
- 1谷歌浏览器解决(cors)跨域问题_谷歌跨域插件
- 2CCNA 之第一跳冗余协议(FHSRP)HSRP、VRRP、GLBP_hsrp 260 ipv6
- 3【Git常用命令及在IDEA中的使用】_idea使用git命令
- 4单片机驱动多个ds18b20_多个ds18b20怎么接
- 5vscode中vue报错:Building for production...Error: error:0308010C:digital envelope routines::unsupported
- 6【考研数据结构知识点详解及整理——C语言描述】第一章时间复杂度解题方法
- 7vscode类似GitHub Copilot的插件推荐_copilot类似
- 8Llama3本地部署的解决方案_llama3 中文本地部署 cpu
- 9波士顿房价预测 使用Python语言和Numpy库来构建神经网络模_forecast oscillator指标python
- 10FPGA 课程综合实验——倒计时(简易计时器闹钟)基于STEP MAX10 FPGA_fpga课程设计
大模型推理速度翻倍的秘密:硬件选型与GPU优化全攻略_游戏性能指标优化gpu
赞
踩

部署大模型应用(如训练、微调、RAG)时,前期硬件选型至关重要。即使已有方案,缺乏实践经验可能导致硬件评估困难。本文提供硬件评估与选型的专业参照,助您高效部署,精准上报。
初识 GPU
硬件选型
在模型训练与推理的硬件选型中,NVIDIA以其GPU领域的卓越实力成为首选。作为全球知名的GPU公司(1993年创立),其AI芯片领域的垄断性优势使创始人黄仁勋被誉为“黄教主”,引领行业前行。

什么是 GPU
Graphical Processing Units (GPUs)
- GPU是强大电子芯片,专为沉浸式视频游戏、电影等视觉媒体设计,展现细腻逼真的2D/3D图形与动画,打造极致视觉体验。
- 凭借卓越的并行矩阵运算性能,GPU广泛应用于人工智能领域,涵盖机器视觉、NLP、语音识别及自动驾驶等系统,助力智能技术飞速发展。

CUDA 核心和 Tensor 核心
CUDA 核心
- NVIDIA打造的并行计算平台与编程模型,实现GPU上的通用计算,功能强大,如同万能工匠,适应各种任务需求。
- 适合游戏和图形渲染、天气预测、电影特效等场景
案例1:视频渲染优化
电影制片公司打造3D视觉盛宴时,CUDA核心成为渲染关键。它高效处理光线追踪、纹理、阴影等细节,确保画面逼真。当光从源反射至物体再至摄像机,CUDA核心精准计算光线路径,赋予画面真实美感。计算力强大,满足电影制作的极致追求。
Tensor 核心
- 中文叫:张量核心
- 专门设计用于深度学习中的矩阵运算,加速深度学习算法中的关键计算过程
- 适合语音助手、人脸识别等场景
案例2:面部识别技术革新,安全系统、智能手机和众多应用纷纷采用。深度学习模型精准捕捉面部特征,Tensor核心成为核心动力,飞速处理神经网络中的矩阵运算,确保面部识别高效准确,引领科技前沿。
AI 领域常用 GPU
AI 常用 GPU 价格排序
NVIDIA显卡价格排序表出炉,由低至高一目了然。更多排名详情,请查阅《NVIDIA显卡排行榜》章节。
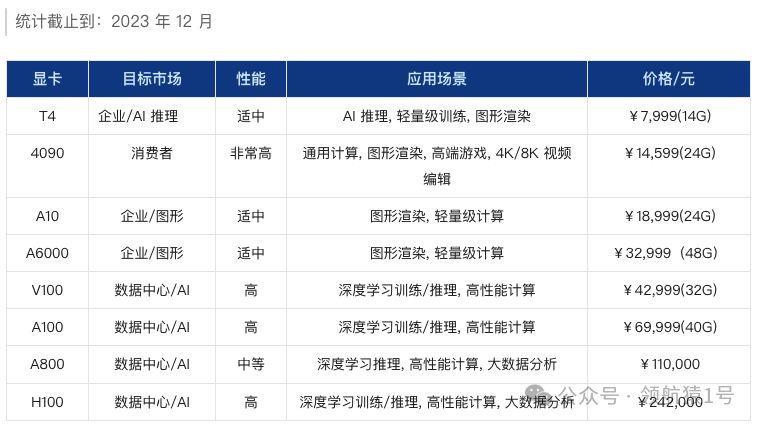
- 有些在京东就能买到
- 美国商务部严格限制GPU对华出口,算力上限4800 TOPS、带宽上限600 GB/s,致使顶级H100和A100遭禁。为应对市场,黄教主迅速推出专为中国市场打造的A800和H800,以满足需求。
- 参考:
- 英伟达 A100 和 H100 已被禁止向中国供货
- 50 亿美元,算力芯片迎来狂欢,腾讯字节抢购英伟达 A800 订单
H100 与 A100
H100 比 A100 快多少?
