'] = 23
print(dict1)
#输出结果: {'name': 'liuyu', 'age': 23, 'school': '中国地质大学(北京)'}
- 1
- 2
- 3
- 4
上述代码中,修改的是已有key的value值,当key不存在时,字典会默认创建这个key,然后赋于值。
dict2 = {'A':'a','B':'b'}
dict2['C'] = 'c'
print(dict2)
#输出结果: {'A': 'a', 'B': 'b', 'C': 'c'}
- 1
- 2
- 3
- 4
总结:
字典[key] = value这种方法,当没有这个Key的时候会自动创建这个键值对,并添加到字典的末尾。- 当有key的时候则是修改value值
方式二:利用setdefault()方法增加字典的值
格式:
-
dict.setdefault(key,value)- 1
特点:
- 当key存在不进行任何修改。
- 当key不存在则将该键值对添加至字典的末尾。
代码示例:
-
dict1 = {'name':'liuyu','age':22,'school':'中国地质大学(北京)'} dict1.setdefault('school','北京大学光华管理学院') dict1.setdefault('addr','北京') print(dict1) # {'name': 'liuyu', 'age': 22, 'school': '中国地质大学(北京)', 'addr': '北京'}- 1
- 2
- 3
- 4
可以发现,由于已经存在了,所有school的值并没有被修改,而addr属性并没有,所以就新增了。
根据具体情况来选择是方式一还是方式二。
3.5.2 删除属性或字典
方式一:pop删除指定的键值对
格式:
-
dict.pop('要删除键值对的key','自定义报错信息') dict.pop('要删除键值对的key',['报错1','报错2','报错3',])- 1
- 2
- 3
作用:
- 用于删除字典内指定的键值对。
特点:
- 该方法在删除不存在key时,会报错,但是可以返回指定的报错信息。
- 成功删除了之后,可以返回被删除键值对的value
代码示例:
dict1 = {'name':'liuyu','age':22,'school':'中国地质大学(北京)'}
res = dict1.pop('addr','未找到Key')
print(res) #输出结果: 未找到Key
res = dict1.pop('school') #会返回key为school的value值。
print(res,dict1)
#输出结果: 中国地质大学(北京) {'name': 'liuyu', 'age': 22}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
方式二:利用popitem()方法删除最后一对属性
格式:
-
dict.popitem()- 1
作用:
- 调用该方法的字典,会删除最后一位属性,并返回被删除的键值对
代码示例:
dict1 = {'name': '盖伦', 'age': 76, 'addr': '德玛西亚', '身高': 190,}
print(dict1.popitem()) #输出结果:('身高', 190)
print(dict1.popitem()) #输出结果:('addr', '德玛西亚')
# 后两位已被删除
print(dict1) #输出结果:{'name': '盖伦', 'age': 76}
- 1
- 2
- 3
- 4
- 5
- 6
删除字典方式一:利用内置方法del()删除
格式:
-
删除整个字典:
del 字典名- 1
-
删除字典的键值对
del 字典名[key]- 1
删除字典方式二:clear()清空字典
dict1.clear() # 此时dict1为空字典
print(dict1) # 输出结果: {}
- 1
- 2
3.5.3 修改属性
方式一:直接修改
dict1 = {'name': '盖伦', 'age': 76, 'addr': '德玛西亚', '身高': 190}
dict1['身高'] = 150 #当添加的k已经存在,则直接修改。
print(dict1) #身高已被修改为150
#输出结果: {'name': '盖伦', 'age': 76, 'addr': '德玛西亚', '身高': 150}
- 1
- 2
- 3
- 4
方式二:利用update方法(了解即可)
关于修改,还有另外一种方式,那就是利用update方法,将字典B同步给字典A。
将dict2字典的内容,同步到dict1中:
-
dict1 = {'name':'liuyu','age':'22','addr':'shanghai'} dict2 = {'name':'xiaxia','age':'21','school':'Beijing_University'} dict1.update(dict2) print(dict1) print(dict2) #输出结果: {'name': 'xiaxia', 'age': '21', 'addr': 'shanghai', 'school': 'Beijing_University'} #输出结果: {'name': 'xiaxia', 'age': '21', 'school': 'Beijing_University'}- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以发现,相同Key的情况下,值以dict2字典为标准,同时dict1字典中没有而dict2有的属性,会被同步过去。
当dict1中有,而dict2中没有的属性,会继续保留。
3.5.4 查找属性
如何列出字典中所有的Key、value呢。
格式:
-
dict.keys() # 列出字典所有的 键 dict.values() # 列出字典所有的 值 dict.items() # 列出字典所有的 键和值 以元组的形式展示- 1
- 2
- 3
代码示例:
-
dic = {'name': '盖伦', 'age': 76, 'addr': '德玛西亚', '身高': 190} print(dic.keys()) #输出结果:dict_keys(['name', 'age', 'addr', '身高']) print(dic.values()) #输出结果:dict_values(['盖伦', 76, '德玛西亚', 190]) print(dic.items()) #输出结果:dict_items([('name', '盖伦'), ('age', 76), ('addr', '德玛西亚'), ('身高', 190)])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
由于python中可以多个变量赋值,所以我们可以通过循环将key键和value值,依次通过赋值打印出来(for循环等在文章后面有讲述)
dic = {'name': '盖伦', 'age': 76, 'addr': '德玛西亚', '身高': 190}
for k,v in dic.items():
print(k,v)
# 因为 items() 输出的为 ('name', '盖伦'), ('age', 76), ('addr', '德玛西亚'), ('身高', 190)
# 每个元组刚好有两个元素,这与for循环中的k和v刚好对应上,所以可以正确赋值,并打印出来。
'''输出结果:
name 盖伦
age 76
addr 德玛西亚
身高 190
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在之前有提到,python中字典的可以直接通过key查找value的,如:
dic = {'name': '盖伦', 'age': 76, 'addr': '德玛西亚', '身高': 190}
value1 = dic['name']
print(value1) # 盖伦
- 1
- 2
- 3
但是,当中括号内的Key,在字典中并不存在时会报错,所以需要可以不报错的方法,或者可以自定义报错的方法。
get方法
格式:
-
dict.get('要取值的键','自定义报错信息')- 1
代码示例:
dic = {'name':'liuyu'}
print(dic.get('name')) # 输出结果:liuyu
print(dic.get('age','not find')) # 输出结果:not find
- 1
- 2
- 3
字典的嵌套
现在有一个字典,名字叫做zidian,现在我们想让字符串Syria变成全大写,需要怎么操作。
zidian = {
'name':['法外狂徒张三','李四'],
'Learn':{
'time':'2021/5/10,',
'learn':'AKM的基本保养及维护,巴雷特快速换弹技术',
'addr':'Syria'
},
'age':57
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
第一步,我们一层一层来拆开看看效果,先想一想字典的查是如何查的。
abc = zidian['Learn'] # 通过Key找v print(abc) '''输出结果: { 'time': '2021/5/10,', 'learn': 'AKM的基本保养及维护,巴雷特快速换弹技术', 'addr': 'Syria' } '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
第二步
abc = zidian['Learn']['addr'] print(abc,type(abc)) # 输出结果为: # Syria <class 'str'> #既然类型是str那就可以用str的方法使其变成全大写。 abc = zidian['Learn']['addr'].upper() print(abc) # SYRIA 这样就得到了大写的值- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.6 集合
定义:
'多个元素的无序组合,每个元素唯一,集合元素不可修改(为不可变数据类型)'
- 1
特点:
无序,无索引,没有重复的元素
集合一旦被创建,无法更改项内容,但是可以添加项
类似于高中数学中的集合,可求∩交集∪并集等。
使⽤ {} 或 set() , 但是如果要创建空集合只能使⽤ set() ,因为默认 {} 是⽤来创建空字典的。
set1 = {10, 20, 30, 40, 50} print(type(set1)) # set
- 1
- 2
3.6.1 集合的增删改查
一、add增加数据
格式:
set.add()
- 1
代码示例:
s1 = {10, 20} s1.add(100) #s1这个集合中添加100,因为集合是无序且去重的,所以这个100是随机插入的。 s1.add(10) #因为集合是无序的且去重,所以这个10不会被添加进去。 print(s1) # 输出结果: {100, 10, 20}
- 1
- 2
- 3
- 4
二、update 拆分元素并随机添加
格式:
set.update()
- 1
代码示例:
s1 = {10, 20} s1.update('abc') print(s1) #{10, 'b', 20, 'a', 'c'}
- 1
- 2
- 3
三、删除
(1)pop随机删除
# pop随机删除,该函数会返回被删除的那个元素
set1.pop()
print(set1) #会输出被删除的元素
- 1
- 2
- 3
(2)remove按元素删除
# remove按元素删除,该函数与pop不同,这个没有返回值
set1.remove('1') #如果没有这个元素会报错。
print(set1)
- 1
- 2
- 3
(3)清空与删除集合
#清空集合 clear
set1.clear()
#删除 del
del set1
- 1
- 2
- 3
- 4
- 5
四、查
由于集合并没有专门查询方法,同时也没有索引,无法知己取值,所以需要借用for循环,迭代的从数组中取值。
#通过for循环拿到集合中的每一个值
for i in set1:
print(i)
- 1
- 2
- 3
3.6.2 求交并集
求交集的两种方式
方式一:利用关键字
set_1 = {1,5,7,9,4} set_2 = {6,4,2,5,9} print(set_1 & set_2) # {9, 4, 5}
- 1
- 2
- 3
方式二:利用intersection函数
print(set_1.intersection(set_2))
- 1
求并集的两种方式
方式一:利用关键字
print(set_1 | set_2) # {1, 2, 4, 5, 6, 7, 9} print(set_1.union(set_2)) # {1, 2, 4, 5, 6, 7, 9}
- 1
- 2
方式二:利用symmetric_difference函数
print(set_1 ^ set_2) # {1, 2, 6, 7} print(set_1.symmetric_difference(set_2)) # {1, 2, 6, 7}
- 1
- 2
3.6.3 利用集合实现列表去重
因为集合内的元素都是唯一的,没有重复的值,所以我们可以将列表转成集合数据类型,再转回列表。
lis = [1,1,2,2,3,3]
lis = list(set(lis))
print(lis) # [1, 2, 3]
- 1
- 2
- 3
但是,由于集合是无序的,所以原来列表的排序,会被打乱。
3.7 补充
3.7.1 可变与不可变类型
可变类型:
- 值改变,id不变(内存地址),证明改的是原值,证明原值是可以被改变的.
不可变类型:
- 值改变,id也变了,证明是产生新的值,压根没有改变原值,证明原值是不可以被修改的
验证
int是不可变类型
x=10 print(id(x)) # 140710450899024 x=11 # 产生新值 print(id(x)) # 140710450899056 内存地址发生的改变√
- 1
- 2
- 3
- 4
float是不可变类型
x=3.1 print(id(x)) # 2336632639536 x=3.2 print(id(x)) # 2336632639600 内存地址发生的改变√
- 1
- 2
- 3
- 4
str是不可变类型
x="abc" print(id(x)) # 2692737058544 x='gggg' print(id(x)) # 2692737440752 内存地址发生的改变√
- 1
- 2
- 3
- 4
小结:int、float、str都被设计成了不可分割的整体,不能够被改变。而其余的数据类型都是可更改的(元组这个只读列表除外)
列表就是可变数据类型
l=['aaa','bbb','ccc'] print(id(l)) # 2514251642368 print(id(l[0])) # 1332798747696 l[0]='AAA' print(id(l)) #2514251642368 栈指向堆中的内存地址不变 print(id(l[0])) # 1332801653424 堆中指向的值,内存地址不一样。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
经过测试,列表这种数据类型确实满足 “值改变,id不变” 这个原则,说明是可变数据类型。
3.7.2 初识编码
后续的章节中会详细介绍,具体见目录(我懒得找,哈哈哈哈,嗝~)
ASCII:字母,数字,特殊字符:都是用1个字节 8位
Unicode:2个字节16位 4个字节32位
utf-8:一个英文字母1个字节8位 欧洲两个字节16位 中文3个字节24位
gbk:英文1个字节8位 中文2个字节16位
python3中默认使用的编码为:Unicode
- 1
- 2
- 3
- 4
- 5
- 6
3.7.3 bool数据类型
bool数据类型,与上述数据类型都不太一样,bool数据类型的特点就是不是True就是False,所以多用于条件判断。
flag = True
print(flag,type(flag))
#输出结果: True <class 'bool'>
- 1
- 2
- 3
3.8 格式化输出
作用:
- 实现将字符串中指定的内容,灵活的替换成我们想要的。
实现方式:
- 1.利用%s占位符来进行替换
- 2.利用str的.format方法来进行替换
- 3.利用 f’{}’ 这样的F语句
一、利用占位符实现格式化字符串
关键词:
- %s 与 %d
- 都是占位符,%s表示当前位置是个字符串,%d表示当前位置是个数字。
格式:
-
str = '%s'%(字符串) #使用%s占了几个位置,就要补充对应多少个值,进行替换- 1
代码示例
name = 'liuyu'
msg = '我的名字是:%s'%(name)
print(msg)
#输出结果:我的名字是:liuyu
- 1
- 2
- 3
- 4
案例:
-
用户输入个人信息之后,打印用户信息表
name = input('请输入姓名:') age = input('请输入年龄:') job = input('请输入工作:') hobbie = input('你的爱好:') msg = '''------------ info of %s ----------- Name : %s Age : %d job : %s Hobbie: %s -------------- end ----------------''' %(name,name,int(age),job,hobbie) print(msg)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输入信息之后,打印示例:
------------ info of liuyu -----------
Name : liuyu
Age : 22
job : 后端开发
Hobbie: 吃饭
---------------- end -----------------本案例中注意事项:
- input接收输入的信息,格式为字符串,如果站位使用的是%d是,需要注意转换数据类型。
二、利用format方法
-
format方法有三种使用方法,详情可见字符串常用方法
#利用位置进行替换 test1 = '每个人身上都有{},让我为你唱{}'.format('毛毛','毛毛') #利用索引进行替换 test2 = '每个人身上都有{0},让我为你唱{1}'.format('毛毛','maomao') #利用关键字进行替换 test3 = '你叫什么叫,{sha}'.format(sha='不服你打我') print(test1) print(test2) print(test3) # 输出内容:每个人身上都有毛毛,让我为你唱毛毛 # 输出内容:每个人身上都有毛毛,让我为你唱maomao # 输出内容:你叫什么叫,不服你打我- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
三、利用F语句
格式:
-
f'{变量}...内容....{变量}'- 1
代码示例:
name = '米奇'
print(f'嘿,你丫的瞅什么呢,我是你die{name}') # F语句
# 输出内容: 嘿,你丫的瞅什么呢,我是你die米奇
- 1
- 2
- 3
- 4
另外,F语句可以执行内部代码:
f'{print("这个F真牛逼")}' # 这个F真牛逼
f"{print('aaaa')}" #aaaa
- 1
- 2
3.8.1 模拟进度条
本章节需要看完if判断,for循环,内置函数之后再回头查看
两种写法
# 利用覆盖输出,让每次打印的#号以及百分比数值不断变化就好。
import time
for i in range(0,101,2):
time.sleep(0.1)
num = i // 2
print( '\r{}%:{}'.format(i,'#'*num) if i == 100 else '\r{}%:{}'.format(i,'#'*num),end='')
#不加这个end=''会自动换行,那么\r就没用了
#输出结果: 100%:##################################################
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
import time
for i in range(0,101,2):
time.sleep(0.1)
num = i//2
print('\r[%-50s]%s%%'%('#'*num,i),end='')
#输出结果:[##################################################]100%
- 1
- 2
- 3
- 4
- 5
- 6
涉及到知识点详解:
- 开头\r 表示覆盖输出,这样不会另起一行。
- 末尾的end= ‘’ 表示末尾不换行,因为print函数默认是end=‘\n’
- %s%% 两个百分号在这里可以理解为屏蔽特殊字符的意思,这样就可以输出%
- %50s 表示占位符的宽度是多少(50),且数字是正数表示靠右侧
- %-50s 表示占位符的宽度是多少(50),-50为负数表示靠左侧
四、运算符
4.1 常见的运算符
1、算数运算符
print(10 + 3.1)
print(10 + 3)
print(10 / 3) # 结果带小数
print(10 // 3) # 取余但只保留整数部分
print(10 % 3) # 取余数
print(10 ** 3) # 幂运算
'''输出结果:
13.1
13
3.3333333333333335
3
1
1000
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2、比较运算符
#2、比较运算符: >、>=、<、<=、==、!=
# 返回的结果为布尔值,条件成立则返回True,不成立返回False
print(10 > 3) # True
print(10 == 10) # True
print(10 >= 10) # True
print(10 >= 3) # True
- 1
- 2
- 3
- 4
- 5
- 6
3、逻辑运算符
#3、逻辑运算符:not、and、or #not:将后面的条件结果取反 print(not 1>2) #True print(not True) #False print(not False) #True #and:用来链接左右两个条件,两个条件同时为True结果才为True。当左右两边为数字时,第一位为True则输出第二位,第一位为False时则输出第一位。(注:0表示False) print(1+2 > 3 and 4-3<0) #False print(0 and 3) # 0 print(4 and 3) # 3 #or:用来链接左右两个条件,两个条件但凡有一个为True,最终结果就为True。如果两把是数字时,当第一位为真则输出第一位,当第一位为假时则输出第二位,0表示假 print(3+7 > 5 or 9-11>0) #True print(6 or 7) # 6 print(0 or 7) # 7 # is:用来判断前者是不是后者,比较的是内存地址 str1 = 'abc' str2 = 'abc' print(str1 is str2) # True # in: 用来判断前者是否在后者里面 str = '1' res = str in '123' print(res) # True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
4、成员运算符
作用:
- 判断一个字符串,是否存在于一个字符串中
关键词:
- in 是否存在
- not in 是否不存在
代码示例:
test = '今晚8点,锁定我的直播间,咱们嗨起来!'
