
- 1微信小程序触底加载分页_小程序 scroll-view分页
- 2【推荐100个unity插件之12】UGUI的粒子效果(UI粒子)—— Particle Effect For UGUI (UI Particle)_particleeffectforugui
- 3MP算法和OMP算法及其思想_momp算法
- 4vue-cli3.0项目中设置scss全局变量_vue3如何在jis中更改scss变量的全局的值
- 5Unity XLua 协程 Coroutine_attempt to yield from outside a coroutine
- 6以太坊智能合约开发:Solidity 语言快速入门
- 7阿里云centos7安装Nginx_阿里云安装nginx
- 8Stone 3D教程:创建全景图云展览,只需要几分钟
- 9隐蔽通信(Covert Communication)论文阅读总结(以及正在尝试论文复现)
- 10C# Dictionary(字典)的键、值排序
基于ChatGLM2-6B的微调技术分享_from model import mode
赞
踩
写在前面
-
微调所用GPU:RTX3090 24GB 实测两种微调所需显存分别为16GB和20GB。
-
数据集不能超过100MB(心存疑惑)?清华提供的广告数据集约52MB有114599条数据,训练约4h。
-
主要工作为基于ChatGLM2-6B的微调理解与实操,主要针对P-TuningV2和Lora微调。对比效果可见jupyter notebook,但指标没有量化。
-
参考代码为ChatGLM2-6B官方教程GitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型与微调延伸项目:GitHub - liucongg/ChatGLM-Finetuning: 基于ChatGLM-6B、ChatGLM2-6B模型,进行下游具体任务微调,涉及Freeze、Lora、P-tuning、全。其中官方教程仅包含P-TuningV2微调与全量微调(显存要求很高),而且代码封装程度较高,可读性较差。微调后保存的模型有些区别,清华官方微调后的model只保存附加层的参数(只有几MB),后者train后的model是保存的全量参数(约12GB)
-
参考资料(包含自己写的博文):
-
ChatGLM2-6B的部署与微调配置:ChatGLM2-6B本地部署或云端部署配置过程_WEIXW99的博客-CSDN博客
-
算法原理——自注意力机制与transformer:Self-Attention——自注意力机制理解_WEIXW99的博客-CSDN博客和Transformer——Sequence-to-sequence的理解_WEIXW99的博客-CSDN博客
-
Azure OpenAI的服务文档,重点是微调的数据集的准则与实践:如何准备用于自定义模型训练的数据集 - Azure OpenAI Service
-
RLHF(强化学习微调):大模型微调方法综述 - 古月居
-
微调实战系列综述:动手学大模型
-
paper:P-Tuning V2和Lora
-
一、微调算法——P-TuningV2和Lora
1、原理
按照时间来讲,prompt最初是由人工设计的,优化能力有限,且成本较高。
为了弥补这一缺点,Prompt tuning(P-tuning V1)应运而生:在embedding层添加一些连续的embedding,并且只训练这一部分。但效果不是很理想。P-Tuning v1如下图左侧所示,右侧是V2版本的。
P-tuning V2(也可称Prefix-tuning,但不完全一样,每个人说法不一样,斯坦福先提出的Prefix-tuning,后有清华在这个和ptuning的基础上进行的改进)版本不仅只在embedding上进行微调,也在TransFormer上的embedding输入每一层进行微调。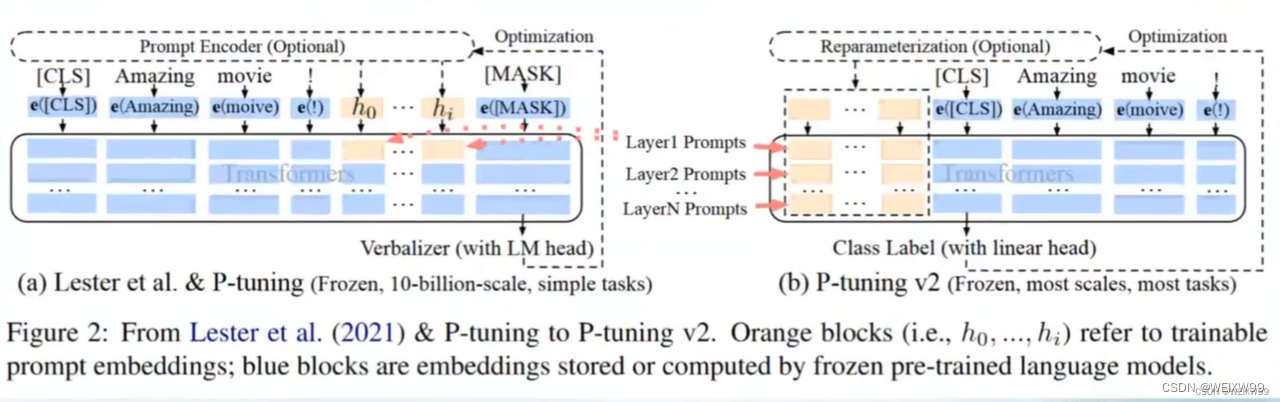
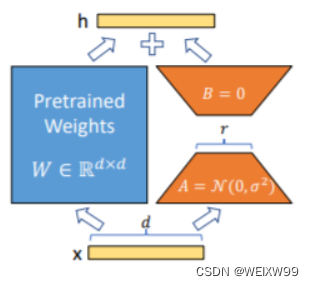
Lora方法在大型语言模型上对指定参数(权重矩阵)并行增加额外的低秩矩阵,并在模型训练过程中,仅训练额外增加的并行低秩矩阵的参数。 当“秩值”远小于原始参数维度时,新增的低秩矩阵参数量也就很小。在下游任务tuning时,仅须训练很小的参数,但能获取较好的表现结果。
2、数据集
以下是清华官方提供的广告数据集,content作为输入,summary作为输出。根据提供的商品信息,生成广告文本。
- {"content": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤", "summary": "宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"}
