
热门标签
热门文章
- 1Vue 登录权限配置_vue3登录游客登录和管理员登录
- 2STM32_PWM呼吸灯_stm32pwm的呼吸灯设计总结
- 3python网球比赛模拟_2019-05-12 Python之模拟体育竞赛
- 4如何理解期权的保证金和权利金的区别?
- 5python做应用程序错误_pythonw.exe应用程序错误
- 6Python+Selenium详解(超全)_selenium,python
- 7云服务器搭载zookeeper集群遇到的坑,java.net.BindExxeption和java.net.SoketTimeoutException_quorumlistenonallips=true
- 8提取数据_python pdf文件提取表格数据
- 9【联邦学习+区块链】TORR: A Lightweight Blockchain for Decentralized Federated Learning_federated learning blockchain call for paper
- 10【编程入门题--二维数组的转置】
当前位置: article > 正文
LLM:LLaMA模型和微调的Alpaca模型
作者:weixin_40725706 | 2024-02-14 20:06:22
赞
踩
alpaca模型
LLaMA模型
简单了解[LeCun狂赞:600刀GPT-3.5平替! 斯坦福70亿参数「羊驼」爆火,LLaMA杀疯了]
论文原文:https://arxiv.org/abs/2302.13971v1
预训练数据

模型架构
模型就是用的transformer的decoder,模型设计的不同点在于:
1 Position Embedding:RoPE旋转位置编码rotary-embedding
删除了绝对位置嵌入,而是在网络的每一层添加了Sujianlin等人(2021)引入的旋转位置嵌入(RoPE)。
现阶段被大多数模型采用的位置编码方案,具有很好的外推性。
2 Feedforward Layer
采用SwiGLU;Feedforward变化为(8/3)倍的隐含层大小,即2/3*4d而不是4d。
SwiGLU激活函数:
Swish=x⋅sigmoid(βx)
![]()
源于PaLM中使用的[SwiGLU激活函数]
3 Layer Normalization: 基于RMSNorm的Pre-Normalization
同GPT3。
Pre-Normalization

RMS Pre-Norm

不同模型的超参数的详细信息。

训练细节
使用AdamW优化器进行训练(Loshchilov和Hutter,2017),具有以下超参数:β1=0.9,β2=0.95。
使用余弦学习速率表,使得最终学习速率等于最大学习速率的10%。我们使用0.1的权重衰减和1.0的梯度裁剪。
使用2000个预热步骤,并根据模型的大小改变学习速度和批量大小。
Alpaca模型
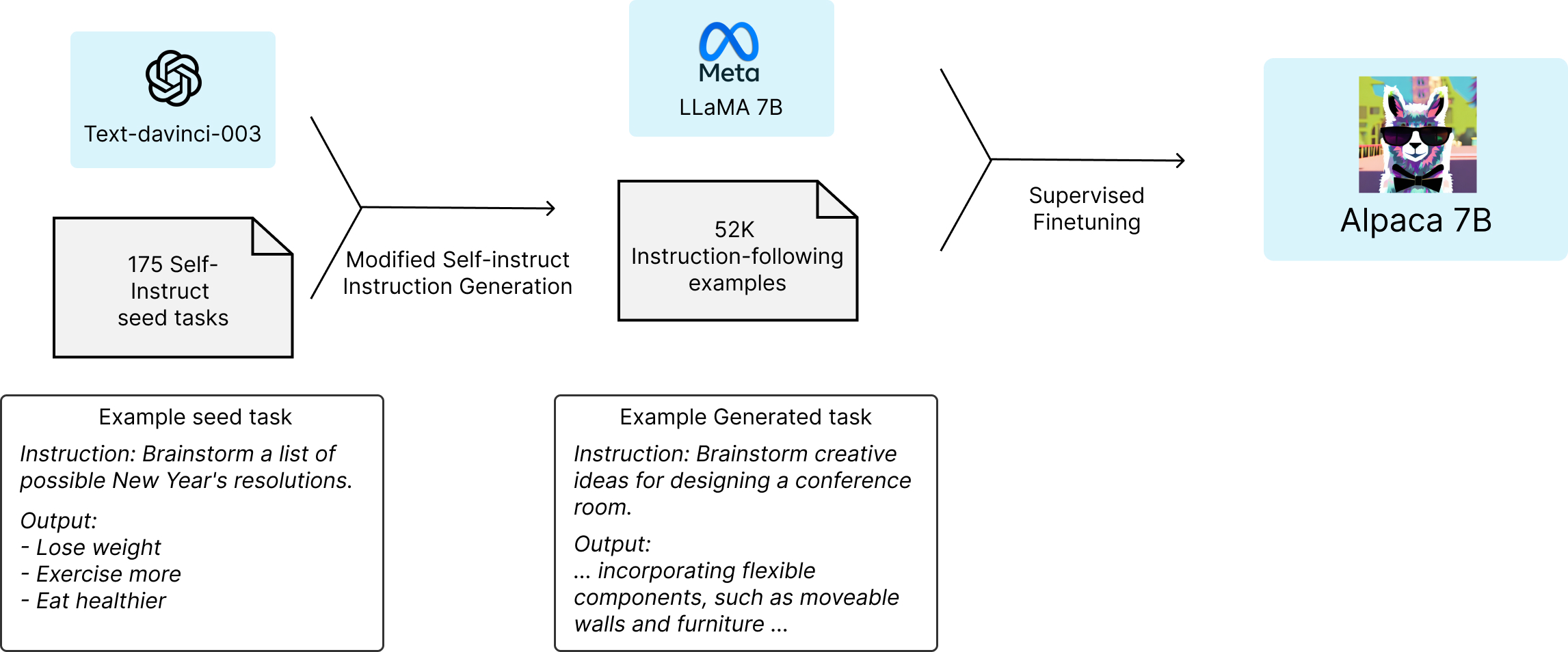
中文聊天aipaca
GitHub - ymcui/Chinese-LLaMA-Alpaca
内容导引
| 章节 | 描述 |
|---|---|
| ⏬模型下载 | 中文LLaMA、Alpaca大模型下载地址 |
| 【wpsshop博客】 推荐阅读 相关标签 Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。 |

