
- 1LangChain的Memory的4种用法(一)_langchain + memory
- 2独家 | 从零开始用python搭建推荐引擎(附代码)
- 3[LangChain核心模块]模型的输入和输出->Prompts_langchain怎么选择prompt
- 4这7本书Web安全的必须看(附全套PDF)_web安全攻防渗透测试实战指南 pdf
- 5Android系统中Thread,Looper,MessageQueue,Message,Handler相互关系的简单分析_android server new thread looper handlemessage
- 6Linux的虚拟环境下安装GPU版本的torch、torchaudio、torchvision详细过程_linux安装torch
- 7几个数据采集工具分享,都是免费的
- 8Unity 踩坑笔记 两种Animation Clip_unity 给animator里的添加animationclip
- 9蓝屏代码大全(留着自己看)
- 10api-ms-win-core-file-l1-1-0.dll文件找不到的完美解决方法_api-ms-win-core-l1-1-0.dll 丢失
利用LSTM实现预测时间序列(股票预测)_# 将前面的prev_days_for_train天的数据作为输入,并且要记得将self.train
赞
踩
1. 作者介绍
糜红敏,男,西安工程大学电子信息学院,2019级硕士研究生,张宏伟人工智能课题组。
研究方向:机器视觉与人工智能。
电子邮件:1353197091@qq.com
2. tushare 简介
Tushare是一个免费、开源的python财经数据接口包。主要实现对股票等金融数据从数据采集、清洗加工到数据存储的过程,能够为金融分析人员提供快速、整洁、和多样的便于分析的数据,为他们在数据获取方面极大地减轻工作量,使他们更加专注于策略和模型的研究与实现上。考虑到Python pandas包在金融量化分析中体现出的优势,Tushare返回的绝大部分的数据格式都是pandas DataFrame类型,非常便于用pandas、NumPy、Matplotlib进行数据分析和可视化。
更详细的介绍http://tushare.org/index.html#id3
通过tushare接口下载下来的部分数据的可视化如图所示:
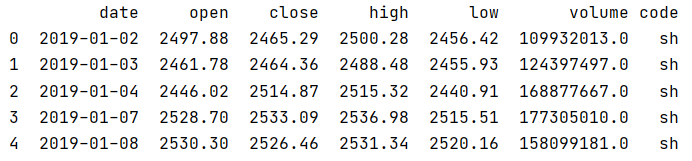

3. LSTM简介
3.1 循环神经网络 (Recurrent Neural Networks)
人对一个问题的思考不会完全从头开始。比如你在阅读本片文章的时,你会根据之前理解过的信息来理解下面看到的文字。在理解当前文字的时候,你并不会忘记之前看过的文字,从头思考当前文字的含义。
传统的神经网络并不能做到这一点,这是在对这种序列信息(如语音)进行预测时的一个缺点。比如你想对电影中的每个片段去做事件分类,传统的神经网络是很难通过利用前面的事件信息来对后面事件进行分类。
而循环神经网络(RNN)可以通过不停的将信息循环操作,保证信息持续存在,从而解决上述问题。RNN如下图所示:(原文来自这里)
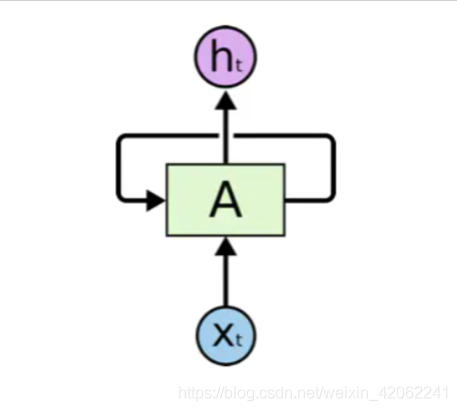
可以看出A是一组神经网络(可以理解为一个网络的自循环),它的工作是不停的接收 Xt 并且输出 ht。从图中可以看出A允许将信息不停的再内部循环,这样使得它可以保证每一步的计算都保存以前的信息。
