
- 1如何做好单元测试_简述如何做好单元测试的各个阶段的管理工作。
- 2C4.5算法详解(非常仔细)_c4.5决策树流程
- 3JAVA?:使用_? java
- 4【BUG日记】【Maven】【SpringBoot】启动项目的时候,报错:If you want an embedded database (H2, HSQL or Derby)
- 5Baidu Comate智能代码助手-高效代码编程体验_智能代码助手comate
- 6遇到软件测试职业瓶颈,如何突破_测试部门想突破的事
- 7XCode 开发证书配置(更换电脑后)_xcode accounts user manger
- 8Vue 使用 Video.js_vue使用video.js
- 9Redis - 高并发场景下的Redis最佳实践_翻过6座大山_redis 并发
- 10扫雷游戏(C语言实现,快三万字超详细教程+源码)_扫雷算法的流程图
【python实现网络爬虫(14)】python爬取酷狗中多类型音乐步骤详解(附全部源代码)_python爬取酷狗付费音乐
赞
踩
目标网址:酷狗音乐-赤伶,页面如下

爬虫逻辑:
【找到要获取特定音乐的url】>>>【找到该资源链接的url】>>>【封装获取音乐的函数】>>>【封装下载音乐的函数】
注意:
这两个获取url的顺序是和之前获取url的过程是反过来的,以往是获取外部页面的url后进入内部页面的url,然后再获取该页面的信息。
但是下载音乐(定向爬取数据),首先是要确定获取音乐的url(通过浏览器输入后点击可以直接播放–内部页面数据),然后再找其上一层的url(资源链接的url–外部页面数据)
1. 网页结构分析
1) 找到所要获取音乐的url
在目标页面鼠标右键选择’检查’,右上方菜单栏点击'Network',后进行网页刷新,接着查找右下区中php相关的文件,随后在'Preview'选项下点击'data',查找到'play_url',复制后面的内容使用浏览器打开后,就可以直接播放。图解如下

2) 找到资源链接的ur
在上述的界面点击'Preview'旁边的'Headers'菜单栏,这时候发现'General'下的第一个信息就是资源链接的url,如下
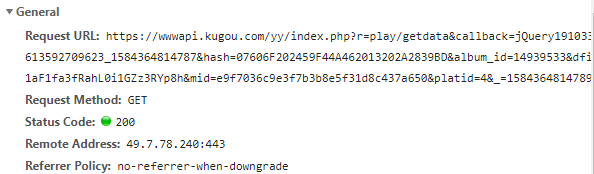
该页面下方还有一个信息,如下,可以对比url里面的内容和下面的信息

3) 简化资源链接的url
通过上面的对比,可以发现,url里面的内容除了主站域名外,其他的几乎都是有可确定的字段拼接而成的,可以尝试将字段进行删减,比如先去掉最后的&_=1584364814789数据,看看网页是否返回数据,其次再往上一个字段的数据进行尝试,直到无法返回数据为止。通过测试发现,当把hash对应的数据删除后,网站不返回请求数据了。因此简化的请求资源链接的url就如下
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19103336613592709623_1584364814787&hash=07606F202459F44A462013202A2839BD
- 1
–> 输出结果为:(至此两个url就获取完毕了)

2. 封装第一个函数
首先导入相关的库和设定相关的参数
import requests
import time
import math
import re
import os
import json
from bs4 import BeautifulSoup
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1) url参数的设置
要爬取资源的url基础元素就是主站域名加上查找数据返回的文件信息(index.php?),其中data里面的数据(url基础元素后面的搜索参数),就是上一步测试简化url所对应的数据,因为测试到删除hash字段数据对应的网址不再返回页面数据信息,所以需要保留,那么hash之前的字段数据自然也需要保留了。
url = 'https://wwwapi.kugou.com/yy/index.php?'
data = {
'r': 'play/getdata',
'callback': 'jQuery19108922952455208721_1584362904730',
'hash': '07606F202459F44A462013202A2839BD'
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
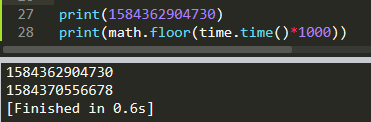
其中关于’callback’参数里面的1584362904730数据,是一个时间计时,可以对应time库里面的.time方法。由此可以自己创造一个时间计时(代表着访问时间)
2) 请求头设定
User-Agent和Referer数据都可以在当前的页面进行找到,但是没有cookie信息

