
- 1Internet Download Manager中文破解版v6.42.3绿色版_internet download manager 6.42.3
- 2nltk学习之统计词频和分词nltk.word_tokenize nltk.FreqDist_nltk.word_tokenize()
- 3TrOCR:基于Transformer的新一代光学字符识别_transfromer识别文字
- 4北理计算机考研初试复试经验分享贴专硕889_北理计算机考研复试经验贴
- 5深度之眼Paper带读笔记NLP.11:FASTTEXT.Baseline.06_in this work, we explore ways to scale thesebaseli
- 6maya smpl 笔记
- 7mmdetection算法之DETR(0)_mmdetection 跑detr模型训练结果为0
- 8【Android入门到项目实战-- 5.1】—— 广播(一):接收系统广播_android 接收广播
- 9手把手教你在Linux系统下进行Python pip换源操作
- 10TSNE数据降维_tsne降维
数据结构 二叉树(一篇基本掌握)
赞
踩
绪论
雄关漫道真如铁,而今迈步从头越。 本章将开始学习二叉树(全文共一万两千字),二叉树相较于前面的数据结构来说难度会有许多的攀升,但只要跟着本篇博客深入的学习也可以基本的掌握基础二叉树。
话不多说安全带系好,发车啦(建议电脑观看)。

附:红色,部分为重点部分;蓝颜色为需要记忆的部分(不是死记硬背哈,多敲);黑色加粗或者其余颜色为次重点;黑色为描述需要
目录
2.3.1.1当给定前序 / 后序 + 中序就能确定唯一的二叉树(考试常考点)
1.树的概念
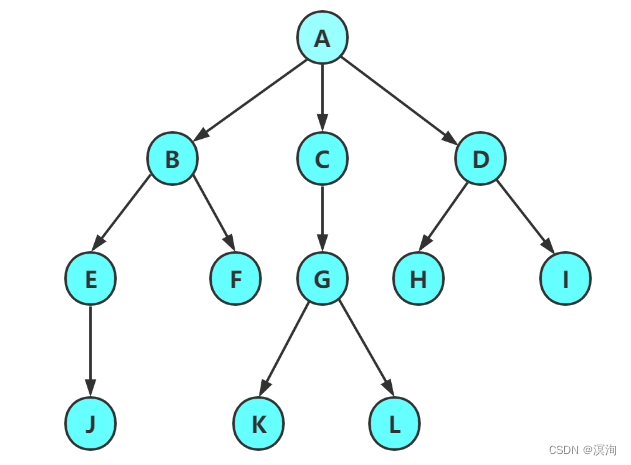