- {"content": "类型#裙*风格#简约*图案#条纹*图案#线条*图案#撞色*裙型#鱼尾裙*裙袖长#无袖", "summary": "圆形领口修饰脖颈线条,适合各种脸型,耐看有气质。无袖设计,尤显清凉,简约横条纹装饰,使得整身人鱼造型更为生动立体。加之撞色的鱼尾下摆,深邃富有诗意。收腰包臀,修饰女性身体曲线,结合别出心裁的鱼尾裙摆设计,勾勒出自然流畅的身体轮廓,展现了婀娜多姿的迷人姿态。"}
- {"content": "类型#上衣*版型#宽松*颜色#粉红色*图案#字母*图案#文字*图案#线条*衣样式#卫衣*衣款式#不规则", "summary": "宽松的卫衣版型包裹着整个身材,宽大的衣身与身材形成鲜明的对比描绘出纤瘦的身形。下摆与袖口的不规则剪裁设计,彰显出时尚前卫的形态。被剪裁过的样式呈现出布条状自然地垂坠下来,别具有一番设计感。线条分明的字母样式有着花式的外观,棱角分明加上具有少女元气的枣红色十分有年轻活力感。粉红色的衣身把肌肤衬托得很白嫩又健康。"} {"content": "类型#裙*版型#宽松*材质#雪纺*风格#清新*裙型#a字*裙长#连衣裙", "summary": "踩着轻盈的步伐享受在午后的和煦风中,让放松与惬意感为你免去一身的压力与束缚,仿佛要将灵魂也寄托在随风摇曳的雪纺连衣裙上,吐露出<UNK>微妙而又浪漫的清新之意。宽松的a字版型除了能够带来足够的空间,也能以上窄下宽的方式强化立体层次,携带出自然优雅的曼妙体验。"}
- {"content": "类型#上衣*材质#棉*颜色#蓝色*风格#潮*衣样式#polo*衣领型#polo领*衣袖长#短袖*衣款式#拼接", "summary": "想要在人群中脱颖而出吗?那么最适合您的莫过于这款polo衫短袖,采用了经典的polo领口和柔软纯棉面料,让您紧跟时尚潮流。再配合上潮流的蓝色拼接设计,使您的风格更加出众。就算单从选料上来说,这款polo衫的颜色沉稳经典,是这个季度十分受大众喜爱的风格了,而且兼具舒适感和时尚感。"} {"content": "类型#上衣*版型#h*材质#蚕丝*风格#复古*图案#条纹*图案#复古*图案#撞色*衣样式#衬衫*衣领型#小立领", "summary": "小女人十足的条纹衬衣,缎面一点点的复古,还有蓝绿色这种高级气质复古色,真丝材质,撞色竖条纹特别的现代感味道,直h型的裁剪和特别的衣长款式,更加独立性格。双层小立领,更显脸型。"}
- {"content": "类型#裙*材质#网纱*颜色#粉红色*图案#线条*图案#刺绣*裙腰型#高腰*裙长#连衣裙*裙袖长#短袖*裙领型#圆领", "summary": "这款连衣裙,由上到下都透出一丝迷人诱惑的女性魅力,经典圆领型,开口度恰好,露出你的迷人修长的脖颈线条,很是优雅气质,短袖设计,在这款上竟是撩人美貌,高腰线,散开的裙摆,到小腿的长度,遮住了腿部粗的部分,对身材有很好的修饰作用,穿起来很女神;裙身粉红色花枝重工刺绣,让人一眼难忘!而且在这种网纱面料上做繁复图案的绣花,是很考验工艺的,对机器的要求会更高,更加凸显我们的高品质做工;"}
- {"content": "类型#上衣*颜色#纯色*图案#纯色*图案#文字*图案#印花*衣样式#卫衣", "summary": "一款非常简洁大方的纯色卫衣,设计点在于胸前的“<UNK><UNK>”的中文字印花,新颖特别,让人眼前一亮。简单又吸睛的款式,而且不失时髦感,很适合个性年轻人。"}
- {"content": "类型#上衣*版型#宽松*颜色#黑色*颜色#灰色*颜色#姜黄色*风格#休闲*图案#线条*图案#撞色*衣样式#毛衣*衣袖型#落肩袖", "summary": "看惯了灰色的冷淡和黑色的沉闷感,来一点醒目的彩色增添点活力吧。亮眼又吸睛的姜黄色色调,嫩肤显白非常的有设计感。趣味的撞色和宽松的版型相交辉映,修饰身形小缺点的同时,时尚又百搭。优雅的落肩袖,轻松修饰肩部线条,让毛衣上身凸显出一丝慵懒随性的休闲感,时尚魅力尽显。"}
- {"content": "类型#上衣*风格#休闲*风格#潮*图案#印花*图案#撞色*衣样式#衬衫*衣领型#圆领*衣长#中长款*衣长#常规*衣袖长#无袖", "summary": "黑与白,两种最极端的颜色却轻松搭配成了经典,就像此款衬衣,无需过多装饰,仅色调就足够醒目个性,受潮<UNK>所喜欢。做了无袖中长款的样式,走路带风的感觉着实不错,圆领的设计,不是常规的衬衫领,少了点正式反而有种休闲感觉,适合孩子们穿着。后背大面积撞色印花装点,是时尚潮流的象征,也让衣衣不至于单调,轻松就能穿出彩。"}
- {"content": "类型#上衣*版型#宽松*风格#街头*风格#休闲*风格#朋克*图案#字母*图案#文字*图案#印花*衣样式#卫衣*衣款式#连帽*衣款式#对称", "summary": "个性休闲风的连帽卫衣造型时髦大方,宽松的版型剪裁让肉肉的小宝贝也可以穿着,保暖的连帽设计时刻给予宝贝温柔的呵护,袖子和后背别致时髦的字母印花点缀,满满的街头元素融入,演绎休闲朋克风,对称的小口袋美观大方,方便放置更多的随身物品。"} {"content": "类型#裙*裙款式#链条", "summary": "简单大气的设计,不费吹灰之力就能搭配的时髦范儿。时尚的配色一点都不觉得平淡了,有种浑然天成的大气感。强调了整体的装饰,和谐又不失个性,搭配裤装帅气十足,搭配裙子精致优雅。链条和肩带的搭配让使用感更加舒服,单肩手提都好看。"}