更好的理解方式,将RNN的自循环结构展开,像是将同一个网络复制并连成一条线的结构,将自身提取的信息传递给下一个继承者,如下图所示。
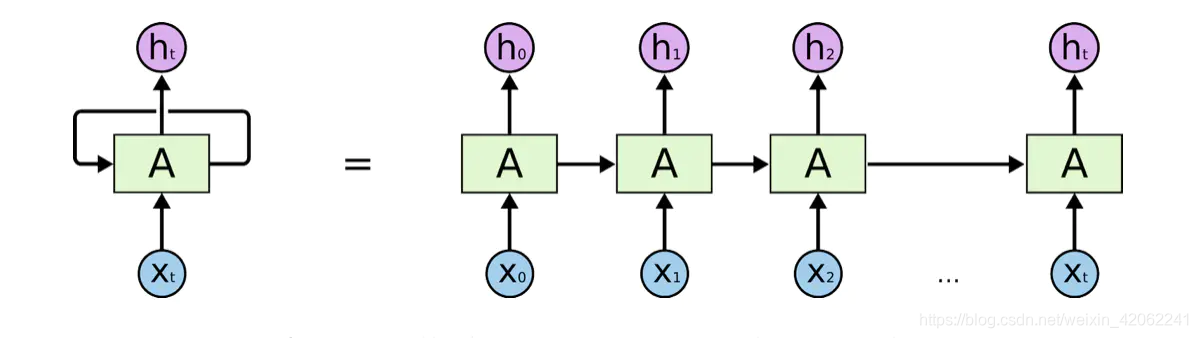
这样的一条链状神经网络代表了一个递归神经网络,可以认为它是对相同神经网络的多重复制,每一时刻的神经网络会传递信息给下一时刻。
递归神经网络因为具有一定的记忆功能,可以被用来解决很多问题,例如:语音识别、语言模型、机器翻译等。但是它并不能很好地处理长时依赖问题。
长时依赖是这样的一个问题,当预测点与依赖的相关信息距离比较远的时候,就难以学到该相关信息。例如在句子”我出生在法国,……,我会说法语“中,若要预测末尾”法语“,我们需要用到上下文”法国“。理论上,递归神经网络是可以处理这样的问题的,但是实际上,常规的递归神经网络并不能很好地解决长时依赖,好的是LSTM可以很好地解决这个问题。
3.2 LSTM网络
Long Short Term Memory networks(以下简称LSTMs),一种特殊的RNN网络,该网络设计出来是为了解决长依赖问题。该网络由 Hochreiter & Schmidhuber (1997)引入,并有许多人对其进行了改进和普及。他们的工作被用来解决了各种各样的问题,直到目前还被广泛应用。
所有循环神经网络都具有神经网络的重复模块链的形式。 在标准的RNN中,该重复模块将具有非常简单的结构,例如单个tanh层。标准的RNN网络如下图所示
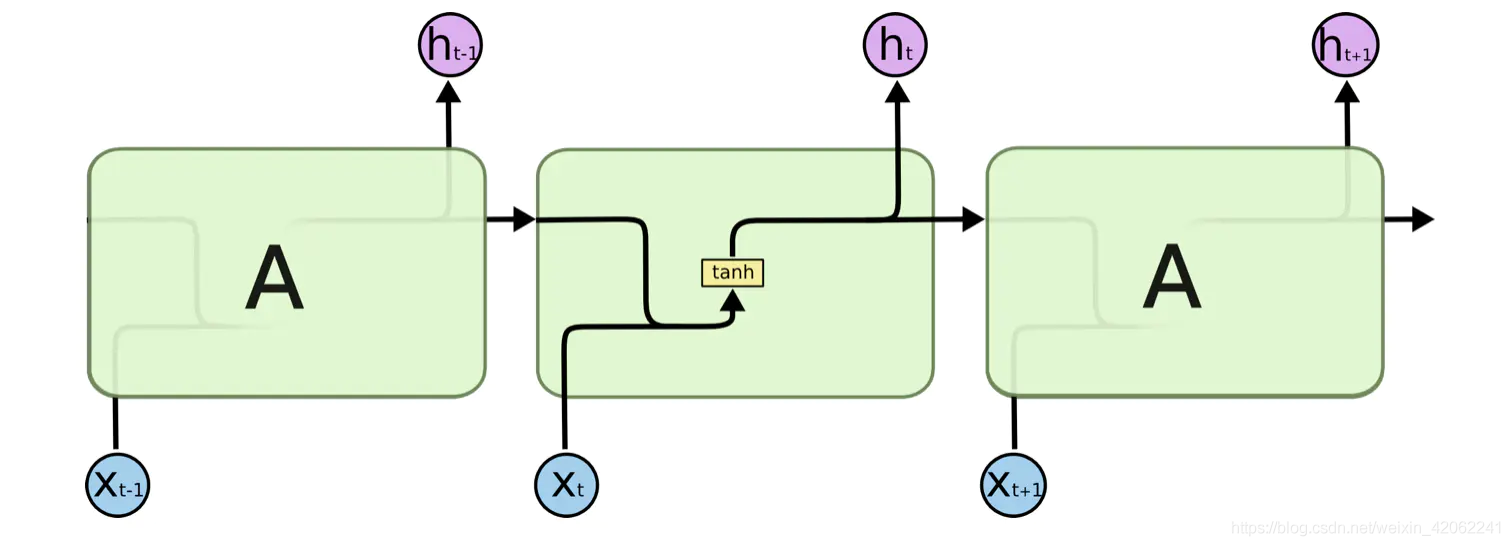
LSTM也具有这种链式结构,但是它的重复单元不同于标准RNN网络里的单元只有一个网络层,它的内部有四个网络层。LSTM的结构如下图所示。
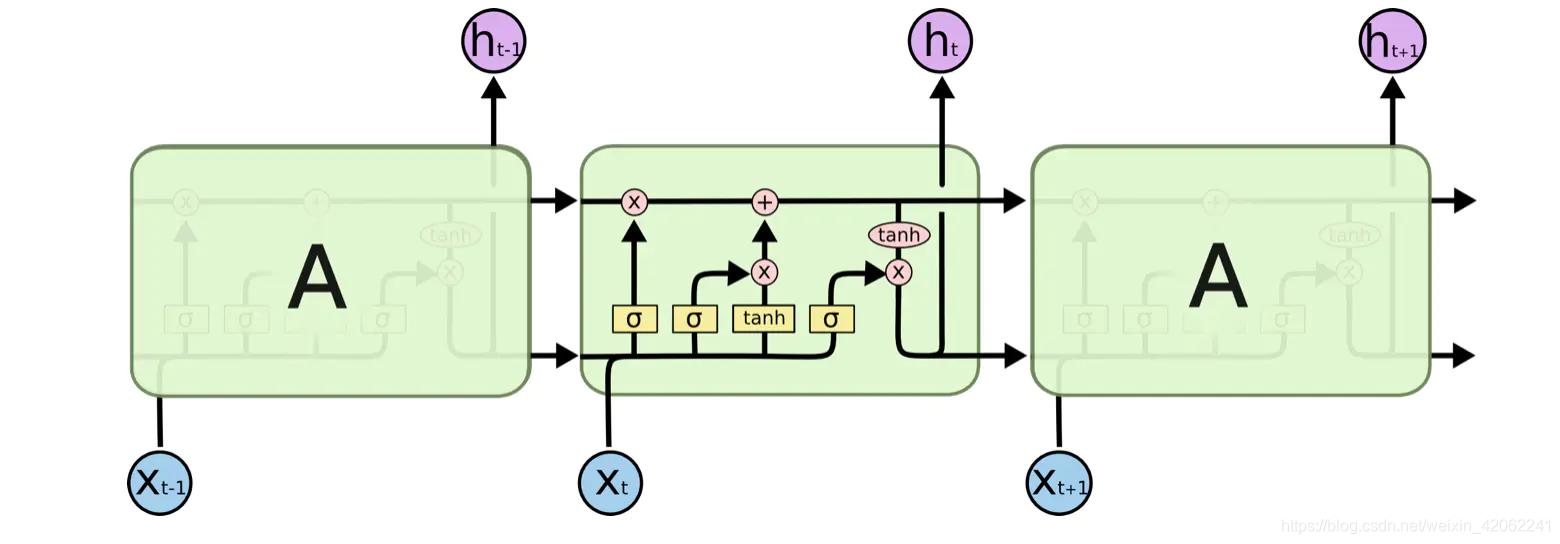
在解释LSTMs的详细结构时先定义一下图中各个符号的含义,符号包括下面几种

图中黄色类似于CNN里的激活函数操作,粉色圆圈表示点操作,单箭头表示数据流向,箭头合并表示向量的合并(concat)操作,箭头分叉表示向量的拷贝操作。
3.2.1 LSTM的核心思想
LSTM的核心是细胞状态,用贯穿细胞的水平线表示。
细胞状态像传送带一样。它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNN。细胞状态如下图所示:

LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息。
门能够有选择性的决定让哪些信息通过。其实门的结构很简单,就是一个sigmoid层和一个点乘操作的组合。如下图所示:
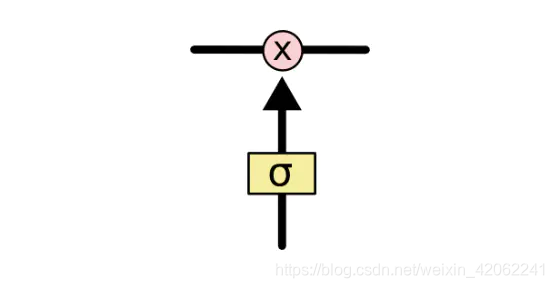
因为sigmoid层的输出是0-1的值,这代表有多少信息能够流过sigmoid层。0表示都不能通过,1表示都能通过。
一个LSTM里面包含三个门来控制细胞状态。
3.2.2 一步一步理解LSTM
前面提到LSTM由三个门来控制细胞状态,这三个门分别称为忘记门、输入门和输出门。下面一个一个的来讲述。
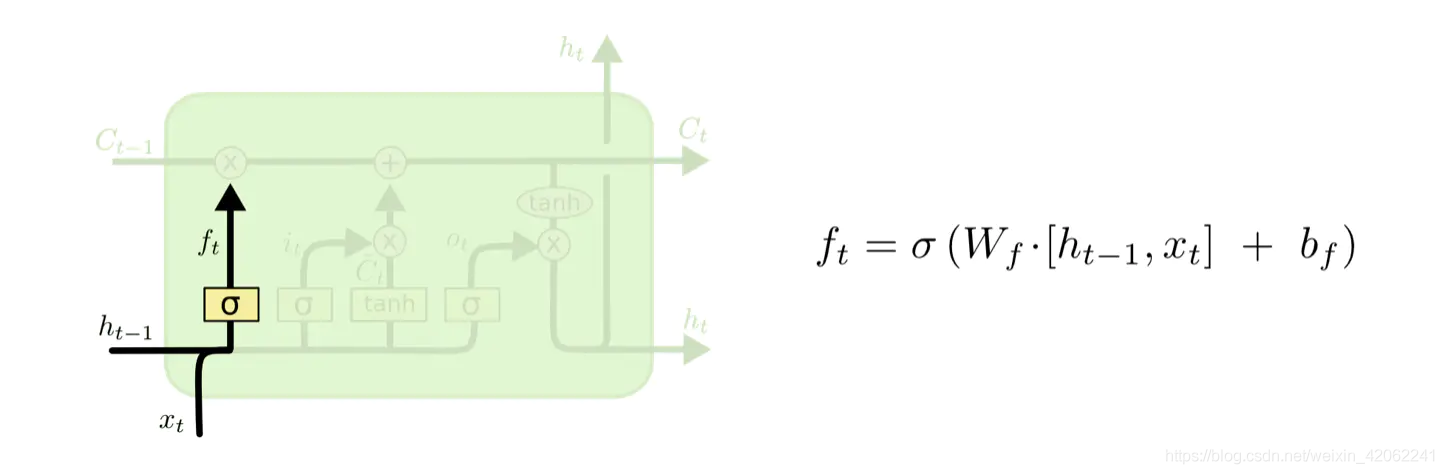
LSTM的第一步就是决定细胞状态需要丢弃哪些信息。这部分操作是通过一个称为忘记门的sigmoid单元来处理的。它通过查看
h
t
−
1
h_{t-1}
ht−1 和
x
t
x_t
xt 信息来输出一个0-1之间的向量,该向量里面的0-1值表示细胞状态
C
t
−
1
C_{t-1}