树是一种非线性的数据结构,因为其结构和现实中的树的分叉形式倒过来的样子非常相似故被称为树,其中每个数据被称为一个个 节点,在一棵树中最上面的节点又被称为根节点(根节点没有前驱节点),对于每个节点来说都能称为一个树(或称为子树),每棵树都是由多颗子树构成,并且每个节点都会有且只有一个前驱节点而且由多个或零个后继节点。在树中的各个子树是不能有交集的(互不相交的),一棵有n个节点的树有n-1个父节点(在树中常习惯用亲缘关系来描述)
- 父节点(双亲节点):一个节点的前驱节点(上图A就是BCD的父节点)
- 子节点:一个节点的后继节点(A的子节点有BCD)
- 度:每个节点有的子节点个数(A的度就为3)
- 树的度:在一个树中的所有节点中的最大的度(上面的树其中就是A的度最大故树的度为3)
- 节点的层次:从根开始算,根的层次为1依次往后....(故A的层次为1 、 j 的层次为4)
- 高度(深度):一般来说也是从1开始的,上图的深度/高度就是4(会有争议有些是从0开始)
- 叶(子)节点(终端节点):度为0的节点 或者 可以看成没有子节点的节点就是叶节点(如J、K、L、H、I、F)
- 分支节点(非终端节点):不是叶子节点的节点都算分支节点 或者 度不为0的节点(上图除了叶子节点的其余节点都能看成分支节点)
- 兄弟节点:有相同父节点的节点(如上图的BCD他们都互为兄弟节点)
- 堂兄弟节点:父节点在同一层的节点(如F与G)
- 祖先节点:从根到该节点所经过的所有节点
- 子孙:其节点往后的所有节点都能看成该节点的子孙(上图所有节点都是A)
- 森林:多颗互不相交的树
应用:目录树(由左孩子右兄弟法结构表示)
2.二叉树
2.1二叉树的概念
二叉树是树中的特殊的一种树,其中二叉树的度最大为2,此时的每个节点的子节点称为左孩子、右孩子(左子树、右子树)
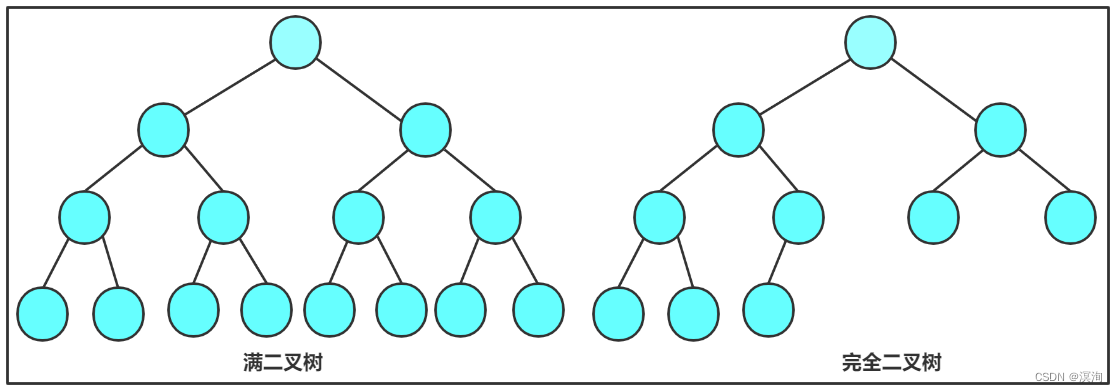
- 满二叉树:除了叶子结点度为0,其余的节点的度都为2,每一层都是满的
- 一个h层的满二叉树,有(2 ^ h) - 1 个节点
- 完全二叉树:高度为h的完全二叉树,其前h-1层都是满的,最后一层可以不满,但最后一层必须从左往右是连续的