测试集:
- {"content": "类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞", "summary": "简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。"} {"content": "类型#裙*材质#针织*颜色#纯色*风格#复古*风格#文艺*风格#简约*图案#格子*图案#纯色*图案#复古*裙型#背带裙*裙长#连衣裙*裙领型#半高领", "summary": "这款BRAND针织两件套连衣裙,简约的纯色半高领针织上衣,修饰着颈部线,尽显优雅气质。同时搭配叠穿起一条背带式的复古格纹裙,整体散发着一股怀旧的时髦魅力,很是文艺范。"}
- {"content": "类型#上衣*风格#嘻哈*图案#卡通*图案#印花*图案#撞色*衣样式#卫衣*衣款式#连帽", "summary": "嘻哈玩转童年,随时<UNK>,没错,出街还是要靠卫衣来装酷哦!时尚个性的连帽设计,率性有范还防风保暖。还有胸前撞色的卡通印花设计,靓丽抢眼更富有趣味性,加上前幅大容量又时尚美观的袋鼠兜,简直就是孩子耍帅装酷必备的利器。"}
- {"content": "类型#裤*风格#英伦*风格#简约", "summary": "裤子是简约大方的版型设计,带来一种极简主义风格而且不乏舒适优雅感,是衣橱必不可少的一件百搭单品。标志性的logo可以体现出一股子浓郁的英伦风情,轻而易举带来独一无二的<UNK>体验。"} {"content": "类型#裙*裙下摆#弧形*裙腰型#高腰*裙长#半身裙*裙款式#不规则*裙款式#收腰", "summary": "这款来自梵凯的半身裙富有十足的设计感,采用了别致的不规则设计,凸显出时尚前卫的格调,再搭配俏皮的高腰设计,收腰提臀的同时还勾勒出优美迷人的身材曲线,而且还帮你拉长腿部比例,释放出优雅娇俏的小女人味。并且独特的弧形下摆还富有流畅的线条美,一颦一动间展现出灵动柔美的气质。"}
- {"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳", "summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"}
- {"content": "类型#裙*材质#蕾丝*风格#宫廷*图案#刺绣*图案#蕾丝*裙型#大裙摆*裙下摆#花边*裙袖型#泡泡袖", "summary": "宫廷风的甜美蕾丝设计,清醒的蕾丝拼缝处,刺绣定制的贝壳花边,增添了裙子的精致感觉。超大的裙摆,加上精细的小花边设计,上身后既带着仙气撩人又很有女人味。泡泡袖上的提花面料,在细节处增加了浪漫感,春日的仙女姐姐。浪漫蕾丝布满整个裙身,美丽明艳,气质超仙。"} {"content": "类型#裤*版型#显瘦*颜色#黑色*风格#简约*裤长#九分裤", "summary": "个性化的九分裤型,穿着在身上,能够从视觉上拉长你的身体比例,让你看起来更加的有范。简约的黑色系列,极具时尚的韵味,充分凸显你专属的成熟韵味。修身的立体廓形,为你塑造修长的曲线。"} {"content": "类型#裙*版型#显瘦*风格#文艺*风格#简约*图案#印花*图案#撞色*裙下摆#压褶*裙长#连衣裙*裙领型#圆领", "summary": "文艺个性的印花连衣裙,藏青色底蕴,低调又大气,撞色太阳花分布整个裙身,绚丽而美好,带来时尚减龄的气质。基础款的舒适圆领,简约不失大方,勾勒精致脸庞。领后是一粒包布扣固定,穿脱十分方便。前片立体的打褶设计,搭配后片压褶的做工,增添层次和空间感,显瘦又有型。"} {"content": "类型#裙*颜色#蓝色*风格#清新*图案#蝴蝶结", "summary": "裙身处采用立体蝴蝶结装饰辅以蓝色条带点缀,令衣身造型饱满富有层次的同时为其注入一丝甜美气息。将女孩清新娇俏的一面衬托而出。"}
- {"content": "类型#裙*颜色#白色*风格#清新*图案#碎花*裙腰型#松紧腰*裙长#长裙*裙衣门襟#拉链*裙款式#拉链", "summary": "这条颜色素雅的长裙,以纯净的白色作为底色,辅以印在裙上的点点小碎花,<UNK>勾勒出一幅生动优美的“风景图”,给人一种大自然的清新之感,好似吸收新鲜空气的那种舒畅感。腰间贴心地设计成松紧腰,将腰线很好地展现出来,十分纤巧,在裙子的侧边,有着一个隐形的拉链,能够让你穿脱自如。"} {"content": "类型#裤*材质#羊毛*裤长#九分裤*裤口#微喇裤", "summary": "不同于一般的西服裤。这款<UNK>小喇叭羊毛裤在样式上显得更加时髦优雅,特地采用微微的九分喇叭裤腿设计,视觉上将脚踝处显得更加纤细。并且特地甄选柔软的羊毛材质,就算直接贴肤穿着,也不会觉得寒冷,比较适合初秋穿噢。"}