Ct−1中的哪些信息保留或丢弃多少。0表示不保留,1表示都保留。忘记门如下图所示:
下一步是决定给细胞状态添加哪些新的信息。这一步又分为两个步骤,首先,利用
h
t
−
1
h_{t-1}
ht−1 和
x
t
x_t
xt 通过一个称为输入门的操作来决定更新哪些信息。然后利用
h
t
−
1
h_{t-1}
ht−1 和
x
t
x_t
xt 通过一个tanh层得到新的候选细胞信息
C
t
~
\tilde{C_t}
Ct~,这些信息可能会被更新到细胞信息中。这两步描述如下图所示:
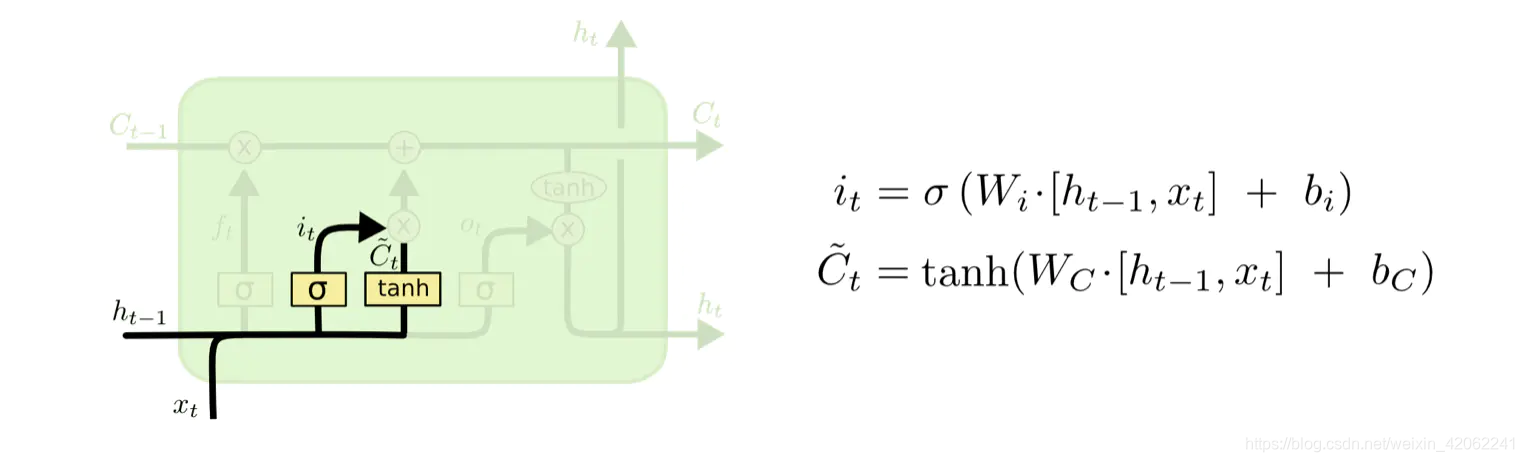
下面将更新旧的细胞信息
C
t
−
1
C_{t-1}
Ct−1,变为新的细胞信息
C
t
C_{t}
Ct。更新的规则就是通过忘记门选择忘记旧细胞信息的一部分,通过输入门选择添加候选细胞信息
C
~
t
\tilde C_{t}
C~t 的一部分得到新的细胞信息
C
t
C_{t}
Ct。更新操作如下图所示:
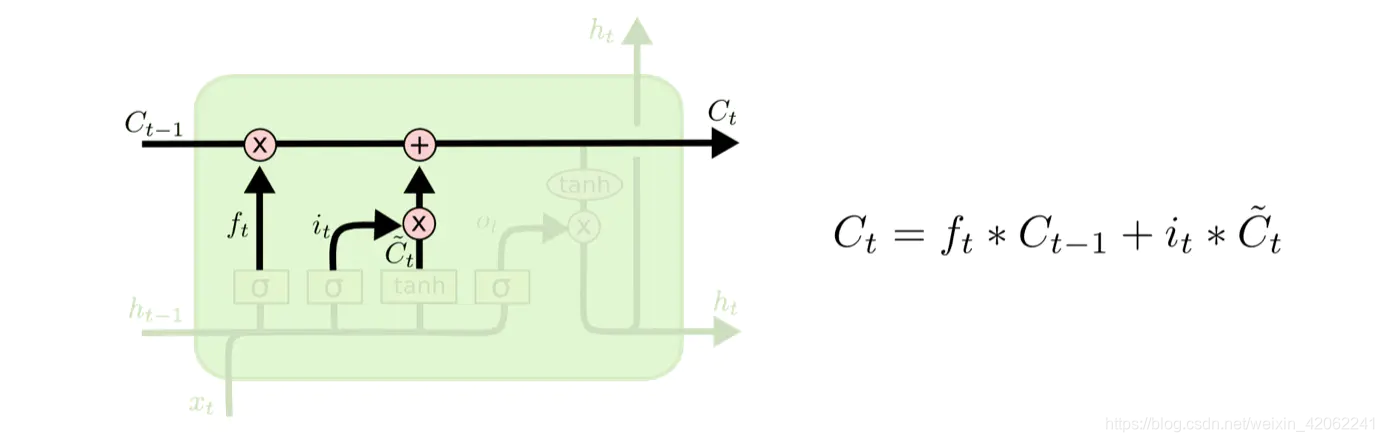 更新完细胞状态后需要根据输入的
h
t
−
1
h_{t-1}
ht−1 和
x
t
x_t
xt 来判断输出细胞的哪些状态特征,这里需要将输入经过一个称为输出门的sigmoid层得到判断条件,然后将细胞状态经过tanh层得到一个-1~1之间值的向量,该向量与输出门得到的判断条件相乘就得到了最终该RNN单元的输出。该步骤如下图所示:
更新完细胞状态后需要根据输入的
h
t
−
1
h_{t-1}
ht−1 和
x
t
x_t
xt 来判断输出细胞的哪些状态特征,这里需要将输入经过一个称为输出门的sigmoid层得到判断条件,然后将细胞状态经过tanh层得到一个-1~1之间值的向量,该向量与输出门得到的判断条件相乘就得到了最终该RNN单元的输出。该步骤如下图所示:
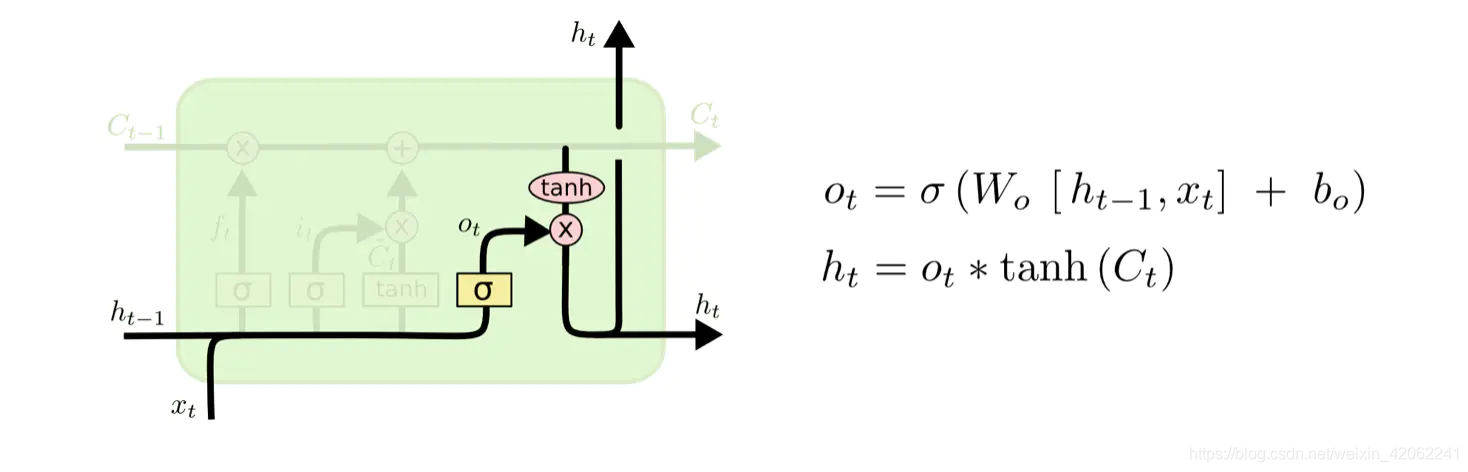
还是拿语言模型来举例说明,在预测动词形式的时候,我们需要通过输入的主语是单数还是复数来推断输出门输出的预测动词是单数形式还是复数形式。
4. 代码实现
4.1 导入相关资源包
这里除了安装深度学习框架pytorch之外,还需要安装matplotlib、numpy、pandas、tushare等库,安装步骤都很简单,只需输入pip3 install xxx(库名)即可。
import matplotlib.pyplot as plt
import numpy as np
import tushare as ts
import torch
from torch import nn
import datetime
import time
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4.2 定义模型结构
class LSTM_Regression(nn.Module): """ 使用LSTM进行回归 参数: - input_size: feature size - hidden_size: number of hidden units - output_size: number of output - num_layers: layers of LSTM to stack """ def __init__(self, input_size, hidden_size, output_size=1, num_layers=2): super().