
算法竞赛命题指南(命题流程、Polygon的使用等)_polygon出题
赞
踩
本文主要讲述人经验,可能与实际理解存在偏差,亦有片面的观点,还请见谅!
部分内容引自OIWIKI:https://oi-wiki.org/
一.引言
命好一场题目,是一个艰巨的任务。它非常考察个人水平和团队合作能力。在出题前,你应该做好以下准备:
抱有认真负责的态度
出题是给别人做的,比起展示自己,更多是为了是服务他人。算法竞赛是选手之间的竞赛,而不是出题人与做题人之间的较量。因此,出题不应以考倒选手为目标(当然,适当的防 AK 与良好的区分度也是非常重要的),而应当让选手能在比赛中有所收获。花费足够的时间精力去学习如何出题并认真负责地出题非常重要。
在命题前,请与命题团队认真开讨论会,确定比赛的定位,讨论比赛的受众群体,设计、划分题目的难易度,设计每道题目的考察知识点等等。请重视讨论会,没有良好的沟通,题目质量必然参差不齐,带来糟糕的比赛体验。
做好耗费大量时间的准备
如果想要认真地出题,就必然要花费大量的时间。如果不做好心理准备,可能导致比赛准备匆忙,质量不过关,也可能在事后由于没有将时间花费在学习上而懊悔。但出题也可以带来很多美好的回忆,如果真的对出题抱有兴趣,并做好了充分的心理准备,出题带来的收获也能够弥补那些花费的时间。
如果要准备一场标准ICPC比赛(校赛级别),请至少在赛前1个月开始命题计划。如果准备一场选拔赛,请至少在赛前半个月开始命题。短期准备命制的题目可能不乏有好题,但垃圾题会比好题多的多!如果赛前几天才开始命题,你将面临一场充满锅和抱怨的比赛,此时建议直接拉原题,不要在花心思去准备新题。
命题组的沟通
一般而言,不建议5人以上同时命制一场比赛,众口难调,作为比赛的组织者会非常被动,从而导致比赛题目难度不一。
请务必于组内成员保持良好的沟通!并选择尽可能熟悉的人来命题。
二.大脑篇
想命好一道题目,是非常考察命题者的综合素养的。
你需要具备一定的刷题量,通过刷题你可以了解设计题目的各种小 t r i c k trick trick,以及想到一些合适的 i d e a idea idea;
你需要拥有清晰的命制思路,确保命制过程严丝合缝,否则你会命出一道锅题;
你需要有至少清晰的表达能力,能表达你的题目意图而不产生歧义;
你需要了解并熟练运用各种工具,以命制符合规格的题目;
…
1.idea 的来源
- 受到已有题目的启发(但不能照搬或无意义地加强,如:序列题目搬到仙人掌上)。
- 受到学过的知识点的启发(但不能毫无联系地拼凑知识点)。
- 从生活/游戏中受到启发(但注意不要把游戏出成大模拟)。
- 不知道为什么,就是想到了一道题。
2.什么样的 idea 是不好的
关于原题
原题大致可分为完全一致、几乎一致和做法一致三种。
- 完全一致:使用一题的 AC 代码可以 AC 另一题。
- 几乎一致:由一题的 AC 代码改动至另一题的 AC 代码可以由一个不会该题的人完成。
- 做法一致:核心思路、做法一致,但代码实现上、不那么关键的细节上有差异。
这三种原题自下而上为包含关系。
以下情况不应出现:
- 在明知有“几乎一致”的原题的情况下出原题。
- 由于未使用搜索引擎查找导致自己不清楚有原题,从而出了“几乎一致”的原题。
- 在“做法一致”的原题广为人知(如:NOIP、NOI 原题)时出原题。
- 在带有选拔性的考试的非送分题中出现“做法一致”的原题。
以下情况最好不要出现:
- 在明知有至少为“做法一致”的原题的情况下出原题。
- 由于未使用搜索引擎查找导致自己不清楚有原题,从而出了“做法一致”的原题。
- 在任何情况下出“几乎一致”的原题。
可以放宽要求的例外情况:
- 校内模拟赛。
- 以专题训练为目的的模拟赛。
- 难度较低的比赛,或是定位为送分题的题目。
关于毒瘤题
“毒瘤题”是一个非常模糊而主观的观念,在这只是引用一些前人关于此的探讨,加以自己的一些理解。这个话题是非常开放的,欢迎大家来发表自己的观点。
一道好题不应该是两道题拼在一起,一道好题会有自己的 idea——而它应该不加过多包装地突出这个 idea。
一道好题应该新颖。真正的好题,应该是能让人脑洞出新的好题的好题。
——[vfk《UOJ 精神之源流》][1]
例子:「XR-1」柯南家族,做法的前后两部分完全割裂,前半部分为 「模板」树上后缀排序,后半部分是经典树上问题。就算是随意输入树的点权,依然可以做第二部分,前后部分没有联系。
一类 OI 题以数学为主,无论是题目描述还是做法都是数学题的特征,并且解法中不含算法相关的知识点,这类 OI 题目统称为纯数学题。
——[王天懿《论偏题的危害》][2]
经典例子:NOIP2017 小凯的疑惑
OI 中的数学题与其它数学题的区别,也是体现 OI 本质的一个特点,是 OI 中的数学题往往重点不在答案 是什么,而在如何 加快 答案的计算。如果一道题考察的重点是“怎么算”而非“怎么快速计算”,这样的数学题一般都是不适合出在 OI 中的。
一部分偏题中牵涉到了大学物理的内容,导致选手在面对这些从未接触过物理知识点时变得不知所措,造成了知识上的隔膜。
——[王天懿《论偏题的危害》][2]
经典例子:「清华集训 2015」多边形下海
不止是物理,OI 题目中不应过多涉及到其它学科的知识,如果涉及应当给予详细的解释,不应使其它学科的知识作为解题的重大障碍。
一道好题无论难度如何,都应该具有自己的思维难度,需要选手去思考并发现一些性质。