3、代码
基于ChatGLM2-6B的P-tuningV2与lora的微调,该部分代码取自github项目ChatGLM-Finetuning的核心代码
可以直接使用shell脚本(ptuning.sh与lora.sh)运行,或者使用该文档运行(暂不能运行)
测试设备RTX3090-24G ptuning实际显存占用约为16G、lora实际显存占用约为20G
训练生成的模型约为24G
出现的问题:
1、jupyter的运行运行模式是单核运行,和终端运行的方式不太一样,因此不能初始化分布式训练。对于shell和python两种运行方式,可以通过设置分布式训练初始化进程的方式进行解决。
原因是因为两种运行程序的不一样。jupyter是以单个内核进程的形式运行的,并且通常不会自动启动额外的进程来进行分布式训练。在设置分布式训练的时候出现了问题。
2、数据集的数量和质量对微调的影响很大。数据集小非常容易过拟合。数据集设置的column在util里面的GLM2PromptDataSet函数。
3、lora有自己的第三方库,支持设置好lora的模型与配置,然后再冻结预训练模型的参数就可以训练。
train:用ptuning微调,准备了1w条数据集一个epoch大约需22分钟,第一个epoch的loss约为3.2、第二个约为3.13
用lora微调,同样准备相同的1w条数据集一个epoch大约30分钟,loss为2.5
- # 调用相关的包,utils和model是项目中的python文件
- import argparse
- import json
- import math
- from tqdm import tqdm
- import torch
- from torch.utils.data import DataLoader, RandomSampler
- from torch.utils.data.distributed import DistributedSampler
- import deepspeed
- from utils import print_trainable_parameters, print_rank_0, to_device, set_random_seed, save_model
- from utils import DataCollator
- from peft import LoraConfig, get_peft_model
- from model import MODE
-
- # 尝试两种方式调用tensorboard
- try:
- from torch.utils.tensorboard import SummaryWriter
- except ImportError:
- from tensorboard import SummaryWriter

- # 超参数设置,该部分只是展示,使用shell脚本设置效果更好。
- # 如果需要直接使用python运行需加上如下代码:
- # torch.distributed.init_process_group('gloo', init_method='file:///tmp/somefile', rank=0, world_size=1)
- def parse_args():
- parser = argparse.ArgumentParser()
- # Model
- parser.add_argument("--model_name_or_path", default="/root/autodl-tmp/model/chatglm2-6b", type=str, help="")
- # DataSet
- parser.add_argument("--train_path", default="data/train_new.json", type=str, help="")
- parser.add_argument("--max_len", type=int, default=1560, help="")
- parser.add_argument("--max_src_len", type=int, default=1024, help="")
- parser.add_argument("--is_skip", action='store_true', help="")
- # Train
- parser.add_argument("--per_device_train_batch_size", type=int, default=1, help="")
- parser.add_argument("--learning_rate", type=float, default=1e-4, help="")