- 一个h层的完全二叉树,有 2 ^( h - 1)~ (2 ^ h) - 1
- 在二叉树中 第 h 层的最大节点个数为:2 ^( h - 1)(若是满二叉树那就直接等于)
- 一个有h层的二叉树其节点个数最大为( 2 ^ h )- 1
- 对于非空二叉树来说度为0的节点 n0 = 度为2的节点n2 + 1:n0 = n2 + 1
- 在完全二叉树中度为1的节点只有可能为 1 / 0 ;树的节点个数为偶数时度为1的节点个数是1、奇数时为0

2.2二叉树的顺序结构
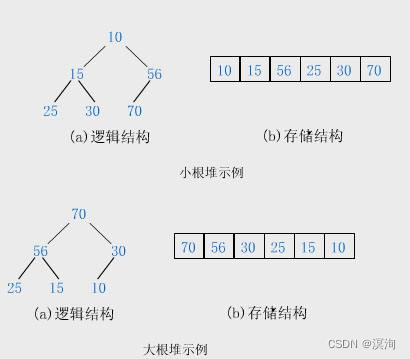
二叉树的结构可以由顺序、链表结构实现,对于一般的二叉树来说不适合用顺序结构来存储,因为对于一些没有节点的地方会有许多空间的浪费,完全二叉树很适合用顺序结构,现实中通常把堆(一种二叉树)使用顺序结构的数组存储
2.2.1堆:
- 为一棵完全二叉树
- 大堆:树中的父节点都大于子节点
- 小堆:树中的父节点都小于子节点
- 父节点与子节点的关系
- 父节点到左孩子:leftchild = parent * 2 + 1
- 父节点到左孩子:leftchild = parent * 2 + 2
- 左、右孩子到父节点:parent = (child - 1) / 2
- 对于堆结构来说,我们要理解到它的逻辑结构和物理结构
- 逻辑结构来说他是一颗完全二叉树
- 物理结构来说他的底层是数组来存储的
- 我们需要记住他的底层数组来描述这棵完全二叉树
堆的实现(所要实现的功能):
- 初始化(主要针对顺序结构所需要的空间)
- 销毁
- 插入数据
- 堆的向上调整算法
- 大概的算法原理:给定孩子的位置和父节点进行比较如果大于/小于则交换(大堆/小堆)循环判断若孩子到了堆顶了停止
- 时间复杂度为:O(N*logN)
- 删除数据
- 堆的向下调整算法
- 大概的算法原理:给定父节点和树中的个数,然后让父节点和子节点进行比较如果大于/小于则交换(小堆/大堆)循环判断若孩子节点不存在时停止
- 时间复杂度为:O(N)