cookie信息的获取,可以随便的点击一个有关post请求信息的页面,如下

最后构建的请求头如下:
dic_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'cookie': 'kg_mid=e9f7036c9e3f7b3b8e5f31d8c437a650; kg_dfid=1aF1fa3fRahL0i1GZz3RYp8h; _WCMID=1648cadf5e0f206e4bca9435; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1584362882; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1584362905; kg_mid_temp=e9f7036c9e3f7b3b8e5f31d8c437a650',
'Referer': 'https://www.kugou.com/song/'
}
- 1
- 2
- 3
- 4
- 5
3) 函数封装
① 初步封装获取返回的文本数据
def get_musci(): url = 'https://wwwapi.kugou.com/yy/index.php?' data = { 'r': 'play/getdata', 'callback': 'jQuery19108922952455208721_{}'.format(math.floor(time.time()*1000)), 'hash': '07606F202459F44A462013202A2839BD' } dic_headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', 'cookie': 'kg_mid=e9f7036c9e3f7b3b8e5f31d8c437a650; kg_dfid=1aF1fa3fRahL0i1GZz3RYp8h; _WCMID=1648cadf5e0f206e4bca9435; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1584362882; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1584362905; kg_mid_temp=e9f7036c9e3f7b3b8e5f31d8c437a650', 'Referer': 'https://www.kugou.com/song/' } html = requests.get(url,params=data, headers = dic_headers) print(html.text) get_musci()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
–> 输出结果为:(输出的结果也就是上面简化url测试时候网页返回的数据)
jQuery19108922952455208721_1584362904730({"status":1,"err_code":0,"data":
{"hash":"07606F202459F44A462013202A2839BD","timelength":266045,"filesize":4263645,
"audio_name":"HITA - \u8d64\u4f36","have_album":1,
"album_name":"\u8d64\u4f36","album_id":"14939533",
"img":"http:\/\/imge.kugou.com\/stdmusic\/20190130\/20190130172751733550.jpg",
"have_mv":1,"video_id":"1449487","author_name":"HITA",
"song_name":"\u8d64\u4f36",
......
"play_backup_url":"https:\/\/webfs.cloud.kugou.com\/20200316223\/dc5586939d67e36282f1fdf34d313860\/G093\/M04\/1E\/15\/_YYBAFu5_rmAfzpPAEEO3Q5ZQDY336.mp3"
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
② 文本数据清洗转化为可识别类型数据
输出结果发现和之前获取腾讯新闻返回的结果有点类似,需要将数据转化为可识别的类型,然后进行程序导入,这里如果还按照数数的方法就有点效率低下了,使用.index的方法进行
start = html.text.index('{')
end = html.text.index('})')+1
json_data = json.loads(html.text[start:end])
print(json_data)
- 1
- 2
- 3
- 4
–> 输出结果为:
{'status': 1, 'err_code': 0, 'data':
{'hash': '07606F202459F44A462013202A2839BD', 'timelength': 266045,
'filesize': 4263645, 'audio_name': 'HITA - 赤伶', 'have_album': 1,
'album_name': '赤伶', 'album_id': '14939533',
'img': 'http://imge.kugou.com/stdmusic/20190130/20190130172751733550.jpg',
'have_mv': 1, 'video_id': '1449487', 'author_name': 'HITA',