一道好题的代码可以长,但一定不是通过强行嵌套或者增加条件而让代码变长,而是长得自然,让人感觉这个题的代码就应该是这么长。
——[王天懿《论偏题的危害》][2]
经典例子:「SDOI2010」猪国杀,「集训队互测 2015」未来程序·改
在一般的 OI 比赛中,思维难度应占主要部分。当然,如 THUWC/THUSC 的 Day 2+ 那样的工程题也有其存在的道理——毕竟体验营的目的除了考察选手的算法设计能力,还有和大学学习对接的工程代码以及文档学习能力。但在一般的 OI 比赛中,考察更多的应当还是算法设计与思维能力。
三.题面篇
本部分引自 OI-Wiki:出题 - OI Wiki (oi-wiki.org)
1.题目背景
题目背景最好尽量简短。在题目背景较长时,应当与题目描述分开。
需要绝对避免题目背景严重影响题意的理解。
必要时,可以提供与背景结合的题目描述与简洁的题目描述两个版本。
2.题目描述
简而言之,题目描述需要 清晰易懂。
题面中的每个可能不被理解的定义都应得到解释,不应凭空冒出未加定义的概念。例如:在 CF1172D Nauuo and Portals 中,你必须在题面中解释什么是“传送门”。
题面中涉及到的每个概念应当使用单一的词汇来描述。例如:不应一会儿说“费用”,一会儿说“代价“。
不应不加说明地使用与原义、常见义不同的词汇。例如:不应不加说明地用“路径”代指一条边。
你需要保证你的题面不会自相矛盾。例如:在 CF1173A Nauuo and Votes 中,没有把 “?” 作为一种 “result”,是因为 “?” 的含义是 “there are more than one possible results”。
你需要保证你的题面不能被错误理解而自圆其说,即使这种理解是反常识、没有人会这么去想的。例如:在 CF1172D Nauuo and Portals 中,之所以要繁琐地定义 “walk into” 并与 “teleport” 区分,是为了防止这种理解:通过传送门可以到另一个传送门,而到了传送门会传送,因此会反复横跳。
顺着读题目描述应当能看懂每一句话,并理解题目的任务与要求。至少在紧接着的下一段话中疑惑能够得到解释,而不是需要在若干段后才能得到解释,或者要看了输入输出格式才能明白题意,甚至需要根据样例来猜题意。例如:在 「GuOJ Round #1」琪露诺的冰雪宴会 中,在输出格式才第一次出现了题目的目标“雾之湖最终能接收到的最大水量”,再加上“灵梦当然能很快算出来清理完全部小溪的总费用是多少”这句带有误解性质的话,更容易使人读错题意,这是不可取的,应当在题目描述中就对题目的目标进行说明。(在这个例子中还存在题目背景严重影响题意理解的问题。)相同的错误还出现在 CF1423(4)N Bubblesquare Tokens 中,在输出格式才第一次出现了题目的目标 “friend pairs and number of tokens each of them gets on behalf of their friendship”。
3.输入输出格式
输入输出格式清晰 完整 即可,没有死板的要求,个人建议参照 CF 的题目来写输入输出格式,具体可以参考[CF 出题人须知][3]。
为了方便选手做题,输入输出格式中最好说明每个变量的具体含义,除非变量的意义非常长,没法一句话说清楚(这时可以说“意义见题目描述”)。
需要特别注意的是,如果输出中含有小数,请尽量使用 SPJ 来对误差的大小进行限制,而非要求“保留 x 位小数”。
“保留 x 位小数”对精度的要求可能是无限的。例如:要求保留三位小数,实际答案为 0.0015 0.0015 0.0015,此时只要有任意大小的误差导致计算出的答案小于 0.0015 0.0015 0.0015,即使计算出的答案是 0.00149999 ⋯ 0.00149999\cdots 0.00149999⋯ 也会输出错误的答案。
如果无法使用 SPJ,请保证对精度的要求是有限的,例如:请输出答案四舍五入后保留小数点后三位的结果。令标准答案为 a n s ans ans,数据保证对于任意满足 ∣ x − a n s ∣ max ( 1 , a n s ) < 1 0 − 9 \frac{|x-ans|}{\max(1,ans)}<10^{-9} max(1,ans)∣x−ans∣<10−9 的 x x x,四舍五入后结果与 a n s ans ans 四舍五入后相同。
可以参考的一些句子:
输入的第一行包含三个正整数 $n$, $m$, $k$ ($1\le n,m\le 2\cdot 10^5$, $1\le k\le 100$) — $n$ 表示数列的长度,$m$ 表示操作个数,$k$ 的意义见题目描述。
- 1
输入的第二行包含 $n$ 个非负整数 $a_1,a_2,\ldots,a_n$ ($1\le a_i\le 10^9$) — 题目给出的数列。
- 1
接下来的 $m$ 行中的第 $i$ 行包含两个正整数 $l_i$ 和 $r_i$ ($1\le l_i\le r_i\le n$),表示第 $i$ 次操作在区间 $[l_i,r_i]$ 上进行。
- 1
接下来的 $n-1$ 行,每行包含两个正整数 $u$ 和 $v$ ($1\le u,v\le n$),表示 $u$ 和 $v$ 之间由一条边相连。
数据保证给出的边能构成一棵树。
- 1
- 2
- 3
输入的唯一一行包含一个由小写英文字母构成的非空字符串,其长度不超过 $10^6$。
- 1
