
- 1c++ 实现学生类设计_c++设计一个学生类,包括学号,姓名,性别
- 2NLP笔记_softlabel 软标签
- 3基于diffusion models的无监督Image-to-Image转化_cyclediffusion
- 4java.io.FileNotFoundException: No content provider: http
- 5midiOutShortMsg 函数的用法以及乐器编号
- 6FPGA(基于xilinx)中PCIe介绍以及IP核XDMA的使用_xilinx pcie
- 7基于uniapp下的微信小程序ocr识别_uniapp微信小程序ocr识别接口
- 8ps -aux 命令详解_ps aux | grep nginx
- 9Zabbix 6.4 惊喜发布!让管理Zabbix配置比以往任何时候都更加容易!新功能速查!
- 10Linux文件系统的barrier:启用还是禁用_barrier=0
“体验版”PyTorch 2.0备受瞩目,它到底好在哪里?_pytorch哪个版本稳定
赞
踩
过去的几年里,PyTorch从1.0到1.13进行了创新和迭代,12月2日,PyTorch 2.0正式发布。它训练速度快,可用性强,并且100%向后兼容。
虽然目前还只是“体验版”,其稳定版预计在 2023 年 3 月初才会发布。但自发布以来网上关于它的文章消息依然是层出不穷(如下图),那么对于PyTorch 2.0,“圈内人士”到底是怎么看得呢?现在笔者就和大家一起来看下:
来自袁进辉的评论:
链接:
https://www.zhihu.com/question/570220953/answer/2786337522
来源:知乎
前天晚上看了 PyTorch Dev Con 2022 的上半场直播,可能我原本一直关注着 PyTorch 的日常进展的缘故,这次新版本发布的一些改进早就知道了,所以就没有那么震撼的感觉。
大家都能看到,这次版本最大的改进还是大举引入编译器技术,这对原本以Eager见长的PyTorch来说的确是大事,这对原本以静态编译见长的框架(TensorFlow, OneFlow, MindSpore等)来说就不新鲜。所以也有其他朋友提出猜测:PyTorch走别人的路,会不会让别人无路可走?
特别是 @波尔德 在回答里提到了 oneflow一些小众框架,
如oneflow也在做类似的事情:完全兼容torch 1.x的API,但引入编译加速。torch这一波不知道会不会官方逼死同人。
所以,我从和 OneFlow 对比来简要的分享一些我对PyTorch 2.0 的理解。
-
PyTorch 这次最大的改进是引入了 torch.compile(),OneFlow 里的 nn.graph 和这个抽象是对标的,但必须承认 PyTorch 的编译方案有更高明的地方,特别是 TorchDynamo,通过ByteCode 层面支持自动 graph capture,这个很牛逼,OneFlow 没有这个功能,其他框架也没有做到这么好。TorchDynamo 也有不足,追求性能极致的话,自动 graph capture 还是比不上人工提供一些 hint, 人工来做 graph capture (譬如TorchScript, OneFlow nn.graph等),虽然 PyTorch 展示百分之几十的性能提升,还是不如其它方案几倍提升那么明显 (以最近大热的 stable diffusion 为例,Meta AIT 和 OneFlow nn.graph 都能相对于 PyTorch Eager 带来几倍的性能提升)。