16-bit 推理快约 3.5 倍,16-bit 训练快约 2.3 倍。
参考资料
深度学习中如何选择GPU?Tim Dettmers详解2023年最佳深度学习GPU,助你高效构建AI模型,不容错过!
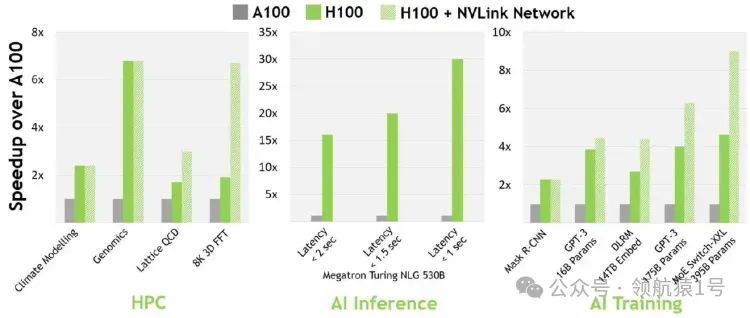
根据场景选择GPU
以下是显卡4090上chatglm与chatglm2模型的Fine tuning实验数据概览,专业精准,助您轻松把握模型优化成效。
llm-utils 上一些选型的建议
- Falcon 是目前为止 huggingface 上排行榜第一的模型
根据不同的使用情境,以下是使用的建议GPU:
模型
显卡要求
推荐显卡
Running Falcon-40B
运行 Falcon-40B 所需的显卡应该有 85GB 到 100GB 或更多的显存
See Falcon-40B table
Running MPT-30B
当运行 MPT-30B 时,显卡应该具有80GB的显存
See MPT-30B table
Training LLaMA (65B)
对于训练 LLaMA (65B),使用 8000 台 Nvidia A100 显卡。
Very large H100 cluster
Training Falcon (40B)
训练 Falcon (40B) 需要 384 台具有 40GB 显存的 A100 显卡。
Large H100 cluster
Fine tuning an LLM (large scale)
大规模微调 LLM 需要 64 台 40GB 显存的 A100 显卡
H100 cluster
Fine tuning an LLM (small scale)
小规模微调 LLM 则需要 4 台 80GB 显存的 A100 显卡。
Multi-H100 instance
不同情况推荐
划重点:
- GeForce RTX 4090等消费级GPU,轻松应对本地个人研发项目的中等规模需求,性能卓越,值得信赖。
- 数据规模小时,可考虑预算内的 A10 或 T4 型号。
- 追求性价比?用4090显卡搭建服务器或选择AutoDL等第三方4090服务,高效又经济,满足您的专业需求。
1、大模型内存选择
大模型训练依赖高性能硬件确保效率与速度。推荐采用高速ECC或DDR5内存。当前主流基于GLM、LLaMA等大模型训练,国内优选A800/H800 x 8 GPU配置,内存同步升级至512GB,以实现高效训练。选择专业配置,加速大模型训练进程。
2、大模型所需磁盘
大模型训练离不开大容量、高速的存储支持,以确保数据快速读取和处理。推荐采用SSD或NVMe固态硬盘,其容量一般介于4T至8T之间,为您的模型训练提供坚实后盾。
3、推荐配置参考
GPU算力平台:大模型训练、自动驾驶、深度学习解决方案。
- A100/A800大模型训练配置分享
- 平台:SYS-420GP-TNAR(4U)
- CPU:2*8358(32核心,铂金版,2.6GHz 超频 3.4GHz)
- GPU:NVIDIA HGX A100/A800(80G SXM)
- 内存:32*64GB DDR4
- H100/H800大模型训练配置分享
- 平台:SYS-821GE-TNHR(8U)
- CPU:2*8468(48核心,铂金版,2.1GHz 超频 3.8GHz)
- GPU:NVIDIA HGX H100/H800(80G SXM5)
- 内存:32*64GB DDR5
物理机 vs. 云服务
划重点:
- 如果经常做微调实验,有自己的物理机会方便很多很多
- 提供推理服务,首选云服务
- 如果有自建机房或 IDC,请随意
云服务厂商对比
国内主流
- 阿里云GPU云服务器,专业加速,高效计算。立即体验,助力业务腾飞!