输入的第二行包含一个小数点后不超过三位的实数 $x$ ($-10^6\le x\le 10^6$),意义见题目描述。
- 1
输出包含一个实数,当你的输出与标准答案之间的绝对误差或相对误差小于 $10^{-6}$ 时视作正确。
- 1
输出的第二行包含 $n$ 个正整数,表示你构造的一组方案 — 其中第 $i$ 个数表示你打出的第 $i$ 张牌的编号。
如果有多组合法的答案,可以任意输出其中一组。
- 1
- 2
- 3
???+note “在选手代码内由随机数生成器生成输入数据”
有的题目会因为输入数据过大,为了防止读入用时过长,而要求选手在代码内通过给定的数据生成器生成数据,代替通过标准输入或文件输入来读入数据。
采用这种做法需要谨慎考虑,因为它有很多缺点:
- 可能引入了正解所不需要的数据随机性,或者使得构造数据变得困难
- 可能增大了理解输入格式的难度
- 如果随机数生成器封装的不好,可能理解数据生成器本身的使用方法就有难度
- 如果选手没有使用出题者推荐的语言,可能需要自己写一个数据生成器
采用这种做法一般是为了防止读入数据用时过长,所以一个可能的替代方案是下发一个性能足够好的 [读入、输出优化](./io.md) 模板,以尽量保证所有人的读入用时一致,这样的话即使读入用时很久也不会影响不同选手用时的差异。另一个解决方案是将题目包装成函数调用式(而非 IO 式)交互题,即使算法过程中没有交互,交互题也可以起到统一读入用时的作用,IOI 就采用了所有题目都是交互题的方案。但是,这两种方案都对选手使用的语言有限制,需要出题者手动支持每种允许选手使用的语言。
回到问题的本源,还可以考虑一下过大的输入数据是否是必要的,有没有可能使用较小的输入数据达到目的,以及比正解复杂度稍劣的做法是否有卡掉的必要。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.数据范围
按照 CF 的要求,数据范围要写在输入格式里,但在国内,数据范围往往是写在题目的最后的。
数据范围中最容易犯的错误就是不完整。输入中的每一个数、每一个字符串都应该有清晰的界定。在上文所给出的输入输出格式示例中就有一些数据范围的正确写法。
数据范围的常见遗漏:
- “整数”中的“整”。
- 题面中只说了是“整数”没说是“正整数”,并且数据范围中只有上限没有下限。
- 字符串没说字符集。
- 实数没说小数点后位数。
- 某些变量没有给范围。
你需要保证标程可以通过满足题面所述数据范围的 任何一组数据。
???+note “关于“保证数据随机生成””
有的题目中会“保证数据随机生成”,很多时候这样的限制并不是最优的解决方案,因为“随机生成”对数据的限制并不明确,会给判断具体数据范围、提供 hack 数据带来困难。
一般来说,“保证数据随机生成”可以换成解法所需要的数据性质。例如,随机生成一棵树往往可以换成限制树的高度。
如果一定要保证数据随机生成,应当指定随机生成的具体操作。例如,生成一棵树是随机选择父亲节点还是随机生成 Prufer 序列。
需要注意的是,非确定性算法和依赖于数据随机性的算法是不同的。前者可以对于任意数据都有很高的概率得到正解,而后者是对于大部分的数据能得到正解,对于某些特定的数据则不可能得到正解。
- 1
- 2
- 3
- 4
- 5
4.样例
样例应当有一定的强度,能够查出一些简单的错误。读错题意的人应当能够通过样例发现自己读错了题意。
有多种操作的题,每种操作都应在样例中出现。
有多种输出的题(如 CF1173A Nauuo and Votes),每种输出都应在样例中出现。例外:实际上不可能无解,但要求判断是否有解的题目。
5.样例解释
题目描述越复杂、越不易理解就越应当有详细的样例解释。
题目难度越简单就越应当有详细的样例解释。
详细的样例解释可以选择配上图片。
较大的样例可以没有样例解释。
为了照顾色觉障碍者,最好不要使颜色成为理解样例解释所必备的。可以用彩色图片来美化样例解释,但如果一定要用颜色传递一些必要的信息,最好不要同时出现红黄或者红绿。
6.时限、空间限制与部分分
时限与空间限制的目的是卡掉复杂度错误的做法。(当然,也是为了防止评测用时过长,如:只对交互次数有限制而对时间复杂度没有限制的交互题也有时间限制。)
因此,原则上时间限制应当选取不使错误做法通过的尽量大的值。
一般地,时限应满足以下要求:
- 至少为 std 在最坏情况下用时的两倍。
- 如果比赛允许使用 Java,应使 Java 能够通过。
- 不应使错误做法通过(实在卡不掉、想放某种错解过除外)。
为了更好地在放大常数做法过的同时卡掉错解,一般可以采用同时增大数据范围和时限的方法。但要注意,有时正解(由于缓存等玄学问题)会在数据范围增大时有极大的常数增加,此时增大数据范围不一定能够增大正解与错解之间用时的差距。
在有部分分的赛制中,还可以通过设置有梯度的数据、数据范围稍小的数据来使较为优秀的错解和大常数正解不能通过,同时使其获得较高的部分分。
需要注意的是,在数据范围小于 5 ⋅ 1 0 5 5\cdot 10^5 5⋅105 时,应当考虑是否能使用 指令集 通过。
一般情况下空间限制应当设置的足够大,除非空间复杂度更优的做法的确十分巧妙,值得卡掉空间复杂度大的做法。这种情况下可以考虑设置空间限制较松的部分分。值得注意的是,如果不想卡掉空间消耗较大的做法,数据结构题一般需要设置较大的空间限制。
一道好题应该具有它的选拔性质,具有足够的区分度。应该至少 4 档部分分,让新手可以拿到分,让高手能够展示自己的实力。