- 取堆顶的数据、查看堆有几个数据、对堆判空
具体细节会在实现里有详细的注释(注释在我们日后工作中是非常重要的,所以可以写成一种习惯)
向上、下调整的应用:
1.向上、向下调整直接建堆的方法:
向上调整:他是在一个堆中进行的,我们从数组的第二个数据开始调整这样就不用管这个前提条件了(因为向上看的话单独的节点可以看成一个堆)
向下调整:他左右节点是堆中进行的,我们可以从最后一个叶节点的父节点开始调整这样就不用再考虑前提条件(因为向下看的话单独的节点可以看成一个堆)
这样给定一个数组让他变成大、小堆的话,就能通过向上或者向下调整循环来构造出一个堆。
具体如下:
建小堆:(若要建大堆的话在向上下调整函数中改变一下大小与关系即可换成建大堆)
2.通过大小堆来实现排升、降序
升序建大堆、降序建小堆
因为我们建大堆时父节w点一定大于子节点,所以此时根节点也就是最大的节点,可以把根节点和最后节点交换,这样最大的就发到了 , 然后size--把这个节点先排除再进行向下调整就能还原堆 , 最后循环上面过程最终就能实现升序。
小堆的方法一样就不赘述了。通过代码来看
- //通过向下调整建小堆
- for (int i = (n - 2) / 2; i >= 0; i--) // 最后一个叶子节点 n - 1 的父节点(( n - 1 ) - 1 )/ 2
- {
- AdjustDown(a,n,i);
- }
-
- int end = n - 1;//找到最后一个节点
- while (end > 0)
- {
- swap(&a[0], &a[end]);//将最后的节点和堆顶元素交换下
-
- AdjustDown(a, end, 0);//再还原一下堆
-
- --end;//改变尾
- }
此处的时间复杂度为:O(N + N*logN)==O(N*logN)
堆的TopK问题:
从堆中取出最大/最小的前K个,建大堆找最大的前K个、建小堆找最小的前K个
方法1:在大堆中 pop k次 就能找到最大的前K个、在小堆中 pop k次找最小的前k个
