
热门标签
热门文章
- 1零基础小白撸空投攻略:空投流程是什么样的? 如何操作?_web3怎么撸空投
- 2vue 单元测试_vue单元测试
- 3【数据结构-C语言】冒泡排序,插入排序,选择排序
- 4最短生成树 (超详细大全)
- 5crossover如何永久免费 crossover激活码分享 crossover软件安装使用 2024永久免费版CrossOver软件下载
- 6细节详解 | Bert,GPT,RNN及LSTM模型
- 7【2024华为OD机试C卷】476、矩阵匹配、数组中第 K 大的数中的最小值 | 机试真题+思路参考+代码解析(C语言、C++、Java、Py、JS)
- 82022 01 27 dnf 起号 搬砖 脚本源码开源 by ~戴眼镜的猫_dnf脚本源码
- 9软件测试面试八股文(答案+文档)_软件测试八股文.pdf
- 10配置Java开发环境
当前位置: article > 正文
基于 Transformer 的多子空间多模态情感分析-数据代码_多模态情感识别代码
作者:黑客灵魂 | 2024-07-27 14:58:55
赞
踩
多模态情感识别代码
项目介绍:
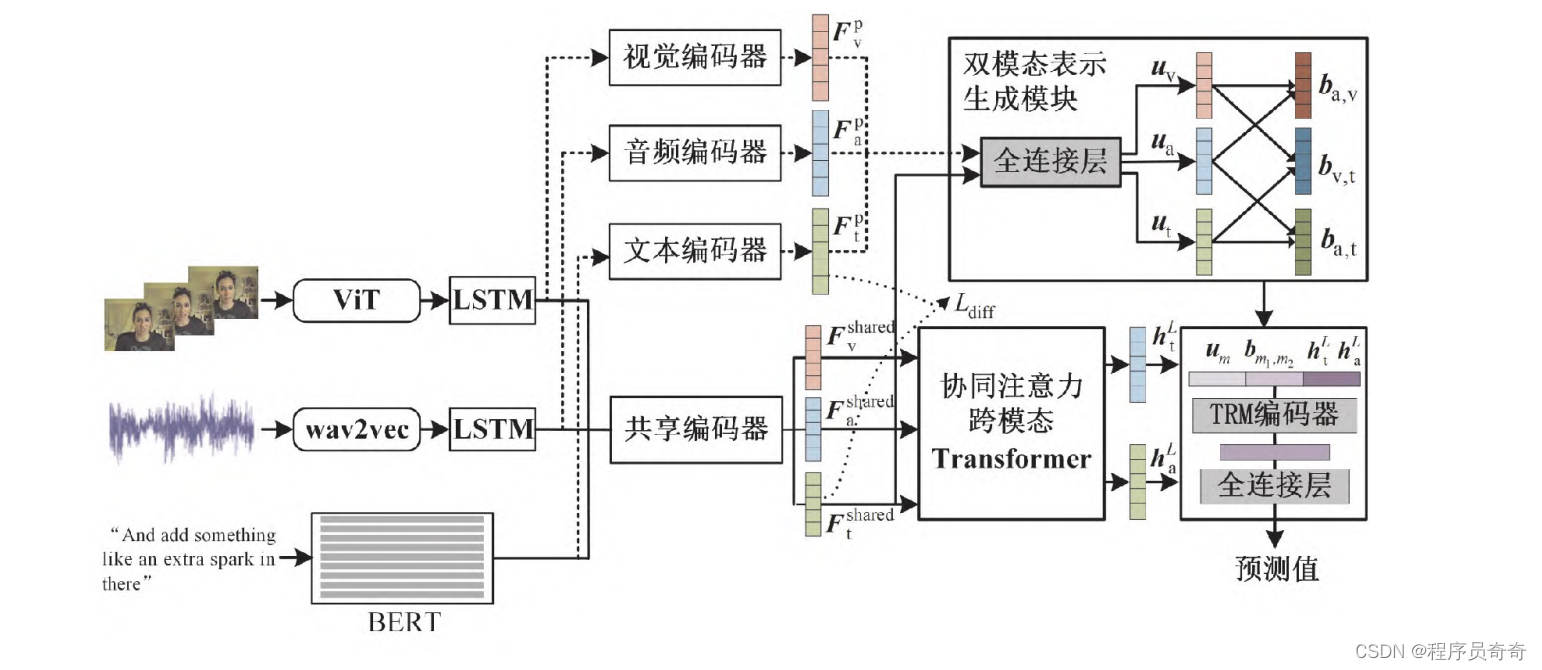
多模态情感分析是指通过文本、 视觉和声学信息识别视频中人物表达出的情感。 现有方法大多通过设计复杂的融合方案学习多模态一致性信息, 而忽略了模态间和模态 内的差异化信息, 导致缺少对多模态融合表示的信息补充。 为此提出了一种基于Transformer 的多子空间多模态情感分析方法。 该方法将不同模态映射到私有和共享子空间,获得 不同模态的私有表示和共享表示,学习每种模态的差异化信息和统一信息。 首先,将每种 模态的初始特征表示分别映射到各自的私有和共享子空间,学习每种模态中包含独特信 息的私有表示与包含统一信息的共享表示。 其次,在加强文本模态和音频模态作用的前 提下,设计二元协同注意力跨模态 Transformer 模块,得到基于文本和音频的三模态表示。 然后, 使用模态私有表示和共享表示生成每种模态的最终表示, 并两两融合得到双模态 表示, 以进一步补充多模态融合表示的信息。 最后, 将单模态表示、 双模态表示和三模 态表示拼接作为最终的多模态特征进行情感预测。 在 2 个基准多模态情感分析数据集上 的实验结果表明。
直接看模型:
- import torch
- import torch.nn as nn
- import torchaudio
- from transformers import ViTModel, Wav2Vec2Model, BertModel
-
-
- # 定义模型结构
- class MultiModalModel(nn.Module):
- def __init__(self):
- super(MultiModalModel, self).__init__
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/黑客灵魂/article/detail/890603
推荐阅读
相关标签