——vfk《UOJ 精神之源流》
部分分一般分为较小数据范围与特殊性质两种。
较小数据范围一般要设置多档,即使你想不到某种复杂度的做法,也可以考虑给这种复杂度一档分。一般来说,为了避免卡常,可以设置一档极限数据除以二的部分分。
“数据有梯度”最好用多档部分分替代。
特殊性质部分分的设置要依具体题目而定。理想的特殊性质部分分应当是能够引导选手思考正解的。与较小数据范围部分分不同,在你不会针对某种特殊性质的做法时,最好不要给这种特殊性质一档分。例如:「CTS2019」随机立方体 的 k = 1 k=1 k=1 这档部分分在讲题时就被很多人吐槽,称这档部分分妨碍了思考正解。
如果题目给分方式与默认方式不同(如:在一般的 OI 赛制比赛中绑 subtask 测试),一定要在题面中说明。
不推荐使用“百分之 XX 的数据满足 XX”的说法,尤其是数据范围有多个变量时。例如,“ 30 % 30\% 30% 的数据满足 n ≤ 1000 n \le 1000 n≤1000”和“ 40 % 40\% 40% 的数据满足 m ≤ 100 m \le 100 m≤100”可能描述了 70 % 70\% 70% 的数据的性质,也可能只描述了 40 % 40\% 40% 数据的性质。一般来说,subtask 或数据范围表格是更好的选择。
四.工具篇
1.土法命题
一般而言不推荐使用该种方式,因为容易出锅,而且题目很多的时候难以管理。
土法命题,如其名,就是直接出题,没啥工具。但是也要有基本的出题步骤:
- 立意,构思题目框架和考察算法,以及时空限制;
- 题面,构思题目核心内容,制作题面的主体部分及输入输出;
- 数据,构造几组符合题意的数据,确保输出符合要求,可以用作样例;
- 标程,制作标程,用简单数据进行验证,并根据结果修正存在的问题;
- 扩大数据规模:用脚本生成数据,尽可能覆盖满数据范围,然后跑标程生成输出,记得瞅瞅输出有没有炸掉;
- 编造题目背景:放大脑洞,然后编造一个牛逼的故事背景,并把题面嵌合进去,要消除可能的歧义;
- 验题,自己读至少两遍题面,修正错别字和歧义语句;
- 制作题解,整理题目数据格式。
1).题面制作
题面一般由以下几部分构成:题目描述、输入描述、输出描述、提示及样例解释(可选)。
建议的题目格式如下:
示例
H1:题目名称
Input: 输入类型(Standard/None/Interactive)
Output: 输入类型(Standard)
TimeLimit: 时间限制/ms
MemoryLimit: 空间限制/kb
H2:题目描述 Problem Description
在此书写题目描述
H2:输入描述 Input
在此书写输入描述
H2:输出描述 Output
在此书写输出描述
H2:样例
H3:Sample Input
------
- 1
H3:Sample Output
------
- 1
H2:提示 Hint
在此书写提示
建议使用Markdown来书写题面,对于同一场比赛,务必保证题面格式统一!
更建议使用LaTex来书写题面(如果有能力),格式控制精确,题面整洁。Latex的标准模板如下:
\newpage \section*{\textsf{Problem X: }\textrm{122}} \begin{tabular}{ll} \fontsize{10pt}{10pt} Input file: & \fontsize{10pt}{10pt}\texttt{standard input} \\ \fontsize{10pt}{10pt} Output file: & \fontsize{10pt}{10pt}\texttt{standard output}\\ \fontsize{10pt}{10pt} Time limit: & \fontsize{10pt}{10pt}\texttt{_ seconds} \\ \fontsize{10pt}{10pt} Memory limit: & \fontsize{10pt}{10pt}\texttt{_ megabytes}\\ \end{tabular} \subsection*{\textsf{Problem Description}} 在此书写题面 \subsection*{\textsf{Input}} \noindent 在此书写输入 \subsection*{\textsf{Output}} \noindent 在此书写输出 \noindent \subsection*{\textsf{Examples}} \texttt{ \begin{tabular}{| p{8cm} | p{8cm} |} \hline Standard Input & Standard Output\\ \hline \end{tabular} }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2).数据制作
数据制作有三种主流方式:
- 土法数据生成:C++/Python文件生成,根据题目要求写循环、随机生成
CYARON洛谷开源数据生成器:开源的Python包,具体介绍在后面。需要熟练使用PythonTestlib,是编写相关程序(generator, validator, checker, interactor)时的优秀辅助工具。它是俄罗斯和其他一些国家的出题人的必备工具。后面的Polygon平台也是使用该头文件作为标准库。
