
- 1ESP32 MicroPython AI摄像头应用⑩_esp32 ai
- 2交叉注意力融合时空特征的TCN-Transformer并行预测模型_tcn 和transformer
- 3遥感数据共享(一)珠海一号数据_国产高分遥感下载 珠海
- 4使用DeepStream5.0部署YOLOV3,并实现多路拉流、自定义模型_c++ deepstream拉流nx
- 5并发编程面试题(2020最新版)_容器化能增大传统系统的并发能力吗
- 6微信小程序服务器404,解决小程序404及showToast:fail parameter error: parameter.title should be String instead of Und...
- 7ubuntu 20.04 | 解决 Connecting to raw.githubusercontent.com :443... failed: Connection refused.
- 8idea将git代码版本还原到指定的版本_checkout tag or revision
- 9Springboot+Vue项目-基于Java+MySQL的免税商品优选购物商城系统(附源码+演示视频+LW)
- 10【免费】如何考取HarmonyOS应用开发者基础认证和高级认证(详细教程)_harmonyos云开发基础认证考试
计算机语言结构和篇章,自然语言处理笔记——学习自然语言处理前所要了解的知识...
赞
踩
学习自然语言处理前所要了解的知识
自然语言处理
自然语言与编程语言的区别
词汇量
结构化
歧义性
容错性
易变性
简略性
自然语言处理结构
语音、图像和文本
中文分词、词性标注、命名实体识别
信息抽取
文本分类和聚类
句法分析
语义分析与篇章分析
其他高级任务
自然语言处理的流派
机器学习
什么是机器学习
模型
特征
数据集
训练、训练集
监督学习、无监督学习与半监督学习
博客参考何晗所著的《自然语言处理入门》
自然语言处理
自然语言处理(Natural Language Processing, NLP) 是一门融合了计算机科学、人工智能及语言学的交叉学科。研究内容是通过机器学习等技术,让计算机学会处理人类语言,乃至实现理解人类语言或人工智能。
自然语言与编程语言的区别
词汇量
自然语言中的词汇量远远比编程语言中的关键字多。编程语言中的关键字数量是有限且确定的。而在自然语言中,以汉语为例,《现代汉语常用词表》中一共收录了56008个词条,且新词在不停创造。
结构化
自然语言是非结构化的,而编程语言是结构化的。
歧义性
自然语言中含有大量的歧义,且歧义根据语境不同而表现出特定的含义。
容错性
在编程语言中,必须要保证编程语句的绝对正确,否则会出现无法编译或者存在潜在BUG。而自然语言即使语句中存在错别字、病句等,人类还是可以猜出所要表达的意思。
易变性
编程语言与自然语言都是不断发展变化的。区别是编程语言变化发展较自然语言而言相对缓慢。
简略性
自然语言中常常出现对一个背景、常识等进行简略,如“老地方见”、“网吧对面”。这种现象对自然语言处理带来障碍。
自然语言处理结构
自然语言处理的结构如下图所示,主要有输入源(语音、图像和文本);中文分词、词性标注和命名实体识别;信息抽取;文本分类与文本聚类;句法分析等。
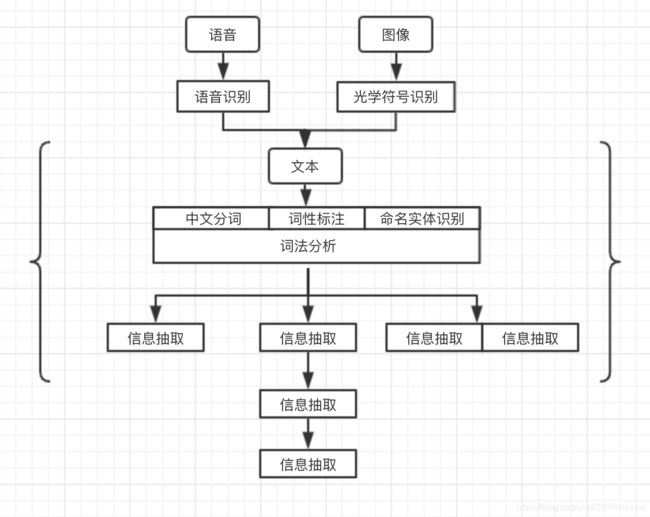
语音、图像和文本
自然语言处理一般将文本作为处理输入源。对于语音、图像显示的输入源,通过语音识别(Speech Recognition) 与光学符号识别(Optical Chatacter Recognition) 转化为文本进行处理。
中文分词、词性标注、命名实体识别
