
热门标签
热门文章
- 1灰度图恢复(100%用例)C卷(Java&&Python&&C++&&Node.js&&C语言)
- 2Apache Velocity漏洞CVE-2020-13936修复记录
- 3idea docker 内网应用实践
- 4error C2099: initializer is not a constant 或者error C2099:初始值设定项不是常量_error c2099: 初始值设定项不是常量
- 5机器学习-聚类算法Kmeans【手撕】
- 6【Linux operation 11】 - Linux 查看系统及内核信息
- 7JDK 各版本汇总表_jdk版本
- 8关于Spring cloud Gateway集成nacos 实现路由到指定微服务的方式总结_spring cloud gateway简写版路由配置无法转到对应微服务问题解决
- 9第四章 字符串_python实现将用户输入的十进制整数转换为指定进制的功能
- 10一文详解docker compose
当前位置: article > 正文
基于matlab中机器学习工具箱中随机森林模型简单易上手对房价预测实战_房价预测模型matlab
作者:Monodyee | 2024-02-16 15:01:28
赞
踩
房价预测模型matlab
一、数据介绍
输入变量:
区域
卧室数
客厅数
房屋面积
楼层高低
是否是地铁房
是否是学区房
输出变量:
房价(万元/平方米)
二、数据处理
2.1.将定性变量转换为虚拟变量
在数据集中,发现楼层高低,是否是地铁房,是否是学区房这三个输入变量均为定性变量,故考虑转为虚拟变量01,记楼层高为1,楼层低为0,是地铁房为1,是学区房为1,否则为0
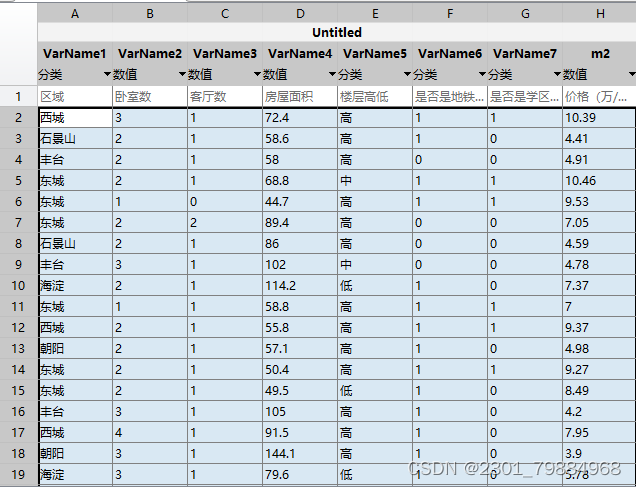
2.2 将转换好的数据集导入matlab中,分为训练集与测试集,记训练集为data1,测试集为data2,其中需要将matlab默认的一些指标更改,在这道例题中是否是地铁房,是否是学区房,matlab默认是数值变量,我们需要手动修改为分类变量,如图所示
三、随机森林模型的建立
3.1随机森林模型的介绍
随机森林算法对大规模数据具有良好性能,核心思想是结合随机特征子空间方法形成性能较弱的多个分类回归决策树,经过一定规则组成森林,最终结果由森林中所有的决策树投票得出。
随机森林
算法流程主要包括 3 个步骤:对训练数据集进行随机抽取获得训练子
集、随机选取特征子集形成决策树、并行训练每个决策树获得对应结果:
设
X
是一个包含
m
个特征的输入向量,
Y
是输出值,  是一个包含 n
个观测值(Xi,Yi)的训练集。
是一个包含 n
个观测值(Xi,Yi)的训练集。
特征选择目前比较流行的方法是信息增益、增益率、基尼系数和卡方检验。这里 主要介绍基于基尼系数(GINI)的特征选择,因为随机森林采用的 CART 决策树就是基 于基尼系数选择特征的。
基尼系数的选择的标准就是每个子节点达到最高的纯度,即落在子节点中的所有 观察都属于同一个分类,此时基尼系数最小,纯度最高,不确定度最小
3.2利用matlab工具箱创建随机森林模型
利用matlab的工具箱,找到回归学习器,在模型的选择中找到树集成中的装袋数,然后点击训练,训练结束后,点击生成函数(2021a版本),在2017a版本matlab中,点击导出函数都是可以的。
利用matlab工具箱生成的函数如下:
- trainingData=data1
- inputTable = trainingData;
- predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4', 'VarName5', 'VarName6', 'VarName7'};
- predictors = inputTable(:, predictorNames);
- response = inputTable.m2;
- isCategoricalPredictor = [true, false, false, false, true, true, true];
-
- % 训练回归模型
- % 以下代码指定所有模型选项并训练模型。
- template = templateTree(...
- 'MinLeafSize', 8);
- regressionEnsemble = fitrensemble(...
- predictors, ...
- response, ...
- 'Method', 'Bag', ...
- 'NumLearningCycles', 30, ...