'song_name': '赤伶', 'lyrics': '\ufeff[id:$00000000]\r\n[ar:HITA]\r\n[ti:赤伶]\r\n[by:]\r\n[hash:07606f202459f44a462013202a2839bd]\r\n[al:]\r\n[sign:]\r\n[qq:]\r\n[total:266045]\r\n[offset:0]\r\n[00:00.78]HITA - 赤伶\r\n[00:01.74]作词:清彦\r\n[00:02.85]作曲:李建衡\r\n[00:04.33]编曲:何天程\r\n[00:05.70]昆曲念白:朱虹\r\n[00:06.91]混音:何天程\r\n[00:08.13]二胡:钟意\r\n[00:09.04]笛子:笛呆子囚牛\r\n[00:32.56]戏一折水袖起落\r\n[00:38.31]唱悲欢唱离合无关我\r\n[00:45.34]扇开合锣鼓响又默\r\n[00:51.26]戏中情戏外人凭谁说\r\n[00:57.68]惯将喜怒哀乐都融入粉墨\r\n[01:02.89]陈词唱穿又如何\r\n[01:06.28]白骨青灰皆我\r\n[01:10.52]乱世浮萍忍看烽火燃山河\r\n[01:15.88]位卑未敢忘忧国\r\n[01:18.96]哪怕无人知我\r\n[01:23.06]台下人走过不见旧颜色\r\n[01:29.43]台上人唱着心碎离别歌\r\n[01:36.06]情字难落墨\r\n[01:38.79]她唱须以血来和\r\n[01:42.83]戏幕起戏幕落谁是客\r\n[01:53.86]啊\r\n[01:54.82]浓情悔认真\r\n[01:59.85]回头皆幻景\r\n[02:06.73]对面是何人\r\n[02:19.54]戏一折水袖起落\r\n[02:25.04]唱悲欢唱离合无关我\r\n[02:32.38]扇开合锣鼓响又默\r\n[02:37.99]戏中情戏外人凭谁说\r\n[02:44.61]惯将喜怒哀乐都藏入粉墨\r\n[02:49.87]陈词唱穿又如何\r\n[02:53.20]白骨青灰皆我\r\n[02:57.55]乱世浮萍忍看烽火燃山河\r\n[03:02.66]位卑未敢忘忧国\r\n[03:06.00]哪怕无人知我\r\n[03:10.10]台下人走过不见旧颜色\r\n[03:16.52]台上人唱着心碎离别歌\r\n[03:23.04]情字难落墨\r\n[03:25.82]她唱须以血来和\r\n[03:29.86]戏幕起戏幕落终是客\r\n[03:39.16]你方唱罢我登场\r\n[03:45.89]莫嘲风月戏莫笑人荒唐\r\n[03:52.31]也曾问青黄\r\n[03:55.09]也曾铿锵唱兴亡\r\n[03:58.99]道无情道有情怎思量\r\n[04:08.76]道无情道有情费思量\r\n',
'author_id': '84981', 'privilege': 8, 'privilege2': '1000',
'play_url': 'https://webfs.yun.kugou.com/202003162300/2842f18911bdac380c74dcc270a7ab21/G093/M04/1E/15/_YYBAFu5_rmAfzpPAEEO3Q5ZQDY336.mp3',
'authors': [{'author_id': '84981', 'is_publish': '1', 'sizable_avatar': 'http://singerimg.kugou.com/uploadpic/softhead/{size}/20191128/20191128094941269.jpg', 'author_name': 'HITA', 'avatar': 'http://singerimg.kugou.com/uploadpic/softhead/400/20191128/20191128094941269.jpg'}],
'is_free_part': 0, 'bitrate': 128, 'audio_id': '44024421',
'play_backup_url': 'https://webfs.cloud.kugou.com/202003162300/c30ab2260877af66297571054b9d03b2/G093/M04/1E/15/_YYBAFu5_rmAfzpPAEEO3Q5ZQDY336.mp3'}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
③ 获取音乐名称和具体的音乐url
song_name = json_data['data']['song_name']
song_author = json_data['data']['author_name']
song_url = json_data['data']['play_url']
name = song_name+ '-'+ song_author
print(song_url)
print(name)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
–> 输出结果为:(下面的网址对应:酷狗音乐-赤伶)
https://webfs.yun.kugou.com/202003162306/138ff21bf052e04ec4a7ef07ebd2c514/G093/M04/1E/15/_YYBAFu5_rmAfzpPAEEO3Q5ZQDY336.mp3
赤伶-HITA
- 1
- 2
3. 封装第二个函数
获得音乐资源后,就可以直接将音乐下载到本地了
def download_music(url,name):
print('正在下载音乐......')
with open(f'{name}.mp3','wb') as f:
f.write(requests.get(url).content)
print('音乐下载完毕')
- 1
- 2
- 3
- 4
- 5
最后在第一个函数中调用该函数即可输出到本地
download_music(song_url,name)
- 1
–> 输出结果为:

4. 拓展
已经可以下载所选定的音乐了,那么可不可以创建一个音乐的下载器呢?那么会员就不用开了,直接白嫖了呢,再尝试一下其他的歌曲,比如我想白嫖周杰伦的晴天,还是相同的步骤
1) 单个音乐文件下载
只需要对比一下获取资源链接的url即可
#晴天资源的url
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19105578760695965006_1584372571110&hash=3BD5C05B9F8D082BA3C9425A1A712394
#赤伶资源的url
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19103336613592709623_1584364814787&hash=07606F202459F44A462013202A2839BD
- 1
- 2
- 3
- 4
- 5
尝试只替换hash参数数据,其余的不变
data = {
'r': 'play/getdata',
'callback': 'jQuery19108922952455208721_{}'.format(math.floor(time.time()*1000)),
'hash': '3BD5C05B9F8D082BA3C9425A1A712394'
}
- 1
- 2
- 3
- 4
- 5
–> 输出结果为:(事实上证明还是要开会员的,获取的音乐资源只有一分钟的时长,但是对于一些网易云音乐没有版权的,但不是vip的音乐是可以批量下载的(赤伶就属于这一种))

2) 音乐文件批量下载
输出结果显示,只需要通过修改'hash'字段就可以实现音乐数据的下载,那么批量数据下载的前提就是找到每首歌对应的'hash'值
第一种:直接在音乐名称的标签上可获得'hash'数据
比如在酷狗首页里面的任意一个歌单

这里选择每周推荐的歌单进行示例,首先确认歌曲标签中的'hash'数据(也就是data=后面的内容)

将上面红框的内容带到上面的程序中去,测试一下是否可以正常下载音乐文件,运行结果发现会报错,然后进入歌曲页面找到真正的’hash’数据,如下,对比发现,上面的标签数据最后面多了一些内容

尝试着把最后的多余部分去掉后再次运行,结果可以正常下载音乐

那么就可以封装第三个函数批量的获取某个推荐歌单的全部音乐了
def get_hash_data():
url = 'https://www.kugou.com/yy/special/single/547134.html'
html = requests.get(url)
soup = BeautifulSoup(html.text,'lxml')
hash_datas_a = soup.select('#songs li a')
for hash_data_a in hash_datas_a[:5]:
hash_data = hash_data_a['data'].split('|')[0]
get_musci(hash_data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
–> 输出结果为:(这里只切片了五首歌曲,进行演示)

第二种:在音乐名称的标签上不可获得'hash'数据
比如榜单中的音乐数据,这里以网络红歌榜为例,比如定位’桥边姑娘’这个音乐的标签信息,如下(可以发现标签信息上并没有’hash’数据)

这时候可以在标签信息窗口调用搜索窗口(ctrl + f),手动输入hash进行匹配,可以发现,所有音乐的’hash’都被放置在一起了,如下(刚好和右边的音乐数据量对应上)