print('今晚' in test) # True
test2 = ['大锤','铁锤','头锤','榔头','二锤']
print('小锤' in test2) #False
test3 = {'姓名':'胡图图','工资':1500,'地址':'番斗花园'}
print('爱好' in test3) #False
print(1500 in test3) #false 因为直接对字典进行的操作大多都是对字典的Key,所以1500这个key并不存在,只有value是没用的。
print('工资' in test3) #True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.2 is与==
区别:
- is比较的是内存地址,==比较的是值。
驻留机制:
- 字符串驻留,是一种在内存中,仅保存一份相同且不可变字符串的方法。
驻留适用范围:
- 字符串长度为0或1时,默认采用驻留机制;
- 字符串长度大于1时,且 字符串中只包含大小写字母、数字、下划线(_) 时,采用驻留机制;
- 对于 [-5,256]之间的整数数字,Python默认驻留 ;
- 字符串只在编译时进行驻留,而非运行时 。Python是解释型语言,但是事实上,它的解释器也可以是理解为是一种编译器,它负责将Python代码翻译成字节码,也就是.pyc文件;
- 用乘法得到的字符串,如果结果长度 <=20且字符串只包含数字、字母大小写、下划线,支持驻留。长度>20,不支持驻留。这样的设计目的是为了保护.pcy文件不会被错误代码搞的过大。
代码示例:(需要直接打开Python解释器执行,win+r —> cmd —> python)
>>> x = 'abc:abc:abc'
>>> y = 'abc:abc:abc'
>>> print(x is y) # 不符合驻留机制,所以不会指向同一个内存地址。
False
>>> print(x == y)
True
>>> x = 'abc_abc_abc'
>>> y = 'abc_abc_abc'
>>> print(x is y)
True
>>> print(x == y)
True
>>>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4.3 其他
逻辑运算符有优先级规则:
- 即 not > and > or
隐式布尔值:
- 所有的值都可以当成条件去用,其中0、None、空(空字符串、空列表、空字典),都代表的布尔值为False,其余都为真。
小整数池[-5,256](了解即可):
- 从python解释器启动那一刻开始,就会在内存中事先申请好一系列内存空间存放好常用的整数
五、 流程控制
流程控制即控制流程,具体指控制程序的执行流程,而程序的执行流程分为三种结构:顺序结构(之前章节写的代码都是顺序结构)、分支结构(用到if判断)、循环结构(用到while与for)
5.1 分支结构if
什么是分支结构:
- 分支结构就是根据条件判断的真假去执行不同分支对应的子代码。
分支结构的作用:
-
人们可以根据某些时候的条件来决定做什么事情,比如:如果今天下雨,就带伞
所以程序中必须有相应的机制来控制计算机具备人的这种判断能力。
python中if关键字可以实现分支结构,语法格式如下:
if 条件:
条件成立执行的代码
elif 条件:
条件成立执行的代码(可以有多个elif)
else :
以上条件都不满足时执行的代码
- 1
- 2
- 3
- 4
- 5
- 6
条件是什么?
- 条件就是bool值,即True或False。如:1>2,通过运算,得到的值为False
代码示例:
# 当age这个年龄变量的值大于18时,打印已成年
age = 20
if age > 18:
print('已成年')
# 输出结果:已成年
- 1
- 2
- 3
- 4
- 5
# 输入分数,当分数90以上、80以上、60以上以及低于60的,输出特定信息
score = int(input('请输入本次考试得分:'))
if score >= 90:
print('很优秀')
elif score >= 80:
print('再接再厉')
elif score >= 60:
print('再努努力')
else:print('你考的有点抽象啊')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
5.1.1 三元运算
作用:
- 可以用一小段代码书写简单的if判断表达式
格式:
-
条件成立返回的结果 if 条件 else 条件不成立返回的结果- 1
代码示例:
test =1 if 5>4 else 3
print(test) #输出结果:1
test =1 if 5<4 else 3
print(test) # 3
- 1
- 2
- 3
- 4
- 5
str1 = '1'
res = '有' if str1 in '123' else '没有'
print(res) # 有
- 1
- 2
- 3
5.2 循环结构for
for循环
语法格式:
# 可迭代对象可以是:列表、字典、字符串、元组、集合 for 变量名 in 可迭代对象: 循环体
- 1
- 2
- 3
变量名会每次从可迭代对象中获取值,并且执行循环体内部代码。
- 1
- 2
代码示例:
a = '嘻嘻哈哈'
for i in a :
print(i)
'''输出结果:
嘻
嘻
哈
哈
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
变量名“i”,每次都会从变量"a"中取出一位元素,随后执行循环体内的代码。这个过程叫循环,循环的次数取决于这个变量"a"的长度。
dic = {'name': '盖伦', 'age': 76, 'addr': '德玛西亚', '身高': 190}
for k,v in dic.items():
print(k,v)
'''输出结果:
name 盖伦
age 76
addr 德玛西亚
身高 190
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
5.2.1 continue与break
一、continue
关键字:
- continue,书写位置:循环体内部
作用:
- 终端本次循环,进入下一次循环
代码示例:
for i in [1,2,3,4,5]:
if i == 2 or i == 4:
continue
print(i) # 输出结果: 1 3 5
- 1
- 2
- 3
- 4
当i等于2或者4的时候,结束循环,所以执行不了print
二、break
关键字:
- break,书写位置:循环体内部
作用:
- 结束整个循环
代码示例:
for i in [1,2,3,4,5]:
if i == 2 or i == 4:
break
print(i) # 输出结果: 1
- 1
- 2
- 3
- 4
当i等于2或者4的时候,结束整个循环,所以后续符合条件的数值都没有打印。
5.2.2 for…else语句
作用:
- 循环执行完之后,才会执行else里的代码。
代码示例:
-
当
for...else语句中出现break时。test = '123' for i in test: if i == '3': break print('第%s次循环' % (i)) else: print('执行完毕') '''输出结果 第1次循环 第2次循环 '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
当**
for...else语句中出现continue**时。test = '123' for i in test: if i == '3': continue print('第%s次循环' % (i)) else: print('执行完毕') '''输出结果 第1次循环 第2次循环 执行完毕 '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
总结:
- for…else语句:在循环执行完之后,才会执行else里的代码。
- 当语句中出现
continue时,else内的代码体仍然可以运行。 - 当
break时,由于退出整个循环了,那么else内的代码自然也就不执行。
5.2.3 实现99乘法表
代码:
for i in range(1, 10):
for j in range(1, i+1):
print(f'{j}x{i}={i*j}\t', end='')
print()
- 1
- 2
- 3
- 4
解析:
-
range函数会在后面章节详细说明,range(1,4)表示可迭代3次,值为1,2,3 不包含4,顾头不顾腚,类似于切片
-
当i=1时,j=range(1,1+1) = 1, 所以输出1*1 = 2,\t制表符隔开,end为空表示结尾不换行,随后内部for循环执行完毕,最后执行print()换行
-
当i=2时,j=range(1,2+1),所以j等于1和2,所以输出 12 22
-
当i=3时,j=range(1,3+1),所以j=1,2,3 所以输出 13 23 3*3
-
…依次类推
5.3 循环结构while
语法格式:
-
while 条件: 循环体 终止循环- 1
- 2
- 3
由于while循环的特点是,当条件成立时无限循环,所以我们不能眼睁睁得看着
死循环发生,需要设置一些条件,然后break终止掉整个循环。# 所以while的基础格式就成了 while 条件: 循环体 if 条件: break- 1
- 2
- 3
- 4
- 5
代码示例:
a = 0
while a < 5: #打印五遍
a += 1 # a 每次循环自加一
print('第{}遍打印'.format(a))
'''输出结果:
第1遍打印
第2遍打印
第3遍打印
第4遍打印
第5遍打印
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
while循环中的break与continue
- 效果与for循环一样的
a = 0 while a < 5: print('while还是强啊') a += 1 if a == 3: break #输出结果:只打印了三次,随后整个循环就结束了 a = 0 while a < 5: a += 1 if a == 2: continue else: print('第%s次' % (a)) #输出结果:没有第二次的,因为跳过了
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5.3.1 while…else语句
当while循环执行完毕之后,再执行else里面的代码
a = 1
while a <= 3:
print('第{}遍打印'.format(a))
a += 1
else:
print('完毕')
'''输出结果:
第1遍打印
第2遍打印
第3遍打印
完毕
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
while…else语句与break、continue
- while…else语句与for…else是一样的,被break打断不会执行else内的代码。
测试如下:
当遇到break时:
a = 1 while a <= 3: print('第{}遍打印'.format(a)) a += 1 if a == 2: break else: print('完毕') '''输出结果: 第1遍打印 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
当遇到continue时:
a = 1 while a <= 3: print('第{}遍打印'.format(a)) a += 1 if a == 2: continue else: print('完毕') '''输出结果: 第1遍打印 第2遍打印 第3遍打印 完毕 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
5.3.2 利用while计算
计算1+2+3+4+…+100
count = 1
sum = 0
while count <= 100:
sum = sum + count
count = count + 1
print(sum)
# 输出结果: 5050
- 1
- 2
- 3
- 4
- 5
- 6
- 7
求1-2+3-4+5-6 … -100的所有数的和
sum = 0
num = 1
while num <= 100:
if num % 2 == 0: #加奇数减偶数,所以对二取余运算。
sum = sum - num
else:
sum = sum + num
num += 1
print(sum)
# 输出结果: -50
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
5.3.3 与for的异同
相同之处:
- 都是循环,for循环可以干的事,while循环也可以干
不同之处:
- while循环称之为条件循环,循环次数取决于条件何时变为假或者break。
- for循环称之为"取值循环",循环次数取决in后包含的值的个数。
六、字符编码
python解释器执行文件的流程:
- 启动pyhon解释器,也就是python.exe
- 解释器将硬盘上的 .py 文件读取到内存中
- 解释器解释刚刚读入内存的内容,开始识别Python语法
什么是字符串编码:
-
人类在与计算机交互时,用的都是人类能读懂的字符,如中文字符、英文字符、日文字符等,而计算机只能识别二进制数。
-
所以由人类的字符到计算机中的数字,必须经历一个翻译的过程,而过程必须参照一个特定的标准,该标准称之为字符编码表,该表上存放的就是字符与数字一一对应的关系,类似于中英文对照表,你好=hello
ASCII码
计算机起源于美国,所以最先考虑仅仅是让计算机识别英文字符,于是诞生了ASCII表
ASCII表的特点
- 只有英文字符与数字的一一对应关系
- 一个英文字符对应1Bytes,1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
此时:
只能识别英文字符,其他国家的字符并不支持。
文件读取或存储到内存、硬盘,参照的都是ASCII编码
此时文件是以ASCII码的二进制存储在硬盘上,当需要读取时,会从硬盘里取出读入到内存中,并且也是ASCII码的二进制,随后文本编辑器再对ASCII进行解码,解码的编码要和文件本身的一致。
GBK编码
为了让计算机能够识别中文和英文,中国人定制了GBK
GBK表的特点
- 只有中文字符、英文字符与数字的一一对应关系
- 一个英文字符对应1Bytes,一个中文字符对应2Bytes
- 1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
- 2Bytes=16bit,16bit最多包含65536个数字,可以对应65536个字符,足够表示所有中文字符
每个国家都有各自的字符,为让计算机能够识别自己国家的字符外加英文字符,各个国家都制定了自己的字符编码表,就造成了…
这种场面下,为了让软件读取到内存时不乱吗,内存中就需要出现一种编码,一种可以兼容万国的编码,不管存入到硬盘的是什么编码,在存入内存时都转成万国码,支持所有字符,这个码就是unicode编码。
unicode编码
特点:
- 存在所有语言中的所有字符与数字的一一对应关系,即兼容万国字符。
- 与传统的字符编码的二进制数都有对应关系。
有了unicode编码之后,文本编辑器输入字符的流程就变成了…
编码与解码
-
由字符转换成内存中的unicode,以及由unicode转换成其他编码的过程,都称为编码encode
-
由内存中的unicode转换成字符,以及由其他编码转换成unicode的过程,都称为解码decode
uft-8的由来
如果文件保存到硬盘的是GBK格式二进制,那么用户打开之后,重新编辑输入的字符只能是中文或英文,那如果我们输入的字符中包含多国字符,要如何处理?
理论上,是可以将内存中unicode格式的二进制,直接存放于硬盘中的,毕竟是万国符嘛。
但是,由于unicode固定使用两个字节来存储一个字符,如果包含大量的英文字符时,使用unicode格式存放会额外占用一倍空间(英文字符其实只需要用一个字节存放即可),并且当我们由内存写入硬盘时会额外耗费一倍的时间,所以将内存中的unicode二进制写入硬盘或者基于网络传输时必须将其转换成一种精简的格式,这种格式即utf-8(全称Unicode Transformation Format,即unicode的转换格式)
- 1
- 2
- 3
那为何在内存中不直接使用utf-8呢?
