
热门标签
热门文章
- 1SublimeText调试JS操作方法_sublime text 调试 javascript
- 2AtCoder 注册、如何参加Atcoder的比赛_atcoder注册
- 3C++ 蓝桥杯之 龟兔赛跑预测_c++龟兔赛跑预测
- 4数据结构和算法之排序总结_排序算法的技术要点和设计要求
- 52022年蓝桥杯Python程序设计B组思路和代码分享
- 6uniapp h5发行_uniapp 发布h5
- 7【Godot】学习状态机和行为树的 Godot 网址_godot教程网站
- 8讯飞星火认知大模型 Nodejs SDK & Web使用_讯飞 spark nodejs 部署
- 9华为OD机试真题- 最小的调整次数【2023Q1】【JAVA、Python、C++】_最小调整次数华为od
- 10Python 之 Pandas DataFrame 数据类型的简介、创建的列操作_python pandas dataframe
当前位置: article > 正文
TFIDF | 有权重的计算文本情感得分
作者:IT小白 | 2024-02-09 19:24:30
赞
踩
加权情感得分

2021暑期 | Python数据挖掘暑假工作坊
在论文
Kai Li, Feng Mai, Rui Shen, Xinyan Yan, Measuring Corporate Culture Using Machine Learning, The Review of Financial Studies,2020
中,
除了使用词向量人工构建五大类文化词典,
还使用了tfidf作为权重,计算企业每条文档五大类文化的得分情况。
情感分析
无权重。直接计算文本中正、负情感词出现的次数
有权重。tf-idf, tf是词频,idf是权重。
Tfidf法
scikit库除了CountVectorizer类,还有TfidfVectorizer类。TF-IDF这个定义相信大家应该已经耳熟能详了:

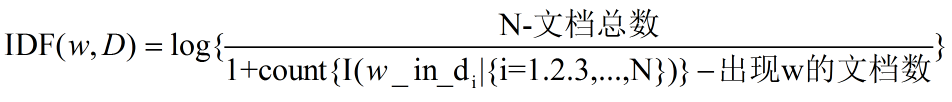
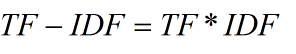
TF 词语出现越多,这个词越有信息量
IDF 词语越少的出现在文本中,词语越有信息量。
原始数据
- import pandas as pd
-
-
- corpus = ["hello, i am glad to meet you",
- "it is wonderful",
- "i hate you",
- "i am sad"]
-
- df1 = pd.DataFrame(corpus, columns=['Text'])
- df1

构造tfidf
- from sklearn.feature_extraction.text import TfidfVectorizer
-
-
- def createDTM(corpus):
- """构建文档词语矩阵"""
- vectorize = TfidfVectorizer()
- #注意fit_transform相当于fit之后又transform。
- dtm = vectorize.fit_transform(corpus)
- #vectorize.fit(corpus)
- #dtm = vectorize.transform(corpus)
- #打印dtm
- return pd.DataFrame(dtm.toarray(),
- columns=vectorize.get_feature_names())
-
- df2 = createDTM(df['text'])
- df2

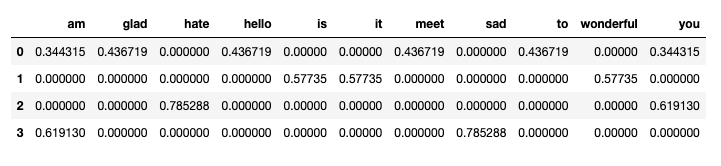
合并df1和df2
- df = pd.concat([df1, df2], axis=1)
- df

- #积极词典
- pos_words = ['glad', 'hello', 'wonderful']
-
- #消极词典
- neg_words = ['sad', 'hate']
-
- #积极词典
- df[pos_words]
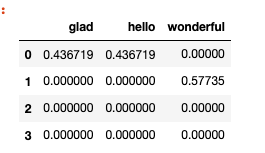
df[pos_words].sum(axis=1)
- 0 0.873439
- 1 0.577350
- 2 0.000000
- 3 0.000000
- dtype: float64
- df['Pos'] = df[pos_words].sum(axis=1)
- df

经过以上操作,很简便的对文本的正面情感进行了计算。同理,也可以对负面情感进行计算,此处省略。
输出
最后保存,输出为csv文件。
df.to_csv('output/tfidf有权重的情感分析.csv')
2021暑期 | Python数据挖掘暑假工作坊
近期文章
腾讯课堂 | Python网络爬虫与文本分析
B站视频 | Python自动化办公
读完本文你就了解什么是文本分析
文本分析在经管领域中的应用概述
综述:文本分析在市场营销研究中的应用
中文金融情感词典发布啦 | 附代码
wordexpansion包 | 新增词向量法构建领域词典
语法最简单的微博通用爬虫weibo_crawler
大邓github汇总, 觉得有用记得star
hiResearch 定义自己的科研首页
whatlies包 | 简单玩转词向量可视化
Jaal 库 轻松绘制动态社交网络关系图
SciencePlots | 科研样式绘图库
使用streamlit上线中文文本分析网站
Clumper | dplyr式的Python数据操作包
Clumper库 | 常用的数据操作函数
Clumper库 | Groupby具体案例用法
Clumper库 | 其他数据分析
plydata库 | 数据操作管道操作符>>
plotnine: Python版的ggplot2作图库
plotnine: Python版的ggplot2作图库
Wow~70G上市公司定期报告数据集
YelpDaset: 酒店管理类数据集10+G
漂亮~pandas可以无缝衔接Bokeh
腾讯课堂 | Python网络爬虫与文本分析
B站视频 | Python自动化办公
读完本文你就了解什么是文本分析
文本分析在经管领域中的应用概述
综述:文本分析在市场营销研究中的应用
中文金融情感词典发布啦 | 附代码
wordexpansion包 | 新增词向量法构建领域词典
语法最简单的微博通用爬虫weibo_crawler
大邓github汇总, 觉得有用记得star
hiResearch 定义自己的科研首页
whatlies包 | 简单玩转词向量可视化
Jaal 库 轻松绘制动态社交网络关系图
SciencePlots | 科研样式绘图库
使用streamlit上线中文文本分析网站
Clumper | dplyr式的Python数据操作包
Clumper库 | 常用的数据操作函数
Clumper库 | Groupby具体案例用法
Clumper库 | 其他数据分析
plydata库 | 数据操作管道操作符>>
plotnine: Python版的ggplot2作图库
plotnine: Python版的ggplot2作图库
Wow~70G上市公司定期报告数据集
YelpDaset: 酒店管理类数据集10+G
漂亮~pandas可以无缝衔接Bokeh
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/72758
推荐阅读
相关标签