土法数据生成的必备语法:文件流
C++
freopen("x.in", "r", stdin);
freopen("x.out", "w", stdout);
- 1
- 2
Python
fs = open('x.in', "w")
# 读取
fs.read() # 读全部
fs.readline() # 读一行
fs.readlines() # 把文件中的所有数据都读取出来,以字符串的形式存放在列表中,一行数据为一个列表元素
# 写入
fs.write("sample")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
CYARON 数据生成器
官网:luogu-dev/cyaron: CYaRon: Yet Another Random Olympic-iNformatics test data generator (github.com)
文档:Wiki · luogu-dev/cyaron Wiki (github.com)
安装:
pip install cyaron
- 1
使用:~
Testlib 头文件
如果你正在使用 C++ 出一道算法竞赛题目,Testlib 是编写相关程序(generator, validator, checker, interactor)时的优秀辅助工具。它是俄罗斯和其他一些国家的出题人的必备工具,许多比赛也都在用它:ROI、ICPC 区域赛、所有 Codeforces round……
Testlib 库仅有 testlib.h 一个文件,使用时仅需在所编写的程序开头添加 #include "testlib.h" 即可。
Testlib 的具体用途:
- 编写 Generator,即数据生成器。
- 编写 Validator,即数据校验器,判断生成数据是否符合题目要求,如数据范围、格式等。
- 编写 Interactor,即交互器,用于交互题。
- 编写 Checker,即 Special Judge。
Testlib 与 Codeforces 开发的 Polygon 出题平台完全兼容。
testlib.h 在 2005 年移植自 testlib.pas,并一直在更新。Testlib 与绝大多数编译器兼容,如 VC++ 和 GCC g++,并兼容 C++11。
具体见Polygon命题部分。
2.Polygon
Polygon 地址:https://polygon.codeforces.com/
Polygon是Codeforces开放给公众使用的一个造题平台。其拥有命题所需要的基本功能以及严格的步骤和题目验证机制,确保命制题目的质量。目前,国内大多数标准XCPC赛事的命题组都会使用Polygon进行命题。
优点:
有版本管理系统,多人合作时不会乱成一团,也不需要互相传文件。
出题系统完善,validator、generator、checker、solutions 环环相扣,输出自动生成。
可以为 solutions 设置标签,错解 AC、正解未 AC 都会警告,方便地逐一卡掉错解。
可以方便地对拍,拍出来的数据可以直接添加到题目数据中。
发现问题可以提 issue,而不会被消息刷屏却一直没有 fix。
出锅率低
缺点:
访问速度不稳定,快如闪电和慢似蜗牛交替,令人抓狂。
0).注册
记得邮箱要填好,因为登录需要邮箱验证。
注册登陆后,首页如下所示:

点击New Problem以创建新题目。
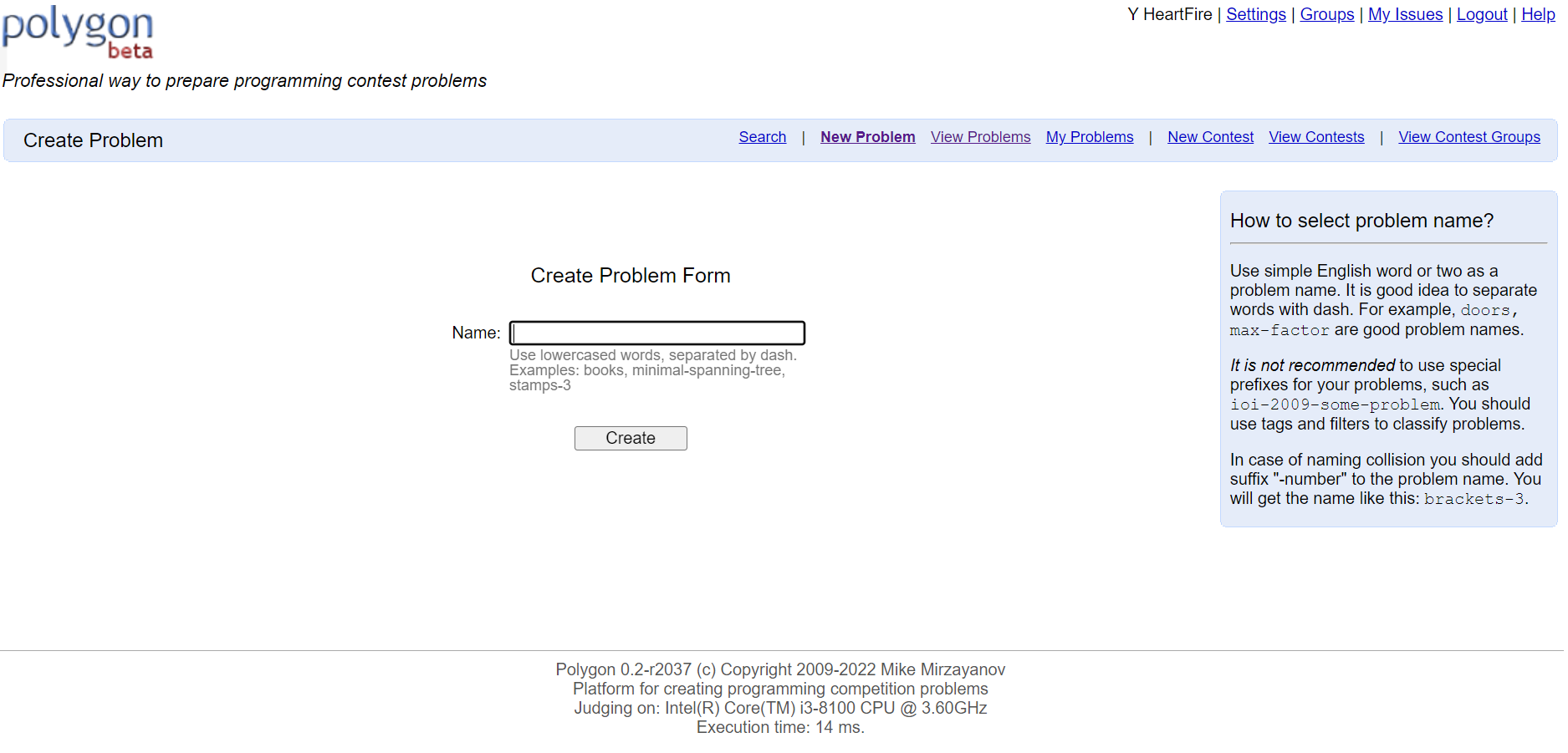
如图,输入题目名称,注意此处的题目名称并不是实际的名称,而是一个标识性名称,类似于文件名。仅允许使用小写字母+'-'命名。注意不要与题库撞名。
1).版本控制
版本控制最主要的功能就是追踪文件的变更。它将什么时候、什么人更改了文件的什么内容等信息忠实地了记录下来。每一次文件的改变,文件的版本号都将增加。
Polygon集成了轻量版本控制系统,可以对题目的修改历史进行追溯。如果有误编辑、需要找回之前的数据,可以通过Checkout操作来返回历史版本。
创建题目后,可以在题目详情页面的右侧找到变更历史记录,此处记录了当前版本与上个版本相比的文件差异。
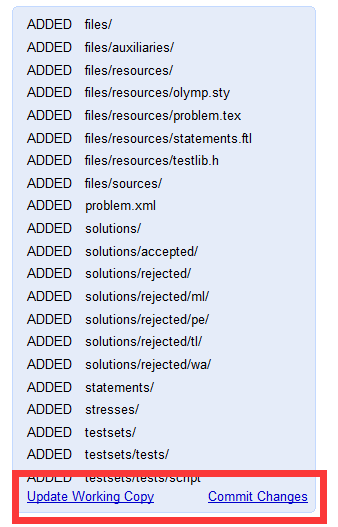
建议各位养成良好的版本控制习惯,每完成一次编辑后都要Commit Changes,便于个人、团队追溯文件变更。
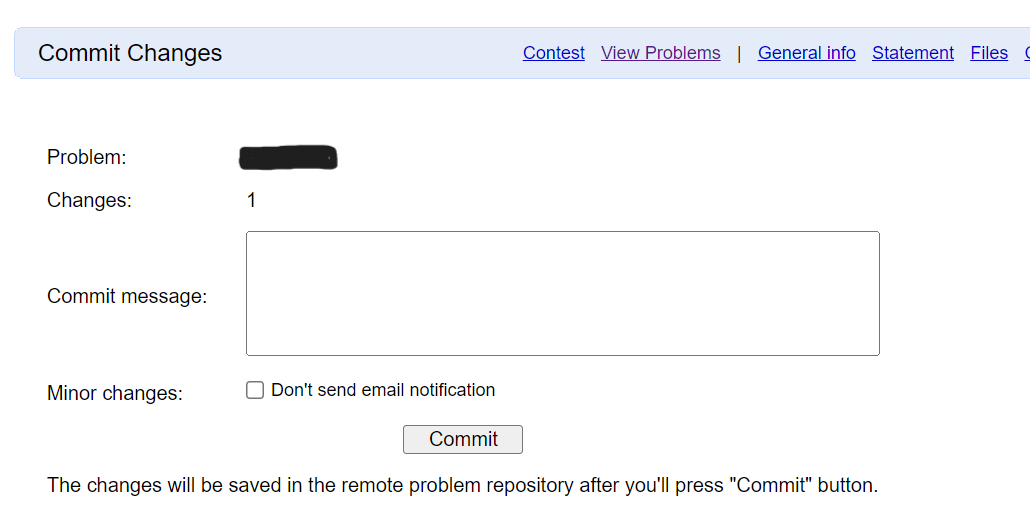
请务必在Commit message中注明主要的变更,以便自己和团队更方便的理解你题目的变更理由、变更部分。
如果你将题目添加到了比赛,那么Polygon-Contest的信息页将展示历史变更:
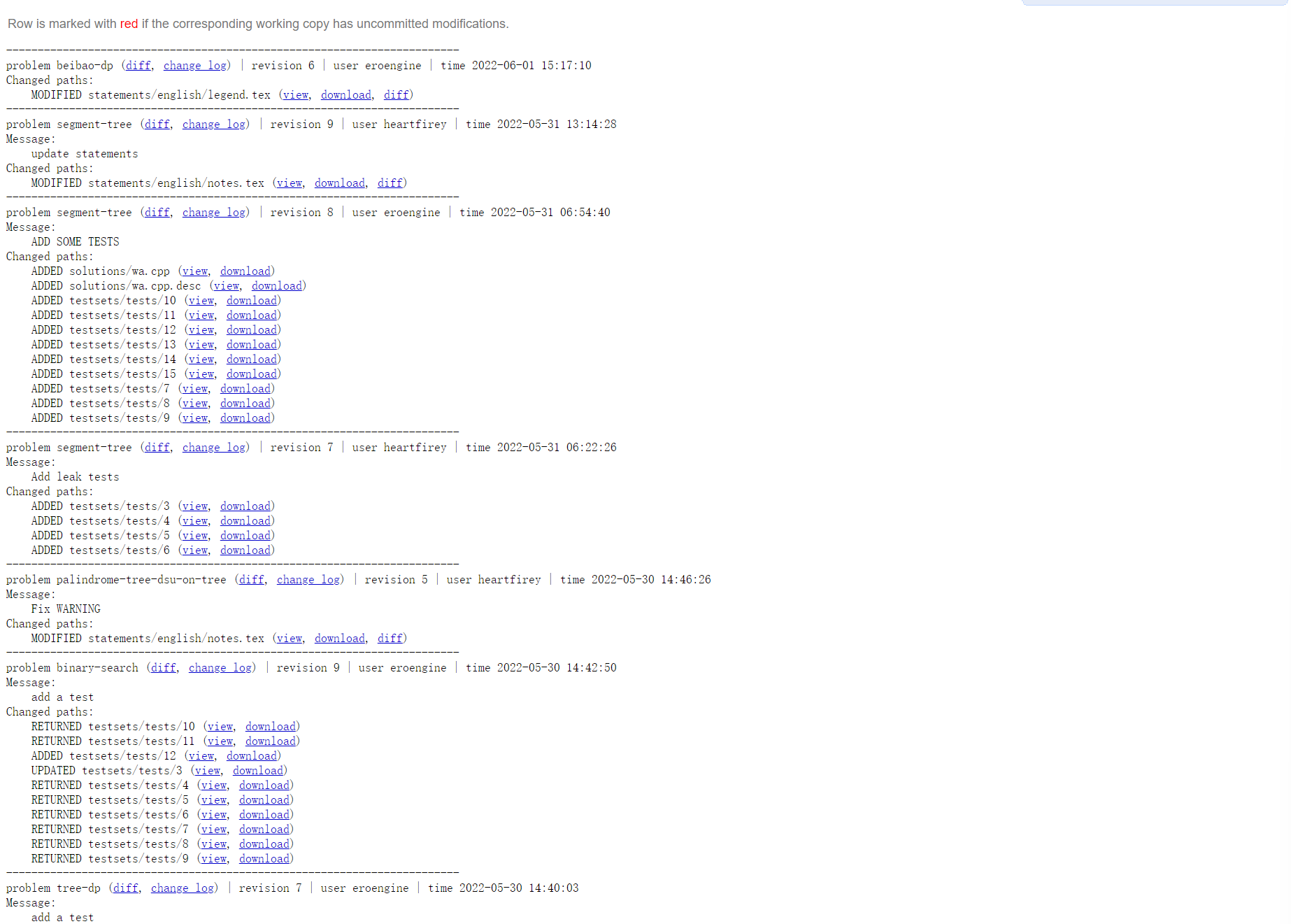
警告!
Polygon 虽然拥有版本管理系统,但是并没有冲突解决系统,一旦发生冲突就无法进入题目管理界面,只能撤销修改后手动重做。并且,只要修改了同一个文件,即使不是同一行也会发生冲突。
所以,使用 Polygon 时请与合作者保持沟通,commit 前保证没有其他人在修改。
2).创建团队
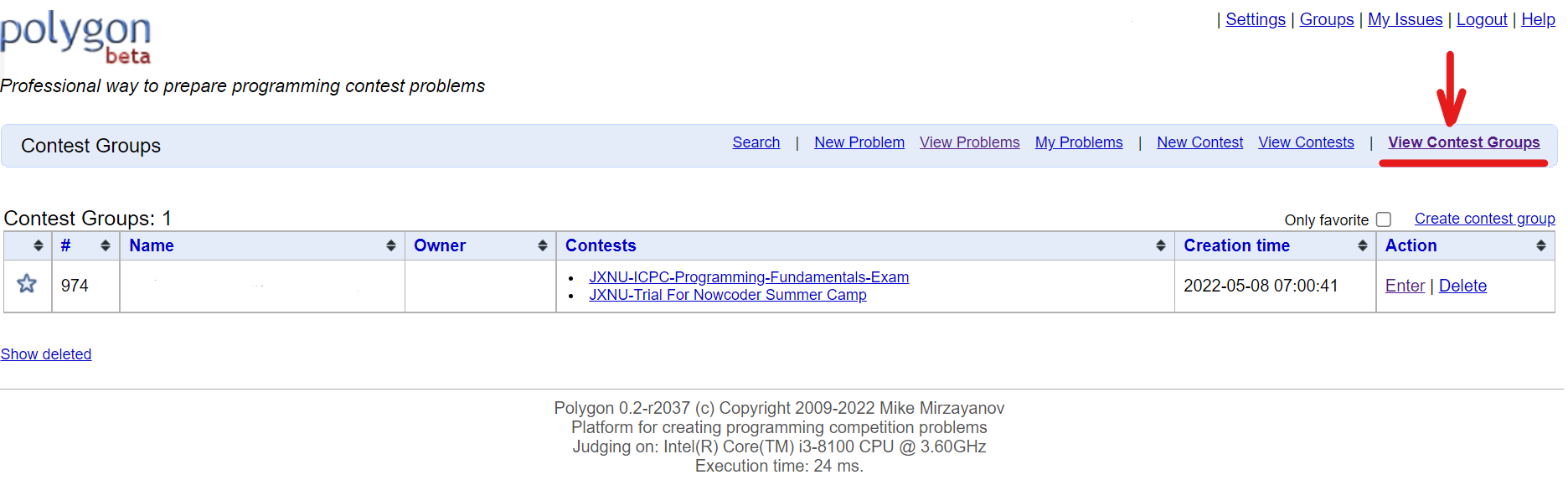
选择View Contest Group,然后点击Create contest group以创建命题组。
创建命题组后可邀请成员加入。后续创建比赛也通过附加到命题组实现协同编辑。
3).创建比赛

在此处输入比赛名称,地点,日期等相关信息。主要语言根据实际情况选择。
进入比赛页面后,可以通过Add Problems添加题目库中的题目。
右边栏提供了一系列操作:
Preview Statements as PDF: 预览整场比赛的PDF题面Preview Statements as HTML:预览整场比赛的HTML题面Preview Tutorial as PDF: 预览整场比赛的PDF题解Preview Tutorial as HTML: 预览整场比赛的HTML题解
你可以直接通过New Problem在比赛中创建题目,并使用Renumberate problems对题目进行排序,使用Add problems to other contest将题目导入其它比赛,Build full packages来构建题目包,Download Package来下载题目包。
4).命制题目
打开题目首页,可以看到很多功能,解释如下:
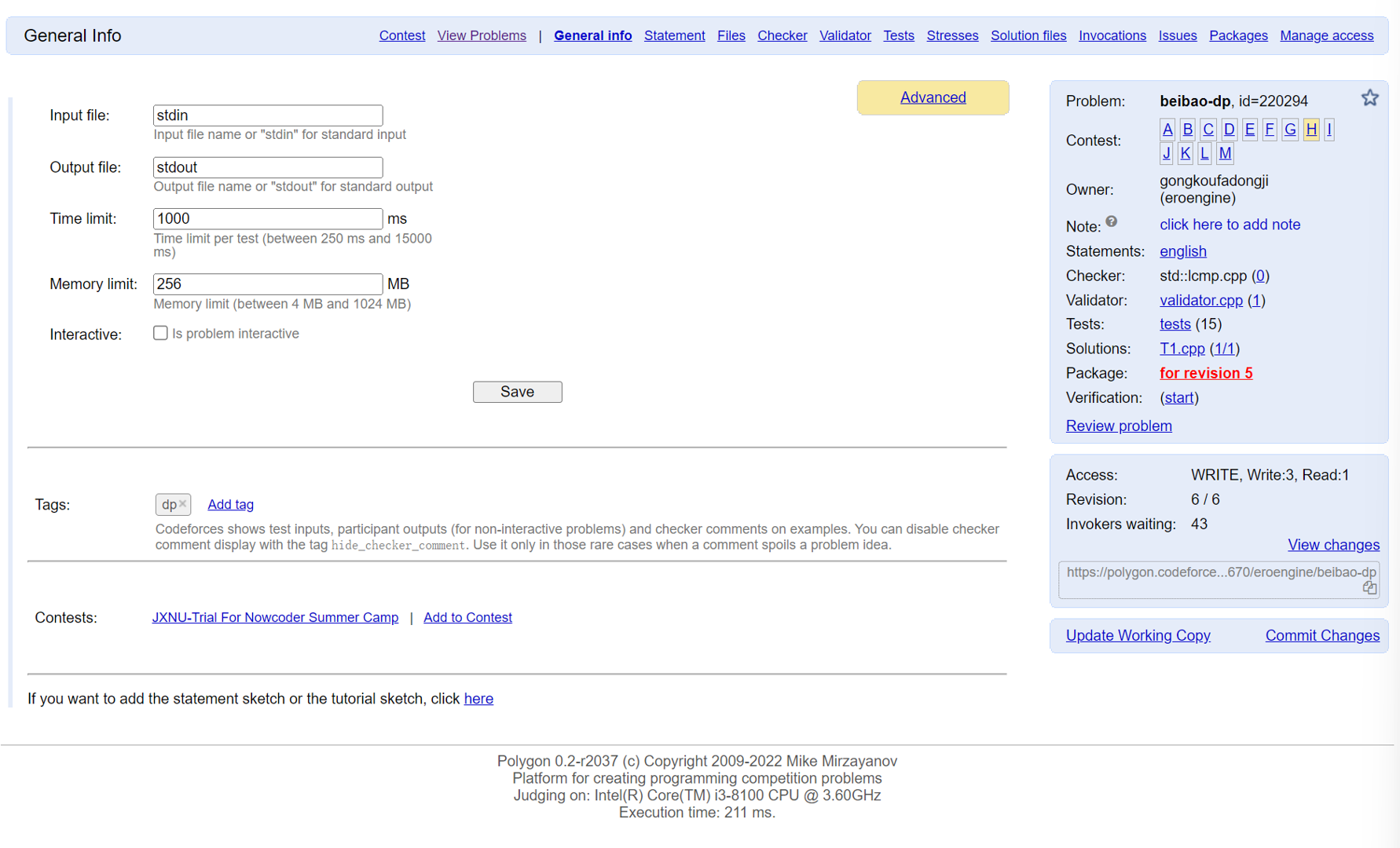
5).题面制作
题面分为中文题面和英文题面,英文题面直接选择语言English创建即可;中文题面选择Chinese创建后需要进行一些改动。
由于Latex默认不支持中文,因此需要导入中文包以使之支持中文。
选择Files选项,进入文件页面,对statements.ftl进行编辑,使用以下内容覆盖该文件:
\documentclass [11pt, a4paper, oneside] {article} \usepackage {CJK} \usepackage [T2A] {fontenc} \usepackage [utf8] {inputenc} \usepackage [english, russian] {babel} \usepackage {amsmath} \usepackage {amssymb} \usepackage <#if contest.language?? && contest.language="russian">[russian]<#elseif contest.language?? && contest.language="ukrainian">[ukrainian]</#if>{olymp} \usepackage {comment} \usepackage {epigraph} \usepackage {expdlist} \usepackage {graphicx} \usepackage {ulem} \usepackage {import} \usepackage{ifpdf} \ifpdf \DeclareGraphicsRule{*}{mps}{*}{} \fi \begin {document} \begin{CJK}{UTF8}{gbsn} \contest {${contest.name!}}% {${contest.location!}}% {${contest.date!}}% \binoppenalty=10000 \relpenalty=10000 \renewcommand{\t}{\texttt} <#if shortProblemTitle?? && shortProblemTitle> \def\ShortProblemTitle{} </#if> <#list statements as statement> <#if statement.path??> \graphicspath{{${statement.path}}} <#if statement.index??> \def\ProblemIndex{${statement.index}} </#if> \import{${statement.path}}{./${statement.file}} <#else> \input ${statement.file} </#if> </#list> \end{CJK} \end {document}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
然后题面可以支持中文渲染。
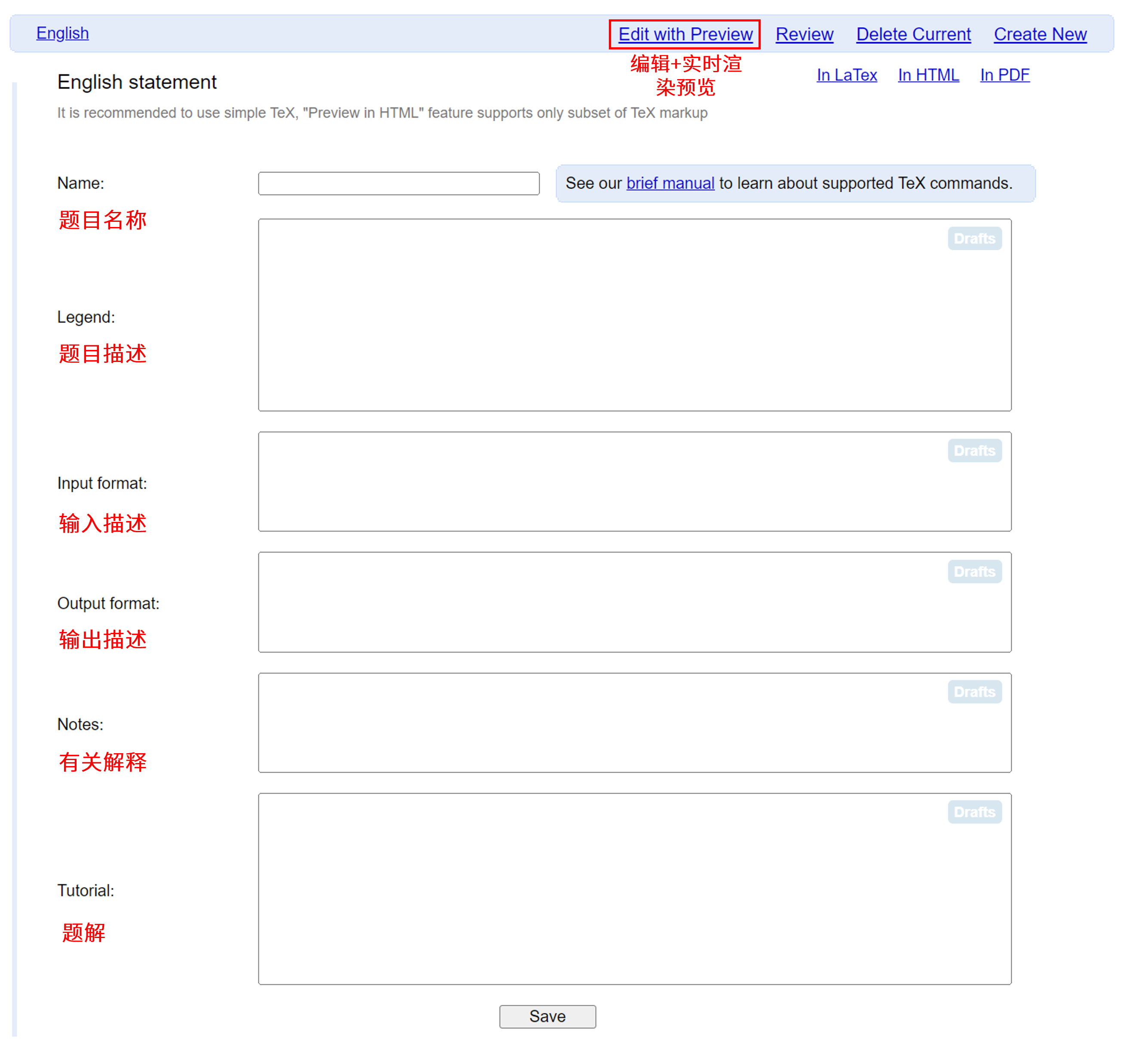
然后回到statements页面,书写题面。可以使用实时渲染编辑器进行编辑,便于查看实际效果。
题面和题解都需要使用 TeX 的语法,不能使用 Markdown。例如,需要使用 \textbf{text} 而不是 **text**。但 Polygon 支持的实际上是 TeX 的一个非常小的子集,具体可以自己尝试。
可以通过最上方的 “In HTML” 链接查看渲染后的题面,通过 “Tutorial in HTML” 查看渲染后的题解。
如果需要在题面中添加图片,需要先在下面的 “Statement Resource Files” 中上传图片,然后在题面中加上 \includegraphics{filename.png}。
6).数据校验
数据校验器基于Testlib实现
数据校验器是非常重要的、必不可少的功能,它可以检查所有的Input,从而严格保证你的题目输入不出锅,且符合你的题目要求。
Validator(中文:校验器)用于检验造好的数据的合法性。当造好一道题的数据,又担心数据不合法(不符合题目的限制条件:上溢、图不连通、不是树……)时,出题者通常会借助 validator 来检查。[^ref1]