但这方法有点弊端:需要先建堆,而数据量非常大的时候就需要非常多的空间,这样就会导致内存的不够用,(适用于K比较小的情况)
方法2:若查找最大的前K个,我们可以创建一个K大小的小堆来存放这些数据(这样就避免将所有的数据都申请空间),让后让他们逐一比较当比堆顶的大就能进堆,建小堆的原因:因为是要找最大的前K个,小堆的根节点是最小的数据,只有这样才能把要找的大的数据放进去(大堆的根节点是最大的)
实现:
2.3二叉树的链式结构
链式二叉树的结构:int val、int* right、int* left,当其左右子树都为NULL时就代表到了最后,即对于链式的二叉树来说主要去查看他的左右子树来进行。
2.3.1前序、中序、后序
前序:根、左子树、右子树、中序:左子树、根、右子树、后序:左子树、右子树、根
这里的根表示访问根节点的数据,而左子树、右子树则表示通过结构去访问左右子树的节点。
像上图当左右子树为NULL时就开始返回
前中后序都是在递归的基础上进行的
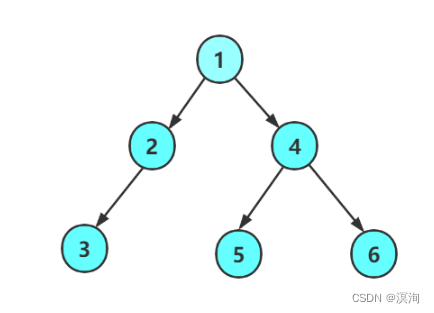
- 前序遍历为:1 2 3 NULL NULL NULL 4 5 NULL NULL 6 N N
- 分析: 前序遍历是先打印所到节点的数据后再往左右子树走遇到NULL则返回
- 中序遍历为:N 3 N 2 N 1 N 5 N 4 N 6 N
- 分析: 中序遍历是先往左子树走遇到NULL则返回 然后再打印所到节点的数据 然后才往右子树走遇到NULL则返回
- 后序遍历为:N N 3 N 2 N N 5 N N 6 4 1
- 分析: 后序遍历是先往左子树走遇到NULL则返回 然后再往右子树走遇到NULL则返回 然后才打印所到节点的数据
用代码实现 :
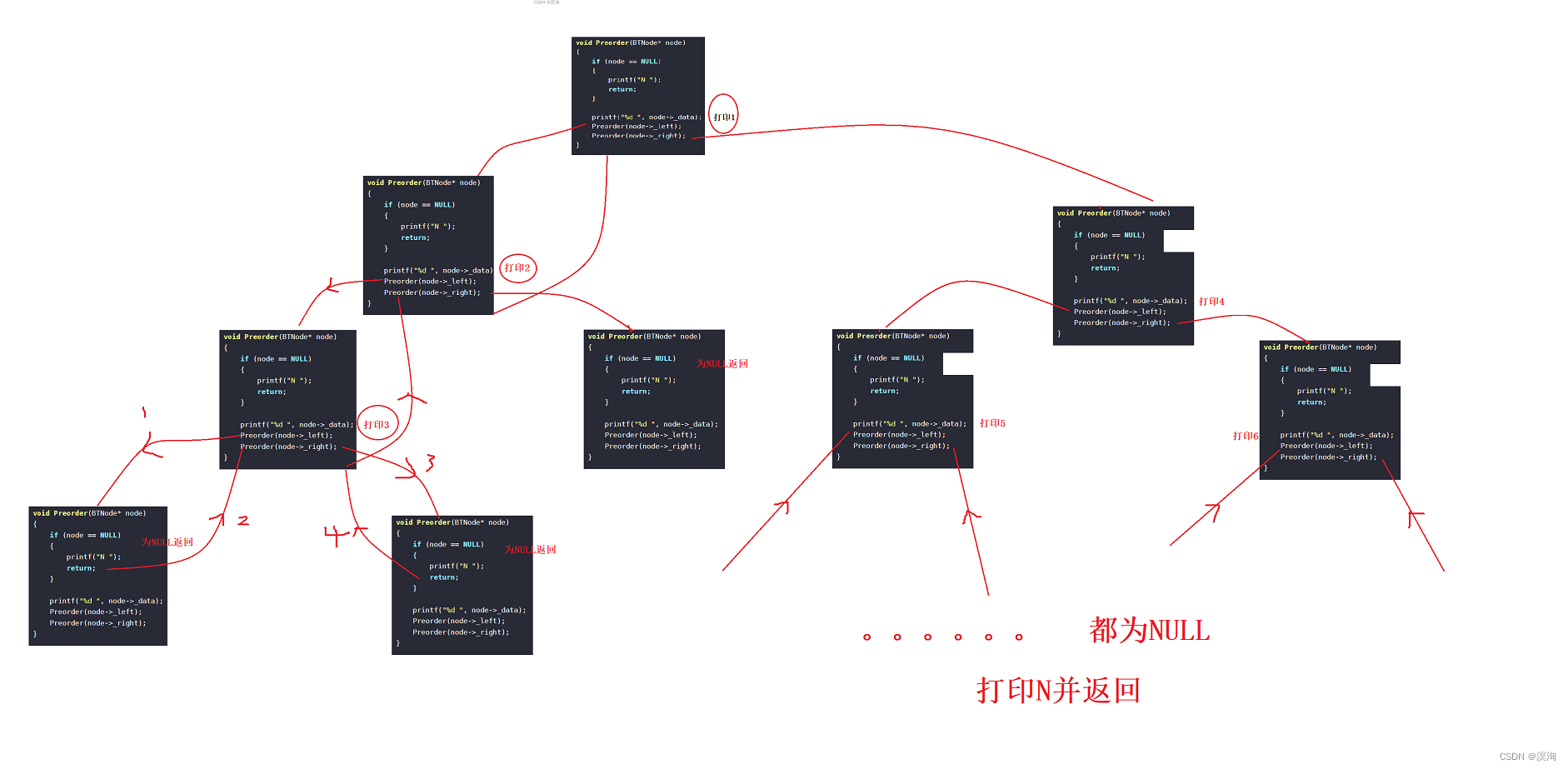
递归展开图(通过这个仔细的了解其原理):
前序:
中序、后序就不画了,建议初学者一定要画画
2.3.1.1当给定前序 / 后序 + 中序就能确定唯一的二叉树(考试常考点)