-
utf-8是不定长的:一个英文字符占1Bytes,一个中文字符占3Bytes,生僻字用更多的Bytes存储,
所以这里面势必要进行一些计算,内存中使用unicode编码这种固定2字节的,会更节省时间。
6.1 字符编码的应用
了解字符编码就是为了存取字符时不发生乱码问题:
- 内存中固定使用unicode无论输入任何字符都不会发生乱码
- 我们能够修改的是存/取硬盘所使用的编码方式,如果编码设置不正确将会出现乱码问题。乱码问题分为两种:存乱了,读乱了。
- 存乱了:如果用户输入的内容中包含中文和日文字符,如果单纯以shift_JIS存,日文可以正常写入硬盘,而由于中文字符在shift_jis中没有找到对应关系而导致存乱了
- 读乱了:如果硬盘中的数据是shift_JIS格式存储的,采GBK格式读入内存就读乱了
python解释器执行文件
-
python解释器读文件时,采用的编码方式为文件当初指定的编码格式,如果没有设置,python解释器则才用默认的编码方式,在python3中默认为utf-8,在python2中默认为ASCII
在文件首行写入包含'#'号在内的以下内容 # coding: 当初文件写入硬盘时采用的编码格式- 1
- 2
-
一个文件test.txt,编码格式为GBK,存入硬盘为utf-8的二进制,当使用python解释器打开时,现将硬盘里的utf-8二进制,转换成Unicode的二进制,随后python读取,如果没有指定编码为GBK,那么默认的utf-8格式和GBK 由于不是同一种编码,所以会乱码。
乱码,因为pycharm默认编码为utf-8,不是GBK(GB2312)
字符串encode编码与decode解码的使用
# 1、unicode格式------编码encode-------->其它编码格式 >>> x='上' # 在python3在'上'被存成unicode,因为变量的值是存入到内存的 >>> res=x.encode('utf-8') >>> res,type(res) # unicode编码成了utf-8格式,而编码的结果为bytes类型,可以当作直接当作二进制去使用 (b'\xe4\xb8\x8a', <class 'bytes'>) # 2、其它编码格式------解码decode-------->unicode格式 >>> res.decode('utf-8') '上'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
七、文件操作
引子:
- 应用程序运行过程中产生的数据最先都是存放于内存中的,若想永久保存下来,必须要保存于硬盘中。
- 应用程序若想操作硬件必须通过操作系统,而文件就是操作系统提供给应用程序来操作硬盘的虚拟概念,用户或应用程序对文件的操作,就是向操作系统发起调用,然后由操作系统完成对硬盘的具体操作。
- 有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程。
利用python打开文件
利用python打开文件,需要知道:
- 文件路径
- 编码方式
- 操作方式(只读,只写,只追加,读写)
格式:
open('文件路径',mode='操作方式',encoding='编码方式')
#mode可以省略不写,利用位置传参,直接写操作方式,如"r+",
- 1
- 2
- open函数返回一个文件对象,该对象有
read方法,可以返回文件句柄,文件句柄后续对内容等操作都需要使用。 - 文件句柄还有一个
close方法,关闭文件请求,回收系统资源。
注意:
- encoding参数如果不赋值的话,那么将按照系统为准,window为GBK,linux为utf-8,注意是系统,不是解释器。
- mode可以省略不写,直接写操作方式,如"r+"
代码示例:
-
# 路径中个别地方需要用反斜来转义,如D:\\新建文本文档.txt file = open('D:\新建文本文档.txt',encoding='utf-8') # 接收open函数返回的文本IO对象 data = file.read() #调用读方法,随后会被操作系统转换为读硬盘操作 # 此时data为文件句柄,后续对文件内容的操作都需要通过它。 print(data) # 打印文件内容 file.close() # 向操作系统发起关闭文件的请求,回收系统资源- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
7.1 资源回收与with上下文管理
打开一个文件包含两部分资源:
-
应用程序的变量file
-
操作系统打开的文件
-
所以,在操作完毕一个文件时,必须把与该文件的这两部分资源全部回收,回收方法为:
file.close() #回收操作系统打开的文件资源 del file #回收应用程序级的变量- 1
- 2
其中del file一定要发生在file.close()之后,否则就会导致操作系统打开的文件无法关闭,白白占用资源, 虽然python自动的
垃圾回收机制决定了我们无需考虑del file,但在操作完毕文件后,最好还是记住file.close()
with open() as
- 既然del file这个操作由垃圾回收机制帮我们做了,那单独一个close()就更容易被遗忘了,所以python提供了
with关键字来帮我们管理上下文。
格式:
-
with open('文件路径','操作方式') as 别名: 子代码块- 1
- 2
在执行完子代码块后,with 会自动执行f.close()
#可用with同时打开多个文件,用逗号分隔开即可 with open('a.txt','r') as read_f,open('b.txt','w') as write_f: data = read_f.read() write_f.write(data) #将a.txt文件中的内容,写入到b,txt- 1
- 2
- 3
- 4
7.2 文件的操作模式
| r 表示只读 | r+表示可读可写 | rb或r+b,以bytes类型读取,主要针对于非文字类的 |
|---|---|---|
| w 表示只写 | w+表示可写可读 | wb以bytes类型读取,主要针对于非文字类的 |
| a 表示只追加 | a+可读可追加 | t 模式只能用于操作文本文件 |
7.2.1 读
相关方法:
-
read():读取所有内容,执行完该操作后,文件指针会移动到文件末尾,同一时间所有内容都被提取出来,并占用了空间。 -
readline():读取一行内容,光标移动到第二行首部。 -
readlines():读取每一行内容,存放于列表中,同一时间所有内容都被提取出来,并占用了空间。 -
也可以配合for循环使用,同一时刻只读入一行内容到内存中。
注:在使用read和readlines的时候,要考虑到文件的大小。
代码示例:
-
readline
with open('data.txt','r',encoding='utf-8') as f: print(f.readline()) print(f.readline()) print(f.readline()) '''输出结果: 2021年5月10日 2021年5月16日 2021年5月19日 ''' readline把文件内每一行末尾换行也读出来了,所以这里会有很大的“空隙”,其实是“\n”换行。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-
read
with open('data.txt','r',encoding='utf-8') as f: print(f.read()) '''输出结果: 2021年5月10日 2021年5月16日 2021年5月19日 '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
readlines
with open('data.txt','r',encoding='utf-8') as f: print(f.readlines()) '''输出结果: ['2021年5月10日\n', '2021年5月16日\n', '2021年5月19日'] '''- 1
- 2
- 3
- 4
- 5
- 6
-
for循环
with open('data.txt','r',encoding='utf-8') as f: for i in f: print(i) '''输出结果: 2021年5月10日 2021年5月16日 2021年5月19日 '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
只读 r 和 rb
只读:
文件名: - D:\\test.txt 文件的内容: - 2021年5月16日 - 2021年5月16日
- 1
- 2
- 3
- 4
- 5
file = open('D:\\test.txt',encoding='utf-8') data = file.readlines() for i in data: print(i) file.close() # 输出结果: 2021年5月16日 # 2021年5月16日
- 1
- 2
- 3
- 4
- 5
- 6
- 7
流程如下:
- 文件是什么编码格式,最终从内存里获取到的,也要用相同的方式解码,否则就会乱码
只读,并且是bytes数据类型:
file = open('D:\\test.txt','rb') data = file.read() print(data) print(data.decode('utf-8')) file.close() # 输出结果: # b'2021\xe5\xb9\xb45\xe6\x9c\x8816\xe6\x97\xa5\r\n2021\xe5\xb9\xb45\xe6\x9c\x8816\xe6\x97\xa5' # 2021年5月16日 # 2021年5月16日
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
rb模式:
- 将bytes数据类型完完整整的接收,不做任何处理,常用于非文字类。
- bytes数据类型是二进制0101010001,之所以是b’\xe6\x88…,是因为python环境为了更好的观察,以16进制的形式展示,开头的b表示这是一个bytes类型。
文件以bytes数据类型打开,但文件在硬盘存储为utf-8编码,所以上文代码中,我们可以
decode拿到文件原本的内容。
注意事项:
-
打开一个文件之后,之所以可以从头读到尾,是因为开始的光标就是开头,也就是第一行的第一位
-
当read读完之后,这个光标就跑到了文件的末尾,既然都末尾了那后面肯定就没有内容了,所以重复
print(f.read())会不执行with open('data.txt','r',encoding='utf-8') as f: print(f.read()) print('第一次read完毕') print(f.read()) # 并不会重新打印出文件的内容 print(f.read()) # 因为文件的光标在末尾了,没有内容可以供打印。- 1
- 2
- 3
- 4
- 5
可读可写 r+
代码示例:
with open('data.txt','r+',encoding='utf-8') as f: f.read() # 现在光标在文件末尾了 f.write('\n2022年8月20日') # 由于目前光标在末尾,要想查看文件的全部内容,在现阶段需要重写打开,然后读出来。 with open('data.txt','r',encoding='utf-8') as f: for i in f.readlines(): print(i) '''输出数据: 2021年5月10日 2021年5月16日 2021年5月19日 2022年8月20日 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
以r+可读可写的方式、utf-8编码打开data.txt文件,随后先执行f.read(),目的是让光标移动到文件的末尾,然后再使用f.write追加内容,如果不这样,那么f.write将会覆盖写入
“覆盖写入”的解决办法:
- 由于read相关函数调用之后,光标移到了末尾,所以可以先读后写,从而实现追加内容。
- 或者直接特喵的使用追加模式。 (详情见后续章节)
- 或者修改光标位置。 (详情见后续章节)
7.2.2 写
只写 w 和 wb(不推荐使用)
- 默认光标指针在前,所以直接写入会先清空再写入
注意:
-
在文件不关闭的情况下,连续的写入,后写的内容一定会跟在前写内容的后面。
-
如果重新以w模式打开文件并写入,则会清空文件内容!!!
-
如果open函数指定的文件不存在,那么会创建一个
# 示例 with open('test.txt','w',encoding='utf-8') as f: f.write('111') f.write('222') f.write('\n') f.write('333') print('写入完毕') with open('test.txt','r',encoding='utf-8') as f: print('查看当前写入的内容:') print(f.read()) print('============') with open('test.txt','w',encoding='utf-8') as f: print('重新以W只读打开文件') with open('test.txt','r',encoding='utf-8') as f: print('再次打开文件,查看当前的内容') print(f.read()) '''输出内容: 写入完毕 查看当前写入的内容: 111222 333 ============ 重新以W只读打开文件 再次打开文件,查看当前的内容 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
可以很明显的看到,原本写入的内容,重新以只读的方式打开以后,文件被清空了,再次读取就发现读取不到内容。
总结:
- 写入数据的时候会遇到“覆盖写入”的问题。 (代码示例在"写r+"章节)
- 重复以只读的方式打开会清空文件。
- 总结就是使用这玩意干啥…
wb模块
-
wb模式下,不需要再指定编码。
with open('D:\\test.txt','wb') as f: f.write('123'.encode('utf-8'))- 1
- 2
这里写入的时候需要进行编码,将字符串’123’编码成utf-8的二进制,这样同为bytes数据类型就可以写入进去了。
7.2.3 追加
只追加 a
- 默认光标都在后
with open('data.txt','a',encoding='utf-8') as f:
f.write('719')
with open('data.txt','r',encoding='utf-8') as f:
print(f.read())
# 输出结果:liuyu719
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 可以发现,原本的数据并没有被覆盖,a模式下写入的数据默认就是在末尾。
只追加a与只写w的异同点:
1 相同点:在打开的文件不关闭的情况下,连续的写入,新写的内容总会跟在前写的内容之后
2 不同点:以 a 模式重新打开文件,不会清空原文件内容,会将文件指针直接移动到文件末尾,新写的内容永远写在最后
7.2.4 指定取多少字符的内容
示例文件内容(test.txt)
-
1、先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。- 1
取两个字符
f = open('test.txt',mode='r+',encoding='utf-8')
print(f.read(2)) #取两个字符
f.close()
#输出结果 1、
- 1
- 2
- 3
- 4
取四个字节
f = open('test.txt',mode='rb')
print(f.read(4)) #取四个字节
f.close()
#输出结果 b'1\xe3\x80\x81'
a = b'1\xe3\x80\x81' #因为test.txt文件是utf-8进行编码的,所以4个字符分别为数字“1”占一个,中文标点“顿号”占三个。
print(a.decode('utf-8'))
#输出结果 1、
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
7.3 更改文件内指针(光标)
针对于文件指针操作的函数
| 函数名 | 说明 |
|---|---|
| f.seek(指针移动的字节数,模式控制) | 以文件开头为起始点,移动n个字节 |
| f.seek(指针移动的字节数,模式控制) | 以上一次移动指针为起点,再次移动n个字节 |
| f.seek(n,2) | 以文件末尾为起始点,移动n个字节 |
| print(f.tell()) | 查看当前光标 |
模式控制:
- 0: 默认的模式,该模式代表指针移动的字节数是以文件开头为参照的。
- 1: 该模式代表指针移动的字节数,是以当前所在的位置为参照的。
- 2: 该模式代表指针移动的字节数,是以文件末尾的位置为参照的。
- 强调:1跟2模式只能在b模式下用。
代码示例:
test文件内容:
1、先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。 2、然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。
- 1
- 2
代码:
一、以文件开头为起点,移动4个字节with open('D:\\test.txt',mode='r',encoding='utf-8') as f: f.seek(4,0) # 0模式,代表从文件开头出为起点参照物。 print(f.readline()) #输出: “先帝....秋也” 因为一个数字字符1字节,一个中文字符3字节。
- 1
- 2
- 3
二、以当前指针位置为起点,再移动4个字节
# b模式才可以使用模式控制1 with open('D:\\test.txt',mode='rb') as f: f.readline() # 先读,readline表示读一行,此时光标在第一行的末尾 f.seek(4,1) #在第一行的末尾基础之上进行移动4个字节。 print(f.readline().decode('utf-8')) #输出结果:“然侍卫之....也” print(f.tell()) #查看指针现在所在位置,为第二行的末尾219字节后面
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
7.4 文件内容修改/重命名
文件对应的是硬盘空间,硬盘不能修改对应着文件本质也不能修改, 那我们看到文件的内容可以修改,是如何实现的呢? 大致的思路是将硬盘中文件内容读入内存,然后在内存中修改完毕后再覆盖回硬盘 具体的实现方式分为两种:
#实现思路:将文件内容发一次性全部读入内存,然后在内存中修改完毕后再覆盖写回原文件
#优点: 在文件修改过程中同一份数据只有一份
#缺点: 会过多地占用内存
#test.txt文件内容为: 123你好世界
with open('test.txt',mode='r',encoding='utf-8') as f:
content = f.read()
with open('test.txt', mode='r+', encoding='utf-8') as f:
f.write(content.replace('123','一二三')) #replace字符串替换
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
# 实现思路:以读的方式打开原文件,以写的方式打开一个临时文件,一行行读取原文件内容,修改完后写入临时文件...,删掉原文件,将临时文件重命名原文件名
#优点: 不会占用过多的内存
#缺点: 在文件修改过程中同一份数据存了两份
with open('test.txt',mode='r',encoding='utf-8') as f,open('test.txt_back',mode='w',encoding='utf-8') as f2:
for i in f:
if '123' in i:
i = i.replace('123','YIERSAN')
f2.write(i)
import os
os.remove('test.txt')
os.rename('test.txt_back','test.txt')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
八、函数
引子:
假设:如果有一天len方法突然不能直接用了,然后现在有一个需求,让你计算’hello world’的长度,你怎么计算?
str1 = "hello world" length = 0 for i in str1: length = length+1 print(length)
- 1
- 2
- 3
- 4
- 5
现在所要的功能确实可以实现,很完美,但是如果需要计算的字符串不止这一个那怎么办,难道要将循环代码写很多遍吗,一个是时间效率,另一个是代码重复量大,那么此时就需要用到函数。
什么是函数:
- 函数的核心在于事先准备好工具,遇到应用场景时拿来就用,而不是等遇到了才临时制造。在程序中,具备某一功能的工具指的就是函数,事先准备工具的过程即函数的定义,拿来就用即函数的调用。
定义函数的语法
函数的格式:
-
def 函数名(参数1,参数2,...): """文档描述""" 函数体 return 值 #(返回值视情况而定) 函数名() #调用函数,执行函数体的代码- 1
- 2
- 3
- 4
- 5
- 6
一、定义函数
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 print(length) #函数调用 mylen() #输出结果: 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
此时我们可以看到s1字符串的长度被计算了出来.
