
- 13个可以写进简历的京东AI NLP项目实战,走完这五步就是Top算法工程师
- 22024最强SoTA行人重识别(ReID)项目实战_stn行人重识别
- 3TransE模型的简单介绍&TransE模型的python代码实现
- 4Github项目README美化-Github徽章制作_readme 徽章
- 5python开源框架_5个开源Python GUI框架
- 6什么是分区分桶?
- 7Elasticsearch快速入门
- 8项目管理计算-- PV、EV、AC、BAC、EAC、ETC等计算公式含义_bac计算公式
- 9医院信息化-5 集成平台和数据中心_医院数据中心和集成平台
- 10unity鼠标悬停在Button上显示介绍_unity检测鼠标在button上
论文阅读--Knowledge distillation via softmax regression representation learning
赞
踩
ABSTRACT
This paper addresses the problem of model compression via knowledge distillation. We advocate for a method that optimizes the output feature of the penultimate layer of the student network and hence is directly related to representation learning. To this end, we firstly propose a direct feature matching approach which focuses on optimizing the student’s penultimate layer only. Secondly and more importantly, because feature matching does not take into account the classification problem at hand, we propose a second approach that decouples representation learning and classification and utilizes the teacher’s pre-trained classifier to train the student’s penultimate layer feature. In particular, for the same input image, we wish the teacher’s and student’s feature to produce the same output when passed through the teacher’s classifier, which is achieved with a simple L2 loss. Our method is extremely simple to implement and straightforward to train and is shown to consistently outperform previous state-of-the-art methods over a large set of experimental settings including different (a) network architectures, (b) teacher-student capacities, (c) datasets, and (d) domains. The code is available at https://github.com/jingyang2017/KD_SRRL.
翻译:
这篇论文解决了通过知识蒸馏进行模型压缩的问题。我们主张一种优化学生网络倒数第二层输出特征的方法,因此与表示学习直接相关。为此,我们首先提出了一种直接特征匹配方法,重点优化学生网络的倒数第二层。其次,更重要的是,因为特征匹配没有考虑到手头的分类问题,我们提出了第二种方法,将表示学习和分类解耦,并利用教师的预训练分类器来训练学生的倒数第二层特征。特别是,对于相同的输入图像,我们希望通过教师的分类器传递时,教师和学生的特征产生相同的输出,这通过简单的 L2 损失实现。我们的方法非常简单易实现,训练过程直接,且在大量实验设置下一直表现优异,包括不同的(a)网络架构,(b)教师-学生容量,(c)数据集和(d)领域。代码可在 GitHub - jingyang2017/KD_SRRL 找到。
INTRODUCTION
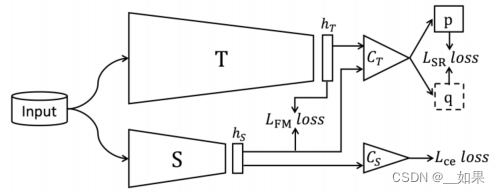
我们的方法通过最小化教师和学生的倒数第二特征表示 hT 和 hS 之间的差异来进行知识蒸馏。为此,我们提出使用两种损失:(a) 特征匹配损失 LFM,和 (b) 所谓的 Softmax 回归损失 LSR。与 LFM 相反,我们的主要贡献 LSR 被设计来考虑手头的分类任务。为此,LSR 规定对于相同的输入图像,当通过教师预先训练和冻结的分类器时,教师和学生的特征产生相同的输出。请注意,为了简单起见,未显示用于使 hT 和 hS 的特征维度相同的函数。
METHOD
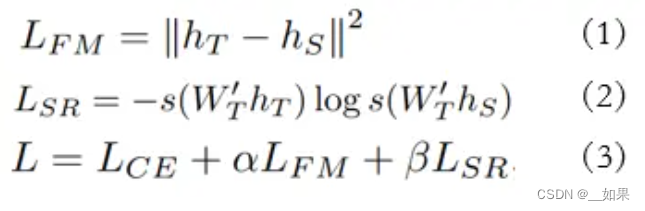
公式1的 ℎ
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

