
热门标签
热门文章
- 1机械键盘入门:教你如何正确选择机械键盘!学习&游戏两不误_黑轴用长程键还是短程键
- 2linux文件拷到光盘,制作本地yum源(以redhat5.8通过复制光盘文件到本地)
- 3纯CSS3实现柱状图的3D立体动画效果_3d酷炫柱状图css
- 4如何用java编写小游戏_java小游戏文字描述
- 5如何检查docker和docker compose是否已经安装?_怎么检查是否安装docker-compose成功
- 6【人工智能】VScode中使用ChatGPT之Bito插件_vscode中chgpt
- 7SAP Fiori Elements List Report Smart Table 列项目宽度计算的奥妙_fiori element list
- 8深度学习(19)——informer 详解(1)_informer实战
- 9[Unity][计时器][协程]协程计时器倒计时_unity协成被打断
- 10Kafka中的生产者如何处理消息发送失败的情况?_kafka消息发送失败重试机制
当前位置: article > 正文
Python学习记录 搭建BP神经网络实现手写数字识别_bp神经网络 手写数字识别 python代码
作者:Gausst松鼠会 | 2024-02-16 15:40:10
赞
踩
bp神经网络 手写数字识别 python代码
搭建BP神经网络实现手写数字识别
通过之前的文章我们知道了,构建一个简单的神经网络需要以下步骤
- 准备数据
- 初始化假设
- 输入神经网络进行计算
- 输出运行结果
这次,我们来通过sklearn的手写数字数据集,来搭建一个BP神经网络,实现手写数字识别
背景
- 搭建的是一个2层的神经网络,包含一个输入层(输入层一般不计入网络的层数里面),一个隐藏层和一个输出层
- 每个样本包含64个特征,标签进行了独热化处理(独热化处理就会将每种标签转化成一个只包含0和1,长度为10的数组,例如:数字0的标签就为[1,0,0,0,0,0,0,0,0,0],数字1的标签为[0,1,0,0,0,0,0,0,0,0],数字2的标签为[0,0,1,0,0,0,0,0,0,0]),因为存在10个标签(0到9),所以输入层设置了64个神经元,输出层设置了10个神经元,隐藏层设置100个神经元
- 神经网络的输出,也是一个长度为10的数组,如0为[1,0,0,0,0,0,0,0,0,0],最大大数字的索引为0,即预测结果为0,只需要取出数组最大数字的索引便可得到预测结果
- 激活函数为sigmoid函数
- 数据集使用sklearn的手写数字数据集
准备数据
加载数据
digits = load_digits()
- 1
设置输入数据
X为我们的输入数据
X = digits.data
- 1
设置目标输出数据
Y为我们的目标数据
Y = = digits.target
- 1
数据归一化处理
将输入数据归一化,范围变成0 到 1之间
X = (X - X.min()) / (X.max() - X.min())
- 1
数据拆分
将数据拆分成训练集和测试集,测试数据就是我们的假设数据,用于与训练模型进行测试
x_train, x_test, y_train, y_test = train_test_split(X, Y)
- 1
独热化处理
将训练数据标签独热化处理
labels = LabelBinarizer().fit_transform(y_train)
- 1
- 独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效
- 独热化处理就会将每种标签转化成一个只包含0和1,长度为10的数组,例如:数字0的标签就为[1,0,0,0,0,0,0,0,0,0],数字1的标签为[0,1,0,0,0,0,0,0,0,0],数字2的标签为[0,0,1,0,0,0,0,0,0,0]
初始化假设并输入神经网络进行计算
搭建神经网络
设置偏置值
没有偏置的话,分割线会经过原点,就不能正确的分类了
class NeuralNetwork:
def __init__(self, layers):
# 初始化隐藏层权值
self.w1 = np.random.random([layers[0], layers[1]]) * 2 - 1
# 初始化输出层权值
self.w2 = np.random.random([layers[1], layers[2]]) * 2 - 1
# 初始化隐藏层的偏置值
self.b1 = np.zeros([layers[1]])
# 初始化输出层的偏置值
self.b2 = np.zeros([layers[2]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
定义激活函数和它的导函数(梯度下降法所需要)
# 定义激活函数
@staticmethod
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 定义激活函数的导函数
@staticmethod
def dsigmoid(x):
return x * (1 - x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
设置训练方法