- parser.add_argument("--weight_decay", type=float, default=0.1, help="")
- parser.add_argument("--num_train_epochs", type=int, default=2, help="")
- parser.add_argument("--gradient_accumulation_steps", type=int, default=4, help="")
- parser.add_argument("--warmup_ratio", type=float, default=0.1, help="")
- parser.add_argument("--output_dir", type=str, default="./output-glm2", help="")
- parser.add_argument("--mode", type=str, default="glm2", help="")
- # 设置微调的算法
- parser.add_argument("--train_type", type=str, default="lora", help="")
- parser.add_argument("--seed", type=int, default=1234, help="")
- parser.add_argument("--local_rank", type=int, default=-1, help="")
- parser.add_argument("--show_loss_step", default=10, type=int, help="")
- parser.add_argument("--gradient_checkpointing", action='store_true', help="")
- parser.add_argument("--save_model_step", default=None, type=int, help="")
- # deepspeed features
- # 该部分是deepspeed的一个显存优化技术,成为零冗余优化器,可以提高大模型的训练能力
- parser.add_argument("--ds_file", type=str, default="ds_zero2_no_offload.json", help="")
- # P-tuning
- parser.add_argument('--pre_seq_len', type=int, default=16, help='')
- # pre_seq_len表示ptuning中soft-prompt的长度,即自然语言指令的长度,一般范围时1到512。
- # 指令越长越复杂,该值就需要增大,以便能够理解指令的含义。
- # 网传该值如果比实际需要的大很多,容易生成重复或单一的内容(未测试)
- parser.add_argument('--prefix_projection', type=bool, default=True, help='')
- # ptuning的模式选择,该变量设置true时,则是V2版本,即对大模型的embedding和每一层都加上新的参数
- # 设置成False的时候,为P-tuningV1,也就是only-embedding
- # LoRA
- parser.add_argument("--lora_dim", type=int, default=8, help="")
- # lora增加旁路的低秩矩阵的秩
- parser.add_argument("--lora_alpha", type=int, default=30, help="")
- # 归一化超参数,归一化,以便减少改变r时需要重新训练的计算量
- parser.add_argument("--lora_dropout", type=float, default=0.1, help="")
- parser.add_argument("--lora_module_name", type=str, default="query_key_value", help="")
- # LoRA 目标模块,用于指定要对哪些模块的参数进行微调。比如我们可以对 Q, K, V, O 都进行微调;
- # 也可以只对 Q、V 进行微调。不同的设定会影响需要微调的参数量,也会影响训练过程中的计算量
- parser = deepspeed.add_config_arguments(parser)
- return parser.parse_args(args=[])
- # 一些简单配置,包括deepspeed的config读取与设置、使用tensorboard和读取tokenizer
