
- 1Java常用类库之ArrayList_引用什么库含有arraylist
- 2p++与++p解读_p++和++p
- 3vue2.0搭配elementui实现dark暗黑主题_elementui黑色主题
- 4HTML中显示特殊字符“<”,“>“_span显示 html 类型
- 5『恶意代码分析实战』Windows API编程——通过修改注册表的方式实现自启动_编写代码,编辑注册表的run/runonce/runonceex键(任选其一,并明确三个键的区别
- 6【深度学习之YOLO8】视频流推断_yolov8视频流
- 7机器学习:BP神经网络,CNN卷积神经网络,GAN生成对抗网络_bp神经网络、随机森林以及cnn卷积神经网络三大机器学习算法预警模型
- 8UE4 实时渲染原理&优化策略笔记_ue4 pbr源码分析
- 9树莓派4B编译安装snowboy_libsnowboy-detect.a: error adding symbols: file in
- 104.Eigen Tensor详解【三】_eigen tensor sum
语言大模型的浮点运算分配
赞
踩

本文通过实证分析展示了实际LLM模型的FLOPS分配情况,并与理论分析进行对比。通过理论和实证相结合的方式,本文为理解和优化语言大模型的性能提供了有益见解。
作者Finbarr Timbers是一名机器学习研究员,曾就职于DeepMind。(以下内容由OneFlow编译发布,转载请联系授权。原文:https://www.artfintel.com/p/where-do-llms-spend-their-flops)
作者 | Finbarr Timbers
OneFlow编译
翻译|宛子琳、杨婷
本文对LLM的性能进行了理论分析,然后通过详细分析一个实际的LLM,查看实证结果与理论之间的差异。首先是理论分析部分,我会借助Kipply的优质博文来填充细节。基本结论是:对于标准解码器模型,FLOPS(每秒浮点运算数)的分配如下(按每层计算):
6d^2 用于计算QKV(Query(查询)、Key(键)和Value(值))
2d^2 用于计算注意力输出矩阵,softmax(Q @ K.T) @ V
16d^2 用于运行前馈神经网络(FFN)
总计24d^2 FLOPS。从百分比看,25%的时间用于计算QKV,约8%的时间用于计算注意力输出矩阵,约66%的时间用于运行FFN。
那么用于注意力机制的时间呢?众所周知,注意力机制方程为:

假设你正在使用KV缓存,Q(查询)、K(键)和V(值)都是d维向量(等价于(d,1)矩阵)。每个点积大约需要2d个flops(https://www.stat.cmu.edu/~ryantibs/convexopt-F18/scribes/Lecture_19.pdf),加上进行d次除法需要d个flops,总计约为5d个flops,四舍五入为零。

当d等于4096(在Llama7b中的取值),这仅为0.005%,几乎可以忽略不计。这似乎表明注意力机制不重要,但事实并非如此。我们之所以使用KV缓存(以及flash attention等)正是因为它们非常重要,可以将其类比于米尔顿·弗里德曼的恒温器(https://worthwhile.typepad.com/worthwhile_canadian_initi/2010/12/milton-friedmans-thermostat.html,感谢 @bradchattergoon):
假设一个房屋配备了一个运行良好的恒温器,那么我们能看到炉子燃烧的油量(M)与室外温度(V)之间存在强烈的负相关关系,同时炉子燃烧的油量(M)与室内温度(P)之间没有相关性,此外,室外温度(V)与室内温度(P)之间也没有相关性。
一位计量经济学家观察数据后得出结论:燃烧的油量对室内温度没有影响,室外温度对室内温度也没有影响。唯一的影响似乎是燃烧油量会降低室外温度。
观察相同的数据,第二位计量经济学家得出了完全相反的结论。他认为,室外温度(V)增加唯一的影响是会减少耗油量(M),而不会对室内温度(P)产生任何影响。
尽管两位计量经济学家得出了不同的结论,但他们一致认为燃烧油量(M)和室外温度(V)对室内温度(P)没有影响。基于这一共识,他们决定关闭炉子,不再浪费金钱购买燃油。
KV缓存需要O(T)的内存(其中T是我们希望生成的词元数),因此内存需求成本较高,这一点可以参考公司股票($NVDA)情况。
KV缓存有多大呢?对于每个词元,需要存储以下数量的字节(第一个2是因为我们假设使用bf16精度,因此每个参数占用2个字节;第二个2是因为需要同时存储K和V张量):
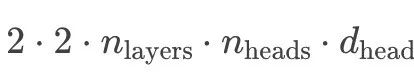
注意,根据假设,n_heads*d_head=d_model=d,因此字节数为4*层数*d。
GPT-3有96层,d_model为12288,每个词元需要4.72MB。因此,生成2048个词元需要5.6GB的内存。
尽管如此,要使用给定模型生成给定长度的序列,我们仍需使用与KV缓存相同的内存量,只是在每次前向传播结束时将其丢弃。因此,我们并不需要更多内存。从某种意义上说,KV缓存不占用内存(至少在Jax中是如此,除了一些繁琐的bookkeeping工作)。
对于一些新兴架构(例如Mistral 7B)又有何不同呢?Mistral 7b使用了分组查询注意力(Llama2也使用了类似的注意力机制,就好像这两个模型的作者存在某种联系。)和滑动窗口注意力。
在分组查询注意力中,我们可以在多头之间共享一个KV投影(MQA),具体而言,可以是所有注意力头之间共享一个KV投影(MQA,https://arxiv.org/abs/1911.02150),或者将其分成多个组(GQA,https://arxiv.org/abs/2305.13245v3)。这两种方法都等同于具有较小d_model的标准多头注意力(MHA)。在之前的KV缓存计算中,我们假设注意力头的数量乘以头的维度等于模型维度,但是在MQA/GQA中,我们放宽了这一假设。KV缓存公式如下:
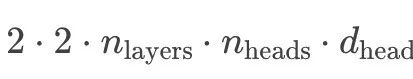
可以转换为:

其中,注意力头的数量乘以头的维度就是模型的有效维度。因此,可以看到,随着KV头数量的减少,KV缓存大小呈线性减小( 这也是GQA/MQA方法背后的关键动机之一)。
Llama{1,2} 模型参数如下:

Llama 2中,每个词元所需的KV缓存如下:
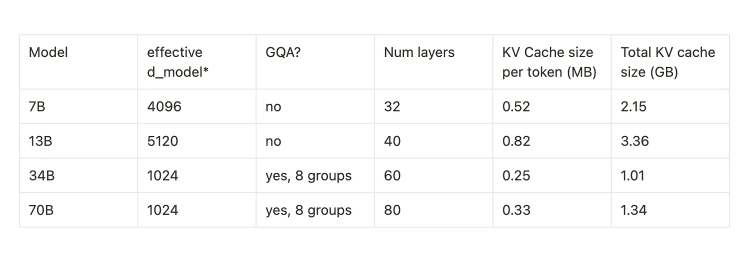
在没有分组查询注意力(GQA)的情况下,34B模型需要的KV缓存内存是原来的5倍,而70B模型需要的KV缓存内存是原来的8倍。
Llama/Mistral的另一个改进是滑动窗口注意力,它保证我们可以将KV缓存限制在窗口大小,对于Llama7B来说,窗口大小为4096。
1
性能驱动的架构变化
如前所述,LLM每层使用了24d^2个flops。增加的层数将线性扩展flops和参数数量,增加模型宽度会二次方扩展模型大小。需要注意的是,这是因为参数的数量与d_model的平方成正比,因为我们的大多数层是从一个d_model输入向量转变为一个d_model的输出向量,所以权重矩阵的尺寸为(d_model, d_model)。换句话说,计算量与参数的数量呈正比,增加d_model会使参数数量呈二次方增加。模型深度增加一倍会使参数数量翻倍,但模型宽度增加一倍会使参数数量增加四倍。
尽管如此,更宽的模型的优势是能够更好地并行化。要计算第N层,必须首先计算前面的N-1层。这在高效并行化上十分困难,尤其是在训练期间,而通过张量并行化方法,跨多个GPU拆分单个层要容易得多。如果你主要关心时延,那么选择更宽的模型可能更合适。
2
实证分析
我使用Colab进行了这项分析。(https://colab.research.google.com/drive/1TH6AKsICZqlFoW1ph8h3wsF7q7qVMF8T?usp=sharing)
以下是单次前向传播的高级概要(我的网站上有交互式概要:https://finbarr.ca/static/llama-profile.svg):

可以看到,本次运行的总时间中有4.88%用于单次前向传播。在前向传播中,有1.98%的时间用于注意力机制,有2.58%的时间用于多层感知机(MLP)。在前向传播的总时间中,有40%的时间用于注意力层,53%用于MLP。在注意力层内部,时间分配在4个不同的线性层上,其中有2个线性层花费的时间大致相同(linear_1、linear_2),一个花费的时间多50%(linear_3),另一个则是前两者的两倍(linear_0)。我猜测linear_0正在计算查询嵌入,而linear_1/2正在计算键和值嵌入。请注意,由于KV头的数量较少,计算速度要快得多!GQA(Query-aware Attention)带来了明显的差异,即便所使用的注意力机制(xformers.ops.memory_efficient_attention)要求QKV嵌入被广播到相同的大小。
理论分析预测,2/3的时间将用于计算FFN,1/3将用于计算注意力机制。这基本符合我们上面所看到的情况。我们花在计算注意力机制上的时间略多于MLP,但我怀疑这是因为MLP正在为Torch执行一个经良好优化的路径。
3
性能变化
接下来,我对Llama2进行了一系列实验,涉及模型宽度和深度的调整。以下是实验结果:

结果非常有趣。可以看到,隐藏维度为1024和1536的两个模型的速度基本没有变化(1.10秒vs1.11秒),隐藏维度为1024和2048的模型只发生了轻微变化(1.15秒vs1.10秒)。然而,当我们比较隐藏维度为2048(1.15秒)、3072(1.41秒)和4096(1.82秒)的模型时,可以看到速度类似于线性扩展!
对此,我的看法是,调度kernel和实际执行矩阵乘法中存在较大的开销。这是在T4上运行的,尽管按现在的标准来看有些过时,但仍具有65 TFLOPS的bf16计算能力。如果我们将两个1024x1024的矩阵相乘,这就需要1G FLOP的计算能力,因此,理论上,我们可以每秒乘以 65000个1024x1024的矩阵。实际上,我们只能得到其60-80%的性能,但仍然是每秒40000次矩阵乘法。如今的GPU拥有大量核心,T4有2560个CUDA核心,每个核心的运行频率在585到1590 MHz之间。因此,任何能够并行化的任务都表现良好,但是那些需要顺序计算的任务则不会得到优化。我认为,这就是图中所看到的的情况——没有足够的并行性来充分利用GPU。
Transformer的深度使性能与预期完全一致:推理时间与深度呈线性增长。最深的模型可能存在一些噪声,但它的性能表现相当稳定。
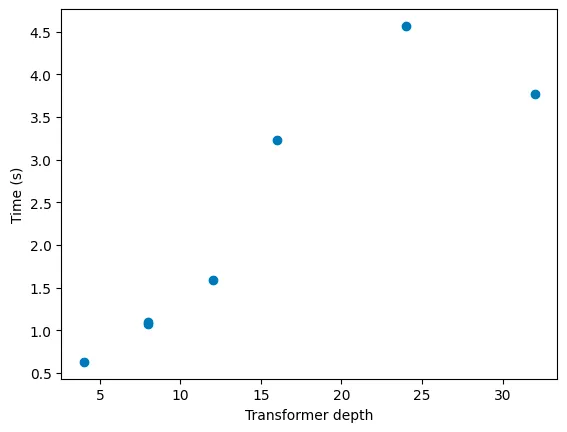
接下来,我计算了生成更多词元所需的成本(对每个词元数量进行了10次运行,以减少噪音):
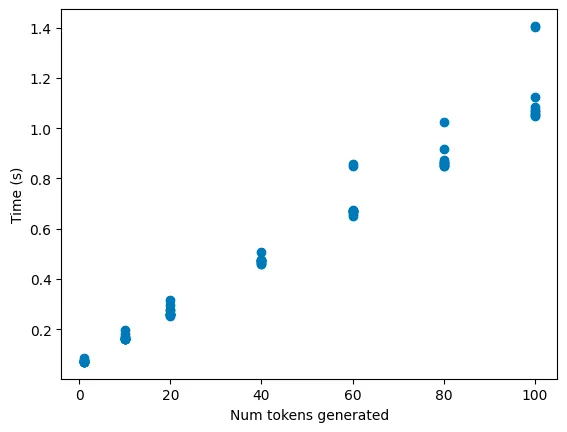
正如预期的那样,完全呈线性增长,因为Llama2使用了KV缓存。如果我们查看保留的内存,就会看到KV缓存与预期的一致(在某种程度上):

可以看到,模型每增加20个词元,内存占用就会增加约2.1MB。由于该模型的 d_model 为1024,有8个隐藏层,因此需要4 * num_layers * d_model字节的内存,即4*8*1024字节=每词元32KB的内存。理论上我们只需要640KB的内存。目前还不清楚额外的3倍开销是从哪里产生的。我怀疑是因为执行还不够高效。
【语言大模型推理最高加速11倍】SiliconLLM是由硅基流动开发的高效、易用、可扩展的LLM推理加速引擎,旨在为用户提供开箱即用的推理加速能力,显著降低大模型部署成本,加速生成式AI产品落地。(技术合作、交流请添加微信:SiliconFlow01)

SiliconLLM的吞吐最高提升近4倍,时延最高降低近4倍

数据中心+PCIe:SiliconLLM的吞吐最高提升近5倍;消费卡场景:SiliconLLM的吞吐最高提升近3倍

System Prompt场景:SiliconLLM的吞吐最高提升11倍;MoE模型:推理 SiliconLLM的吞吐最高提升近10倍
其他人都在看
试用OneDiff: github.com/siliconflow/onediff

- 先添加jar包
junit[详细] 赞
踩