- 腾讯云:
- 火山引擎:
国外主流
- AWS:aws.amazon.com
- Vultr:www.vultr.com
- TPU:cloud.google.com/tpu
TPU是Google为加速机器学习而设计的顶尖硬件,高效架构让它在大规模深度学习任务中性能卓越,能耗更低。
它的优点和应用场景
- 高性能和能效: TPU 可以更快地完成任务,同时消耗较少的能源,降低成本。
- 大规模训练: TPU 适用于大规模深度学习训练,能够高效地处理大量数据。
- 实时推理: 适合需要快速响应的任务,如实时图像识别和文本分析。
TPU广泛应用于图像处理、自然语言处理、推荐系统等,深受国外科研机构、大公司和初创企业青睐,表现卓越。
NVIDIA GPU 在主流厂商的价对比
下面是对两款 NVIDIA GPU 在火山引擎、阿里云、腾讯云的价格进行对比:
- A100:在云服务中,A100 是顶级的企业级 GPU,适用于高性能计算需求。
- T4:相比之下,T4 更为经济,适合日常模型微调和推理任务。
算力平台
主要用于学习和训练,不适合提供服务。
- Colab:谷歌出品,升级服务仅需 9 美金。colab.google.com
- Kaggle免费提供每周30小时T4、P100算力,助力数据分析与机器学习探索。立即访问www.kaggle.com。
- AutoDL:亲民价,支持Jupyter Notebook与SSH,国内首选平台。立即体验,尽在www.autodl.com。
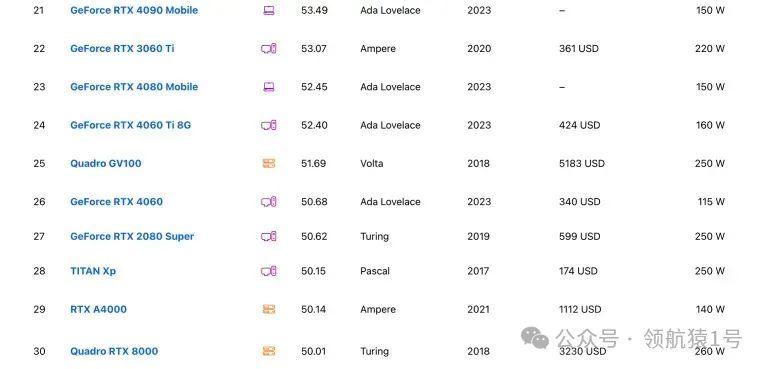
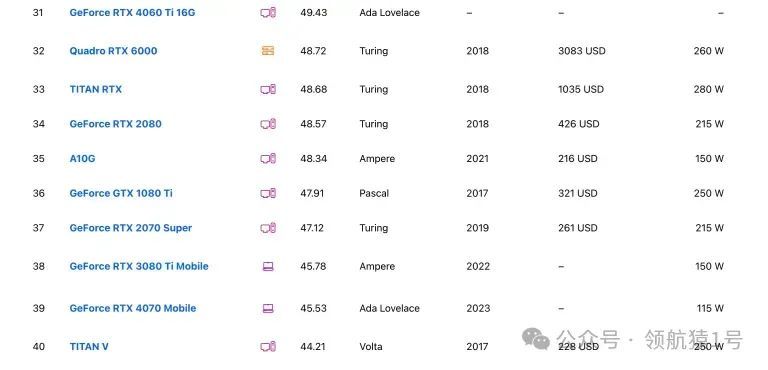
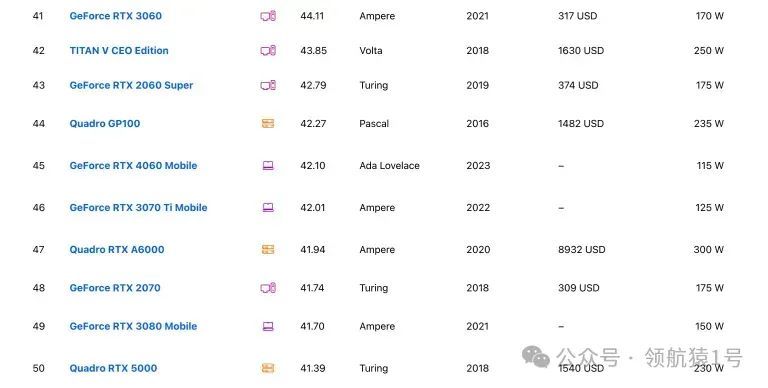
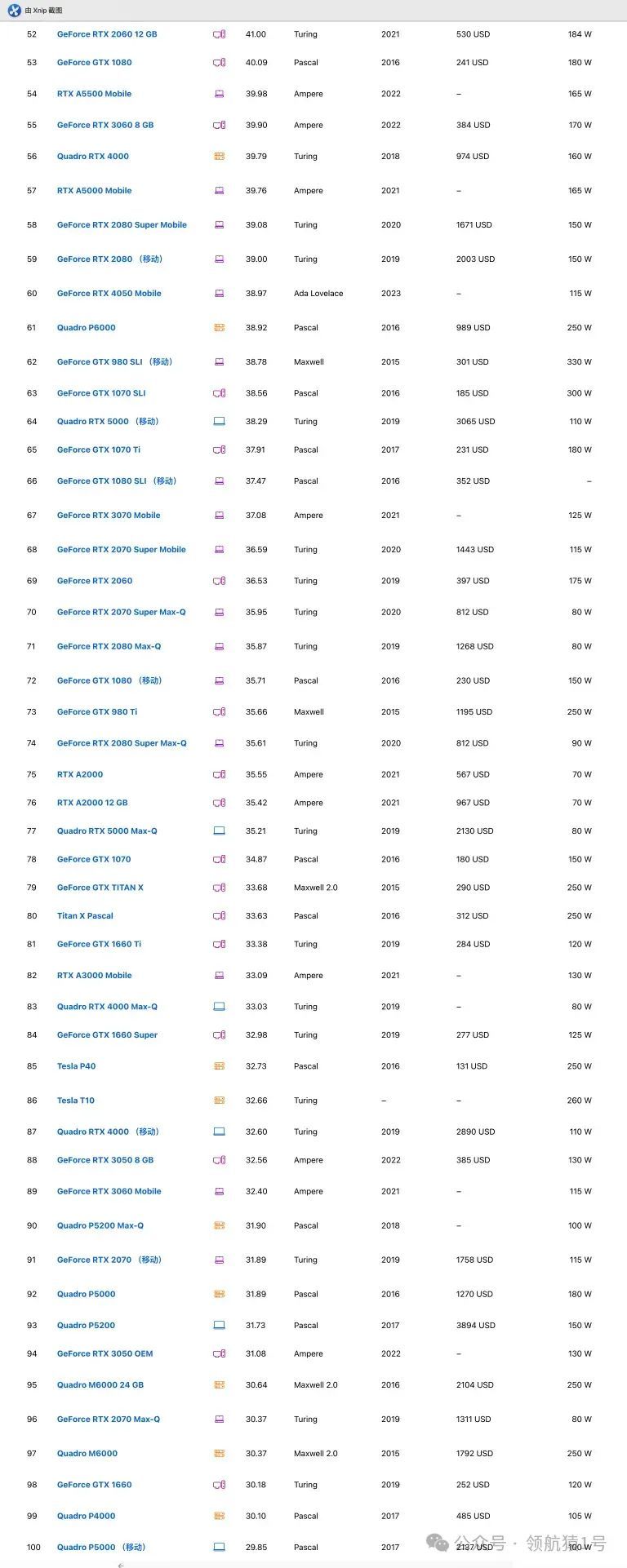
NVIDIA显卡排行榜
此网站能实时对比各种型号显卡
NVIDIA性能评测揭晓,技术实力一览无余。深度剖析,专业解读,助您了解最新科技动态。立即点击,不容错过!
Top 100
下面截图给大家 Top 100,详细请看。
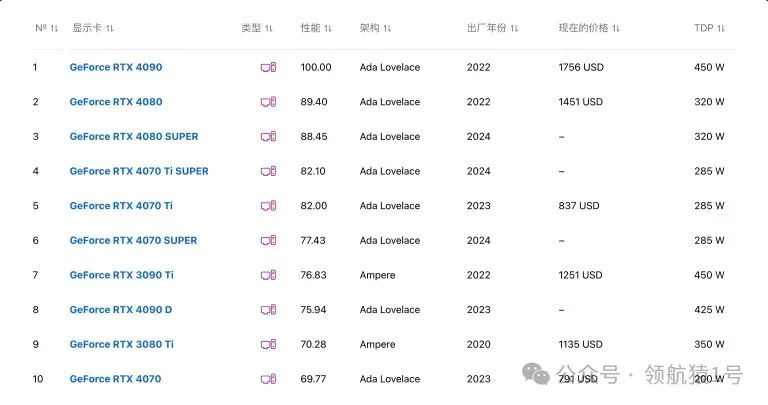
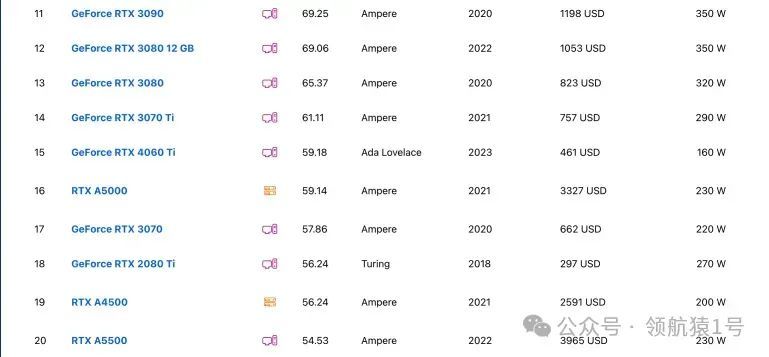
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-