def train(self, x_data, y_data, lr=0.1, batch=50): """ 模型的训练函数 :param x_data: 训练数据的特征 :param y_data: 训练数据的标签 :param lr: 学习率 :param batch: 每次要训练的样本数量 :return: """ # 随机选择一定批次的数据进行训练 index = np.random.randint(0, x_data.shape[0], batch) x = x_data[index] t = y_data[index] # 计算隐藏层的输出 l1 = self.sigmoid(np.dot(x, self.w1) + self.b1) # 计算输出层的输出 l2 = self.sigmoid(np.dot(l1, self.w2) + self.b2) # 计算输出层的学习信号 delta_l2 = (t - l2) * self.dsigmoid(l2) # 计算隐藏层的学习信号 delta_l1 = delta_l2.dot(self.w2.T) * self.dsigmoid(l1) # 计算隐藏层的权值变化 delta_w1 = lr * x.T.dot(delta_l1) / x.shape[0] # 计算输出层的权值变化 delta_w2 = lr * l1.T.dot(delta_l2) / x.shape[0] # 改变权值 self.w1 += delta_w1 self.w2 += delta_w2 # 改变偏置值 self.b1 += lr * np.mean(delta_l1, axis=0) self.b2 += lr * np.mean(delta_l2, axis=0)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
设置预测方法
def predict(self, x):
"""
模型的预测函数
:param x: 测试数据的特征
:return: 返回一个包含10个0-1之间数字的numpy.array对象
"""
l1 = self.sigmoid(np.dot(x, self.w1) + self.b1)
l2 = self.sigmoid(np.dot(l1, self.w2) + self.b2)
return l2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
保存和加载模型
# 保存训练模型
def save(self, path):
np.savez(path, w1=self.w1, w2=self.w2, b1=self.b1, b2=self.b2)
# 加载训练模型
def load(self, path):
npz = np.load(path)
self.w1 = npz['w1']
self.w2 = npz['w2']
self.b1 = npz['b1']
self.b2 = npz['b2']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
设置输入检测图像的API接口
# 输入手写数字图像,返回模型预测结果 def predict_num(self, img): # 将图片转换为灰度图 img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图片转换为二值图 img = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)[1] # 将图片转换为8*8的矩阵 img = cv2.resize(img, (8, 8)) # 将图片转换为一维向量 img = img.flatten() # 图片归一化处理 img = img / 255 # 预测图片的数字 num = self.predict(img) # 返回预测结果 return np.argmax(num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
定义一个2层的网络模型
输入层64个特征输入
隐藏层100个神经元
输出层10个神经元
nn = NeuralNetwork([64, 100, 10])
- 1
设置训练周期和测试周期
epoch = 20000
test = 400
- 1
- 2
保存测试时产生的代价函数的值以及测试过程中的准确率
loss = []
accuracy = []
- 1
- 2
输入神经网络进行计算
for n in range(epoch): nn.train(x_train, labels) # 每训练一定的次数后,进行一次测试 if n % test == 0: # 用测试集测试模型,返回结果为独热编码的标签 predictions = nn.predict(x_test) # 取返回结果最大值的索引,即为预测数据 y2 = np.argmax(predictions, axis=1) # np.equal用来比较数据是否相等,相等返回True,不相等返回False # 比较的结果求平均值,即为模型的准确率 acc = np.mean(np.equal(y_test, y2)) # 计算代价函数 cost = np.mean(np.square(y_test - y2) / 2) # 将准确率添加到列表 accuracy.append(acc) # 将代价函数添加到列表 loss.append(cost) print('epoch:', n, 'accuracy:', acc, 'loss:', loss)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
