
- 1【开题报告】ssm电影推荐系统99182计算机毕业设计程序_电影推荐系统开题报告
- 2基于用户的相似性度量
- 3VBA自学笔记_type:=xlfilldefault
- 4【跟着江科大学Stm32】STM32F103C6T6_PWM控制直流电机_代码_stm32f103c6t6伺服源码
- 5网络工程师必备技术汇总_网络工程师掌握的技术
- 6【深度学习】LSTM实现情感分析 (Pytorch)
- 7Codeforces Round #742 Div.2 (A~E)题解_codeforces round #742 (div. 2) e
- 8大数据开发:Hadoop的开源架构实现_hadoop 主流开源云框架实验
- 9PDF 图片转文字_pdf图片转成文字版
- 10[数据结构]链表之单链表(详解)
期末作业|Python爬虫数据采集可视化分析项目完整版_python爬虫与可视化期末大项目word
赞
踩

这是我本学期的数据可视化期末作业,如果对您有帮助,给个关注吧!!
作品效果展示:
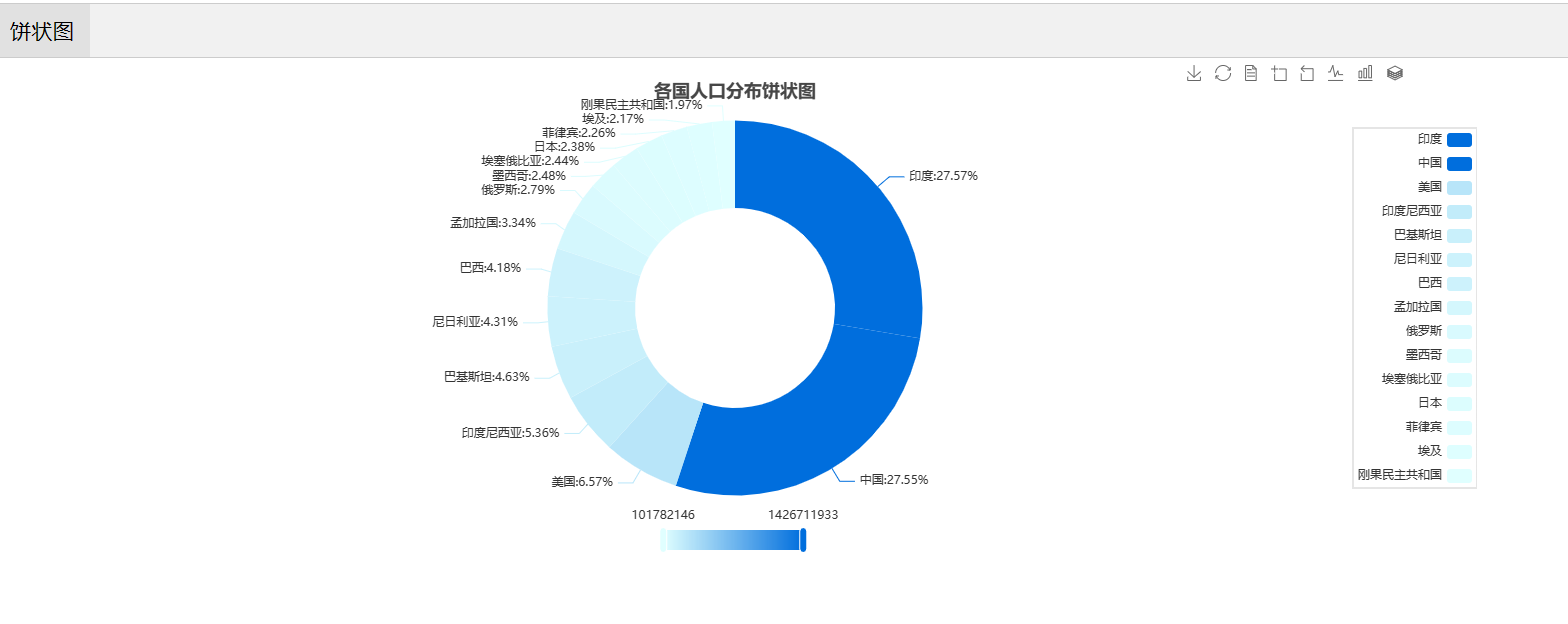
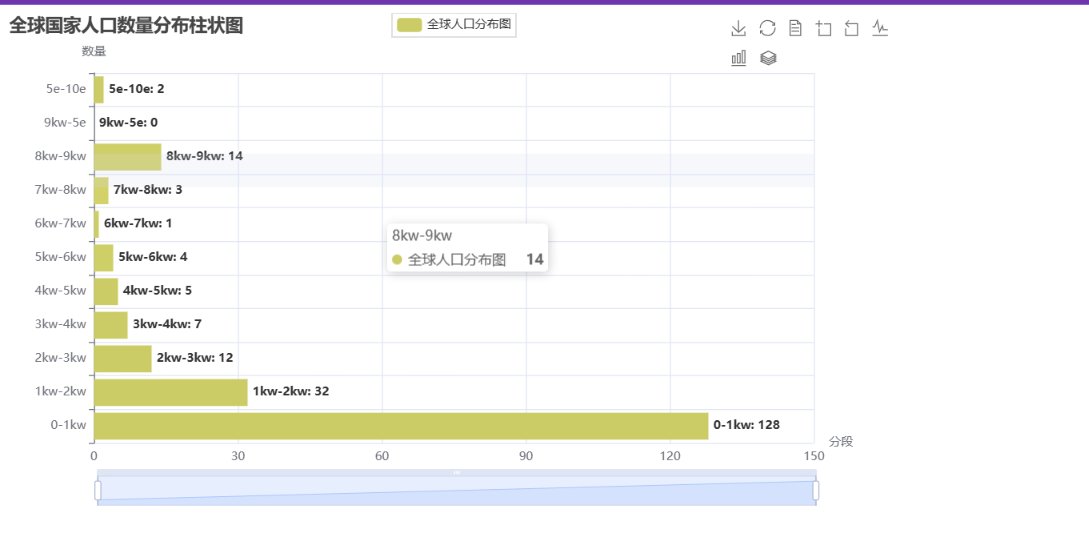
柱状图:
柱状图:
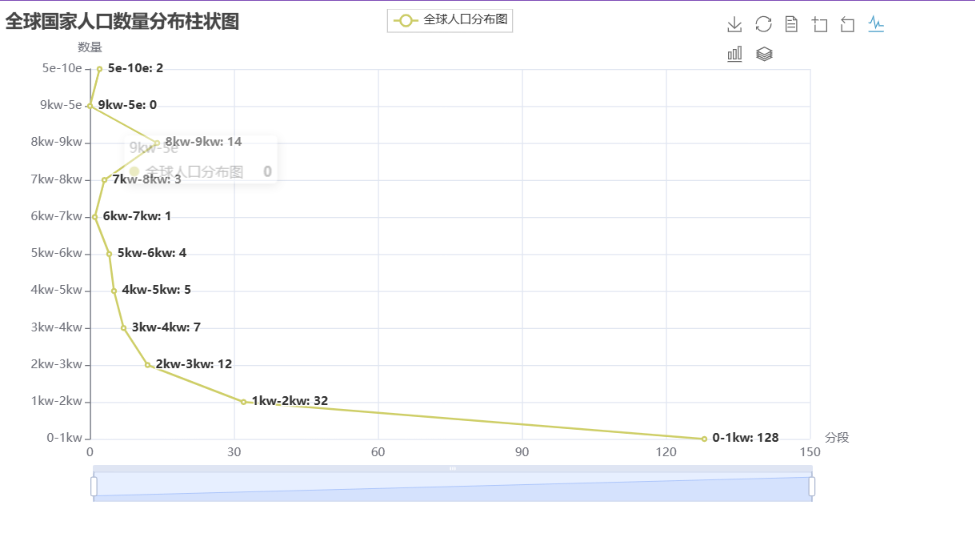
折线图:
折线图:
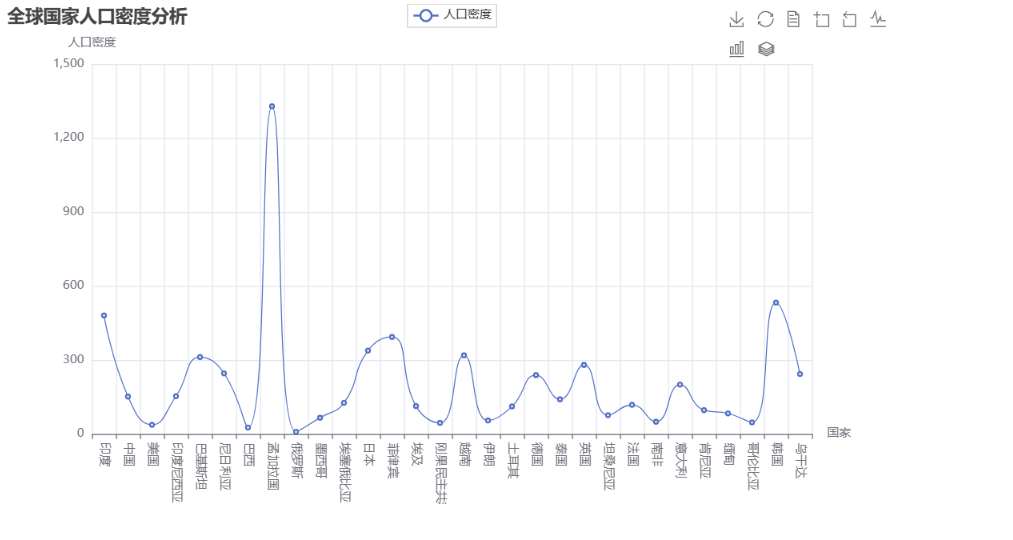
折线图:
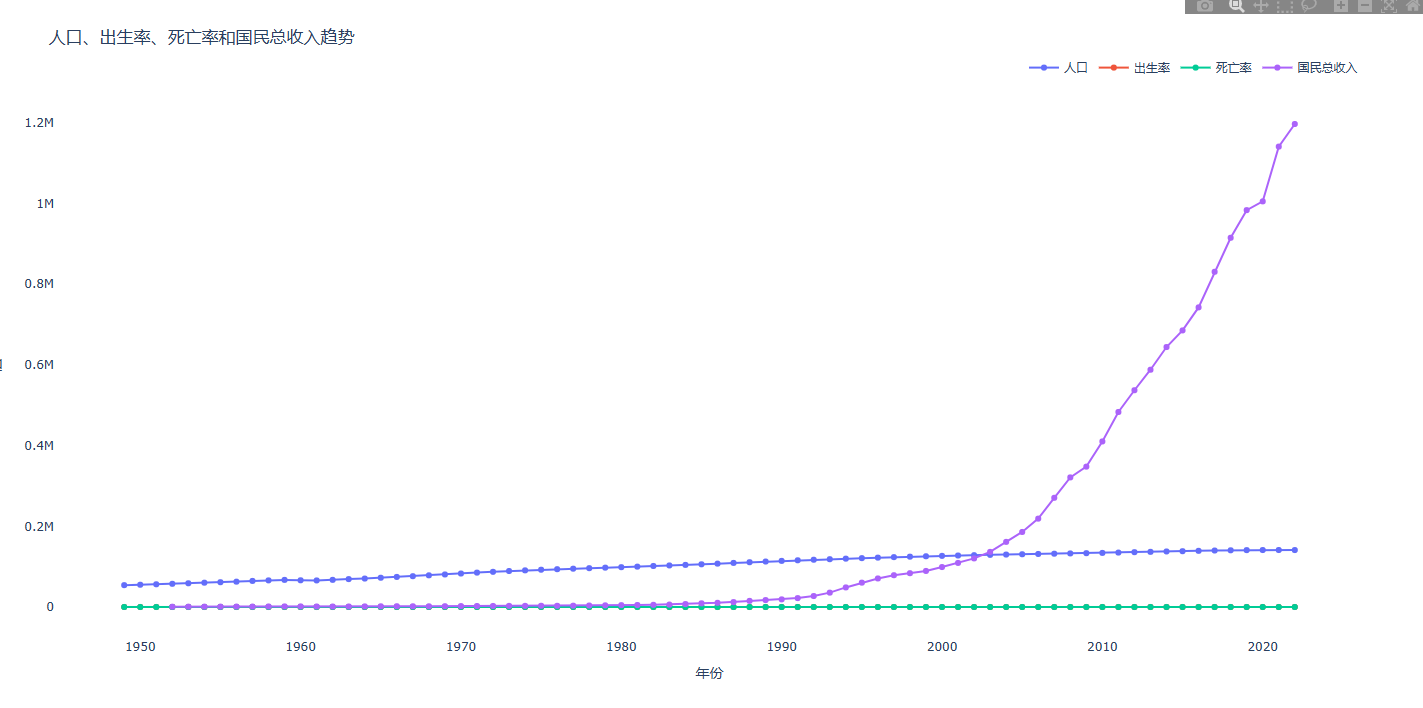
数据集:

总共三张表:进行数据分析
代码:
第一个数据集通过爬虫爬取:
获取数据代码:
import bs4 import pandas as pd import requests def head(url): header={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51' } reqs = requests.get(url,headers=header) return reqs def run(): global ws bank = [] # 世界排名 country = [] # 国家 num = [] # 人口基数 index = [] # 增长率 p = [] # 密度 for i in range(1,13): url = "https://web.phb123.com/city/renkou/rk_"+str(i)+".html" r = requests.get(url) html = bs4.BeautifulSoup(r.text.encode("utf-8"),"html.parser") # 获得排名 ranklist = html.find_all(class_="xh") for rank in ranklist: bank.append(rank.get_text('td')) # 获得国家名 namelist = html.find_all(class_="cty") for name in namelist: country.append(name.text.strip()) # 获得人口基数 for i in range(0,20): numlist = html.find_all('td')[2+5*i].text num.append(numlist) # 增长率 for i in range(0, 20): indexlist = html.find_all('td')[3 + 5 * i].text index.append(indexlist) # 人口密度 for i in range(0, 20): plist = html.find_all('td')[4 + 5 * i].text p.append(plist) data = { "排行榜": bank, "国家": country, "人口": num, "增长率": index, "密度": p } df = pd.DataFrame(data) df.to_excel("世界人口数据1.xlsx",index=False) if __name__ == '__main__': run()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
处理数据:
import pandas as pd
# 加载原始的 Excel 文件数据
df = pd.read_excel('世界人口数据1.xlsx')
# 进行数据预处理
df = df.dropna(subset=['国家']) # 去除国家为空的行
df = df[df['人口'] != 0] # 去除人口为0的行
df = df[df['增长率'] != '0.00%'] # 去除增长率为0的行
df = df[df['密度'] != 0] # 去除密度为0的行