封装第四个函数,这里就需要使用到正则表达式了
def get_hash_data1():
url = 'https://www.kugou.com/yy/rank/home/1-23784.html?from=rank'
html = requests.get(url)
# print(html.text)
hash_data_lst = re.findall(r'{"Hash":"(.*?)"', html.text)
print(hash_data_lst)
get_hash_data1()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
–> 输出结果为:(共22个'hash'数据)
['628EA5873E5EECC9563C7CA0B674A077', 'BB01737DD38BEABE31496E1088010AD2',
'FB5FCE4EB17ABE6B7344035B25A0BBB7', '3337C18539D5BB00D8027D653D536A35',
'EABDDF85153719DA1991B20ABE5FB80D', 'D5F247E40952E83473C8CA9647C524E2',
'7927879CA5664B8E7B90E3688EE2AA29', '69CE89784C4B69D2D57888F4D1F4F2F2',
'ACCC0AD7997B3F48BD61C05AD5BC94FD', 'FAEDD01C425118BA343648B5AF35861F',
'ED8DBD8AE97359912A8AEC71C61758D2', '7707BE115CF9131E3AEF782D294155D4',
'42FD96EE5BC779A686540E029813219A', 'F36AB94DA7FAF948248BE675E43C3EF5',
'0BCD762E2FA1984818B3CCCDB16A5424', 'B5C7BB5A00C84783C10259E21B7831B3',
'DF2E5B8C4F4C9CE4539875BFFF818163', 'F831122AA78D17AF1C67050CD6235917',
'B66DA0F3955DF61FF7899A9F62971509', '004B4AF5908B4322B9E80C6265AB3BBA',
'04E4C1D0AFB9DEEF3B0834AA1F71B654', 'D8E40DA7F51C0486224E008A3B6ABD45']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
接着就可以直接进行遍历输出,并进行音乐的下载,这里还是以下载5首歌曲进行演示
for hash_data in hash_data_lst[:5]:
get_musci(hash_data)
- 1
- 2
–> 输出结果为:(至此工作全部完结)

5. 全部代码
import requests import time import math import re import os import json from bs4 import BeautifulSoup def get_musci(hash_data): url = 'https://wwwapi.kugou.com/yy/index.php?' data = { 'r': 'play/getdata', 'callback': 'jQuery19108922952455208721_{}'.format(math.floor(time.time()*1000)), 'hash': hash_data } dic_headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', 'cookie': 'kg_mid=e9f7036c9e3f7b3b8e5f31d8c437a650; kg_dfid=1aF1fa3fRahL0i1GZz3RYp8h; _WCMID=1648cadf5e0f206e4bca9435; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1584362882; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1584362905; kg_mid_temp=e9f7036c9e3f7b3b8e5f31d8c437a650', 'Referer': 'https://www.kugou.com/song/' } html = requests.get(url,params=data, headers = dic_headers) #print(html.text) start = html.text.index('{') end = html.text.index('})')+1 json_data = json.loads(html.text[start:end]) song_name = json_data['data']['song_name'] song_author = json_data['data']['author_name'] song_url = json_data['data']['play_url'] name = song_name+ '-'+ song_author print(song_url) print(name) download_music(song_url,name) def download_music(url,name): print('正在下载音乐......') with open(f'{name}.mp3','wb') as f: f.write(requests.get(url).content) print('音乐下载完毕') def get_hash_data(): url = 'https://www.kugou.com/yy/special/single/547134.html' html = requests.get(url) soup = BeautifulSoup(html.text,'lxml') hash_datas_a = soup.select('#songs li a') for hash_data_a in hash_datas_a[:5]: hash_data = hash_data_a['data'].split('|')[0] get_musci(hash_data) #get_hash_data() def get_hash_data1(): url = 'https://www.kugou.com/yy/rank/home/1-23784.html?from=rank' html = requests.get(url) # print(html.text) hash_data_lst = re.findall(r'{"Hash":"(.*?)"', html.text) #print(hash_data_lst) for hash_data in hash_data_lst[:5]: get_musci(hash_data) get_hash_data1()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68