但是还有个问题,那就是如果我们需要把计算出来的这个值做运算,而函数代码中只有print在控制台中显示一下而已,并没有把这个结果返回给我们,所以我们需要定义返回值。
二、返回值
返回值的几种情况:
- 没有返回值
- 返回一个值
- 返回多个值
'没有返回值' 1.不写return的情况下,会默认返回一个None:我们写的第一个函数,就没有写return,这就是没有返回值的一种情况。 2.只写return,后面不写其他内容,也会返回None,因为一旦遇到return,结束整个函数。 3.直接 return None
- 1
- 2
- 3
- 4
'返回一个值' 1.只需在return后面写上要返回的内容即可。
- 1
- 2
'返回多个值' 1.可以返回任意多个、任意数据类型的值。 2.返回的多个值会被组织成元组被返回,也可以用多个值来接收。用多个值接收返回值:返回几个值,就用几个变量接收
- 1
- 2
- 3
所以就有了:
-
def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 #print(length) return length #将长度返回给调用它的地方 #函数调用 ret = mylen() #接收到之后,赋值给变量 print(ret+10) #结果为21,说明变量ret接收的到返回值- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
定义函数mylen,调用该函数返回字符串s1的长度,返回值的数据类型为int,可用于后续计算。
新问题:
- mylen这个函数只能用来计算s1字符串的长度,写死了,所以后续使用并不方便。
- 此时就需要运用到带参数的函数。
带参数的函数
#函数定义 def mylen(str): length = 0 for i in str: length = length + 1 return length #函数调用 str1_len = mylen("hello world") print(f'长度为{str1_len}') # 输出结果: 长度为11 str2_len = mylen('123456') print(f'长度为{str2_len}') # 输出结果: 长度为6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
我们需要告诉mylen函数要计算的字符串是谁,这个过程就叫做 传递参数,简称传参。
调用函数时传递的这个“hello world”和定义函数时括号里的str就是参数。
参数又分为形参和实参
实参与形参-1:
-
我们调用函数时传递的这个“hello world”,被称为实际参数,因为这个是实际的要交给函数的进行处理的,简称实参。
-
定义函数时括号里的str,被称为形式参数,因为在定义函数的时候它只一个形式,表示这里有一个参数,接收实参传来的数据,简称形参。
-
形参和实参可以有多个,如下:
def my_max(x,y): the_max = x if x > y else y return the_max max_num = my_max(10,20) #返回实参中最大的数 print(max_num) # 输出结果: 20- 1
- 2
- 3
- 4
- 5
- 6
实参与形参-2:
站在实参的角度:
1.可以按照位置传参
def my_max(x,y): the_max = x if x > y else y return the_max max_num = my_max(10,20) #返回实参中最大的数 print(max_num) # 输出结果: 20
- 1
- 2
- 3
- 4
- 5
- 6
这个代码就是按照位置传参,传一个实参,值为10是由x接收而非y,按照先后顺序的。
2.按照关键字传参
def test(x,y,z): print(x,y,z) test(1,2,z=3) # 输出结果: 1 2 3
- 1
- 2
- 3
- 4
指定某一个参数的值,但是要满足定义形参时的先后顺序。
- 1、位置参数必须在关键字参数的前面。
- 2、对于一个形参只能赋值一次。
站在行参的角度:
1.默认参数
def stu_info(name,sex = "Boys"): print(name,sex) stu_info('大锤') stu_info('铁锤','Girls ') # 输出结果: 大锤 Boys # 输出结果: 铁锤 Girls
- 1
- 2
- 3
- 4
- 5
- 6
- 7
作用:可以定义形参时,设置默认的参数值,当没有传参时,使用默认值。
2.动态参数
可以解决什么问题:
当需要实现计算器加法功能时,会遇到一个问题,那就是不知道实参有多少,有可能参数只有两个1和2,也有可能是三个1和2和3,所以就没办法定义相对应数量的形参。
*args 可以接收所有位置参数,保存成元组形式
- “ * ” 表示将多余的位置参数进行归纳,然后赋值给args,数据类型为元祖(形参中)
- 需要注意的是,当 “ * ” 号出现在函数体或者其他地方时,那就不是归纳,而是打散。
**kwargs可以接收任意个关键字参数,保存成字典形式。
- “ ** ” 表示将多余的关键字参数,进行归纳,随后赋值给kwargs,数据类型为字典。(形参中)
- 需要注意的是,当 “ ** ” 号出现在函数体或者其他地方时,那就不是归纳,而是打散。
def count_num(*args): # *args可以接收多个参数 sum = 0 for i in args: # 此时的args是元祖,for循环拿到的是每个元素 sum += i return sum sum = count_num(1,2,3,4) print(sum) # 输出结果:10 经过函数处理,打印1+2+3+4的结果。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
def stu_info(**kwargs): print(kwargs) stu_info(name = '铁锤',sex = '女孩') # 输出结果:{'name': '铁锤', 'sex': '女孩'}
- 1
- 2
- 3
- 4
定义函数的规则:
- 1、
定义:以def 关键词开头,空格之后接函数名称和圆括号()。 - 2、
参数:圆括号用来接收参数。若传入多个参数,参数之间用逗号分割。- 如果涉及到多种参数的定义,应始终遵循:位置参数、*args、默认参数、kwargs顺序定义。
- 3、
注释:函数的第一行语句应该添加注释,描述该函数形参、返回值,以及能实现的效果。 - 4、
函数体:函数内容以冒号起始,并且缩进。 - 5、
返回值:return [表达式] 结束函数。不带表达式的return相当于返回 None
调用函数的规则:
- 1、函数名后面+圆括号就是函数的调用。
- 2、圆括号用来传入参数,若传入多个参数,应按先位置传值,再按关键字传值。
- 3、如果函数有返回值,还应该定义变量接收返回值,如果返回值有多个,也可以用多个变量来接收,变量数应和返回值数目一致。
函数命名的一些规范
-
形参后面冒号跟的数据类型,表示当前形参需要的数据类型,用于提示
-
–> 表示该函数返回值的提示信息。
def test(name:str,msg:str,num:int=1)->str: ''' 用于两段字符串的拼接以及后续乘法的运算 :param name: 字符串 :param msg: 字符串 :param num: 倍数,默认为1 :return: 拼接之后的字符串乘以倍数 ''' return (name+msg)*num print(test('团结紧张','严肃活泼',3)) # 输出结果:团结紧张严肃活泼团结紧张严肃活泼团结紧张严肃活泼- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
获取函数的提示信息:
print(test.__annotations__)
# {'name': <class 'str'>, 'msg': <class 'str'>, 'num': <class 'int'>, 'return': <class 'str'>}
- 1
- 2
其他:
print(test.__name__) #查看字符串格式的函数名
print(test.__doc__) #查看函数的注释
'''输出内容:
test
用于两段字符串的拼接以及后续乘法的运算
:param name: 字符串
:param msg: 字符串
:param num: 倍数
:return: 拼接之后的字符串乘以倍数
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
8.1 名称空间与作用域
引子
先来定义一个函数
def my_max(x,y): m = x if x>y else y return m bigger = my_max(10,20) print(bigger)
- 1
- 2
- 3
- 4
- 5
有没有想过,为什么还需要定义变量来接收return m 呢,为什么不在函数体外面直接print呢,我们来试试看。
def my_max(x,y): m = x if x>y else y my_max(1,3) print(m) # 报错如下: NameError: name 'm' is not defined #名称错误: 未定义名称“m”
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结果就报错了,意思时名称m没定义,也就是没有m这个变量,这时就要引出命名空间和作用域这个概念了。
命名空间
全局命名空间: 代码在运行伊始,创建的存储“变量名与值的关系”的空间。
局部命名空间: 是在函数的运行中开辟的临时的空间。
内置命名空间: 中存放了python解释器为我们提供的名字:input,print,str,list,tuple…
作用域
作用域就是作用范围,按照生效范围可以分为全局作用域和局部作用域。
全局作用域:包含内置名称空间、全局名称空间,在整个文件的任意位置都能被引用、全局有效。
局部作用域:局部名称空间,只能在局部范围内生效。
简单来说就是:
-
局部的可以找自己、全局和内置的东西。
-
全局的只能找自己和内置的。
-
内置的就只能找自己的。
所以我们在局部命名空间定义的变量m,在全局命名空间是没有用的,因为这两个命名空间的作用域都是不一样的,所以在函数内部声明的变量m并不能在全局直接方法,所以选择了使用return的方式,将内部的变量值进行返回,变相的将内部变量作为全局使用。
8.1.1 global关键字
作用:
- 当在局部想对全局变量的值进行修改的时候(不可变数据类型),可以使用global关键字。
a = 10
def func():
global a
a = 20
#查看原来的值
print(a) # 输出结果: 10
# 调用函数修改全局a的值
func()
#查看经过局部修改之后的值
print(a) # 输出结果: 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
8.1.2 nonlocal关键字
作用:
- 当需要修改函数外层函数包含的名称对应的值时(不可变数据类型),需要使用nonlocal
x = 0
def func1():
x = 11
# 定义func2函数,但是未执行
def func2():
nonlocal x
x = 22
# 调用func2函数修改外层函数func1的x变量
func2()
print(f'func1内的x值为{x}')
func1()
# 输出结果: func1内的x值为22
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
8.2 函数对象
由前几节我们知道,函数加括号是调用,并且可以拿到返回值,那么不加括号呢。
def test():
print('test函数')
f = test
print(test) # 输出结果: <function test at 0x0000024CF3425F70>
print(f) # 输出结果: <function test at 0x0000024CF3425F70>
test() # 输出结果: test函数
f() # 输出结果: test函数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以看到,不加括号打印输出的是内存地址,并且我们将这个内存地址赋值给变量时,由于指向的同一个内存地址,且还是函数,所以变量f可以加括号调用。
函数对象,精髓就是可以把函数当成变量去用
应用案例:
- 当用户输入不同指令时,可以调用不同的功能模块
def back(): # 退出功能模块 print('已退出') def login(): # 登陆功能模块 print('登陆') def register(): # 注册功能模块 print('注册') # 指令与模块之间的对应关系列表 func_list = [ {'0':['退出',back]}, {'1':['登陆',login]}, {'2':['注册',register]}, ] # 业务代码运行 print(''' 后台管理系统 \t退出请输入0 \t登陆请输入1 \t注册请输入2 ''') choose = input('输入指令:').strip() # 获取输入的指令 if choose.isdigit() and int(choose) in range(0,len(func_list)): # 当输入的字符串是数字,且输入的数字要在 0-2之间 func_list[int(choose)][choose][1]() # 通过列表字典查找值的方式,找到对应的函数内存地址,并加()括号调用 else: print('输入的指令不正确')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
上述代码中,就是将功能模块,以及输入指令对应的调用关系,组成了一个列表,列表内是字典格式,记录了:
- 指令0,对应的功能是退出,功能函数内存地址是back
- 指令1,对应的功能是登陆,功能函数内存地址是login
- 指令2,对应的功能是注册,功能函数内存地址是register
8.3 闭包函数
大前提:
闭包函数 = 名称空间与作用域+函数嵌套+函数对象核心点;名字的查找关系以函数定义阶段为准
闭包:
- “闭”代表函数是内部的,“包”代表函数外’包裹’着对外层作用域的引用。因而无论在何处调用闭包函数,使用的仍然是包裹在其外层的变量。
闭包的用途:
- 可以在全局使用局部的属性
- 可以利用闭包进行传值
函数传值的第一种方法
# 声明形参 def func(x): print(x) func(1)
- 1
- 2
- 3
- 4
函数传值的第二种方法
def fun(x): def func(): print(x) return func test = fun(111) print(test) # <function fun.<locals>.func at 0x000001A59BA903A0> # fun函数 内部的func func的内存地址 test() # 输出结果:111
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- fun函数有一个形参x,后续调用时传入了111,此时就再fun函数的名称空间中声明了x=111。
- 内部函数func使用了外层函数fun的x变量,所以func函数的运行结果为,打印调用fun函数时传入的参数。
- fun函数内部,之所以要return func,是因为要把内部函数的内存地址给返回出去,这样才能被变量所接收调用。
8.4 装饰器
装饰器的作用:
- 在不改变函数调用方式、不改变函数源码的情况下,对该函数增添额外的功能。
为什么要使用装饰器:
- 因为在开发过程中,需要遵守开放封闭原则。
- 开放:指的是,对拓展功能是开放的。
- 封闭:指的是对修改源代码是封闭的。
装饰器公式:
def 函数(被装饰的函数):
def 闭包函数(*args, **kwargs):
装饰之前的动作
接收的变量 = 被装饰的函数(*args, **kwargs)
装饰之后的动作
return 接受的变量
return 闭包函数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
装饰器分析:
代码示例:
import time def index(*args): count = 0 for i in args: count += i return count def timmer(func): # func=index函数的内存地址 def inner(*args, **kwargs): start = time.time() # 计算从1970.1.1到现在经过的秒数 time.sleep(2) # 睡2秒,用于看到实验效果而已。 res = func(*args, **kwargs) end = time.time() # 计算从1970.1.1到现在经过的秒数 print(end - start) # 用结束时间减去开始时间,就是实际执行的时间。 return res return inner index = timmer(index) # index = inner = return res = index() print(index(1, 2, 3, 4, 5, 6)) # 输出结果: 2.0024735927581787 # 输出结果: 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
首先是定义了一个函数index,可以接收多个参数进行计算,此时需要添加一个功能,那就是计算下index函数的运算时间,在不改变原函数的调用方式,以及原函数的源代码的情况下,可以使用装饰器来修饰。
- index = timmer(index),代码先执行右侧的,timmer(index),将index函数的内存地址当做参数传入,并被timmer函数的形参func所接收,所以在timmer函数的内部会执行func=index函数的内存地址。
- 由于timmer(index)的返回值为inner,所以index函数的内存地址,被重新赋值称为timmer下的inner函数内存地址。
- 所以index(1,2,3,4,5,6),这一步就是在调用inner函数,传入的参数被args和kwargs所接收,随后执行被装饰函数执行完毕之前新增的功能代码
- res = func(*args,**kwargs)这一步,还是先执行等号右侧的,这里的func属性为外层的func=index函数的内存地址,加括号表示调用,同时将传入的参数通过 “ * ” 号打散,得到最开始传入参数的样子1,2,3,4,5,6,执行index函数,随后将返回值赋给res,最后执行被装饰函数执行完毕之后新增的功能代码,并把res返回。
- 最终print(index(1,2,3,4,5,6))打印的是inner函数内部的res,而res的值,是通过调用index函数返回的,只是在调用Index函数之前和之后,我们新增了一些代码,用于计算时长而已。
语法糖
-
语法糖可以帮我们省略这句代码 index = timmer(index)
-
格式为:
def 装饰器函数(): @装饰器函数的名称 def 被装饰函数():- 1
- 2
- 3
- 4
注意:装饰器函数一定要在,被装饰器函数的上面
修改之后还能继续调用
import time def timmer(func): def inner(*args,**kwargs): start = time.time() time.sleep(2) res = func(*args,**kwargs) end = time.time() print(end - start) return res return inner @timmer def index(*args): ''' 计算函数 ''' count = 0 for i in args: count += i return count print(index(1,2,3,4,5,6)) # 输出结果: 2.0024735927581787 # 输出结果: 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
在上述案例中,我们将原函数名指向的内存地址,《偷梁换柱》成inner函数,所以我们应该将inner函数,做的跟原函数index一样才行。
先来看看有哪些不同
-
被装饰之后,打印__name__方法与__doc__方法
print(index.__name__) # inner print(index.__doc__) # None- 1
- 2
原来的__name__方法与__doc__方法
print(index.__name__) # index print(index.__doc__) # 计算函数- 1
- 2
双下name方法表示,对应实际内存地址的函数名称,双下doc方法表示函数的注释信息,可以看到因为index函数加了装饰器之后,实际运行的函数是inner,所以我们为了做的跟原函数一样,双下的一些方法,如name和doc,我们也要改成和原函数一样的。
由于方法过多,每个装饰器都要写一大堆 inner.__name__ = func.__name__ 。。。。。
''' python中提供了一个模块,该模式是个装饰器,只需要装饰在inner函数即可: ''' import time from functools import wraps def timmer(func): @wraps(func) # 将inner函数进一步伪装成index函数 def inner(*args,**kwargs): start = time.time() time.sleep(2) res = func(*args,**kwargs) end = time.time() print(end - start) return res return inner @timmer def index(*args): ''' 计算函数 ''' count = 0 for i in args: count += i return count print(index.__doc__)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
8.4.1 有参数的装饰器
通过上一节的呢,我们利用装饰器实现了对index函数新增计时功能。
如果此时我们再加一个功能,那就是将index计算好的数值,按照传入的参数进行相乘,如index(1,2,3,),最后输出60
哪里可以加参数?