三者统称为词法分析,主要任务是将文本分解为有意义的词语(中文分词),确定词语的类别及进行简单的歧义消除(词性标注),识别较长的专有名词(命名实体识别)。
信息抽取
在经过词法分析阶段后,文本已部分结构化,既为有意义的单词列表。通过单词列表从简单的高频词汇到高级算法提取关键词。
文本分类和聚类
文本分类和文本聚类是对于文本输入源在文章级别进行的分析操作。
文本分类:将许多文档进行分类整理、判断一段话的褒贬义、判断邮件是否为垃圾邮件。
文本聚类:将相似的文档归档到一起,或者排除重复的文档。在这其中不关心文档的具体类别。
句法分析
对于句子的主谓宾结构进行分析,用于问答系统、搜索引擎和基于短语的机器翻译。
语义分析与篇章分析
语言分析侧重语义而非语法。包括的内容有确定一个词在语境中的含义(词义消歧),标注句子中的谓语与其他成分的关系(语义角色标注),分析句子中词语之间的语义关系(语义依存分析)。
其他高级任务
自动问答:小米的小爱同学,苹果的Siri
自动摘要:为一篇长文档生成摘要
机器翻译: 将一句话从一种语言翻译为另外一种语言
自然语言处理的流派
自然语言处理中的流派有:基于规则的专家系统;基于统计的学习方法
基于规则的专家系统:既为规则系统,根据特点领域专家手工定制的确定性流程来运行的系统称为基于规则的专家系统。其特点是要求设计者对所处理的问题具备输入的理解,并在可能的情况下全面考虑所有的发生情况。系统难以扩展,维护成本高。
基于统计的学习方法:使用统计学的方法让计算机自动学习语言(统计学习方法是机器学习的别称)。
现如今基本将规则与统计这两种方法结合起来,以统计学为主,以规则为辅进行自然语言处理。
机器学习
学习自然语言处理,不可避免的学习机器学习领域有关的知识。
什么是机器学习
机器学习的定义是:不直接编程却能赋予计算机提高其能力的方法
既机器学习是让机器学会算法的算法。通常称机器学习算法为 “元算法”,被学习的算法为 “模型”。
模型
模型是对现实问题的数学抽象,由一个假设函数以及一系列的参数构成。过程类似于数学建模。
特征
特征是指事物的特点转换的数值。
例如:在性别识别问题中,中国人的姓名的特征为:
对于中国人的人名,姓与其性别无关。则姓为无用特征,名为有用特征。对于“名”,在机器学习中赋予中国字对应的优先级(即为特征权重或参数模型)。机器学习算法根据数据自动觉得这些字的权重。这个过程称为 特征提取。在工程上不需要逐个字的去写特征,而是定义一套模板来提取特征。这种自动提取特征的模板为 特征模板
例如:名字为name的话,定义特征模板为name[1]+name[2],通过遍历一些姓名实例,即可取得其相应的特征。
数据集
让机器自动学习以得到模型参数的大量实例为习题集。其中“例子”称为 样本 。
习题集在机器学习领域称为 数据集 ,在自然语言处理领域称作 语料库 。
训练、训练集
在机器学习中对有标注的数据集上进行迭代学习的过程称为 训练 。训练所用到的数据集叫做 训练集。其中的每一遍学习都称为 一次迭代。
监督学习、无监督学习与半监督学习
监督学习
在进行机器学习时,采用的数据集是已标注过的,监督学习算法让机器先进行一遍学习,将学习所得的结果与答案对比,根据误差纠正模型的错误。监督学习的流程如下所示:
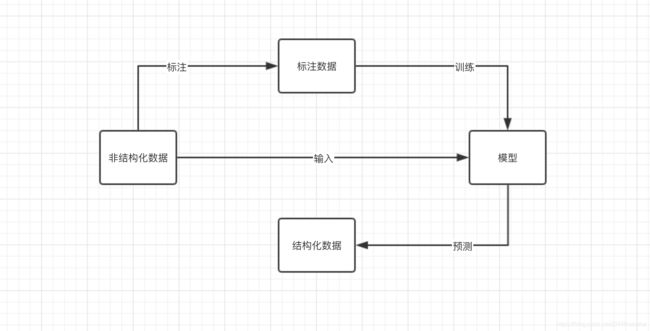
无监督学习
机器学习所采用的数据集没有经过标注,既数据集无答案。这种学习称作无监督学习。一般用于聚类和降维,因为两者都不需要数据标注。
半监督学习
半监督方法则是将监督学习方法与无监督学习方法友好的结合起来。既训练多个模型,对同一实例进行预测,会得到多个结果。如果这些结果大多一致,则可以将该实例和结果放到一起作为新的训练样本,扩充训练集。