# 存储处理后的数据到新的 Excel 文件
df.to_excel('处理后的世界人口数据.xlsx', index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
需要数据集的可以微信加我获取
完整数据爬取代码和数据可视化代码可加我文章下方微信获得,一小时内好友通过
程序设计报告:
程序结构说明文档:
对三个数据集进行分析,三个数据集来源:
通过爬虫爬取世界人口国家排名:世界国家人口数据数据集
剩余两个是网上下载的数据集,一个中国近几十年人口数量数据集,
另一个是医疗消费水平数据集。
第一个数据集:世界国家人口数据数据集文档说明:
程序详细设计
(1)程序编写思路流程图:
(2)设计代码实现:
爬虫技术:python
数据存储:xlsx文件
数据可视化处理:pyechatrs模块
1.通过python对所需要的数据进行爬取并进行存储
目标网页内容:
相关模块导入:
import bs4
import pandas as pd
import requests
数据爬取过程:伪装请求网址请求头
def head(url):
header={
‘User-Agent’:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54’
}
reqs = requests.get(url,headers=header)
return reqs
通过BeautifulSoup模块进行所求标签进行锁定和数据处理并存储
def run():
global ws
bank = [] # 世界排名
country = [] # 国家
num = [] # 人口基数
index = [] # 增长率
p = [] # 密度
for i in range(1,8): url = "https://web.phb123.com/city/renkou/rk_"+str(i)+".html" r = requests.get(url) html = bs4.BeautifulSoup(r.text.encode("utf-8"),"html.parser") # 获得排名 ranklist = html.find_all(class_="xh") for rank in ranklist: bank.append(rank.get_text('td')) # 获得国家名 