__init__() self.lstm = nn.LSTM(input_size, hidden_size, num_layers) self.fc = nn.Linear(hidden_size, output_size) def forward(self, _x): x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size) s, b, h = x.shape # x is output, size (seq_len, batch, hidden_size) x = x.view(s*b, h) x = self.fc(x) x = x.view(s, b, -1) # 把形状改回来 return x

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
4.3 制作数据集
def create_dataset(data, days_for_train=5) -> (np.array, np.array):
"""
根据给定的序列data,生成数据集
数据集分为输入和输出,每一个输入的长度为days_for_train,每一个输出的长度为1。
也就是说用days_for_train天的数据,对应下一天的数据。
若给定序列的长度为d,将输出长度为(d-days_for_train+1)个输入/输出对
"""
dataset_x, dataset_y= [], []
for i in range(len(data)-days_for_train):
_x = data[i:(i+days_for_train)]
dataset_x.append(_x)
dataset_y.append(data[i+days_for_train])
return (np.array(dataset_x), np.array(dataset_y))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.4 模型训练
可以根据自己的兴趣选择想要下载的时间范围,比如代码中选择了起始日期为2019年1月1日。另外训练集与测试集的长度也可以自由调节。
if __name__ == '__main__': t0 = time.time() data_close = ts.get_k_data('000001', start='2019-01-01', index=True)['close'].values # 取上证指数的收盘价的np.ndarray 而不是pd.Series data_close = data_close.astype('float32') # 转换数据类型 plt.plot(data_close) plt.savefig('data.png', format='png', dpi=200) plt.close() # 将价格标准化到0~1 max_value = np.max(data_close) min_value = np.min(data_close) data_close = (data_close - min_value) / (max_value - min_value) dataset_x, dataset_y = create_dataset(data_close, DAYS_FOR_TRAIN) # 划分训练集和测试集,70%作为训练集 train_size = int(len(dataset_x) * 0.7) train_x = dataset_x[:train_size] train_y = dataset_y[:train_size] # 将数据改变形状,RNN 读入的数据维度是 (seq_size, batch_size, feature_size) train_x = train_x.reshape(-1, 1, DAYS_FOR_TRAIN) train_y = train_y.reshape(-1, 1, 1) # 转为pytorch的tensor对象 train_x = torch.from_numpy(train_x) train_y = torch.from_numpy(train_y) model = LSTM_Regression(DAYS_FOR_TRAIN, 8, output_size=1, num_layers=2) loss_function = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), lr=1e-2) for i in range(1000): out = model(train_x) loss = loss_function(out, train_y) loss.backward() optimizer.step() optimizer.zero_grad() with open('log.txt', 'a+') as f: f.write('{} - {}\n'.format(i+1, loss.item())) if (i+1) % 1 == 0: print('Epoch: {}, Loss:{:.5f}'.format(i+1, loss.item()))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
4.5 测试与保存结果
model = model.eval() # 转换成测试模式 # model.load_state_dict(torch.load('model_params.pkl')) # 读取参数 # 注意这里用的是全集 模型的输出长度会比原数据少DAYS_FOR_TRAIN 填充使长度相等再作图 dataset_x = dataset_x.reshape(-1, 1, DAYS_FOR_TRAIN) # (seq_size, batch_size, feature_size) dataset_x = torch.from_numpy(dataset_x) pred_test = model(dataset_x) # 全量训练集的模型输出 (seq_size, batch_size, output_size) pred_test = pred_test.view(-1).data.numpy() pred_test = np.concatenate((np.zeros(DAYS_FOR_TRAIN), pred_test)) # 填充0 使长度相同 assert len(pred_test) == len(data_close) plt.plot(pred_test, 'r', label='prediction') plt.plot(data_close, 'b', label='real') plt.plot((train_size, train_size), (0, 1), 'g--') # 分割线 左边是训练数据 右边是测试数据的输出 plt.legend(loc='best') plt.savefig('result.png', format='png', dpi=200) plt.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.6 实验结果