首先
inner(*args,**kwargs)这里是不能加参数的,因为要和func(*args,**kwargs)保持一致,因为inner函数就是要伪装成index函数的,所以这里不可以新增参数。
timmer(func)这里也不可以加,因为语法糖不支持多个参数。所以解决方案就是,再套一层
代码示例:
def func(x): def timmer(func): def inner(*args,**kwargs): res = func(*args,**kwargs) * x return res return inner return timmer @func(10) def index(*args): count = 0 for i in args: count += i return count print(index(1,2,3,))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
分析:
- 语法糖
@func(10),首先这里的func是个函数,加了括号那就是调用,调用返回的结果是timmer函数的内存地址,所以@func()就变成了@timmer。 - 此时不仅装饰器回到了上一章节,而且还把 x 这个值给带入了进来,后续还需需要其他参数,就不需要再套一层了,我们可以直接@func(参数1,参数2,参数3…)
有参装饰器公式
def 有参装饰器(参数) def 装饰器函数(被装饰的函数): def 闭包函数(*args,**kwargs): 装饰之前的动作 接收的变量 = 被装饰的函数(*args,**kwargs) 装饰之后的动作 return 接收的变量 return 闭包函数 return 装饰器函数 @有参装饰器(参数) def 被装饰函数(): pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
8.5 迭代器
可迭代对象
- 但凡内置有__iter__方法的,都称之为可迭代对象。
- 字符串、列表、元组、字典、集合、文件对象,这些都是可迭代对象。
调用可迭代对象的__iter__方法,会将其转换成迭代器对象。
dic = {'name':'liuyu','age':22} res = dic.__iter__() print(res) # 输出结果:<dict_keyiterator object at 0x000002152DCBB950>
- 1
- 2
- 3
- 4
iterator [ɪtə’reɪtə] 翻译为: 可迭代的
迭代器:
-
拥有
__next__方法,以及__iter__方法的,就是迭代器 -
调用
__next__可以迭代获取到元素或Keydic = {'name':'liuyu','age':22} dic_iterator = dic.__iter__() print(dic_iterator.__next__()) # name print(dic_iterator.__next__()) # age print(dic_iterator.__next__()) # 抛出异常 StopIteration- 1
- 2
- 3
- 4
- 5
- 6
-
调用第一次__next__方法之后,返回dic字典的key。
-
再次调用时,在第一次的基础之上,返回下一个key。
-
因为字典没有其他key了,所以再次调用就抛出异常。
迭代器中的__iter__方法:
- 迭代器对象调用该方法时,不会有任何变化,得到的还是迭代器对象本身。
- 存在的意义,是为了给for循环使用,这样for循环时,不管跟的是可迭代对象还是迭代器,都调用__iter__方法,这样拿到的都是迭代器对象。
for循环原理
dic = {'name':'liuyu','age':22} for i in dic: print(i)
- 1
- 2
- 3
- 4
- 1、for循环中,现将dic调用__iter__,拿到迭代器对象。
- 2、随后依次调用迭代器对象中的__next__方法,直到捕获到异常。
附:
-
__next__和__iter__方法,其实还有另外一种写法
next() iter()- 1
- 2
代码示例:
dic = {'name':'liuyu','age':22} dic_iterator = iter(dic) print(next(dic_iterator)) print(next(dic_iterator)) # 输出结果: name age- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
迭代器的优缺点:
- 优点:惰性计算,减少内存占用。
- 缺点:当一个迭代对象用__next__方法,获取到所有内容之后,就不能再调用了,只能利用可迭代对象,再生成一个迭代对象。
扩展:
- 调用open方法生成的文件对象,其本身就是迭代器对象,具有__next__方法,以及__iter__方法。
- 因为文件,有可能会有很多很多行,所以文件对象为迭代器对象时,只有调用__next__方法,才会从文件中拿到一行,调动一次获取一行,不会将所有内容一次性都读入到内存中。
8.6 生成器
什么是生成器函数
- 当函数内部出现yield关键字函数时,该函数变成了生成器函数
生成器
- 生成器函数调用之后形成生成器
- 生成器就是迭代器,具有可迭代性,拥有
__next__和__iter__方法。
yield返回值
代码示例:
def generator(): print(1) yield 'a' # 当出现yield的时候这个函数就变成了生成器函数 print(2) yield 'b' # yield与return只允许出现一个,效果都是返回值 print(3) yield 'c' # yield并不会结束函数,可以理解为暂停 # 会随着每次.__next__来结束暂停,并继续执行,当执行到下一个yield时,返回值之后,会继续暂停。 g = generator() # 生成器函数调用之后形成生成器,生成器就是迭代器,具有可迭代性 # 既然就是迭代器,那么就可以通过__next__方法来获取内容 print(g.__next__()) # 输出结果:1 a print(g.__next__()) # 输出结果:2 b print(g.__next__()) # 输出结果:3 c print(g.__next__()) # 抛出异常StopIteration
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
注意:
- 生成器与迭代器一样,当使用__next__将值全部取完之后,再取就会抛出异常,需要再次利用生成器函数产生新的生成器。
send()
send(),给yield传值
作用:
- 当使用next之后,生成器函数内部会暂停在yield处,此时可以利用send()方法给yield进行传值,随后yield可以将收到的值,赋给变量,并在后续的代码中使用传入的值。
代码示例:
def eat(name): print('%s好饿,想吃东西'%name) while True: food = yield print('\t正在吃%s'%food) # 利用生成器函数,生成 生成器函数 generator = eat('阿煜') # 使用next方法,将代码运行暂停在yield处 next(generator) # 向yield传参 generator.send('麻辣香锅') ''' 暂时挂起,可以运行其他代码 ''' generator.send('炭烤牛蛙') ''' 暂时挂起,可以运行其他代码 ''' generator.send('韩式烤肉') # 控制台输出: #阿煜好饿,想吃东西 # 正在吃麻辣香锅 # 正在吃炭烤牛蛙 # 正在吃韩式烤肉
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 生成器
eat调用之后,得到generator生成器,生成器与迭代器一样,都具有可迭代性,调用next方法之后,代码到yield暂时“挂起”。- 这个时候
send()函数给yield传值,然后由food变量接收,紧接着就执行print代码了。- 随后只要后续再执行send方法就执行,这个时候我们可以执行其他代码。
8.7 递归函数
什么是递归函数:
- 在调用一个函数的过程中,又直接或间接地调用到本身。
应用场景:
- 如:二分查找(算法)
现在,有一个列表lis,里面存放的是从小到大的数字,现在利用for循环,将指定的数值找到。
lis = [1,2,3,4,5,6,7,8,18,19,23,56,62,78,99,130,150,520] def select_num1(find_num,list): for i in list: if i == find_num: print('找到了') import time start_time = time.time() select_num1(520,lis) # 调用函数 time.sleep(1) # 睡一秒 print(round(time.time() - start_time,7)) # 输出总共执行的时间 # 输出结果: 找到了 1.0146868
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
二分法
原理:
- 先得到列表中索引是中间的值,随后将查询的数字与其对比。
- 当查询的数值大于中间数值时,那么就以中间为分割,往右查。
- 当查询的数值小于中间数值时,那么就以中间为分割,往左查。
- 当查询的数值等于中间数值时,那就是找打数值了
- 随后利用递归,不断重复循环体内部的代码,将列表不断的对半分片,然后查找,对半分片然后查找。
代码示例:
def select_num2(find_num,lis): print(lis) mid_index = len(lis) // 2 mid_num = lis[len(lis) // 2] if mid_num > find_num: lis = lis[:mid_index] select_num2(find_num, lis) elif mid_num < find_num: lis = lis[mid_index+1:] select_num2(find_num, lis) else: print('找到了') import time start_time = time.time() select_num2(520,lis) time.sleep(1) print(round(time.time() - start_time,7)) # 输出结果: 找到了 1.0026853 ''' 附:列表每次递归之后的变化 [1, 2, 3, 4, 5, 6, 7, 8, 18, 19, 23, 56, 62, 78, 99, 130, 150, 520] [23, 56, 62, 78, 99, 130, 150, 520] [130, 150, 520] [520] '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- mind_index为中间数的索引,min_num为中间数的值,后续用来和find_name进行比较。
- 判断之后,find_num大于min_num时,对列表进行切片,切取右半部分,反之则是左半部分。
- 注意,切片的时候因为“顾前不顾腚”,所以向右切片时,会把min_num给包含进去,所以要+1
传统方法的耗时:
- 第一次:0.0077575(单位/秒)
- 第二次:0.0066813(单位/秒)
二分算法的耗时:
- 第一次:0.0056694(单位/秒)
- 第二次:0.0021276(单位/秒)
8.8 匿名函数
格式:
lambda 参数1,参数2...: 返回值
- 1
匿名函数的调用方式
-
方式一:
print(lambda x,y,z:x*y*z) # 输出结果: <function <lambda> at 0x000002AACA805F70>- 1
- 2
可以看到,直接打印匿名函数表达式,返回的是内存地址,所以我们可以直接加括号调用,但是此时lambda表达式也要用括号括起来,不然调用函数的括号,会与返回值视为一个整体。
res = (lambda x,y,z:x*y*z)(1,2,3) print(res) # 输出结果: 6- 1
- 2
- 3
-
方式二:
func = lambda x,y,z:x*y*z print(func(2,3,4)) # 输出结果: 24- 1
- 2
- 3
注:
- 虽然方式二,可以调用匿名函数,但是这样就毫无意义了,要的就是匿名,结果还是将内存地址给了func,还不如直接def。
- 匿名函数讲究的就是用完就销毁,一次性的,所以方式二绝对不会用到,而方式一也极少数情况会这么用。
应用场景:
- 见8.9章节的几个内置函数
8.9 内置函数
本章节前半部分(89.1–8.9.4)承接lambda匿名函数的一些应用,后续章节中详细的介绍了其他常用的内置函数使用方法。
8.9.1 max函数
lis = [1,2,3,5,301,1,208]
print(max(lis)) # 输出结果: 301
- 1
- 2
利用max方法,快速找到列表中最大的元素。
那字典用这个方法如何呢?
dic = {'盖伦':38,'嘉文':37,'赵信':500,'拉克丝':22,'希瓦娜':700}
print(max(dic)) # 输出结果:赵信
- 1
- 2
- 当我们想输出年龄最大的value值,所对应的key时,最后输出的为“赵信”
- 这是由于我们没有给max方法指定对比的依据。
dic = {'盖伦':38,'嘉文':37,'赵信':500,'拉克丝':22,'希瓦娜':700}
print(max(dic,key=lambda k:dic[k]))
# 输出结果: 希瓦娜
- 1
- 2
- 3
-
max函数的原理就是通过遍历获取值,从而进行对比,当没有设置key属性的时候,字典数据类默认就是对比最大的key,而不是value。
-
max函数每次迭代字典dic获取到的key,会传给匿名函数的
形参k,有了形参值之后执行dic[k],获取到该Key的value并返回,这个时候max函数就懂了,知道我们是想按照value值进行对比,比较出来谁最大
8.9.2 sorted函数
回顾:
-
在上面的章节中,我们提到了列表的sort和reverse方法,这两个方法都是排序相关的,并且是直接对原列表进行的操作,
而本章的sorted方法,是不会对原列表产生影响的。
-
sort函数有个参数key,可以指定排序的方式,如:
# sort方法 l = [1,-4,6,5,-9,-2] l.sort(key=abs) #按绝对值排序 print(l) #输出结果:[1, -2, -4, 5, 6, -9] l.sort(key=abs,reverse=True) #从大到小,默认为reverse=False表示从小到大 print(l) #[-9, 6, 5, -4, -2, 1] # reverse方法 li2 = [1,4,7,2,3,8,6] li2.reverse() print(li2) # [6, 8, 3, 2, 7, 4, 1]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
sorted方法
作用:
- 与sort一样,都是进行数值大小的正反向排序,
reverse=True时表示从大到小排列,默认为FALSE表示从小到大。
特点:
- sorted虽然不会对原列表产生影响,但是会在内存中再生成一个列表,用来存放排序后的数据,所以当列表很大的时候慎用。 (PS:啥都要慎重啊[doge])
结合lambda函数的使用:
-
按照用户表的年龄进行排序
dic = {'盖伦':38,'嘉文':37,'赵信':500,'拉克丝':22,'希瓦娜':700} print(sorted(dic,key=lambda k:dic[k])) # 从小到大 print(sorted(dic,key=lambda k:dic[k],reverse=True)) # 从大到小 # 输出结果:['拉克丝', '嘉文', '盖伦', '赵信', '希瓦娜'] # 输出结果:['希瓦娜', '赵信', '盖伦', '嘉文', '拉克丝']- 1
- 2
- 3
- 4
- 5
- 6
8.9.3 map函数
格式:
map(函数,可迭代对象)
- 1
代码示例:
将名称列表的字符串元素,全部加上前缀
lis = ['张三','李四','王五','马六','侯七'] res = map(lambda name:'法内狂徒-'+name,lis) # 返回的是生成器 print(next(res)) # 输出结果: 法内狂徒-张三 print(next(res)) # 输出结果: 法内狂徒-李四 print(next(res)) # 输出结果: 法内狂徒-王五 print(next(res)) # 输出结果: 法内狂徒-马六
- 1
- 2
- 3
- 4
- 5
- 6
- 7
map函数,会迭代取出可迭代对象lis的值,随后将值给到lambda匿名函数的参数name,最后返回值做处理。
8.9.4 filter函数
格式:
filter(函数,可迭代对象)
- 1
作用:
- 将可迭代对象的值,迭代取出,随后运行函数,将函数的返回值作为筛选依据进行筛选。
代码示例:
将名称列表中,含有四的去掉
lis = ['张三','李四','王五','马六','侯七'] res = filter(lambda name:'四' not in name ,lis) # 返回值也是生成器 new_lis = [i for i in res] print(new_lis) # 输成结果:['张三', '王五', '马六', '侯七']
- 1
- 2
- 3
- 4
- 5
- 6
list列表的数据被迭代取出并赋值给lambda匿名函数的name形参,然后执行匿名函数的代码体,判断字符串"四"是否在当前name中,如果不在那么就通过,如果在就丢弃。于是新的列表new_lis里面的所有人名,就都没有带“四”。
8.9.5 print函数
print()函数
-
作用:打印输出
-
格式:
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) 1. file: 默认是输出到控制台/屏幕,如果设置为文件句柄,输出到文件 2. sep: 打印多个值之间的分隔符,默认为空格 3. end: 每一次打印的结尾,默认为换行符 4. flush: 立即把内容输出到流文件,不作缓存 #flush可以理解为外卖配送,有缓存就是说骑手有两单都是同一个商家的,然后骑手等商家两份都做好了之后一起拿走配送。 #无缓存就是说,商家给一份,骑手就拿去送一份,另外一份等商家做好了再回来拿。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
代码示例:
末尾不换行
print('我是卖报的小行家',end='') print('我是卖报的小行家',end='') # 输出结果: 我是卖报的小行家我是卖报的小行家
- 1
- 2
- 3
将连续打印默认的空格,改成“|”符号
print(1,2,3,4,5,sep='|') # 输出结果: 1|2|3|4|5
- 1
- 2
将print打印输出的内容,展示在文件中(默认是控制台)
f = open('a.txt','w',encoding='UTF-8') print('print的新知识',file=f) f.close()
- 1
- 2
- 3
更多转义符的使用
-
\r,将光标移到一行的开始处(覆盖)
print('我要被覆盖掉了','\r被我覆盖掉了呢') # 输出结果: 被我覆盖掉了呢- 1
- 2
-
\n,换行
print('1\n2') # 输出结果: # 1 # 2- 1
- 2
- 3
- 4
-
\t,制表符,一个tab的距离(4个空格)
print('1\t2') # 输出结果:1 2- 1
- 2
-
r,字符串前面字母“r”表示后面字符串中不进行转义
print(r'1\n2') # 输出结果: 1\n2- 1
- 2
案例:利用print实现打印进度条
import time
for i in range(0,101,2):
time.sleep(0.1)
num = i // 2
print( '\r{}%:{}\n'.format(i,'*'*num) if i == 100 else '\r{}%:{}'.format(i,'*'*num),end='') #不加这个end=''会自动换行,那么\r就没用了
- 1
- 2
- 3
- 4
- 5
8.9.6 数学运算
求绝对值
-
函数: abs(int)
print(abs(-4)) # 输出结果: 4- 1