namelist = html.find_all(class_="cty") for name in namelist: country.append(name.text.strip()) # 获得人口基数 for i in range(0,20): numlist = html.find_all('td')[2+5*i].text num.append(numlist) # 增长率 for i in range(0, 20): indexlist = html.find_all('td')[3 + 5 * i].text index.append(indexlist) # 人口密度 for i in range(0, 20): plist = html.find_all('td')[4 + 5 * i].text p.append(plist) data = { "排行榜": bank, "国家": country, "人口": num, "增长率": index, "密度": p } df = pd.DataFrame(data) df.to_json("世界人口数据.xls",encoding="utf-8")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
2.通过pyecharts模块对采集的数据进行可视化处理 相关模块导入: import re import xlrd from pyecharts import options as opts from pyecharts.charts import Map,
Bar, Pie, Page, Line, Geo 首先处理保存在xls文件内容的数据并将其转化为字典格式
首先处理数据转化为字典格式
表格数据提取 data=xlrd.open_workbook(‘世界人口数据.xls’) table = data.sheet_by_name(‘Sheet1’) row_Num=table.nrows col_Num= table.ncols
s=[] key = table.row_values(0) j = 1 for i in range(row_Num-1):
d = {}
values = table.row_values(j)
for x in range(col_Num):
# 把key值对应的value赋值给key,每行循环
d[key[x]] = values[x]