- args = parse_args()
- device = torch.device("cuda")
- args.global_rank = 0 # 获取设备号,源文件中是指令获取当前设备号,该处是单卡,直接设置为0
-
- with open(args.ds_file, "r", encoding="utf-8") as fh:
- ds_config = json.load(fh)
-
- ds_config['train_micro_batch_size_per_gpu'] = args.per_device_train_batch_size
- ds_config['train_batch_size'] = args.per_device_train_batch_size * args.gradient_accumulation_steps
- ds_config['gradient_accumulation_steps'] = args.gradient_accumulation_steps
-
-
- if args.global_rank <= 0:
- tb_write = SummaryWriter()
-
- set_random_seed(args.seed)
- # load tokenizer
- tokenizer = MODE[args.mode]["tokenizer"].from_pretrained(args.model_name_or_path)
- print_rank_0("tokenizer.pad_token: {}".format(tokenizer.pad_token), args.global_rank) # 填充标记
- print_rank_0("tokenizer.eos_token: {}".format(tokenizer.eos_token), args.global_rank)
- # 加载模型,微调的核心代码,主要是将设置的微调超参数存到model中
- if args.train_type == "lora":
- model = MODE[args.mode]["model"].from_pretrained(args.model_name_or_path)
- lora_module_name = args.lora_module_name.split(",")
- print(lora_module_name)
- config = LoraConfig(r=args.lora_dim,
- lora_alpha=args.lora_alpha,
- target_modules=lora_module_name,
- lora_dropout=args.lora_dropout,
- bias="none",
- task_type="CAUSAL_LM",
- inference_mode=False,
- )
- # 把model和config加入PEFT策略
- model = get_peft_model(model, config)
- model.config.torch_dtype = torch.float32
-
- elif args.train_type == "ptuning":
- config = MODE[args.mode]["config"].from_pretrained(args.model_name_or_path)
- print(config)
- config.pre_seq_len = args.pre_seq_len
- config.prefix_projection = args.prefix_projection # ptuning的模式选择,该变量设置true时,则时V2版本,即对大模型的embedding和每一层都加上新的参数
- model = MODE[args.mode]["model"].from_pretrained(args.model_name_or_path, config=config) # 加载模型参数,与部署预训练模型的加载方式相同
- print(config)
- for name, param in model.named_parameters():
- if not any(nd in name for nd in ["prefix_encoder"]):
- param.requires_grad = False
-
- else:
- raise Exception("train_type无效")
- print('train_type:{}'.format(args.train_type))
- # 加载数据集,并把超参数中的值传入到优化器中,最后把参数打印一遍
- train_dataset = MODE[args.mode]["dataset"](args.train_path, tokenizer, args.max_len, args.max_src_len, args.is_skip)