- 2
取余运算
-
函数: divmod(int1,int2)
print(divmod(9,5)) # 输出结果:(1, 4) 商为1,余数为4- 1
- 2
精确到小数点后几位
-
函数: round(float)
print(round(3.141592653579,5)) # 输出结果:3.14159- 1
- 2
幂运算
-
函数: pow(int1,int2,int3)
- int1和int2进行幂运算,int3为需要进行的取余运算
print(pow(2,3)) # 2的3次方 # 输出结果: 8 print(pow(4,3,5)) #4的3次方,然后在对5取余 # 输出结果: 4- 1
- 2
- 3
- 4
求和运算
-
函数: sum(iterator,初始值)
ret = sum([1,2,3,4,5,6],10) #初始值10,依次迭代出元素进行相加 print(ret) # 输出结果: 31- 1
- 2
- 3
8.9.7 其他内置函数
dir()与help()方法
-
作用:查看一个变量拥有的方法,help查看详细信息。
print(dir(int)) #查看数字可用的方法 print(dir(list)) #查看列表可用的方法 print(help(str)) #查看详细信息- 1
- 2
- 3
- 4
callable()方法
-
作用:检验函数是否可用,返回值为Bool
print(callable(print)) #True print(callable(len)) #True- 1
- 2
readable()和writable()方法
-
作用:检查一个文件是否可读,是否可写
f = open('a.txt') print(f.writable()) #False print(f.readable()) #True- 1
- 2
- 3
format()方法
-
作用:输出符合长度和对齐方式的字符串
print(format('test','<20')) #向左对齐,长度20,不够的填充 print(format('test','>20')) #向右对齐,长度20,不够的填充 print(format('test','^20')) #居中对齐,长度20,不够的填充 # 输出结果: #test # test # test- 1
- 2
- 3
- 4
- 5
- 6
- 7
bytes()方法
-
作用: 将unicode转换成指定编码的二进制字节码(bytes数据类型)
print(bytes('你好',encoding='GBK')) # unicode转换成GBK的bytes print(bytes('你好',encoding='utf-8')) #unicode转换成utf-8的bytes # 输出结果: # b'\xc4\xe3\xba\xc3' # b'\xe4\xbd\xa0\xe5\xa5\xbd'- 1
- 2
- 3
- 4
- 5
ord()方法
-
作用: 查看字符串的ASCII码的十进制是多少
print(ord('A')) # 输出结果:65- 1
- 2
chr()方法
-
作用: 将ASCII码十进制,转换成字符
print(chr(65)) # 输出结果:A- 1
- 2
repr方法
-
作用: 原封不动的将数据类型输出
x = '牛X' print('你真%r'%x) #%r,其实调用的就是repr,会把字符串本身带的引号也进行输出 # 输出结果:你真'牛X' print('你真%s'%x) # 输出结果:你真牛X- 1
- 2
- 3
- 4
- 5
- 6
all()与ang()方法
-
作用: 判断一个可迭代对象的元素是否全为真等。
- all,为全为真即为真
- any,为只要有一个为真就为真
print(all([1,'1','',])) # ''为False # 输出结果: False print(any([' ','',])) # ' ' 为True,因为起码还有个空格。 # 输出结果: True- 1
- 2
- 3
- 4
- 5
zip()拉链方法
-
作用:可将多个iterator,以最短的为基准,进行纵向截取,并以元祖的形式存储
L1 = [1,2,3,4,5,6,7] L2 = ['11','22','33'] L3 = ('111',['222','333'],'666') L4 = {'time':'2021/5/24','addr':'上海'} ret = zip(L1,L2,L3,L4) #返回为迭代器 for i in ret: print(i) # 输出结果: # (1, '11', '111', 'time') # (2, '22', ['222', '333'], 'addr')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
8.10 补充:高阶函数
什么是高阶函数:
- 1、一个函数的函数名作为参数传给另外一个函数。
- 2、一个函数返回值(return)为另外一个函数(返回为自己,则为递归)。
所以,上面介绍的map、filter、sorted等方法,都是高阶函数。
九、模块
什么是模块:
- 模块就是一个功能的集合体,导入之后,就可以使用内部的一些方法,例如前面一直使用的time模块。
- 在Python中,一个py文件就是一个模块,文件名为xxx.py模块名则是xxx。
- 将程序模块化会使得程序的组织结构清晰,维护起来更加方便,且可以重复使用。
- 另外除了自定义模块外,我们还可以导入使用内置或第三方模块提供的现成功能,这种“拿来主义”极大地提高了程序员的开发效率。
模块的分类:
- 内置模块,python解释器自带的。
- 第三方模块,别人写的。
- 自定义模块,自己写的。
如何导入模块
关键字:
import
import md # 也可以利用as,起别名 import md as m # 相当于把md的内存地址给了m
- 1
- 2
- 3
md.py为文件名,但是导入时import后面跟的模块名,不能带.py的后缀。
from…import…在9.1章节
导入模块会发生的事情
模块文件: md.py
print('欢迎使用md模块') x = 'md中的x' def get(): print(x)
- 1
- 2
- 3
- 4
- 5
- 6
主代码文件: test.py
import md # 输出结果: 欢迎使用md模块
- 1
- 2
- 3
所以,导入模块会:
- 执行模块文件。
- 产生md.py的名称空间,将md.py运行过程中产生的名字都存放到md的名称空间中。
- 在test.py文件中,会产生一个新名字md,该名字指向md.py的名称空间。
import md
x = 'test.py中的x'
md.get()
# 输出结果:
# 欢迎使用md模块
# md中的x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
md模块下的get函数所输出的x,以定义阶段为准,不管在test.py文件中怎么改,都影响不到,因为不在一个名称空间。
模块的一些规范
- 命名时,最好采用纯小写+下划线的风格。
- 导入时,最好先导入内置模块,再导入第三方模块,最后再导入自定义模块。
了解性知识点:
-
每个python文件都会有一个内置方法__name__
print(__name__) # 输出结果: __main__- 1
- 2
-
也就是说,当__name__ = __main__时,说明文件被运行。
-
有了它,我们可以进行if判断,当文件被执行时,执行那些代码,当文件被当做模块导入时,执行那些代码。
if __name__ == '__main__': print('文件被执行') else: print('文件已被导入')- 1
- 2
- 3
- 4
9.1 from…import
格式:
-
from 模块名 import 模块文件中的属性 from 模块名 import 模块文件中的属性 as 别名 # 起别名 # 如: from md import get # 导入md模块中的get属性或方法。- 1
- 2
- 3
- 4
与直接import的区别:
- 相比直接import来说,from…import会更精简,因为不需要写前缀。
- from…import在导入模块下属性的时候,会在本地的名称空间中声明,随后将内存地址指向模块文件对应的内存地址。
- 而直接import则是在本地名称空间里声明一个模块名,指向的是模块的内存空间,所有方法和属性都通过模块名+“.”的方式调用。
导入模块中所有的属性
from 模块名 import *
- 1
了解:
为什么from 模块名 import *,靠一个“ * ”号就能获取到所有?
答:因为每个Python文件中,都会有一个__all__属性,值为列表,该列表下存的有所有名称空间的名字,而“ * ”号就是从这里进行获取的。
9.2 模块查找
模块的查找:
- 先从内存中找。
- 再从硬盘中找。
从硬盘中找,会先从当前执行文件的路径进行查找,然后按照设置,在默认的路径下挨个找。
事实上,如果当前执行文件的文件夹中,并没有该模块,那么就需要将模块存放的路径,添加到模块的硬盘查找路径中,这样就能查到了
# 查看已经加载到内存中的模块 print(sys.modules) # 查看模块在硬盘中的查找顺序 print(sys.path)
- 1
- 2
- 3
- 4
- 5
代码示例:
import sys sys.path.append(r'模块文件夹路径') import md md.hello()
- 1
- 2
- 3
- 4
- 5
十、包
什么是包:
- 包的本质就是模块的一种形式,包是用来被当做模块导入的。
- 包,就是一个包含有__init__.py文件的文件夹
导入包之后进行的三件事:
- 产生一个名称空间
- 运行包下的__init__.py文件,将运行过程中产生的名字都丢到对应模块的名称空间中。
- 在当前执行文件的名称空间中,拿到包,以及包指向模块的名称空间
代码示例:
包文件夹下的模块文件
# 文件名model_1.py def demo(): print('hello world')
- 1
- 2
- 3
包文件夹下的__init__.py文件
# 格式: from 包名.模块名 import 属性 from model.model_1 import demo
- 1
- 2
- 3
- 4
- 5
使用者(调用包的py文件)
# 导入包 import model # 执行包文件夹下的init文件,该文件导入了包内的模块文件。 model.demo() # 输出结果:hello world
- 1
- 2
- 3
- 4
- 5
十一、常用模块–后续完善
本章节将详细介绍python中常用的一些内置模块
2022/12/4 更新了一些写错,以及上传CSDN造成的格式/排版/错别字等错误。
2022/11/8 这一章节懒得写了…
2022/9/3 补充了os
11.1 time、datetime模块
在Python中,通常有这几种方式来表示时间:
- 时间戳(Timestamp)
- 格式化时间的字符串(Format String)
- 元祖(Struct_time结构化时间)
UTC:
- 即格林威治天文时间,世界标准时间。在中国为UTC+8。
DST:
- Daylight Saving Time,即夏令时
时间戳:
- 表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。
元组(struct_time):
struct_time元组共有9个元素,返回struct_time的函数主要有gmtime(),localtime(),strptime()。下面列出这种方式元组中的几个元素:
索引(Index) 属性(Attribute) 值(Values) 0 tm_year(年) 比如2011 1 tm_mon(月) 1 - 12 2 tm_mday(日) 1 - 31 3 tm_hour(时) 0 - 23 4 tm_min(分) 0 - 59 5 tm_sec(秒) 0 - 61 6 tm_wday(weekday) 0 - 6(0表示周一) 7 tm_yday(一年中的第几天) 1 - 366 8 tm_isdst(是否是夏令时) 默认为-1
localtime()方法
-
作用:将时间戳,转换成当前时区的struct_time(元组)
-
格式:
time.localtime([时间戳]) # 时间戳为可选参数,当无参数时,则以当前时间为准。- 1
- 2
-
代码示例:
print(time.localtime(1661502020.588591)) # 输出结果: time.struct_time(tm_year=2022, tm_mon=8, tm_mday=26, tm_hour=16, tm_min=20, tm_sec=20, tm_wday=4, tm_yday=238, tm_isdst=0)- 1
- 2
可根据上图表格,可以分析出具体的年月日时分秒等。
gmtime()方法
-
作用:与localtime()方法类似,只不过转的时区不一样。
将时间戳,转换成UTC时区(0时区)的struct_time(元组)- 1
-
格式:
time.gmtime([时间戳]) # 时间戳为可选参数,当无参数时,则以当前时间为准。- 1
- 2
-
代码示例:
print(time.gmtime(1661502020.588591)) # 输出结果: time.struct_time(tm_year=2022, tm_mon=8, tm_mday=26, tm_hour=8, tm_min=20, tm_sec=20, tm_wday=4, tm_yday=238, tm_isdst=0)- 1
- 2
time()方法
-
作用: 返回当前时间的时间戳。
-
格式:
time.time()- 1
-
代码示例:
print(time.time()) # 输出结果: 1661502611.5685425- 1
- 2
mktime()方法
-
作用: 将一个struct_time(元组)转化为时间戳
-
格式:
time.mktime(struct_time)- 1
-
代码示例:
struct_time = time.localtime(time.time()) print(time.mktime(struct_time)) # 输出结果: 1661510528.0- 1
- 2
- 3
asctime()方法
-
作用: 将一个struct_time(元组)转化为这种格式 “Fri Aug 26 18:43:22 2022”。
-
格式:
time.asctime(struct_time)- 1
-
代码示例:
struct_time = time.localtime() print(time.asctime(struct_time)) # 输出结果: Fri Aug 26 18:43:22 2022- 1
- 2
- 3
ctime()方法
-
作用: 与asctime类似,不过ctime是将一个时间戳(float)转成这种格式 “Fri Aug 26 18:43:22 2022”。
-
格式:
time.ctime([float]) # 时间戳为可选参数,不写默认将当前时间- 1
- 2
-
代码示例:
time_float = time.time() print(time.ctime(time_float)) # 输出结果:Fri Aug 26 18:47:39 2022- 1
- 2
- 3
strftime()方法
-
作用:用于将一个代表时间的元组或者struct_time转化为格式化的时间字符串。
-
格式:
time.strftime(自定义格式化格式,[struct_time]) # struct_time为选填参数,默认为time.localtime(),time.localtime()为当前结构化时间(元组) # 格式化的格式见下表:- 1
- 2
- 3
格式 含义 %a 本地(locale)简化星期名称 %A 本地完整星期名称 %b 本地简化月份名称 %B 本地完整月份名称 %c 本地相应的日期和时间表示 %d 一个月中的第几天(01 - 31) %H 一天中的第几个小时(24小时制,00 - 23) %I 第几个小时(12小时制,01 - 12) %j 一年中的第几天(001 - 366) %m 月份(01 - 12) %M 分钟数(00 - 59) %p 本地am或者pm的相应符 %S 秒(01 - 61) %U 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 %w 一个星期中的第几天(0 - 6,0是星期天) %W 和%U基本相同,不同的是%W以星期一为一个星期的开始。 %x 本地相应日期 %X 本地相应时间 %y 去掉世纪的年份(00 - 99) %Y 完整的年份 %Z 时区的名字(如果不存在为空字符) %% ‘%’字符 -
代码示例:
print(time.strftime("%Y-%m-%d %X",time.localtime())) # 输出结果: 2022-08-26 18:58:27- 1
- 2
datetime模块
import time import datetime # 返回当前时间 print(datetime.datetime.now()) # 输出结果:2022-08-26 19:01:31.120960 # 将时间戳转成常见的日期格式 print(datetime.date.fromtimestamp(time.time()) ) # 输出结果: 2022-08-26 # 输出当前时间+3天的时间 print(datetime.datetime.now() + datetime.timedelta(3)) # 输出结果:2022-08-29 19:01:31.120960 # 输出当前时间-3天的时间 print(datetime.datetime.now() + datetime.timedelta(-3)) # 输出结果:2022-08-23 19:01:31.120960 # 输出当前时间+3小时的时间 print(datetime.datetime.now() + datetime.timedelta(hours=3)) # 输出结果:2022-08-26 22:01:31.120960 # 输出当前时间-30分钟的时间 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) # 输出结果:2022-08-26 19:31:31.120960
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
11.2 random模块
随机数模块
import random # 返回大于0且小于1之间的小数 print(random.random()) # 输出结果:0.3722108273806498 # 返回大于等于1且小于等于3之间的整数 print(random.randint(1,3)) # 输出结果:3 # 返回大于等于1且小于3之间的整数 print(random.randrange(1,3)) # 输出结果:1 # 返回1或者23或者[4,5] print(random.choice([1,'23',[4,5]])) # 输出结果:[4,5] # 返回列表元素任意2个组合 print(random.sample([1,'23',[4,5]],2)) # 输出结果:[1, [4, 5]] # 返回大于1小于3的小数 print(random.uniform(1,3)) # 输出结果:1.692226777770463 item=[1,3,5,7,9] random.shuffle(item) #打乱item的顺序,可以理解为"洗牌" print(item) # 输出结果:[1, 3, 7, 9, 5]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
11.3 os模块
汇总一览:
| 格式 | 作用 |
|---|---|
| os.getcwd() | 获取当前工作目录,即当前python脚本工作的目录路径 |
| os.chdir(“dirname”) | 改变当前脚本工作目录;相当于shell下cd |
| os.curdir | 返回当前目录: (‘.’) |
| os.pardir | 获取当前目录的父目录字符串名:(‘…’) |
| os.makedirs(‘dirname1/dirname2’) | 可生成多层递归目录 |
| os.removedirs(‘dirname1’) | 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 |