而当给前序+后序的话是不一定能确定唯一二叉树的
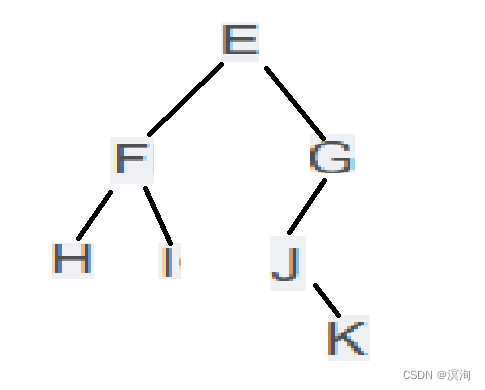
例:前序:EFHIGJK、中序:HFIEJKG
因为前序是:根、左、右 ;中序是:左 、 根 、 右
- 那么前序就能先判断根、而中序能判断左右子树
- 此时前序先为E
- 那么中序E的左子树就为HFI 、 E的右子树就是JKG
- 再通过前序看根:F他是在中序E的左子树的并且前序先是F故为左子树的根
- 再通过中序查看F的左右子树为:左:H ; 右:I (因为其内部只有一个节点就不用再排了故就完成了)
- 此时树的左子树已经完成那就排除掉左边的(EHFI)再继续看右子树(JKG)
- 同样的方法:通过前序从前往后看根、通过中序看左右子树、然后不断往下直到没有节点
- 右子树:前序最开始时G故意G为子树的根节点、再看中序只有左节点那么都在左边 再看J为前序的开始那么以J为根、再看中序K在右边那么K为右子树
- 最终得:
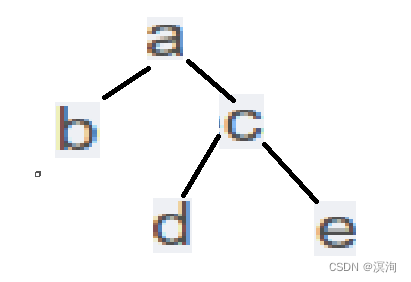
例:后序:bdeca 、中序:badce
此时后序和前序略有不同需要我们从后往前来看
因为后序:左 、右 、根 ; 中序是:左 、 根 、 右
- 后序中从后往前看树的根为a
- 然后看中序只有b在左子树,那么在左子树就b一个节点、然后看右子树有(dce)
- 确定左右子树的节点后再看后序从后往前的倒数第二个为c,那么就表示c为右子树的根(此处要注意此时不同于前序要先看右树的根也就是c)
- 在看中序就能看出d为右子树的左节点、e为右节点
- 最终得:
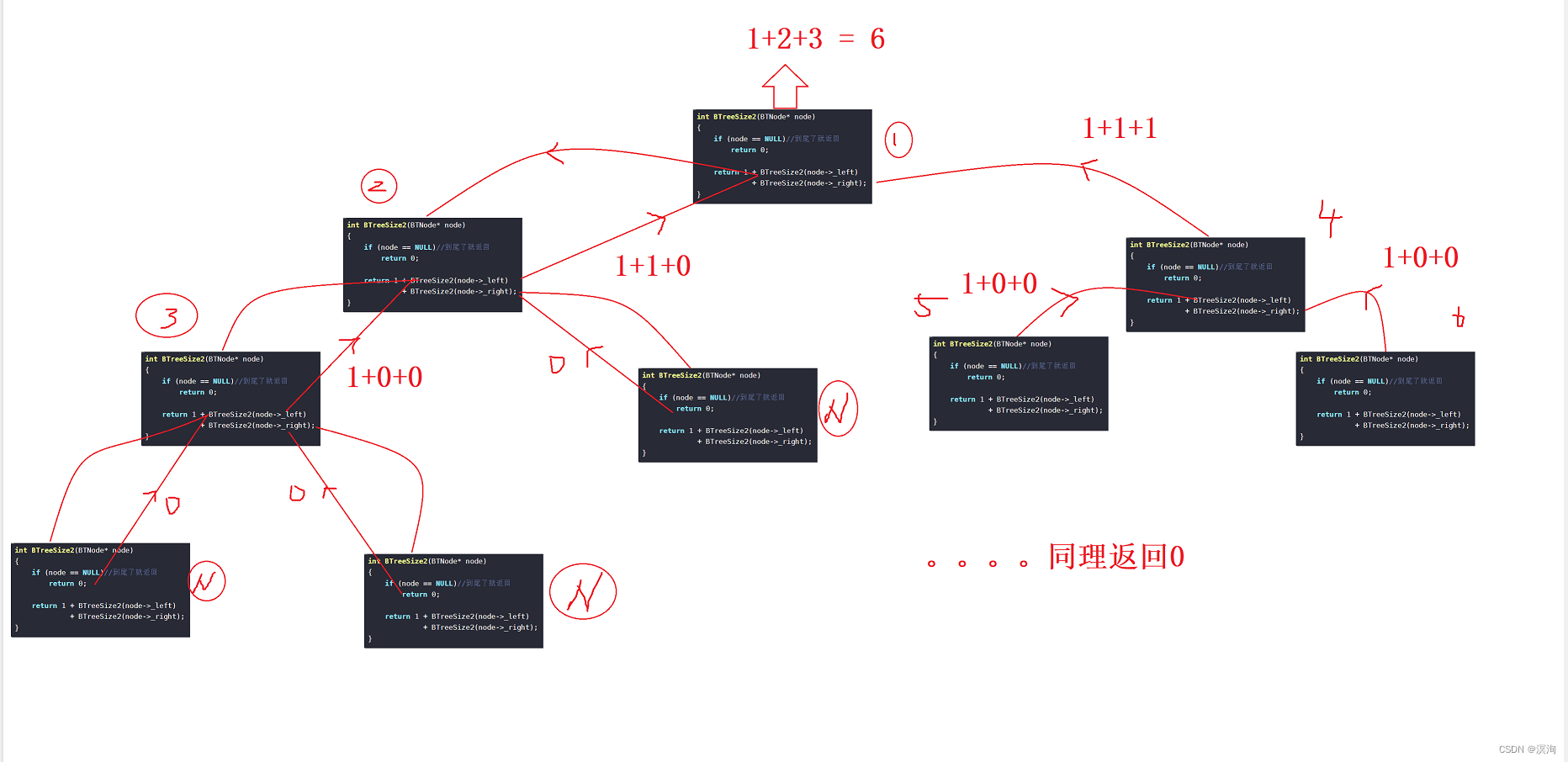
2.3.2求二叉树中的节点个数:
方法1的原理和前中后序一样
方法2原理:返回 自身+左树的所有的节点+右树所有的节点,这样不断递归下去当到NULL时就返回0
初学建议一定要画画递归图这样就能更清楚的了解!下面就不画了看不懂可以画画图或者评论区可以提问我都会看!
