
- 1基于SVD矩阵分解的用户商品推荐(python实现)_基于svd的推荐算法python代码
- 2搭建本地大模型,最简单的方法!效果直逼GPT_ollama下载
- 3树莓派学习(二)笔记本连接_树莓派网线连接上笔记本有什么反应
- 4StableDiffusion对图片进行高清、优化、放大_stablediffusion分辨率怎么调
- 5Android中的消息异步处理机制及实现方案
- 6使用libxml2对xml进行SAX读取_libxml2 sax
- 7Linux安装Python并部署Flask程序_linux flask python
- 8【MySQL】数据类型——MySQL的数据类型分类、数值类型、小数类型、字符串类型_mysql数值型
- 9基于web租车汽车租赁系统设计与实现_汽车租赁系统web
- 10【博学谷学习记录】超强总结,用心分享| hadoop上传和下载文件过程_如何上传文件到hadoop
模糊C-means聚类算法和K-means聚类算法_模糊聚类和kmeans聚类对比
赞
踩
一、模糊C-means聚类算法
1.简介
模糊c-均值聚类算法 fuzzy c-means algorithm (FCMA)或称( FCM)。在众多模糊聚类算法中,模糊C-均值( FCM) 算法应用最广泛且较成功,它通过优化目标函数得到每个样本点对所有类中心的隶属度,从而决定样本点的类属以达到自动对样本数据进行分类的目的。
2. 模糊C-means聚类应用背景
传统的聚类分析是一种硬划分(Crisp Partition),它把每个待辨识的对象严格地划分到某类中,具有“非此即彼”的性质,因此这种类别划分的界限是分明的。然而实际上大多数对象并没有严格的属性,它们在性质和类属方面存在着中介性,具有“亦此亦彼”的性质,因此适合进行软划分。Zadeh提出的模糊集理论为这种软划分提供了有力的分析工具,人们开始用模糊方法来处理聚类问题,并称之为模糊聚类分析。模糊聚类得到了样本属于各个类别的不确定性程度,表达了样本类属的中介性,建立起了样本对于类别的不确定性的描述,能更客观地反映现实世界,从而成为聚类分析研究的主流。
在基于目标函数的聚类算法中模糊C均值(FCM,Fuzzy C—Means)类型算法的理论最为完善,应用最为广泛。
3.模糊C均值聚类的准则

4.模糊C均值算法步骤
(1)设定聚类数目c和加权指数b:
J . C. Bezdek根据经验,认为b 取2 最合适。
Cheung和Chen从汉字识别的应用背景得出b的最佳取值应在1.25~1.75之间。
Bezdek和Hathaway等人从算法收敛性角度着手,得出b 的取值与样本数目n有关的结论,建议b的取值要大于n/(n-2)。
Pal等人从聚类有效性方面的实验研究得到b的最佳选取区间为[1.5, 2.5],在不做特殊要求下可取区间中值b = 2。

用当前的隶属度函数按下式更新计算各类聚类中心:
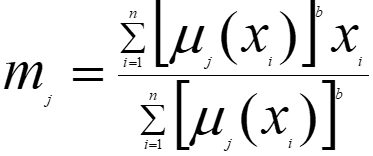
当模糊C均值算法收敛时,就得到了各类的聚类中心和各个样本对于各类的隶属度值,从而完成了模糊聚类划分。如果需要,还可以将模糊聚类结果进行解模糊,即用一定的规则把模糊聚类划分转化为确定性分类。
5.模糊C均值聚类的MATLAB实现
(一)主要代码
这里对酒瓶颜色进行分类。下面介绍其重要程序代码:
1)MATLAB模糊C均值数据聚类识别函数
在MATLAB中ÿ