- train_sampler = RandomSampler(train_dataset)
-
- data_collator = DataCollator(tokenizer)
- train_dataloader = DataLoader(train_dataset, collate_fn=data_collator, sampler=train_sampler,
- batch_size=args.per_device_train_batch_size)
- print_rank_0("len(train_dataloader) = {}".format(len(train_dataloader)), args.global_rank)
- print_rank_0("len(train_dataset) = {}".format(len(train_dataset)), args.global_rank)
-
- # load optimizer
- ds_config["optimizer"]["params"]["lr"] = args.learning_rate
- ds_config["optimizer"]["params"]["betas"] = (0.9, 0.95)
- ds_config["optimizer"]["params"]["eps"] = 1e-8
- ds_config["optimizer"]["params"]["weight_decay"] = 0.1
- num_training_steps = args.num_train_epochs * math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
- print_rank_0("num_training_steps = {}".format(num_training_steps), args.global_rank)
- num_warmup_steps = int(args.warmup_ratio * num_training_steps)
- print_rank_0("num_warmup_steps = {}".format(num_warmup_steps), args.global_rank)
- ds_config["scheduler"]["params"]["total_num_steps"] = num_training_steps
- ds_config["scheduler"]["params"]["warmup_num_steps"] = num_warmup_steps
- ds_config["scheduler"]["params"]["warmup_max_lr"] = args.learning_rate
- ds_config["scheduler"]["params"]["warmup_min_lr"] = args.learning_rate * 0.1
-
- # print parameters
- for name, param in model.named_parameters():
- if param.requires_grad == True:
- print_rank_0(name, 0)
- print_trainable_parameters(model)
-
- # gradient_checkpointing
- if args.gradient_checkpointing:
- model.gradient_checkpointing_enable()
- if hasattr(model, "enable_input_require_grads"):
- model.enable_input_require_grads()
- else:
- def make_inputs_require_grad(module, input, output):
- output.requires_grad_(True)
- model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
- # 该部分为模型训练部分,大循环以epoch=2迭代,代表着将数据集喂给模型训练两次,
- # 在最下面迭代一次,保存一次checkpoint,可以更改为只保存最后一次
- # 该部分代码为了提高可读性,删掉了一些多卡训练和zero3的相关代码
- for epoch in range(args.num_train_epochs):
- print_rank_0("Beginning of Epoch {}/{}, Total Micro Batches {}".format(epoch + 1, args.num_train_epochs,