2.3.3求二叉树的高度
思路:递归思路 ,每个节点记录自己左右子树返回来的值 判断左右孩子那边返回来的值大 , 最终返回大的一边。
实现:
2.3.4求二叉树中第K层的节点
思路:用一个变量记录如果到了第K层就返回1,否则的返回0
实现:
2.3.5在二叉树中查找节点
思路:于上面查看二叉树的高度类似,先不断递归再在递归过程中判断其节点的值是否和所要查找的相等,若相等则返回该节点的地址,反之只有当遇空了才返回NULL , 最后通过记录左右子树的返回情况若为NULL则不用若不为NULL则表示返回来了一个节点指针
实现:
进阶练习:
思路:分析题目,为证明树的对称那么就能发现:要判断左子树的左节点和右子树的右节点是否相等、左子树的右节点和右子树的左节点是否相等。
那么首先要解决的难题是要抛弃固有思路只从一个节点来看,此时就可以在写一个函数,让其可以同时从左右子树往下查询是否相等
并且就能有递归思路:return _isSymmetric(Leftroot->left , Rightroot->right ) && _isSymmetric( Leftroot->right , Rightroot->left); 左树左子--右树右子、左树右子--右树左子
然后就是限制递归的思路:
同时遇NULL表示相等(前面都相等到空树了)那么就表示是相等的返回真
若当只有一方为NULL时是不等的故返回false
再然后 就是判断其值是否相等了
最终代码:
2.3.6层序遍历
层序遍历的方法:通过队列的形式将节点存进队列中,每当有节点出队列时就将其自身的左右节点带进来,这样就能实现对二叉树的层序遍历。
代码实现:
练习:判断一个二叉树是否为完全二叉树
用层序的思路来查看该二叉树
对于完全二叉树的特性:节点是除了最后一层其余每层都是满的并且从左往右是连续的
则就表示在层序的队列中所有节点都是连续存放的其中不会有NULL插开的情况
- bool BTreeCompare(BTNode* root)
- {
- Queue q;
- QueueInit(&q);
-
- if (root)
- QueuePush(&q, root);
-
- //把节点逐一放进队列中
- while (!QueueEmpty(&q))
- {
- BTNode* front = QueueFront(&q);
- QueuePop(&q);
-
- //只要第一次NULL就退出
- if (front == NULL)
- break;
-
- QueuePush(&q, front->_left);
- QueuePush(&q, front->_right);
- }
-
- //查看队列后面是否全部为NULL若不是就表示不是完全二叉树
- //因为完全二叉树的节点是连续的
- while (!QueueEmpty(&q))
- {
- BTNode* front = QueueFront(&q);
- QueuePop(&q);
- if (front != NULL)
- return false;
- }
- return true;
- }
如果有任何问题欢迎讨论哈!
如果觉得这篇文章对你有所帮助的话点点赞吧!
持续更新大量数据结构细致内容,早关注不迷路。