输出运行结果
使用测试数据对模型进行测试
训练完成之后,使用测试数据对模型进行测试
pred = nn.predict(x_test)
y_pred = np.argmax(pred, axis=1)
- 1
- 2
查看模型预测结果与真实标签之间的报告
print(classification_report(y_test, y_pred))
- 1
查看模型预测结果与真实标签之间的混淆矩阵
print(confusion_matrix(y_test, y_pred))
- 1
打印出图标查看
plt.subplot(2, 1, 1)
plt.plot(range(0, epoch, test), loss)
plt.ylabel('loss')
plt.subplot(2, 1, 2)
plt.plot(range(0, epoch, test), accuracy)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
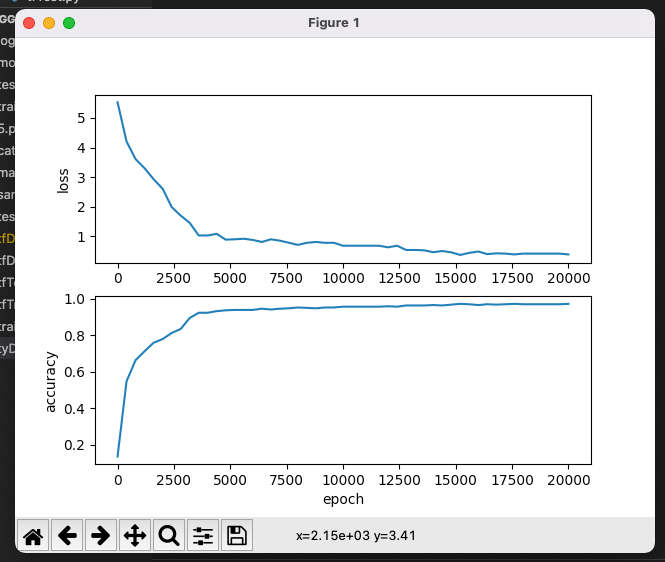
可以看到准确率则是逐渐的增加
输入数字图片进行预测
准备一张图片
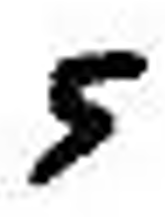
保存为5.png
img = cv2.imread('5.png')
print("识别的数字为:",nn.predict_num(img))
- 1
- 2
完整代码
import numpy as np import cv2 from matplotlib import pyplot as plt from sklearn.datasets import load_digits from sklearn.preprocessing import LabelBinarizer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report, confusion_matrix import os # 数据库路径 MODEL_PATH = "sklen_num_model.npz" class NeuralNetwork: def __init__(self, layers): # 初始化隐藏层权值 self.w1 = np.random.random([layers[0], layers[1]]) * 2 - 1 # 初始化输出层权值 self.w2 = np.random.random([layers[1], layers[2]]) * 2 - 1 # 初始化隐藏层的偏置值 self.b1 = np.zeros([layers[1]]) # 初始化输出层的偏置值 self.b2 = np.zeros([layers[2]]) # 定义激活函数 @staticmethod def sigmoid(x): return 1 / (1 + np.exp(-x)) # 定义激活函数的导函数 @staticmethod def dsigmoid(x): return x * (1 - x) def train(self, x_data, y_data, lr=0.1, batch=50): """ 模型的训练函数 :param x_data: 训练数据的特征 :param y_data: 训练数据的标签 :param lr: 学习率 :param batch: 每次要训练的样本数量 :return: """ # 随机选择一定批次的数据进行训练 index = np.random.randint(0, x_data.shape[0], batch) x = x_data[index] t = y_data[index] # 计算隐藏层的输出 l1 = self.sigmoid(np.dot(x, self.w1) + self.b1) # 计算输出层的输出 l2 = self.sigmoid(np.dot(l1, self.w2) + self.b2) # 计算输出层的学习信号 delta_l2 = (t - l2) * self.dsigmoid(l2) # 计算隐藏层的学习信号 delta_l1 = delta_l2.dot(self.w2.T) * self.dsigmoid(l1) # 计算隐藏层的权值变化 delta_w1 = lr * x.T.dot(delta_l1) / x.shape[0] # 计算输出层的权值变化 delta_w2 = lr * l1.T.dot(delta_l2) / x.shape[0] # 改变权值 self.w1 += delta_w1 self.w2 += delta_w2 # 改变偏置值 self.b1 += lr * np.mean(delta_l1, axis=0) self.b2 += lr * np.mean(delta_l2, axis=0) def