| os.mkdir(‘dirname’) | 生成单级目录;相当于shell中mkdir dirname |
| os.rmdir(‘dirname’) | 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname |
| os.listdir(‘dirname’) | 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 |
| os.remove() | 删除一个文件 |
| os.rename(“oldname”,“newname”) | 重命名文件/目录 |
| os.stat(‘path/filename’) | 获取文件/目录信息 |
| os.sep | 输出操作系统特定的路径分隔符,win下为"\“,Linux下为”/" |
| os.linesep | 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" |
| os.pathsep | 输出用于分割文件路径的字符串 win下为;,Linux下为: |
| os.name | 输出字符串指示当前使用平台。win->‘nt’; Linux->‘posix’ |
| os.system(“bash command”) | 运行shell命令,直接显示 |
| os.environ | 获取系统环境变量 |
| os.path.abspath(path) | 返回path规范化的绝对路径 |
| os.path.split(path) | 将path分割成目录和文件名二元组返回 |
| os.path.dirname(path) | 返回path的目录。其实就是os.path.split(path)的第一个元素 |
| os.path.basename(path) | 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 |
| os.path.exists(path) | 如果path存在,返回True;如果path不存在,返回False |
| os.path.isabs(path) | 如果path是绝对路径,返回True |
| os.path.isfile(path) | 如果path是一个存在的文件,返回True。否则返回False |
| os.path.isdir(path) | 如果path是一个存在的目录,则返回True。否则返回False |
| os.path.join(path1[, path2[, …]]) | 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 |
| os.path.getatime(path) | 返回path所指向的文件或者目录的最后存取时间 |
| os.path.getmtime(path) | 返回path所指向的文件或者目录的最后修改时间 |
| os.path.getsize(path) | 返回path的大小 |
11.x json模块
import json '''dumps与loads''' a = {'name':'liuyu','age':'18'} b = json.dumps(a) #dumps序列化,将结构数据(字典),转成string print(b,type(b)) # {"name": "liuyu", "age": "18"} <class 'str'> c = json.loads(b) #loads反序列化,将json数据(str),转成结构数据(字典) print(c,type(c)) # {'name': 'liuyu', 'age': '18'} <class 'dict'> '''dump与load''' f = open('json_test.txt','r+',encoding='utf-8') A = {'name':'liuyu','age':'18'} json.dump(A,f) #dump,将结构数据A,序列化成str,然后写入文件句柄f f.seek(0) print(f.read()) f.close() #{"name": "liuyu", "age": "18"} #该数据为json格式 f = open('json_test.txt','r+',encoding='utf-8') A = json.load(f) #将文件中的数据,反序列化为字典 print(A,type(A)) # {'name': 'liuyu', 'age': '18'} <class 'dict'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
后续完善…
后续完善…
十二、面向对象
12.1 初识
面向过程:
- 核心在于“过程”二字,过程即流程,指得是做事的步骤,先什么、在什么、最后什么。
- 基于该思想编写程序就好比在设计一条流水线。
- 优点:复杂的问题流程化,进而简单化。
- 缺点:扩展性非常差
面向对象:
- 核心是“对象”二字,对象就是将程序的数据与功能,进行“整合”。
- “类”用来存放同类“对象”共有的数据和功能。
- 面向对象这种编程思想扩展性非常好。
定义类
- 关键字class,后面跟上类名。
class Student: school = '中国地质大学(北京)' college = '信息工程学院'
- 1
- 2
- 3
实例化对象(通过类生成出对象)
stu_obj1 = Student()
- 1
对象拥有类中共有的属性和方法
print(stu_obj1.school) # 输出结果:中国地质大学(北京)
- 1
- 2
对象自己私有的属性,可以通过直接赋值的形式添加
stu_obj1.name = 'liuyu' print(stu_obj1.name) # 输出结果:liuyu
- 1
- 2
- 3
12.1.1 补充
查看类里面的名称空间(字典格式)
或者说是查看类或对象中的属性
类名.__dict__
- 1
既然是字典格式,那么查看属性就可以中括号[]+key,就可以查询到value了
类名.__dict__[属性]
- 1
python提倡的简洁优美,这样查看对象的属性就有点违背初衷了,所有提供了一个简单的方法:
类名.属性 #本质上就是__dict__只不过用这种更方便
- 1
所以在上述案例中,可以直接print(stu_obj1.school),来输出获取到的信息。
'''
通过类调用方法与通过对象调用类中的方法,内存地址是不一样的。
通过对象调用类中方法时,会把自己当做第一个参数传入进去,这是为什么类中定义函数,都会自带一个参数叫self
所以如果形参没有self,那么通过对象调用时,会报错。
'''
print(id(Student.school)) # 2284401763952
print(id(stu_obj1.school)) # 2284352937856
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
12.2 __init__方法
有了类,我们可以创建出很多对象,现在有Student类,要生成张三对象,李四对象,王五对象。
这三个对象呢可以访问类中的属性和方法,如school属性和college属性,但是作为一个学生对象,没有姓名、年龄、性别等,显然是不合理的。
但是,如果我们每个对象都挨个添加属性,这就又造成了代码冗余(属性名一样的,只是值不一样),而python中,有可以帮我们初始化的方法。
__init__方法
- 该方法在类调用阶段执行,用于实例化对象时,接收对象独有的属性,完成初始化。
class Student: # self为对象本身,self.属性,就是在给对象添加属性或方法。 def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex school = '中国地质大学(北京)' college = '信息工程学院' def get_msg(self): print(f'学生信息如下:姓名{self.name},年龄{self.age},毕业于{self.school}{self.college}') zhangsan_obj = Student('张三',19,'不详') zhangsan_obj.get_msg() # 输出结果:学生信息如下:姓名张三,年龄19,毕业于中国地质大学(北京)信息工程学院 lisi_obj = Student('李四',18,'女') lisi_obj.get_msg() # 输出结果:学生信息如下:姓名李四,年龄18,毕业于中国地质大学(北京)信息工程学院 wangwu_obj = Student('王五',20,'男') wangwu_obj.get_msg() # 输出结果:学生信息如下:姓名王五,年龄20,毕业于中国地质大学(北京)信息工程学院
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
12.3 小案例
创建学校类、学院类、专业类,彼此之间进行绑定,最终要实现的效果:
- 学校类可以查看所有的学院,可以查看开设的所有专业。
- 学院类可以查看每个院开设的专业。
代码示例:
class School: def __init__(self,school_name,school_addr): self.school_name = school_name self.school_addr = school_addr self.college_list = [] #[college_obj1,college_obj2,....] # 给学校添加学院(将学校与学院进行绑定) # 调用该方法,将学院对象传入,并存入学院信息列表中,后续通过学院对象获取学院相关的信息。 def related_college(self,college_obj): self.college_list.append(college_obj) # 查看学校下的所有学院名称 def get_all_college(self): print(f'{self.school_name}:学院列表'.center(40,'=')) for college_obj in self.college_list: print(college_obj.college_name) # 通过学校对象,查询到学院的专业信息 def get_college_of_subject(self): for college_obj in self.college_list: college_obj.get_all_subject() class College: def __init__(self,college_name): self.college_name = college_name self.subject_list = [] #[subject_obj1,subject_obj2,....] # 给学院添加专业(将学院与专业信息,进行绑定) def related_subject(self,subject_obj): self.subject_list.append(subject_obj) # 查看学院所有专业 def get_all_subject(self): print(f'{self.college_name}所开设的专业如下:'.center(40,'=')) for subject_obj in self.subject_list: print(f'\t{subject_obj.subject_name}') class Subject: def __init__(self,subject_name): self.subject_name = subject_name
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
创建类,先把完成共有的属性和方法,再对独有的属性进行初始化。
例如:
- 学校类要有名称和地址,还有学院列表,默认为空,需要后续添加。
- 学院类要名称,要有开设的专业,需要有查询到一个学院内总共开设的有多少专业等。
- 两类之间做关联绑定,无外乎就是将对象传入,有了对象之后,就可以调用对象的所有属性和方法。
调用类生成对象,并进行绑定:
- 为了不被混淆,便于理解,本案例中的变量名将采用中文的方式
# 创建两所大学对象 中国地质大学 = School('中国地质大学(北京)','海淀区学院路29号') 清华大学 = School('清华大学','海淀区双清路30号') # 分别给两所大学创建学院 地大_信息工程学院 = College('信息工程学院') 地大_经济管理学院 = College('经济管理学院') 清华_信息科学技术学院 = College('信息科学技术学院') 清华_机械工程学院 = College('机械工程学院') # 将大学与学院进行关联 中国地质大学.related_college(地大_信息工程学院) 中国地质大学.related_college(地大_经济管理学院) 清华大学.related_college(清华_信息科学技术学院) 清华大学.related_college(清华_机械工程学院) # 创建专业 地大_计算机科学与技术 = Subject('计算机科学与技术') 地大_软件工程 = Subject('软件工程') 地大_电子信息工程 = Subject('电子信息工程') 地大_经济学 = Subject('经济学') 地大_信息管理与信息系统 = Subject('信息管理与信息系统') 地大_工商管理 = Subject('工商管理') 清华_计算机科学与技术系 = Subject('计算机科学与技术系') 清华_自动化系 = Subject('自动化系') 清华_电子工程系 = Subject('电子工程系') 清华_精密仪器系 = Subject('精密仪器系') 清华_机械工程系 = Subject('机械工程系') 清华_工业工程系 = Subject('工业工程系') # 学院与开设的专业,进行绑定 地大_信息工程学院.related_subject(地大_计算机科学与技术) 地大_信息工程学院.related_subject(地大_软件工程) 地大_信息工程学院.related_subject(地大_电子信息工程) 地大_经济管理学院.related_subject(地大_经济学) 地大_经济管理学院.related_subject(地大_信息管理与信息系统) 地大_经济管理学院.related_subject(地大_工商管理) 清华_信息科学技术学院.related_subject(清华_计算机科学与技术系) 清华_信息科学技术学院.related_subject(清华_自动化系) 清华_信息科学技术学院.related_subject(清华_电子工程系) 清华_机械工程学院.related_subject(清华_精密仪器系) 清华_机械工程学院.related_subject(清华_机械工程系) 清华_机械工程学院.related_subject(清华_工业工程系)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
调用测试:
# 通过学校对象,查询学院 中国地质大学.get_all_college() 清华大学.get_all_college() '''输出结果 ============中国地质大学(北京):学院列表============= 信息工程学院 经济管理学院 ===============清华大学:学院列表================ 信息科学技术学院 机械工程学院 ''' # 通过学院查询对应开设的专业 地大_经济管理学院.get_all_subject() 清华_信息科学技术学院.get_all_subject() 清华_机械工程学院.get_all_subject() '''输出结果 ============经济管理学院所开设的专业如下:============= 经济学 信息管理与信息系统 工商管理 ===========信息科学技术学院所开设的专业如下:============ 计算机科学与技术系 自动化系 电子工程系 ============机械工程学院所开设的专业如下:============= 精密仪器系 机械工程系 工业工程系 ''' # 通过学校对象,查询本校所有的专业 中国地质大学.get_college_of_subject() 清华大学.get_college_of_subject() '''输出结果 ============信息工程学院所开设的专业如下:============= 计算机科学与技术 软件工程 电子信息工程 ============经济管理学院所开设的专业如下:============= 经济学 信息管理与信息系统 工商管理 ===========信息科学技术学院所开设的专业如下:============ 计算机科学与技术系 自动化系 电子工程系 ============机械工程学院所开设的专业如下:============= 精密仪器系 机械工程系 工业工程系 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
面向对象,在设计的时候,会比较复杂,但是使用起来会很方便。
12.4 魔术方法
在12.2中,我们使用 __init__ 可以完成对象独有属性的初始化,除了 __init__ 之外,还有其他的:
__str__打印对象时,触发函数体内的代码。__repr__打印对象时,触发函数体内的代码。__call__当对象加括号执行时,触发函数体内的代码。
代码示例:
''' __init__ 调用类时执行 ''' class Student(): def __init__(self,name,age,school): # 实例化对象(赋予对象独有的数据) self.name = name self.age = age self.school = school def stu_info(self): res = f'姓名:{self.name } 年龄:{self.age} 学校:{self.school}' return res stu_obj1 = Student('张三','28','漂亮国新泽西州哥谭市悍匪职业技术学院') print(stu_obj1.stu_info()) # 输出结果: 姓名:张三 年龄:28 学校:漂亮国新泽西州哥谭市悍匪职业技术学院 ''' __repr__与__str__,打印对象时执行 __call__执行对象时,执行 调用类时执行 ''' class Test: def __init__(self,name,age): self.name = name self.age = age def __repr__(self): return f'姓名:{self.name},年龄:{self.age}' def __call__(self, name): print(f'{name}是我的一生之敌') obj = Test('张三','27') # 实例化对象,执行__init__ print(obj) # 打印对象,执行__repr__ obj('罗翔') # 运行对象,执行__call__ # 输出结果: # 姓名:张三,年龄:27 # 罗翔是我的一生之敌
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
12.5 隐藏属性
格式:
- 属性名前加
__ - 类中所有双下滑线开头的属性都会在类定义阶段、检测语法时,自动变成“_类名__属性名”的形式:
class Test(): __x = 1 # 变形为 _Test__x def __f1(self): print('111') def get_x(self): return self.__x # 隐藏属性语法在内部是可以访问的。 ''' 直接访问会失败,因为__双下划线,使语法发生了变形 ''' obj = Test() print(obj.x) # 报错:AttributeError: 'Test' object has no attribute 'x' print(obj.get_x()) # 输出结果: 1 ''' 但,即时是隐藏了,还是可以通过其他途径访问的 因为__x = 1,相当于变形成了 _Test__x ''' print(obj._Test__x) # 输出结果: 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
好处:
- 隐藏属性值,不直接提供给使用者,但是开发者可以通过接口的形式,间接的将数据提供给使用者,另外还可以加些判断。
- 隐藏函数,降低复杂度,通过隐藏函数,使其不用关心内部是如何实现的。
12.6 property装饰器
什么是property,如何使用?
