
热门标签
热门文章
- 1python写购物商城程序,python制作小程序商城_python 实现(简单的一个购物商城小程序)...
- 2【opencv】图像处理之相似变换、仿射变换、透视变换_图像相似变换
- 3【Rust blog】Rust + Flutter 高性能的跨端尝试
- 4深度学习Imagenet caffe AlexNet 实验步骤_fillcnn实验室入口使用教程
- 5Qt总结之七:QPaintEvent绘制雷达图(二)_qt雷达p显
- 6VMware16安装Mac11.1Big Sur遇到“客户机操作系统已禁用 CPU。请关闭或重置虚拟机。”解决方案_vmware操作系统已禁用cpu
- 7超实用!整理了34个Python自动化办公库!_python日常办公
- 8基于CentOS7.X系统的maven私服Nexus搭建_nexus3.59
- 9el-table使用合并行和列功能_el-table合并行
- 103秒开服《幻兽帕鲁》!如何抓住游戏背后的云计算机遇?
当前位置: article > 正文
给大语言模型“开个眼”,看图说话性能超CLIP!斯坦福等新方法无需多模态预训练丨开源...
作者:不正经 | 2024-02-17 23:19:53
赞
踩
lens csdn
西风 发自 凹非寺
量子位 | 公众号 QbitAI
不靠多模态数据,大语言模型也能看得懂图?!
话不多说,直接看效果。
就拿曾测试过BLIP-2的长城照片来说,它不仅可以识别出是长城,还能讲两句历史:

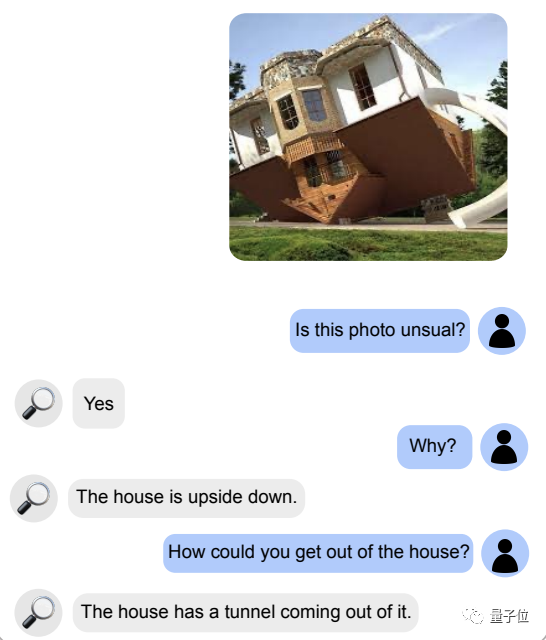
再来一个奇形怪状的房子,它也能准确识别出不正常,并且知道该如何进出:
故意把“Red”弄成紫色,“Green”涂成红色也干扰不了它:

这就是最近研究人员提出的一种新模块化框架——LENS声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/102282
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