训练结束后在终端会有如下显示:

实验结果会保存为.png格式的图片保存在代码的根目录下,如下图所示(线条颜色可根据个人喜好自己选择)。
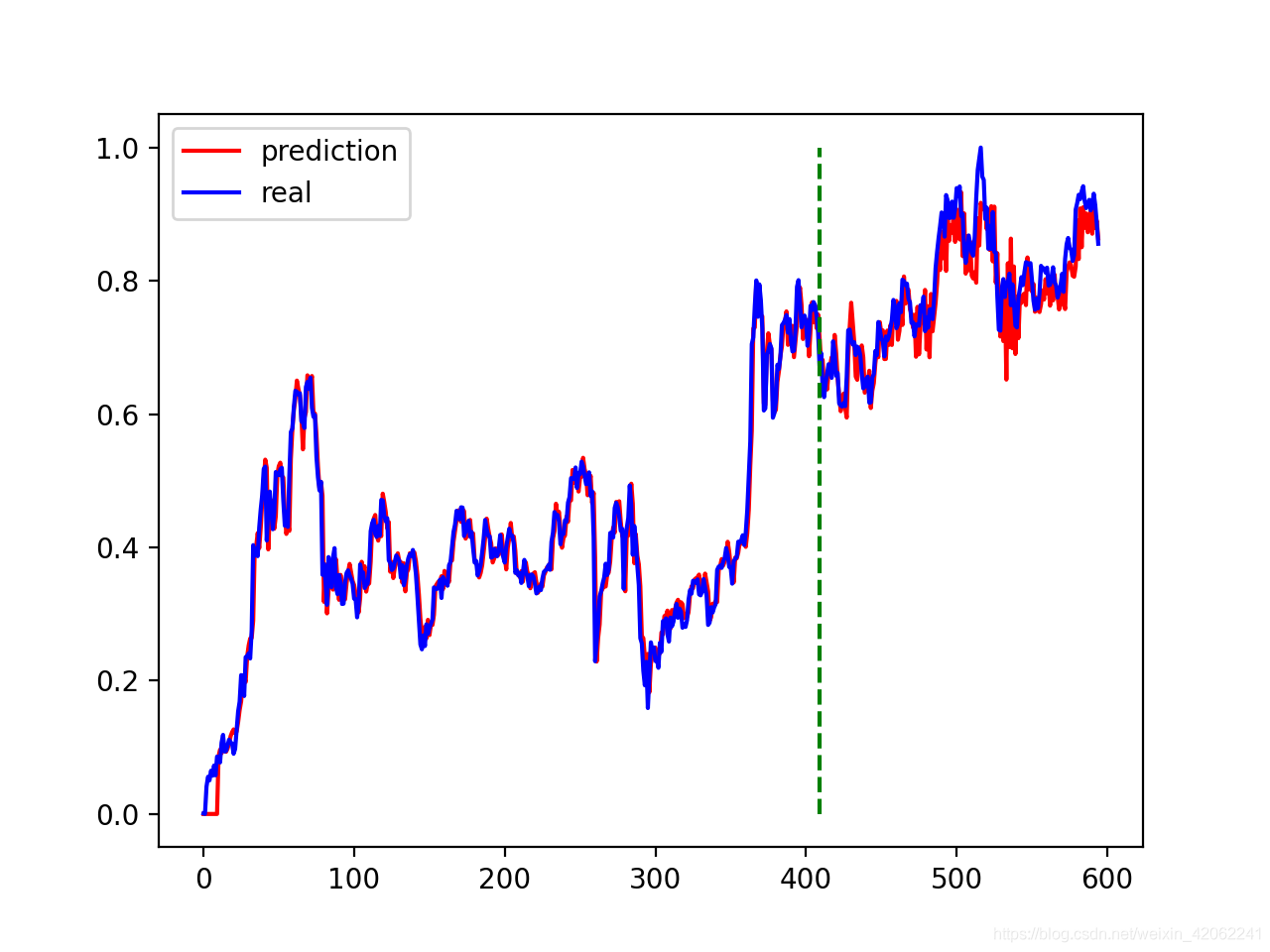
5. 完整代码
#!/usr/bin/python3 # -*- encoding: utf-8 -*- import matplotlib.pyplot as plt import numpy as np import tushare as ts import pandas as pd import torch from torch import nn import datetime import time DAYS_FOR_TRAIN = 10 class LSTM_Regression(nn.Module): """ 使用LSTM进行回归 参数: - input_size: feature size - hidden_size: number of hidden units - output_size: number of output - num_layers: layers of LSTM to stack """ def __init__(self, input_size, hidden_size, output_size=1, num_layers=2): super().__init__() self.lstm = nn.LSTM(input_size, hidden_size, num_layers) self.fc = nn.Linear(hidden_size, output_size) def forward(self, _x): x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size) s, b, h = x.shape # x is output, size (seq_len, batch, hidden_size) x = x.view(s*b, h) x = self.fc(x) x = x.view(s, b, -1) # 把形状改回来 return x def create_dataset(data, days_for_train=5) -> (np.array, np.array): """ 根据给定的序列data,生成数据集 数据集分为输入和输出,每一个输入的长度为days_for_train,每一个输出的长度为1。 也就是说用days_for_train天的数据,对应下一天的数据。 若给定序列的长度为d,将输出长度为(d-days_for_train+1)个输入/输出对 """ dataset_x, dataset_y= [], [] for i in range(len(data)-days_for_train): _x = data[i:(i+days_for_train)] dataset_x.append(_x) dataset_y.append(data[i+days_for_train]) return (np.array(dataset_x), np.array(dataset_y)) if __name__ == '__main__': t0 = time.time() #data_close = ts.get_k_data('000001', start='2019-01-01', index=True)['close'] # 取上证指数的收盘价 #data_close.to_csv('000001.csv', index=False) #将下载的数据转存为.csv格式保存 data_close = pd.read_csv('000001.csv') #读取文件 #df_sh = ts.get_k_data('sh', start='2019-01-01', end=datetime.datetime.now().strftime('%Y-%m-%d')) #print(df_sh.shape) data_close = data_close.astype('float32').values # 转换数据类型 plt.plot(data_close) plt.savefig('data.png', format='png', dpi=200) plt.close() # 将价格标准化到0~1 max_value = np.max(data_close) min_value = np.min(data_close) data_close = (data_close - min_value) / (max_value - min_value) dataset_x, dataset_y = create_dataset(data_close, DAYS_FOR_TRAIN) # 划分训练集和测试集,70%作为训练集 train_size = int(len(dataset_x) * 0.7) train_x = dataset_x[:train_size] train_y = dataset_y[:train_size] # 将数据改变形状,RNN 读入的数据维度是 (seq_size, batch_size, feature_size) train_x = train_x.reshape(-1, 1, DAYS_FOR_TRAIN) train_y = train_y.reshape(-1, 1, 1) # 转为pytorch的tensor对象 train_x = torch.from_numpy(train_x) train_y = torch.from_numpy(train_y) model = LSTM_Regression(DAYS_FOR_TRAIN, 8, output_size=1, num_layers=2) # 导入模型并设置模型的参数输入输出层、隐藏层等 model_total = sum([param.nelement() for param in model.parameters()]) # 计算模型参数 print("Number of model_total parameter: %.8fM" % (model_total/1e6)) train_loss = [] loss_function = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, betas=(0.9, 0.999), eps=1e-08, weight_decay=0) for i in range(200): out = model(train_x) loss = loss_function(out, train_y) loss.backward() optimizer.step() optimizer.zero_grad() train_loss.append(loss.item()) # 