
- 1无人驾驶汽车系统入门(十八)——使用pure pursuit实现无人车轨迹追踪_小车无人驾驶最常用的局部路径跟踪方法
- 2Spring boot使用easy-es操作elasticsearch_easy-es学习
- 3阿里: 高效两阶段知识迁移的多实体跨域推荐
- 415个经典面试问题及回答思路,,大厂面试必问_程序员面试问公司问题
- 5在 Golang 中执行 Shell 命令_go语言执行shell脚本
- 6.gitignore文件不生效解决方法_git:下列路径根据您的一个.gitignore
- 7【无标题】安装ROS E: 无法定位软件包 ros-melodic-desktop-full_unable to locate package ros-melodic-desktop-full
- 8SpringBoot整合RabbitMQ,实现MQ动态配置交换机-路由-队列信息_spring boot 接入rabbitmq,使用外部配置文件(如yaml或properties)来
- 9buildroot创建最小根文件(支持驱动与QT)_buildroot qt
- 10Python-VBA函数之旅-len函数_excel的len函数在vba如何用
YOLOv9/YOLOv8算法改进【NO.102】涨点+轻量化,亲测有效。引入二次创新模块Faster-EMA,将EMA注意力机制与FasterNet中的核心模块结合构成新模块,_yolov9有效改进
赞
踩
前 言
YOLO算法改进系列出到这,很多朋友问改进如何选择是最佳的,下面我就根据个人多年的写作发文章以及指导发文章的经验来看,按照优先顺序进行排序讲解YOLO算法改进方法的顺序选择。具体有需求的同学可以私信我沟通:第一,创新主干特征提取网络,将整个Backbone改进为其他的网络,比如这篇文章中的整个方法,直接将Backbone替换掉,理由是这种改进如果有效果,那么改进点就很值得写,不算是堆积木那种,也可以说是一种新的算法,所以做实验的话建议朋友们优先尝试这种改法。
第二,创新特征融合网络,这个同理第一,比如将原yolo算法PANet结构改进为Bifpn等。
第三,改进主干特征提取网络,就是类似加个注意力机制等。根据个人实验情况来说,这种改进有时候很难有较大的检测效果的提升,乱加反而降低了特征提取能力导致mAP下降,需要有技巧的添加。
第四,改进特征融合网络,理由、方法等同上。
第五,改进检测头,更换检测头这种也算个大的改进点。
第六,改进损失函数,nms、框等,要是有提升检测效果的话,算是一个小的改进点,也可以凑字数。
第七,对图像输入做改进,改进数据增强方法等。
第八,剪枝以及蒸馏等,这种用于特定的任务,比如轻量化检测等,但是这种会带来精度的下降。
...........未完待续
一、创新改进思路或解决的问题
将FasterNet中的核心模块进行改进,通过引入EMA注意力机制的方法,当然也可以引入或者组合其他的模块构建新的网络结构,再引入到YOLOv8代码中,提高算法的检测效果,通过实验证明,改进方法在大部分数据集上是有效果的。
具体改进思路方法是在下面结构图中的FasterNet Block末尾添加上EMA注意力机制。
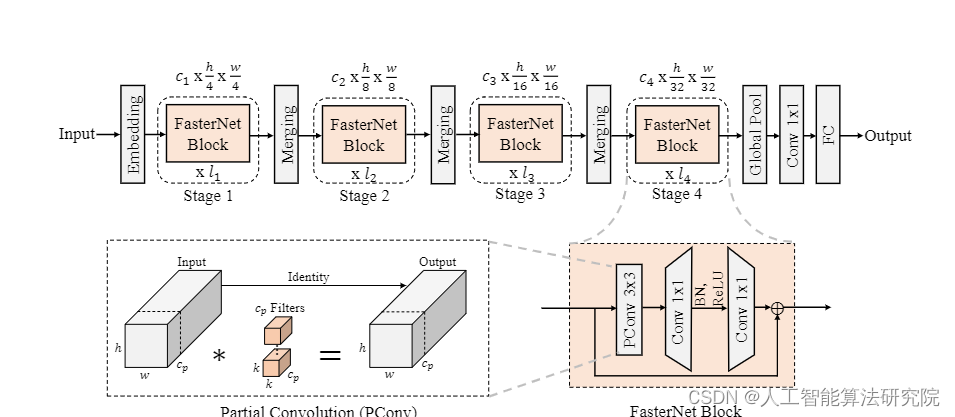
二、基本原理
原文代码: GitHub - JierunChen/FasterNet: [CVPR 2023] Code for PConv and FasterNet

摘要:为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOP)的数量上。然而,我们观察到FLOP的这种减少并不一定会导致类似水平的延迟减少。这主要源于低效率的每秒浮点运算(FLOPS)。为了实现更快的网络,我们重新审视了流行的运营商,并认为如此低的FLOPS主要是由于运营商的频繁内存访问,尤其是深度进化。因此,我们提出了一种新的部分卷积(PConv),通过同时减少冗余计算和内存访问,可以更有效地提取空间特征。在PConv的基础上,我们进一步提出了FasterNet,这是一种新的神经网络家族,它在各种设备上的运行速度远高于其他网络,而不会影响各种视觉任务的准确性。例如,在ImageNet-1k上,我们的小型FasterNet-T0在GPU、CPU和ARM处理器上分别比MobileViT XXS快2.8倍、3.3倍和2.4倍,同时准确率高2.9%。我们的大型FasterNet-L实现了令人印象深刻的83.5%的前1级精度,与新兴的Swin-B不相上下,同时在GPU上的参考吞吐量提高了36%,并在CPU上节省了37%的计算时间。


三、添加方法
第一步:新增网络结构yaml
- # Ultralytics YOLO 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/688187推荐阅读
相关标签

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