因为 Coderforces 支持 hack 功能,所以所有 Codeforces 上的题目都必须要有 validator。UOJ 也如此。Polygon 内建了对 validator 的支持。
- 写 validator 时,不能对被 validate 的数据做任何假设,因为它可能包含任何内容。因此,出题者要对各种不合法的情况进行判断(使用 Testlib 会大大简化这一流程)。
- 例如,输入一个点数为 n n n 的树,主要工作是判断 n n n 是否符合范围和判断输入的是树与否。但是切不可在判断过 n n n 范围之后就不对接下来输入的边的起点与终点的范围进行判断,否则可能会导致 validator RE。
- 即使不会 RE 也不应该不判断,这会导致你的报错不正确。如上例,如果不判断,报错可能会是“不是一棵树”,但是正确的报错应当是“边起点/终点不在 [ 1 , n ] [1,n] [1,n] 之间”。
- 不能对选手的读入方式做任何假设。因此,必须保证能通过 validate 的数据完全符合输入格式。
- 例如,选手可能逐字符地读入数字,在数字与数字之间只读入一个空格。所以在编写 validator 时,数据中的每一个空白字符都要在 validator 中显式地读入(如空格和换行)。
- 结束时不要忘记
inf.readEof()。 - 如果题目开放 hack(或者说,validator 的错误信息会给别人看),请使报错信息尽量友好。
- 读入变量时使用“项别名”。
- 在判断使用的表达式不那么易懂时,使用 ensuref 而非 ensure。
基本框架如下:
#include "testlib.h"
int main(int argc, char* argv[]) {
registerValidation(argc, argv);
/*书写测试逻辑*/
inf.readEof(); //最后需要换行
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
一些基本操作如下:
inf.readSpace(); //读取空格
inf.readEoln(); //读取换行
//读取一个Int型整数,返回值为读到的整数,限定范围为[l, r],超出则抛出异常;name为变量名。
inf.readInt(int l, int r, string name);
//读取一个Long Long类型整数...
inf.readLong(int l, int r, string name);
//读取浮点数,...
inf.readDouble(int l, int r, string name);
//读取字符,要求读到的字符是c
inf.readChar(chr c);
//读字符串,使用regex(正则表达式)进行验证,name为变量名
//例如:inf.readString("[0-1]{0, 5000}", "row") 读入一个长度1~5000,仅由0或1后成的字符串
inf.readString(string regex, string name)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
例子:某场考试的垃圾题–HeartFireY’s trouble
#include <bits/stdc++.h> #include "testlib.h" using namespace std; const int MAX = 24 * 3600 - 1; void checktimes(string str){ int hh = (str[0] - '0') * 10 + (str[1] - '0'); int mm = (str[3] - '0') * 10 + (str[4] - '0'); int ss = (str[6] - '0') * 10 + (str[7] - '0'); ensure(hh >= 0 && hh < 24); ensure(mm >= 0 && mm < 60); ensure(ss >= 0 && ss < 60); ensure((hh * 3600 + mm * 60 + ss) <= MAX); } int main(int argc, char* argv[]) { registerValidation(argc, argv); int n = inf.readInt(1, 10000, "number_of_clocks"); inf.readEoln(); for(int i = 1; i <= n; i++){ string str = inf.readWord("[0-9-]{0,8}", "str"); checktimes(str); inf.readSpace(); inf.readInt(0, MAX, "Ring_Hold"); inf.readSpace(); inf.readInt(0, MAX, "Repeat"); inf.readEoln(); } string str = inf.readWord("[0-9-]{0,8}", "time"); checktimes(str); inf.readEoln(); inf.readEof(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
编译生成的程序如何使用?