-
TorchInductor 主要是引入了OpenAI Triton 支持用 Python 取代 CUDA 编程来写底层硬件的代码,这一个功能是好是坏值得观察,对 OneFlow 来说,我们现在觉得不是那么必要。
-
3PrimTorch 也是很有意思的技术,可以把2000个算子用 250 个基础算子实现出来了,意味着适配新硬件会更加方便。在这一点上,OneFlow 的思路也是一样的,也有对应的抽象,名字也叫 Primitive (oneflow/oneflow/core/ep/cuda/primitive at master · Oneflow-Inc/oneflow (github.com))。
-
分布式的进步比预期的还要小,PyTorch 模仿 OneFlow global tensor 实现了 DistributedTensor, 不过从现场的报告来看,还有比较大的差距,在编程接口抽象上仍有不足, 虽然引进了 dtensor,理论上并行粒度的操纵可以非常细,不过现在还是在module 层面去做(见下图 parallelize_module 接口)

-
PyTorch 既然有了DistributedTensor象,那么理论上,基于该抽象,可以大大简化分布式编程,可以用新的接口大大简化 NVIDIA Megatron-LM 和 Microsoft DeepSpeed,正如 OneFlow LiBai (Oneflow-Inc/libai: LiBai(李白): A Toolbox for Large-Scale Distributed Parallel Training (github.com) ) 只需要五分之一的代码就可以覆盖 Megatron-LM 和 DeepSpeed 的功能,蛮期待 PyTorch 生态里面出现一个和LiBai 类似的项目。
-
在分布式性能上也有很大的提升空间,以搜推广场景的大规模embedding模型为例,大约有10倍的性能差距。
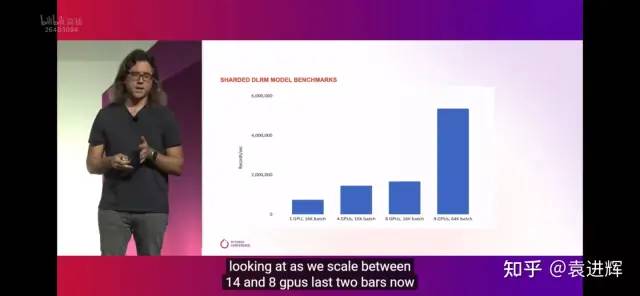

相同的模型,类似的硬件,TorchRec 的吞吐是几百万,NVIDIA HugeCTR和 OneFlow OneEmbedding的吞吐是几千万。
总结一下,PyTorch 里 TorchDynamo 是革命性的,但是在其它方面,其它框架(譬如 OneFlow)还是很有竞争力的。
最后,因为 OneFlow 在追求兼容 PyTorch,因此 OneFlow 也可以被认为是属于 PyTorch 生态,所以我们也乐见 PyTorch 发展的越来越好。
发布于 2022-12-04 09:16
来自谢圜不是真名的评论:
链接:
https://www.zhihu.com/question/570220953/answer/2784950582
来源:知乎
PyTorch 2.0的官方反复强调自己完全向后兼容。
TensorFlow 2.0:首先我没有惹任何人……

这个版本的主要feature就是torch.compile()的出现,通过编译的方式,用一行代码实现模型的稳定加速。
对,它就是优秀到可以让PyTorch换大版本号。
(每天用A5000训BART的答主看到这个改进,不禁流下了感动的眼泪)
使用方法如下:
-
- compiled_model = torch.compile(model)
这个语句返回一个原来模型的引用,但是将forward函数编译成了一个更优化的版本。
(TF支持eager,PyTorch支持编译,正所谓一切战术转换家)
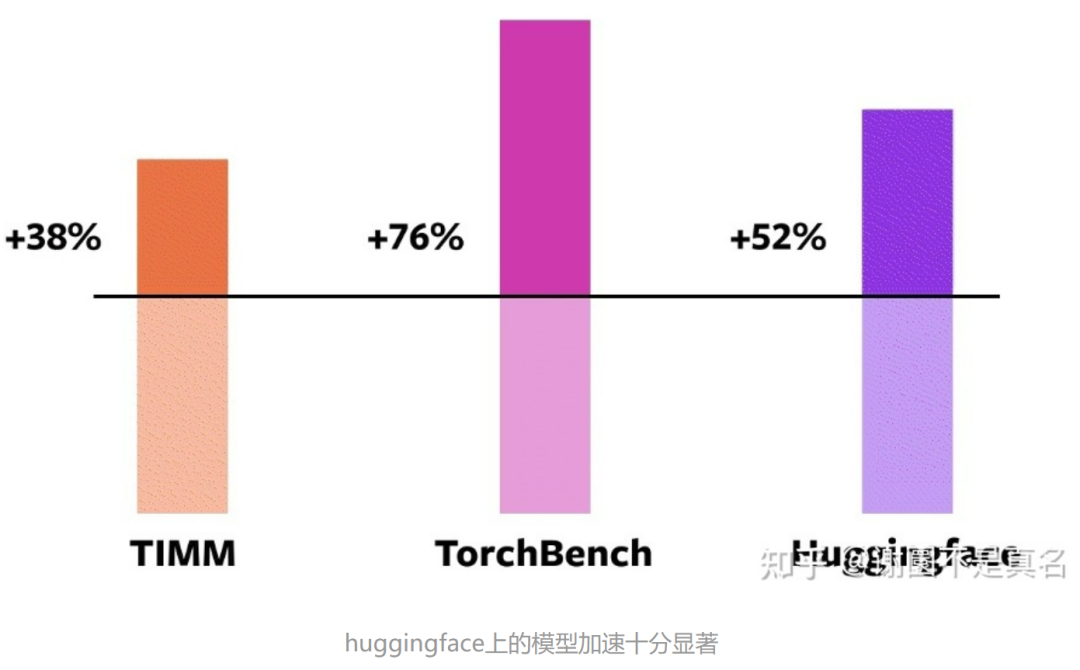
而这一行代码,带来的是在A100上训练速度的43%的提升:
在这163个开源模型中,torch.compile有93%的工作时间,模型在NVIDIA A100 GPU上的训练运行速度快43%。在Float32精度下,它的运行加速平均为21%,在AMP精度下,它的运行加速平均为51%。
这个API同时提供一些参数可以使用:
-
- def torch.compile(model: Callable,
- *,
- mode: Optional[str] = "default",
- dynamic: bool = False,
- fullgraph:bool = False,
- backend: Union[str, Callable] = "inductor",
- # advanced backend options go here as kwargs
- **kwargs
- ) -> torch._dynamo.NNOptimizedModule
可以用来做一些更加细节的指定,通常来说不需要管他们。
官方的介绍来看,这个新API同时兼容torch的DDP也就是并行框架。
这个新API后面的四项新技术
TorchDynamo使用Python Frame Evaluation Hooks,安全地捕获PyTorch程序,这是我们5年来在安全图形捕获方面研发的一项重大创新。
AOTAutograd重载了PyTorch的autograd引擎,作为一个追踪的autodiff,用于生成ahead-of-time的backward追踪。
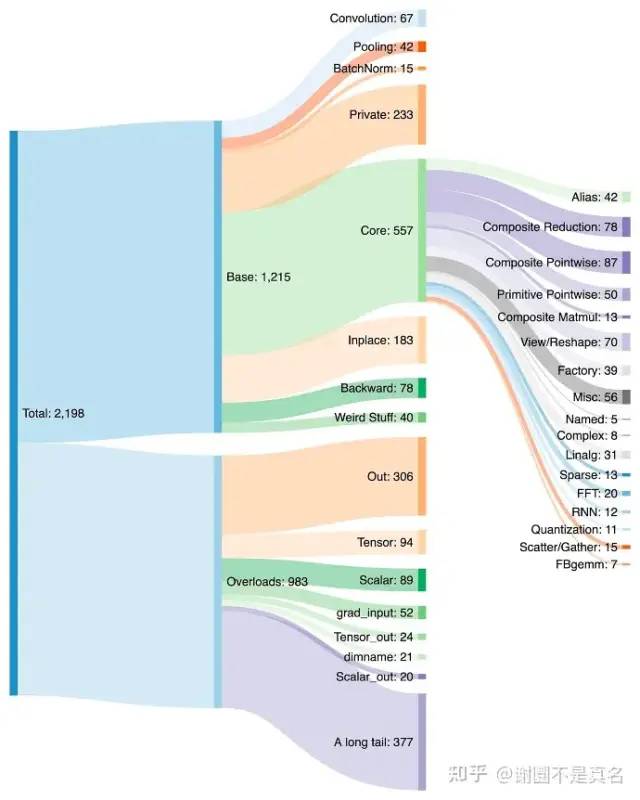
PrimTorch将约2000多个PyTorch运算符归纳为约250个原始运算符的封闭集,开发人员可以针对这些运算符建立一个完整的PyTorch后端。这大大降低了编写PyTorch功能或后端的障碍。
TorchInductor是一个深度学习编译器,可以为多个加速器和后端生成快速代码。对于英伟达GPU,它使用OpenAI Triton作为关
原始的技术细节我就不搬运了,但这个版本尤其是PrimTorch的优化,它们优化了PyTorch最基本的那些运算符,使得新版本的基本运算符的数量更少了,也更稳定了。个人很认同这个努力方向……属于是细水长流的优化工作。
总之,有的框架能够不断优化自己,而另一些框架不断优化用户。
编辑于 2022-12-03 09:03
来自Yuxin Wu的评论:
链接:
https://www.zhihu.com/question/570220953/answer/2798657470
来源:知乎
Graph capture 把用户 Python 写的模型代码变成 graph, 是一切编译的根基. 而 PyTorch 在试了这么多方案之后似乎已经锁定 TorchDynamo 作为 graph capture 的未来方向了, 所以写一点关于 TorchDynamo 的吧. 主要是解释解释到底为什么要做这个东西. (离开FB一年了, 内容主要凭自己的猜测和理解).