- property是一个装饰器,是用来绑定给对象的方法伪造成一个数据对象。
- 例如:Student类中有一个计算当前年龄的方法age,那么对于age来说,站在用户的角度上看,它更应该是一个数据,而不是一个方法,所以property就是将一个方法,伪装成数据,调用时不加括号。
代码示例:
import time class Student: def __init__(self,name,birth_year): self.name = name self.birth_year = birth_year @property def age(self): ''' 获取当前时间 将当前年月日,转换成数字类型,后续用来计算。 ''' current_time = time.strftime("%Y-%m-%d", time.localtime()) c_year, c_month, c_date = current_time.split('-') c_year, c_month, c_date = int(c_year), int(c_month), int(c_date) ''' 获取对象的出生年月日,并转换成int类型。 ''' year, month, date = self.birth_year.split('-') year, month, date = int(year), int(month), int(date) # 计算年龄 if (c_date - date) < 0: c_month = c_month - 1 if (c_month - month) < 0: c_year = c_year - 1 if c_year - year < 0: return '输入的出生年月份异常' elif 0< c_year - year < 1: return 1 else: return c_year - year liuyu_obj = Student('刘煜','2000-7-19') print(liuyu_obj.age) # 不需要加括号,将函数伪装成数据。 # 输出结果:22
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
12.7 继承
什么是继承:
- 继承,是一种创建新类的方式,新建的类可称为子类或派生类,父类又可称为基类或超类,子类会继承父类的所有属性和方法,用于解决一些代码冗余的问题。
- 在python中,支持多继承,新建的类可以继承一个或多个父类,但多继承会造成可读性、扩展性变差,不建议使用,如果非要使用的话,应该使用Mixins机制。
在python2中,有经典类和新式类只分。
- 经典类:没有继承object类的子类,以及该子类的子类…子子类…,都叫做经典类。
- 新式类:继承了object类的子类,以及该子类的子类…子子类…,都叫做新式类。
- object类为内置的类,用于丰富一些功能。
在python3中,所有的类都是新式类。
如何使用继承:
class Father1:
x = 10
class Father2:
y = 20
class Son(Father1,Father2): # 多继承
pass
'''
使用继承Father1类中的x属性,以及Father2类中的y属性
'''
print(Son.x,Son.y)
# 输出结果: 10 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
如何查看一个子类所继承的所有父类
-
类名.__bases__- 1
print(Son.__bases__) # 输出结果: (<class '__main__.Father1'>, <class '__main__.Father2'>)- 1
- 2
继承的应用:
class School_people: def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex class Student(School_people): def __init__(self,name,age,sex,student_id): # 调用父类的init,完成对共有属性的初始化。 School_people.__init__(self,name,age,sex) self.student_id = student_id class Teacher(School_people): def __init__(self,name,age,sex,job,): School_people.__init__(self,name,age,sex) self.job = job teacher1 = Teacher('李某某',28,'女','辅导员') print(teacher1.__dict__) # 输出结果: {'name': '李某某', 'age': 28, 'sex': '女', 'job': '辅导员'} student1 = Student('张三',28,'男',202003557) print(student1.__dict__) # 输出结果: {'name': '张三', 'age': 28, 'sex': '男', 'student_id': 202003557}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- Student类与Teacher类中,出现的冗余代码,那就是name,age,sex属性,所以我们可以把这些属性剥离出来,随后让Student类与Teacher类继承。
- 新建一个类,叫做School_people校内人员类,不管是学生还是老师,都是这个范畴的,所以将name,age,sex属性放在这个父类中,合情合理。
- 在通过Teacher类实例化对象时,首先调用自己下面的init方法,接收参数,随后调用父类中的init方法,将共用的属性完成初始化,但要注意,调用父类的init方法时,一定要传入self,这个self代表我们实例化的那个老师空对象,这样后续调用父类中的init方法时,属性是绑定在这个老师对象中的。
- 在通过Student类实例化对象时,过程和上面一样,自己init下面都是私有的属性,共有的属性需要在父类完成初始化,注意调用父类的init时,一定要传入self。
12.7.1 单继承的属性查找
单继承背景下的属性查找:
class Test1: def f1(self): print('Test1.f1') def f2(self): print('Test.f2') self.f1() class Bar(Test1): def f1(self): print('Bar.f1') obj = Bar() obj.f2() # 输出结果: # Test.f2 # Bar.f1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
查找顺序:
-
Bar类实例化出来的对象obj,调用f2函数,确认自身类中有没有该方法。
-
没有就去父类Test1中进行查找,找到后运行并打印“Test.f2”
-
但是父类的f2函数中,还调用了f1函数,由于是obj调用的f2方法,所以此时的self为obj
obj.f1(),那自然就去从自己那边进行查找。
以上述案例代码为主,如果就是想最后调用的是Test1类中的f1方法,该怎么办
一、方案1:
class Test1: def f1(self): # 2. self为obj print('Test1.f1') # 3.self.f1() = obj.f1() self.f1() def f2(self): print('Test.f2') # 1.指名道姓的调用Test1下的f1方法 #但这里的self,依然是obj,因为f2方法是Obj对象调用的,将自己传给形参self了。 Test1.f1(self) class Bar(Test1): # 4.执行 def f1(self): print('Bar.f1') obj = Bar() obj.f2() '''输出结果: Test.f2 Test1.f1 Bar.f1 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
二、方案2:
class Test1: def __f1(self): # 2. self为obj print('Test1.f1') # 3.self.f1() = obj.f1() self.f1() def f2(self): print('Test.f2') self.__f1() # 变相的“指名道姓” # __f1()变形为 _Test1__f1() class Bar(Test1): # 4.执行 def f1(self): print('Bar.f1') obj = Bar() obj.f2() '''输出结果: Test.f2 Test1.f1 Bar.f1 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
12.7.2 多继承的属性查找
菱形问题:
-
指的是一个类A,继承了B和C,而BC又同时继承了D,因绕起来是个菱形,所以称做“菱形问题”。
-
那么到底会带来什么问题呢?
在python多继承中,新式类与经典类在菱形继承和非菱形继承中,属性查找的顺序是不一样的。
-
下图为菱形继承示例:
如果多继承是在非菱形继承的情况下:
- 经典类与新式类的属性查找顺序一样,都是一个分支一个分支的找下去,然后最后找object。
如果多继承是菱形继承:
- 经典类:深度优先,会在检索第一条分支的时候,直接一条道走到黑,会一直检索到菱形的“头部”,也就是多个类的共同继承类。
- 新式类:会先检索所有小分支之后,最后再检索菱形的“头部”
总结:
- 由于现在python2已经很少在用了,都是python3了,而python3创建的类,默认继承object类,所以就是新式类。
- 而新式类在面对菱形和非菱形时,属性查找顺序都是最后再查**“菱形头部”或者object**。
MRO列表
-
python通过C3线性算法来实现MRO列表,该列表就存放了属性的查找顺序。
-
格式:
类名.mro()- 1
-
代码示例:
''' 菱形继承 ''' class D: pass class C(D): pass class B(D): pass class A(B,C): pass print(A.mro()) # 输出结果: [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
可以发现,先找自己,自己没有了再找B,然后就不再往下找D,而是掉头去找C,C要是还没有该属性,最后才找D,因为D为新式类,默认继承了Object类,所以当D也没有时,会再找object。符合新式类在菱形继承下的属性查找。
注意:
- 如:class B(A,D) 和 class C(D,A),这两个的属性查找顺序是不一样的。
- 多继承时,父类的排序,会影响到属性查找。
12.7.3 Mixin
在其他语言中,并没有多继承的概念,子类在继承父类时都是一对一的,很明确的表达式什么是什么,如四轮车类继承了交通工具类,那么四轮车就是交通工具,逻辑很清晰。
在python中,支持多继承,新建的类可以继承一个或多个父类,但多继承会造成可读性、扩展性变差,如:直升机继承了飞行器类、交通工具类、旋翼类…,不能明确的表达什么是什么,扩展和阅读都不方便。
Mixin:
-
我个人的理解其实就是一些约定俗称,将一些功能性的类,末尾跟上Mixin,这样后续查看源码时,就知道了这个类只是添加一些功能的。如:
class A: pass class BMixin: pass class C(BMixin,A): pass- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
由上图可得,直升机这个类,既继承了交通工具类又继承了飞行器类Mixin。
- 交通工具类:里面存放着公用的属性和方法。
- 飞行器类Mixin,该类用于提取出民航飞机类和直升机类的一些特征,整合为一个类,该类只用来存放飞行相关的属性和方法。
- 为了以后方便阅读源码,将飞行器类改为飞行器类Mixin,这样只要涉及到飞行相关的功能,直接找飞行器类Mixin,就不需要再去找交通工具类了。
12.7.4 调用父类中的方法
在12.7章节中,案例代码的实现就是调用父类的init方法,来完成共有属性的初始化
12.7章节中代码:
class School_people: def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex class Student(School_people): def __init__(self,name,age,sex,student_id): School_people.__init__(self,name,age,sex) self.student_id = student_id class Teacher(School_people): def __init__(self,name,age,sex,job,): School_people.__init__(self,name,age,sex) self.job = job
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
python中,提供的有一个方法,可以帮助我们快捷的去调用父类中的方法,那就是super()
函数名:
super().父类属性或方法
- 1
作用:
- 参照MRO进行父类查找,随后调用父类中对应的属性或方法。
- MRO查找会首先从自己这边找,然后再按照父级查找顺序进行查找。但是,我们的super方法不会从自己这边找,直接就是父级,严格来说是属性的发起者的父级。
代码示例:
class D: def f1(self): return 'D中的f1' class A: def __init__(self,name,age): self.name = name self.age = age class B(A,D): def __init__(self,name,age,sex): super().__init__(name,age) self.sex = sex def f1(self): return '自己中的f1' def test(self): return super().f1() b_obj = B('zhangsan',27,'男') print(b_obj.__dict__) print(b_obj.test()) # 输出结果: # {'name': 'zhangsan', 'age': 27, 'sex': '男'} # D中的f1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
流程:
- 通过B类,实例化对象b_obj,执行B类中的__init__方法,形参接收传来的实参。
- super().__init__表示调用父类的__init__方法,按照MRO列表,会先找A类有没有,然后找D类,最后找object类。
- 所以调用的是A类中的__init__方法,A类中的需要三个参数,self、name、age,因为在python3中,super会自动化的将当前对象自身传入,所以super().__init__()只需要两个参数,即name、age。
- super().f1()同理,根据MRO表进行查找,A没有就找到D,执行D中的f1函数之后,将返回值接收,最后再次返回并打印输出。
12.8 多态与鸭子类型
多态:
- 多态指的是一类事物有多种形态,比如动物有多种形态:猫、狗、猪
- 多态性指的是可以在不用考虑对象具体类型的情况下而直接使用对象,这就需要在设计时,把对象的使用方法统一:例如cat、dog、pig都是动物,但凡是动物肯定有talk方法,于是我们可以不用考虑它们三者的具体是什么类型的动物,而直接使用,并且可以定义一个统一的接口来使用talk方法。
结合生活中的例子:
车这个大类中,有多种形态,比如奔驰、宝马、保时捷等等。
而我们在驾校学车,学的不是如何开丰田、奥迪、吉利,而是教你学车。
学会之后,不管车是那种形态,都可以直接开动,而不需要关系是车是比亚迪还是五菱。
结合python中的例子:
len方法很厉害,可以计算出str类型的长度、list类型的长度、dict类型的长度,等等。
print(len('hello')) # 5 print(len([1,2,3,4])) # 4 print(len({'a':1,'b':2})) # 2
- 1
- 2
- 3
至于为什么可以都通过len方法进行计算,那是因为这些数据类型对象中,都有__len__()方法
print('hello'.__len__()) # 5 print([1,2,3,4].__len__()) # 4 print({'a':1,'b':2}.__len__()) # 2
- 1
- 2
- 3
有了统一的标准之后,那么就可以定义统一的接口,进行调用
实现效果和len是一样的。
def my_len(obj): return obj.__len__() print(my_len('hello')) # 5 print(my_len([1,2,3,4])) # 4 print(my_len({'a':1,'b':2})) # 2
- 1
- 2
- 3
- 4
- 5
- 6
有了统一的标准之后,只要会开车,不管是什么车都能开。
有了统一的标准之后,只要有__len__()方法,那么就能通过my_len接口进行计算,得到长度。
但是,python的多态并不是依据继承来实现统一标准的。
python更推崇的是:鸭子类型
-
鸭子类型,起源于国外谚语:“如果看起来像、叫声像而且走起路来像鸭子,那么它就是鸭子”
-
所以几个类之间可能压根就没有任何联系,只是长得像,那么就可以实现统一标准,如下:
class Dog: def talk(self): print('汪汪汪汪汪汪') class Pig: def talk(self): print('哼哼哼哼哼哼') class Cat: def talk(self): print('喵喵喵喵喵喵') def animal_talk(animal_obj): animal_obj.talk() dog_obj = Dog() cat_obj = Cat() animal_talk(dog_obj) # 汪汪汪汪汪汪 animal_talk(cat_obj) # 喵喵喵喵喵喵- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
猪类、狗类、猫类,都能发声,那么既然都能发声,那就可以定义一个方法,只要传入动物对象,那就能发声,而不用去关系是什么类型的动物对象。
12.9 classmethod与staticmethod
classmethod:
- 绑定给类的方法,又称为绑定方法,类调用传入的是类。
- 多用于创造一种新的实例化对象的方式
理论推导
一、定义类
class Mysql: def __init__(self,ip,port): self.ip = ip self.port = port mysql_obj = Mysql('192.168.1.200','3306') print(mysql_obj.__dict__)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
对象调用类中的__init__方法,会将对象传进入,从而完成对象属性的初始化。
二、现在有个文件叫settings.py,里面记录的有IP和端口信息
# settings文件 ip = '192.168.1.240' port = '3306'
- 1
- 2
- 3
三、添加新功能,可以从设置文件内获取信息,从而实例化对象:
import settings class Mysql: def __init__(self,ip,port): self.ip = ip self.port = port def from_file(): return Mysql(settings.ip,settings.port) mysql_obj = Mysql('192.168.1.200','3306') print(mysql_obj.__dict__) # {'ip': '192.168.1.200', 'port': '3306'} mysql_obj2 = Mysql.from_file() print(mysql_obj2.__dict__) # {'ip': '192.168.1.240', 'port': '3306'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
可以看到,类调用了from_file方法来进行实例化,这个方法是给类调用的。
四、引出classmethod
而python中的classmethod就是声明,那个方法是类方法,调用类方法会把类传进入,所以就有了:
class Mysql: def __init__(self,ip,port): self.ip = ip self.port = port @classmethod def from_file(cls): return cls(settings.ip,settings.port)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这样Mysql类调用from_file方法之后,会把自己传进入,由自定义形参cls接收,cls就表示类。
随后 类() 表示调用,从而执行__init__方法,完成对象的实例化。
staticmethod:
-
使用staticmethod装饰的函数,就变成了非绑定方法,也称为静态方法。
该方法不与类或对象绑定,类与对象都可以来调用它,但它就是一个普通函数而已,因而没有自动传值。
-
当一些函数不需要自动传入self和class时,就可以使用。
12.10 反射
什么是反射,以及作用:
-
反射机制指的是在程序的运行状态中,对于任意一个类,都可以知道这个类的所有属性和方法;
-
对于任意一个对象,都能够调用他的任意方法和属性。
-
这种动态获取程序信息以及动态调用对象的功能称为反射机制。
方法汇总预览:
| 函数名 | 说明 |
|---|---|
| hasattr(object,属性) | 按字符串判断对象有无该属性,返回值为bool类型。 |
| getattr(object, 属性, 返回值) | 当对象object不存在该属性时,返回自定义返回值。 |
| setattr(object, 属性, 值) | 修改或添加对象属性,有属性则修改,无则添加。 |
| delattr(object, 属性) | 删除对象的该属性 |
代码示例:
class Student: def __init__(self,name): self.name = name student_obj1 = Student('Liu Yu')
- 1
- 2
- 3
- 4
- 5
hasattr(object,属性)
作用:查询对象object中是否有该属性
print(hasattr(student_obj1,'name')) # 输出结果: True
- 1
- 2
getattr(object, 属性, 返回值)
作用:hasattr的升级版,不存在该属性时自定义返回值,存在时返回属性对应的值
print(getattr(student_obj1,'name1','not found')) # 输出结果: not found
- 1
- 2
setattr(object, 属性, 值)
作用:修改或添加对象属性,有属性则修改,无则添加。
setattr(student_obj1,'name','xiaxia') setattr(student_obj1,'age',22) print(student_obj1.__dict__) # 输出结果:{'name': 'xiaxia', 'age': 22}
- 1
- 2
- 3
- 4
delattr(object, 属性)
作用:删除对象的该属性
delattr(student_obj1,'name') print(student_obj1.__dict__) # 输出结果: {}
- 1
- 2
- 3
反射练习:
''' FTP为文件传输协议的简称,主要用于文件共享传输,其中get命令是用来获取文件的,格式为: get 文件名 而上传命令为put,格式为: put 文件名 本案例模拟FTP服务器,当用户输入(get 文件名)时,执行获取文件对应的操作,当用户输入(put 文件名)时,执行上传文件对应的操作。 ''' class FtpServer: def get(self,file): print('Downloading %s...' %file) def put(self,file): print('Uploading %s...' %file) def start(self): while True: '''cmd: 命令,即类中的get或put属性。 file: 文件名 ''' cmd,file=input('input your cmd>>: ').strip().split() # 如果输入的命令,对象中存在该属性,那么就为TRUE if hasattr(self,cmd): func=getattr(self,cmd) # getattr(self,cmd) = self.cmd = self.get/put func(file) # 因为get和put需要参数file,所以需要再传入一个参数 server=FtpServer() server.start() '''运行结果示例: input your cmd>>: get 金刚葫芦娃 Downloading 金刚葫芦娃... input your cmd>>: put 葫芦娃高清无码 Uploading 葫芦娃高清无码... '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37