将训练过程的损失值写入文档保存,并在终端打印出来 with open('log.txt', 'a+') as f: f.write('{} - {}\n'.format(i+1, loss.item())) if (i+1) % 1 == 0: print('Epoch: {}, Loss:{:.5f}'.format(i+1, loss.item())) # 画loss曲线 plt.figure() plt.plot(train_loss, 'b', label='loss') plt.title("Train_Loss_Curve") plt.ylabel('train_loss') plt.xlabel('epoch_num') plt.savefig('loss.png', format='png', dpi=200) plt.close() # torch.save(model.state_dict(), 'model_params.pkl') # 可以保存模型的参数供未来使用 t1=time.time() T=t1-t0 print('The training time took %.2f'%(T/60)+' mins.') tt0=time.asctime(time.localtime(t0)) tt1=time.asctime(time.localtime(t1)) print('The starting time was ',tt0) print('The finishing time was ',tt1) # for test model = model.eval() # 转换成测试模式 # model.load_state_dict(torch.load('model_params.pkl')) # 读取参数 # 注意这里用的是全集 模型的输出长度会比原数据少DAYS_FOR_TRAIN 填充使长度相等再作图 dataset_x = dataset_x.reshape(-1, 1, DAYS_FOR_TRAIN) # (seq_size, batch_size, feature_size) dataset_x = torch.from_numpy(dataset_x) pred_test = model(dataset_x) # 全量训练集 # 的模型输出 (seq_size, batch_size, output_size) pred_test = pred_test.view(-1).data.numpy() pred_test = np.concatenate((np.zeros(DAYS_FOR_TRAIN), pred_test)) # 填充0 使长度相同 assert len(pred_test) == len(data_close) plt.plot(pred_test, 'r', label='prediction') plt.plot(data_close, 'b', label='real') plt.plot((train_size, train_size), (0, 1), 'g--') # 分割线 左边是训练数据 右边是测试数据的输出 plt.legend(loc='best') plt.savefig('result.png', format='png', dpi=200) plt.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158