predict(self, x): """ 模型的预测函数 :param x: 测试数据的特征 :return: 返回一个包含10个0-1之间数字的numpy.array对象 """ l1 = self.sigmoid(np.dot(x, self.w1) + self.b1) l2 = self.sigmoid(np.dot(l1, self.w2) + self.b2) return l2 # 保存训练模型 def save(self, path): np.savez(path, w1=self.w1, w2=self.w2, b1=self.b1, b2=self.b2) # 加载训练模型 def load(self, path): npz = np.load(path) self.w1 = npz['w1'] self.w2 = npz['w2'] self.b1 = npz['b1'] self.b2 = npz['b2'] # 输入手写数字图像,返回模型预测结果 def predict_num(self, img): # 将图片转换为灰度图 img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图片转换为二值图 img = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)[1] # 将图片转换为8*8的矩阵 img = cv2.resize(img, (8, 8)) # 将图片转换为一维向量 img = img.flatten() # 图片归一化处理 img = img / 255 # 预测图片的数字 num = self.predict(img) # 返回预测结果 return np.argmax(num) # 定义一个2层的网络模型:64-100-10 nn = NeuralNetwork([64, 100, 10]) # 如果存在数据库就加载,不存在就训练 if os.path.exists(MODEL_PATH): nn.load(MODEL_PATH) else: # 载入数据集 digits = load_digits() X = digits.data Y = digits.target # 数据归一化 X = (X - X.min()) / (X.max() - X.min()) # 将数据拆分成训练集和测试集 x_train, x_test, y_train, y_test = train_test_split(X, Y) # 将训练数据标签化为独热编码 labels = LabelBinarizer().fit_transform(y_train) # 训练周期 epoch = 20001 # 测试周期 test = 400 # 用来保存测试时产生的代价函数的值 loss = [] # 用来保存测试过程中的准确率 accuracy = [] for n in range(epoch): nn.train(x_train, labels) # 每训练一定的次数后,进行一次测试 if n % test == 0: # 用测试集测试模型,返回结果为独热编码的标签 predictions = nn.predict(x_test) # 取返回结果最大值的索引,即为预测数据 y2 = np.argmax(predictions, axis=1) # np.equal用来比较数据是否相等,相等返回True,不相等返回False # 比较的结果求平均值,即为模型的准确率 acc = np.mean(np.equal(y_test, y2)) # 计算代价函数 cost = np.mean(np.square(y_test - y2) / 2) # 将准确率添加到列表 accuracy.append(acc) # 将代价函数添加到列表 loss.append(cost) print('epoch:', n, 'accuracy:', acc, 'loss:', loss) # 保存训练数据 nn.save(MODEL_PATH) # 使用测试数据对模型进行测试 pred = nn.predict(x_test) y_pred = np.argmax(pred, axis=1) # 查看模型预测结果与真实标签之间的报告 print(classification_report(y_test, y_pred)) # 查看模型预测结果与真实标签之间的混淆矩阵 print(confusion_matrix(y_test, y_pred)) # 训练结果可视化 plt.subplot(2, 1, 1) plt.plot(range(0, epoch, test), loss) plt.ylabel('loss') plt.subplot(2, 1, 2) plt.plot(range(0, epoch, test), accuracy) plt.xlabel('epoch') plt.ylabel('accuracy') plt.show() img = cv2.imread('5.png') print("识别的数字为:",nn.predict_num(img))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/94818
推荐阅读
相关标签