- len(train_dataloader)), args.global_rank)
- model.train()
- for step, batch in tqdm(enumerate(train_dataloader), total=len(train_dataloader), unit="batch"):
- batch = to_device(batch, device) # 将batch的数据放到指定的设备上,实测单卡运行不使用deepspeed时,数据会出现紊乱(cpu和gpu都有训练数据)
- print(batch["input_ids"].shape)
- outputs = model(**batch, use_cache=False)
- loss = outputs.loss #计算损失
- tr_loss += loss.item()
- model.backward(loss) # 将loss向模型输入侧进行反向传播
- torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 裁剪梯度
- model.step() # 优化器对参数进行更新
- # 打印数据和保存模型
- if (step + 1) % args.gradient_accumulation_steps == 0:
- global_step += 1
- # 打印所需的显示数据,print_rank_0函数是指如果第二个参数小于等于0,则打印第一个参数,
- # 这样设置的实际目的是应用在多卡训练中,为了避免多余的打印信息
- if global_step % args.show_loss_step == 0:
- print_rank_0("Epoch: {}, step: {}, global_step:{}, loss: {}".format(epoch, step + 1, global_step,
- (tr_loss - logging_loss) /
- (args.show_loss_step * args.gradient_accumulation_steps)), args.global_rank)
- print_rank_0("step: {}-{}-{}".format(step + 1, global_step, model.global_steps), args.global_rank)
- if args.global_rank <= 0:
- tb_write.add_scalar("train_loss", (tr_loss - logging_loss) /
- (args.show_loss_step * args.gradient_accumulation_steps), global_step)
- logging_loss = tr_loss
- # 按照设定好的步数保存checkpoint,即model
- if args.save_model_step is not None and global_step % args.save_model_step == 0:
- save_model(model, tokenizer, args.output_dir, f"epoch-{epoch + 1}-step-{global_step}")
- model.train()
- # 仅适用于单卡训练,zero2的显存优化技术下的模型保存。如果使用的是zero3,还需要将模型参数合并保存
- save_model(model, tokenizer, args.output_dir, f"epoch-{epoch + 1}-step-{global_step}")
4、效果
chatglm2-6b原模型
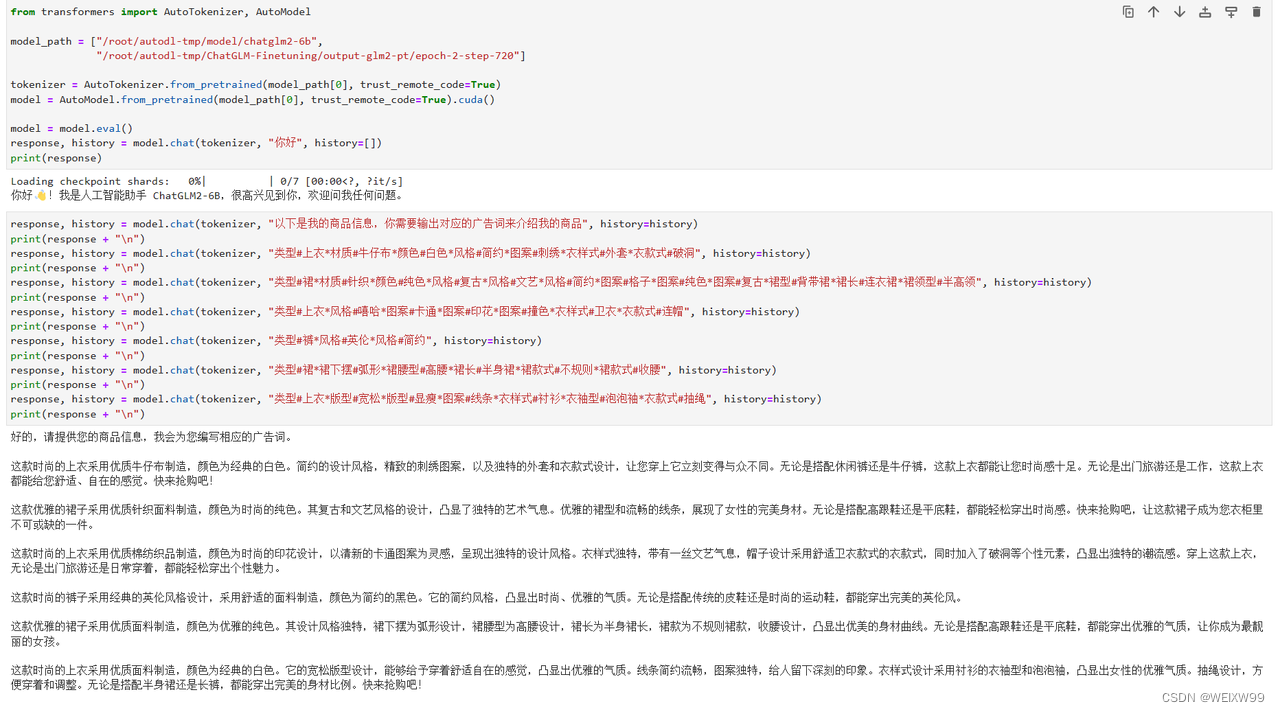
Ptuning微调后(出现了灾难性遗忘)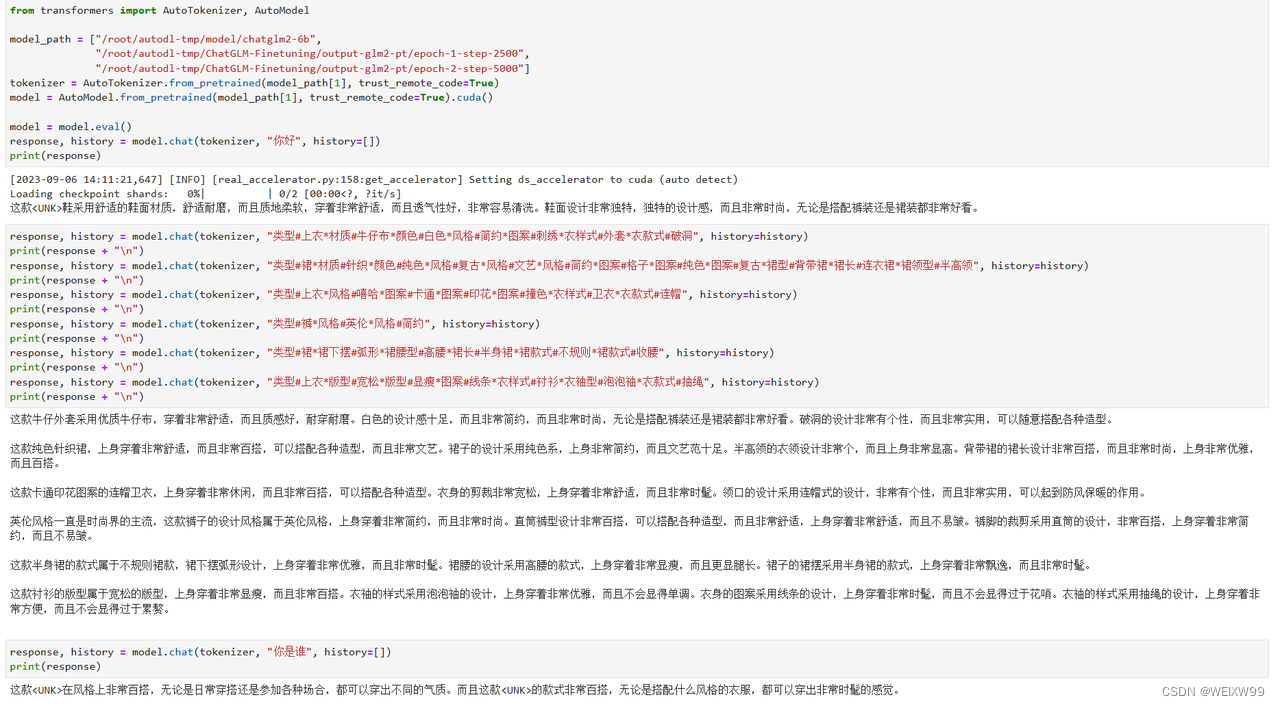
Lora微调后:
二、Future
-
一方面,对于数据集的优化。微调的好坏更多的取决于数据集的质量,同时自定义的效果越好,示例越多,通常模型的性能就越好。微调后模型的性能也会随着示例数的翻倍而线性增加,增加示例数量通常是提高性能的最佳且最可靠的方法。
-
另一方面,使用强化学习(RLHF)进行优化。大模型普遍存在幻觉问题(胡言乱语的答复),出现的原因可能是训练数据存在虚假信息,也可能是预训练模型不够好。目前解决的方法有在prompt中加入相关的相应的警示,或者在训练数据中增加相关的数据进行训练。对于该问题更好的优化方向可能是强化学习,这是一种利用反馈来学习策略的范式,通过与环境交互获得学习的数据。对于中油致知中出现的错误答案,将错误的数据反馈到强化学习中,并给出不好的奖励进行训练优化。或许能train出更高的正确率。