j += 1
# 把字典加到列表中
s.append(d) 进行可视化数据分析:柱状图折线图效果展示:
饼状图效果展示:
(3)疑难问题处理:
1.难点:多页爬取数据,页面翻页 通过观察网页的规律:通过改变url的规律来完成翻页 for i in range(1,8):
url = “https://web.phb123.com/city/renkou/rk_”+str(i)+“.html”
r = requests.get(url)
html = bs4.BeautifulSoup(r.text.encode(“utf-8”),“html.parser”)
2.难点:对特定标签的数据进行采集和爬取 目标数据分析:通过规律对所需内容进行筛选,并添加进入列表 # 获得排名
ranklist = html.find_all(class_=“xh”)
for rank in ranklist:
bank.append(rank.get_text(‘td’))
# 获得国家名
namelist = html.find_all(class_=“cty”)
for name in namelist:
country.append(name.text.strip())
# 获得人口基数
for i in range(0,20):
numlist = html.find_all(‘td’)[2+5*i].text
num.append(numlist)
# 增长率
for i in range(0, 20):
indexlist = html.find_all(‘td’)[3 + 5 * i].text
index.append(indexlist)
#人口密度
for i in range(0, 20):
plist = html.find_all(‘td’)[4 + 5 * i].text
p.append(plist)
3.难点:对列表数据写进xls文件 通过将列表数据转化成字典,写进存储文件中 data = {
“排行榜”: bank,
“国家”: country,
“人口”: num,
“增长率”: index,
“密度”: p } df = pd.DataFrame(data) df.to_json(“世界人口数据.xls”,encoding=“utf-8”)第二个数据集:一个中国近几十年人口数量数据集
折线图效果展示:
第三个数据集:医疗消费水平数据集
柱状图效果展示:

