
- 11-基于ArUco码的标记与检测
- 2C++函数参数的默认值_c++函数形参如果有默认值
- 3RabbitMQ优化消息阻塞系列(二)参数调优_rabbit:listener-container 参数
- 4哪个学校计算机每年招不满,这两所211大学,录取分数线低,却常年招不满生,适合考生捡漏...
- 5JsonObject判断是否为空_jsonobject判断为空
- 6java实现中文分词
- 7Git的rebase命令说明_linux git rebase
- 8HTML5期末大作业:甜品奶茶网站设计——甜品奶茶店(19页) HTML5网页设计成品_学生DW静态网页设计_web课程设计网页制作_奶茶网页设计
- 9C++刷题--选择题4_c++ 函数 只用一个默认值
- 10IT运维工程师职业发展与出路
为什么大模型训练需要GPU,以及适合训练大模型的GPU介绍_为什么用gpu 模型训练
赞
踩
文章目录
前言
今天偶然看到一篇关于介绍GPU的推文,我们在复现代码以及模型训练过程中,GPU的使用是必不可少的,那么大模型训练需要的是GPU,而不是CPU呢。现在市面上又有哪些适合训练的GPU型号呢,价格如何,本文将会将上述疑问的回答一一分享给大家。
1、为什么大模型训练需要GPU,而非CPU
总的来说,选择GPU而非CPU进行大模型训练的主要原因是因为GPU在并行处理能力、高吞吐量和针对机器学习任务的优化方面的优势。这使得GPU成为训练复杂和大规模机器学习模型的首选。
并行处理能力:GPU拥有成千上万个较小、更专用的核心,这使得它们能够同时处理多个任务。这种并行处理能力使GPU非常适合执行机器学习和深度学习算法中的大量矩阵和向量运算。相比之下,CPU(中央处理单元)核心数量较少,但每个核心的通用计算能力更强,适用于需要大量逻辑和顺序处理的任务。
高吞吐量:GPU能够提供更高的吞吐量,这意味着它们可以在较短的时间内处理更多的数据。这对于训练大型模型尤其重要,因为这些模型通常需要处理巨大的数据集,并执行数以亿计的运算。
大规模计算:GPU最初是为了处理复杂的图形和图像处理任务而设计的,这些任务需要大量的计算和数据处理。这些设计特性也让GPU非常适合于训练大型机器学习模型,因为这些模型需要进行大量的数学运算,特别是在训练神经网络时。
优化的库和框架:许多深度学习框架和库,如TensorFlow、PyTorch等,都针对GPU进行了优化,以充分利用其并行处理能力。这些优化包括专门的算法和硬件加速技术,可以显著加快模型训练过程。
成本:虽然高端GPU的初始投资可能比CPU高,但在处理大规模机器学习任务时,GPU因其较高的效率和速度,可以提供更好的成本效益。尤其是在云计算环境中,用户可以根据需要临时租用GPU资源,进一步提高成本效益。
2、现在都有哪些合适的GPU适合训练,价格如何
现在GPU可谓是各大厂商都在疯抢,并不是你有钱就可以买的到的,并且现在大规模训练主要还是英伟达(NVIDIA)系列为主,受中美关系影响,更难搞到好的GP。下面介绍几款常用的GPU:
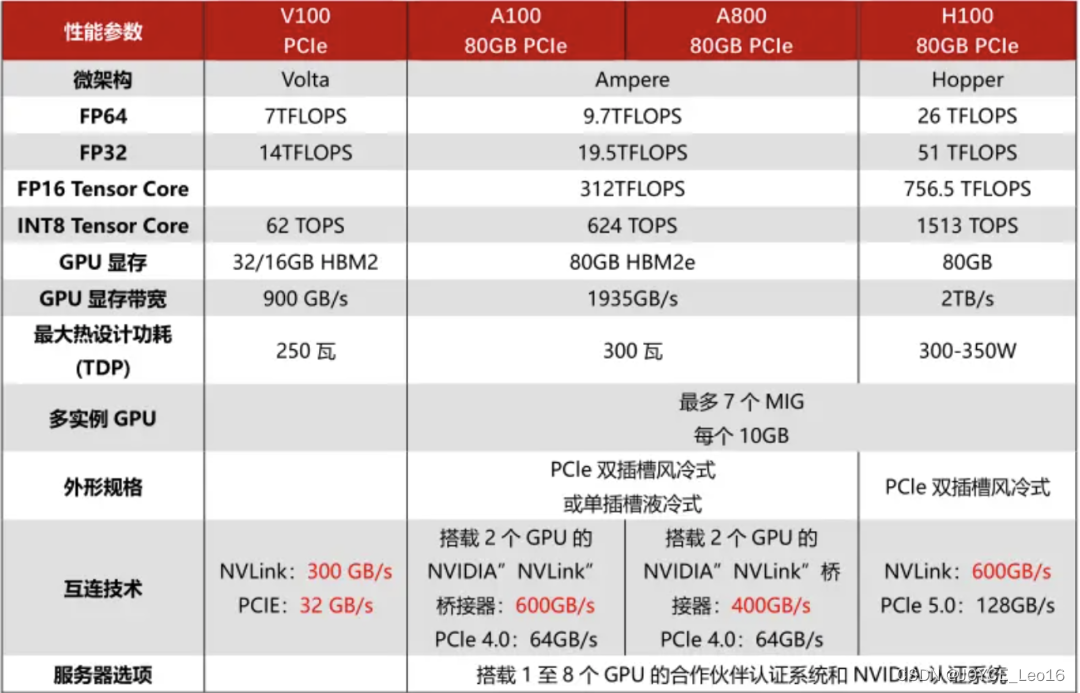
A100:非常适合大规模并行计算任务和大模型训练,现在用的最多的卡之一,性价比高,1.5w美元左右,但是溢价严重,人民币价格区间10w~20w,运气好的话10w左右可以拿下。(价格仅供参考,购买时因素很多,只能提供通用的价格区间,后面GPU价格时也是一样,只提供价格区间)。

H100:A100的下一代产品,提供了更高的性能和更快的NVLink通信速度,特别针对人工智能、机器学习和深度学习进行了优化。价格是A100的2倍左右,售价是2.5w~3w美元之间,但是溢价严重,3.5w美元都不一定能拿下来,所以参考价格区间,25w~35w人民币。
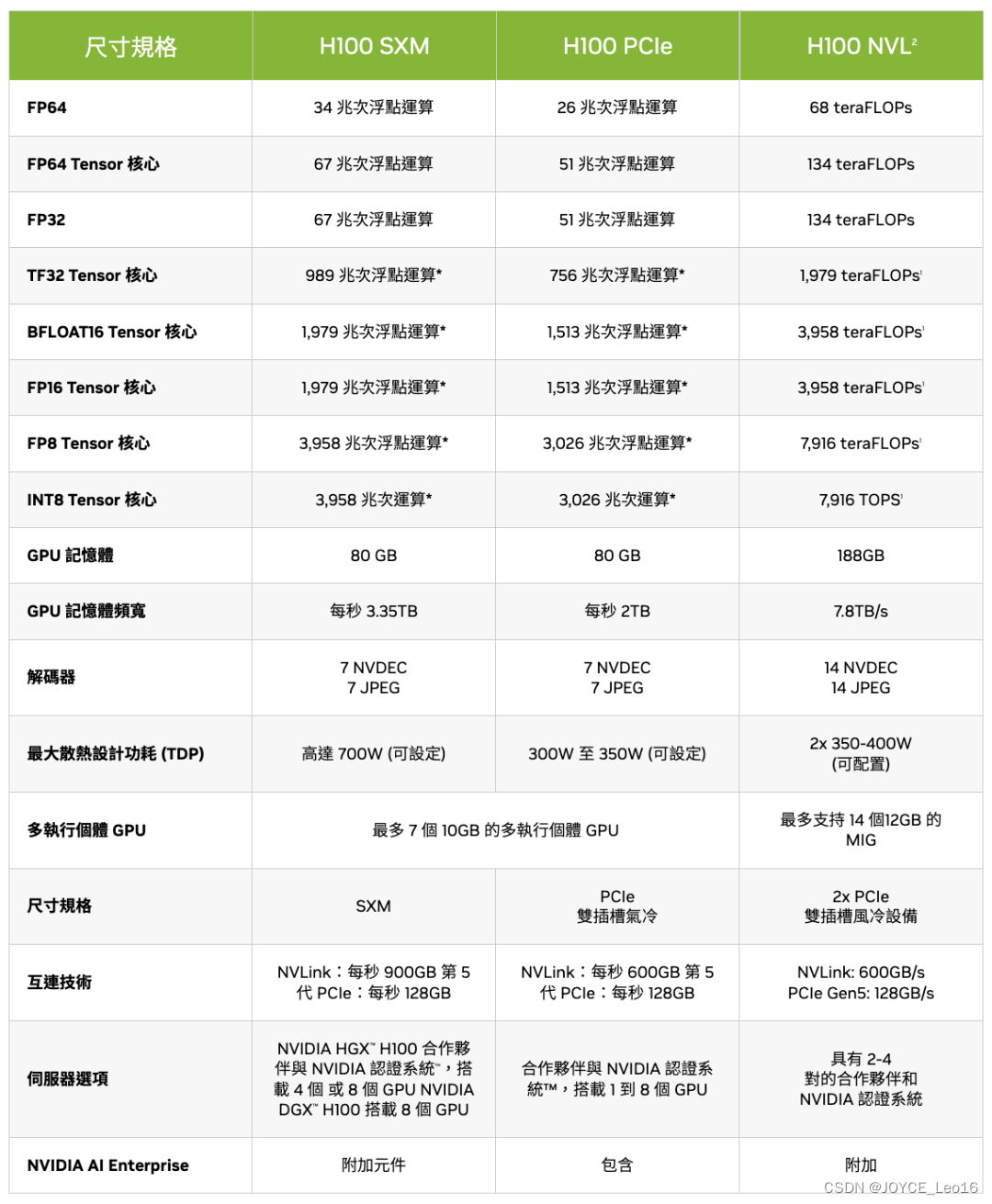
A100和H100,因为政治因素。去年受到了限制,为此NVIDIA推出了替代型号专供中国市场,A100的替代型号是A800,在已有A100的基础上将NVLink高速互连总线的带宽从600GB/s降低到400GB/s,其他完全不变。H100的替代型号是H800,应该是跟A800一样降低了带宽。
A800:具体价格不明,但应该和A100差不多,预计10w~20w之间。
H800:具体价格不明,但是应该25w起,估计在35w~45w之间。
V100:性能肯定不如上面提到的那四个(A100、H100、A800、H800),但是如果资金有限,V100也是一个不错的选择,32G版价格一般5w~8w。

整体对比如下图所示,性能上H100(或H800)> A100(或A800)> V100。
4090:最后再来说一下4090显卡,4090显卡训练大模型不行,因为大模型训练需要高性能的通信,但4090的通信效率太低,但是进行推理可以。价格一般在2w左右。
参考: 极客e家