- 'Learners', template);
-
- % 使用预测函数创建结果结构体
- predictorExtractionFcn = @(t) t(:, predictorNames);
- ensemblePredictFcn = @(x) predict(regressionEnsemble, x);
- trainedModel.predictFcn = @(x) ensemblePredictFcn(predictorExtractionFcn(x));
-
- % 向结果结构体中添加字段
- trainedModel.RequiredVariables = {'VarName1', 'VarName2', 'VarName3', 'VarName4', 'VarName5', 'VarName6', 'VarName7'};
- trainedModel.RegressionEnsemble = regressionEnsemble;
- trainedModel.About = '此结构体是从回归学习器 R2021a 导出的训练模型。';
- trainedModel.HowToPredict = sprintf('要对新表 T 进行预测,请使用: \n yfit = c.predictFcn(T) \n将 ''c'' 替换为作为此结构体的变量的名称,例如 ''trainedModel''。\n \n表 T 必须包含由以下内容返回的变量: \n c.RequiredVariables \n变量格式(例如矩阵/向量、数据类型)必须与原始训练数据匹配。\n忽略其他变量。\n \n有关详细信息,请参阅 <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appregression_exportmodeltoworkspace'')">How to predict using an exported model</a>。');
-
- % 提取预测变量和响应
- % 以下代码将数据处理为合适的形状以训练模型。
- %
- inputTable = trainingData;
- predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4', 'VarName5', 'VarName6', 'VarName7'};
- predictors = inputTable(:, predictorNames);
- response = inputTable.m2;
- isCategoricalPredictor = [true, false, false, false, true, true, true];
-
- % 执行交叉验证
- partitionedModel = crossval(trainedModel.RegressionEnsemble, 'KFold', 5);
-
- % 计算验证预测
- validationPredictions = kfoldPredict(partitionedModel);
-
- % 计算验证 RMSE
- validationRMSE = sqrt(kfoldLoss(partitionedModel, 'LossFun', 'mse'));
- % 交叉验证后得到的测试集上的衡量指标
- isNotMissing = ~isnan(validationPredictions) & ~isnan(response);
- format long g % 数值显示的精度变高
- validationSSE = sum(( validationPredictions - response ).^2,'omitnan') ;
- validationMSE = sum(( validationPredictions - response ).^2,'omitnan') / numel(response(isNotMissing));
- validationRMSE = sqrt(sum(( validationPredictions - response ).^2,'omitnan') / numel(response(isNotMissing) ));
- validationMAE = sum(abs( validationPredictions - response),'omitnan') / numel(response(isNotMissing));
- validationMAPE = sum(abs((validationPredictions - response)./response),'omitnan') / numel(response(isNotMissing));
- validationSMAPE = sum(abs(validationPredictions - response)./((abs(response)+abs(validationPredictions))/2),'omitnan') / numel(response(isNotMissing));
- validationR2 = 1 - sum(( validationPredictions - response ).^2,'omitnan') / sum((response - mean(response,'omitnan')).^2,'omitnan');
- validation_result = table(validationSSE,validationMSE,validationRMSE,validationMAE,validationMAPE,validationSMAPE,validationR2)
- format short
- predict_y = trainedModel.predictFcn(data2)

这样就通过随机森林模型将房价预测好了,但要评价该模型建立的好坏,需要通过R方,即拟合优度\决定系数\可决系数)决定,这里是matlab关于拟合优度的官方链接https://ww2.mathworks.cn/help/stats/coefficient-of-determination-r-squared.html
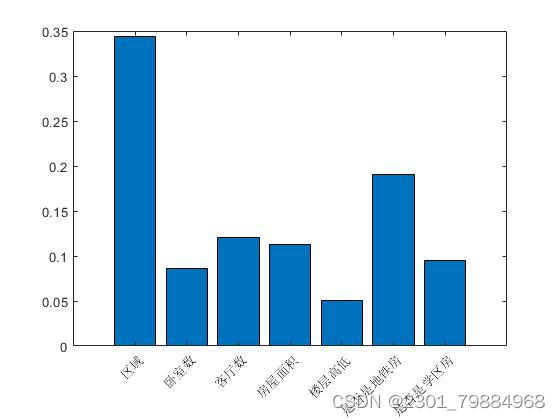
在随机森林模型中,特征选择也很重要,一些特征可能会影响该模型的效果,故我们选择查看各指标的重要性
- importance =oobPermutedPredictorImportance(regressionEnsemble);
- % 可以将重要性归一化到[0 1]区间内 % https://ww2.mathworks.cn/matlabcentral/answers/783611-need-predictor-importance-in-random-forest-expressed-as-a-percentage#answer_671247
- importance(importance<0) = 0;
- importance = importance./sum(importance)
- figure(1)
- h_bar = bar(importance);
- h_bar.Parent.XTickLabel ={'区域','卧室数','客厅数','房屋面积','楼层高低','是否是地铁房','是否是学区房'};
- h_bar.Parent.XTickLabelRotation = 45;
- h_bar.Parent.TickLabelInterpreter = 'none';
效果如图所示
至此,利用matlab的工具箱对房价预测的实战例题已求解完毕
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
相关标签