一句话尽量解释 TorchDynamo 干了什么: 利用 PEP523 的 API 在用户执行每个 python frame 前, 拿到这个 frame 的 bytecode, 把其中认识的部分用 tracing 的方式提取出 graph (并送给后端编译), 不认识的部分维持原样. 把修改后的 bytecode还给 CPython 跑.
由于 LazyTensor 和 TorchDynamo 都做 tracing 并且都是 best-effort graph capture, 即只编译自己能 capture 的部分, capture 不到的用 Python 跑 (aka Python fallback), 所以观感上两者可能会差不多. 然而这两个方案的差别正是 TorchDynamo 关键的地方:
LazyTensor 是个纯靠 tracing 的方案, 不可避免的问题是「只能看见 trace 到的部分, 只有 trace 一下才知道哪里不能 trace」. 而每次执行模型的时候, 不能 trace 的部分可能是不太一样的。为了保证正确性, LazyTensor 就不得不每次执行都要重新 trace. 举个极端的例子, 模型里写了一个torch.add (tensor, random.random()), 其中 random是个 LazyTensor 看不见摸不着的 Python 函数, 那只有重新 trace 才能保证正确性。
而当 TorchDynamo 修改 bytecode 的时候, 事情就不太一样了:
-
在 bytecode 里能够看得见所有需要的信息, 所以能够证明「这段模型代码有用到奇怪的东西所以不需要重新 trace」.
-
光证明了「不需要 trace」不代表可以真的不 trace, 因为用户的代码还是一行行给 Python 来跑的. 但是 TorchDynamo 又来了: CPython 到底跑什么 bytecode 是可以被它换掉的!
因此它可以做到这么一件事: 当用户 call 一个被 capture 过的模型的时候, 模型里大部分 Python 代码都相当于不存在了, 连 symbolic execution 的 overhead 都没有, 而被换成了编译后的 native code. 这一点在以前所有的 partial graph capture 的方案里是做不到的:
-
LazyTensor 即使编译过的 graph 也要每次重新在 Python 里 trace 一遍, 才能发现「哦, 这个 graph 我曾见过的」.
-
@torch.jit.script,@tf.function,@jax.jit可以把装饰的 Python code 换成编译后的, 但是这都依赖用户把这个 subgraph refactor 出来放到一个单独的函数里. 而 TorchDynamo 是全自动不需要用户改代码的. -
这种 refactor 除了增加额外的工作量之外, 还可能与用户的代码结构冲突, 因为 「用来编译的graph的边界」与「用户代码需要的抽象边界」很可能不 match: 例如用户本来希望写三个函数, 但是最佳的优化是把其中两个半函数变成一个 graph, 这会让用户很尴尬.
这只是一个最直接的例子. 由于能够读写 bytecode, 理论上 TorchDynamo 能 access 更多 LazyTensor 根本没有的信息, 做更多事情(后面会提到). 而读写 bytecode 的难度比 source code要低不少, 所以成为了一个可行的方案.
到这里, 有的人可能会说, 上面提到的东西对 whole-graph capture 没太大用啊. 我觉得确实是这样: TorchDynamo 是一个对 partial-graph capture 追求极致的方案, 能够对几乎所有的 Python 实现的模型开箱即用有加速, 不用改代码 -- 前提是还要跑 Python 作为 fallback. 但是部署一般需要的是 whole-graph capture, 整个模型在一个 graph 里不能用 Python.
用 tracing 做 whole-graph capture 的前提是用户要在 Python 代码里避免所有不能被 trace 的东西, 最常见的用户要做的三件事是: 使用 symbolic shape, 使用 symbolic control flow, 禁用除了当前 tensor library之外的所有其他 library. 如果用户做到了这些, 那只要一个普通的 symbolic tracing 就能 capture 到完整的 graph 了, 不需要 TorchDynamo 这么复杂的机制. TorchDynamo 可能可以略微简化用户做这些的工作量, 但我感觉不会有本质不同.
我个人的观点是, 从实用角度出发, 要求用户做上面几件事不算是太复杂的要求: 禁用其他 library 理所应当就不说了; 即使今天PyTorch还没有很好的 symbolic {shape, control flow}, 但是只要用@torch.jit.script_if_tracing来处理少量的 symbolic shape 和 symbolic control flow, 大多数模型都是可以正确的被torch.jit.trace capture的. Meta 应该有几十上百个 vision 模型实现在 detectron2/d2go 里, 目前基本都是走这条路部署的. (我另有篇文章介绍这里面的细节)
TensorFlow 的 whole-graph capture 就简单了: TF 从第一天就有很好的 symbolic shape 和 symbolic control flow, 用就完了。tf.autograph甚至还自动化了一部分 control flow 的改写工作。
所以, 用户少量改代码仍然是必须的. 当然, TorchDynamo 毕竟有着"改变用户要跑的 bytecode" 的超能力. 所以如果愿意的话, 理论上可以让用户的 whole-graph capture 工作变的更简单. 例如:
-
模型中间的一些像
if x.shape[0] > 100的分支, 有的可以通过 shape inference 等价转移到模型开头的. 这样的话就可以 capture 到更大的没有分支的 subgraph. 这件事在 TorchDynamo 里现在叫做 "guard". -
理论上可以把 python control flow 自动替换成 symbolic 的, 类似
tf.autograph做的事情, 只不过输入是 bytecode 而不是 source code.
目前 TorchDynamo 的 "nopython" 模式就是 whole-graph capture 了. 不过似乎还不是工作重心 (以下引用来自这个 design doc):
PT2 will provide infrastructure for a no python export mode for edge and performance sensitive serving cases. The PT2 team won’t drive this end to end stack, but we will keep a feedback loop with the teams in charge of this and ensure the components we build are reusable in these situations.
不过与此同时, PyTorch 2.0 最近在完善 symbolic shape 的支持; functorch 里也加入了少量 control flow operator. 这算是利好 whole-graph capture 的消息.
总的来说, TorchDynamo 由于在 bytecode 层面做文章, 能做到一些其他方案做不到的事情. 它的优点主要为 partial graph capture 服务: 让用户的 Python 模型代码在0修改的情况下就能 capture 并获得加速. 这体现了 PyTorch 对于 "Python first" 哲学的执念.. 这种执着是否有必要, 见仁见智.
TorchDynamo 的主要优势来自于对 bytecode 的读写. JIT scripting compiler 的失败表明在 source code level 做不了太多事, TorchDynamo 能在 bytecode level 做事情确实很巧妙. 不过, 要完整的复刻 CPython bytecode interpreter, 它的工作量, 维护难度(以及出 bug 的概率)都是不小的.
另外, TorchDynamo 对 whole-graph capture 没有很大的帮助. 对于复杂的模型, 用户该做的改写还是得做. 不过我估计2.0至少能对「用户该做什么」有个清晰的说法.
当然, 最后 PT2 到底能不能把 compiler 做好, 还有很多其他因素: IR 怎么设计, 何时specialize/recompile, 各种 backend 不同的特性, 等等. 比如 TorchDynamo 和 LazyTensor 使用的 IR 其实也不一样. 但是本文只讨论 graph capture; 其他问题就不提了.
编辑于 2022-12-13 13:22
(文章观点源自网络,侵删)