直接在命令行输入 ./val 即可。数据通过 stdin 输入。如果想从文件输入可 ./val < a.in。
若数据没有问题,则什么都不会输出且返回 0;否则会输出错误信息并返回一个非 0 值。
7).数据生成
数据生成器基于Testlib实现
Test这个页面是用来管理数据的。
在 Polygon 上,推荐的做法是使用少量 带命令行参数 的 generator 来生成数据,而不是写一堆 generator 或者每生成一组数据都修改 generator。并且,只需要生成输入,输出会自动生成。
“Testset” 就是一个测试集,如果是给 CF 出题需要手动添加 “pretests” 这个 Testset,并且 “pretests” 需要是 “tests” 的子集。
“Add Test” 是手动添加一组数据,一般用于手动输入样例或较小的数据。虽然可以通过文件上传数据,但这是 不推荐的,数据应该要么是手动输入的要么是使用 generator 在某个参数下生成的。
如果勾选了 “Use in statements”,这组数据就会成为样例,自动加在题面里。如果需要题面里显示的不是样例的输入输出(一般用于交互题),就可以点 “If you want to specify custom content of input or output data for statements click here”,然后输入你想显示在题面中的输入输出。
Tests 页面的下方是用来输入生成数据的脚本的,如 generator-name [params] > test-index。可以使用 generator-name [params] > $,就不用手动指定测试点编号了。
可以参考 Polygon 提供的教程 使用 Freemarker 来批量生成脚本。
“Preview Tests” 可以预览生成的数据。
注意,虽然推荐Freemarker,但由于较难学习,我们仍推荐使用Testlib进行数据生成
一个简单的例子:生成两个 [ 1 , n ] [1,n] [1,n] 范围内的整数:
// clang-format off
#include "testlib.h"
#include <iostream>
using namespace std;
int main(int argc, char* argv[]) {
registerGen(argc, argv, 1);
int n = atoi(argv[1]);
cout << rnd.next(1, n) << " ";
cout << rnd.next(1, n) << endl;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
如何使用Testlib进行数据生成?
在一切之前,先执行 registerGen(argc, argv, 1) 初始化 Testlib(其中 1 是使用的 generator 版本,通常保持不变),然后我们就可以使用 rnd 对象来生成随机值。随机数种子取自命令行参数的哈希值,对于某 generator g.cpp , g 100 (Unix-Like) 和 g.exe "100" (Windows) 将会有相同的输出,而 g 100 0 则与它们不同。
rnd 对象的类型为 random_t ,你可以建立一个新的随机值生成对象,不过通常你不需要这么做。
该对象有许多有用的成员函数,下面是一些例子:
| 调用 | 含义 |
|---|---|
rnd.next(4) | 等概率生成一个 [ 0 , 4 ) [0,4) [0,4) 范围内的整数 |
rnd.next(4, 100) | 等概率生成一个 [ 4 , 100 ] [4,100] [4,100] 范围内的整数 |
rnd.next(10.0) | 等概率生成一个 [ 0 , 10.0 ) [0,10.0) [0,10.0) 范围内的浮点数 |
| `rnd.next("one | two |
rnd.wnext(4, t) | wnext() 是一个生成不等分布(具有偏移期望)的函数,
t
t
t 表示调用 next() 的次数,并取生成值的最大值。例如 rnd.wnext(3, 1) 等同于 max({rnd.next(3), rnd.next(3)}) ; rnd.wnext(4, 2) 等同于 max({rnd.next(4), rnd.next(4), rnd.next(4)}) 。如果
t
<
0
t<0
t<0 ,则为调用
−
t
-t
−t 次,取最小值;如果
t
=
0
t=0
t=0 ,等同于 next() 。 |
rnd.any(container) | 等概率返回一个具有随机访问迭代器(如 std::vector 和 std::string )的容器内的某一元素的引用 |
附:关于 rnd.wnext(i,t) 的形式化定义:
wnext
(
i
,
t
)
=
{
next
(
i
)
t
=
0
max
(
next
(
i
)
,
wnext
(
i
,
t
−
1
)
)
t
>
0
min
(
next
(
i
)
,
wnext
(
i
,
t
+
1
)
)
t
<
0
\operatorname{wnext}(i,t)=
另外,不要使用 std::random_shuffle() ,请使用 Testlib 中的 shuffle() ,它同样接受一对迭代器。它使用 rnd 来打乱序列,即满足如上“好的 generator”的要求。
例子:生成树
下面是生成一棵树的主要代码,它接受两个参数——顶点数和伸展度。例如,当 n = 10 , t = 1000 n=10,t=1000 n=10,t=1000 时,可能会生成链;当 n = 10 , t = − 1000 n=10,t=-1000 n=10,t=−1000 时,可能会生成菊花。
#define forn(i, n) for (int i = 0; i < int(n); i++) registerGen(argc, argv, 1); int n = atoi(argv[1]); int t = atoi(argv[2]); vector<int> p(n); /* 为节点 1..n-1 设置父亲 */ forn(i, n) if (i > 0) p[i] = rnd.wnext(i, t); printf("%d\n", n); /* 打乱节点 1..n-1 */ vector<int> perm(n); forn(i, n) perm[i] = i; shuffle(perm.begin() + 1, perm.end()); /* 根据打乱的节点顺序加边 */ vector<pair<int, int> > edges; for (int i = 1; i < n; i++) if (rnd.next(2)) edges.push_back(make_pair(perm[i], perm[p[i]])); else edges.push_back(make_pair(perm[p[i]], perm[i])); /* 打乱边 */ shuffle(edges.begin(), edges.end()); for (int i = 0; i + 1 < n; i++) printf("%d %d\n", edges[i].first + 1, edges[i].second + 1);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
一些注意事项
- 严格遵循题目的格式要求,如空格和换行,注意文件的末尾应有一个换行。
- 对于大数据首选
printf而非cout,以提高性能。(不建议在使用 Testlib 时关闭流同步) - 不使用 UB(Undefined Behavior,未定义行为),如开头的那个示例,输出如果写成
cout << rnd.next(1, n) << " " << rnd.next(1, n) << endl;,则rnd.next()的调用顺序没有定义。
8).答案校验
Checker,即 Special Judge,用于检验答案是否合法。使用 Testlib 可以让我们免去检验许多东西,使编写简单许多。
Checker 从命令行参数读取到输入文件名、选手输出文件名、标准输出文件名,并确定选手输出是否正确,并返回一个预定义的结果.
如果不需要使用SpecialJudge,可以使用模板库中的Checker进行答案比对:
fcmp.cpp逐行比对,不忽略空格(多余的空格判定为非法)hcmp.cpp仅输出一个巨大整数时可以用这个lcmp.cpp逐行比对,忽略多余空格[推荐]wcmp按顺序比较字符串(不带空格,换行符等非空字符)。yesno.cpp比较 YES 和 NO,大小写不敏感。rcmp4.cpp按顺序比较浮点数,最大可接受误差(绝对误差或相对误差)不超过 1 0 − 4 10^{-4} 10−4(还有 rcmp6,rcmp9 等对精度要求不同的 checker,用法和 rcmp4 类似)。- 其余自行探索
9).数据对拍
OI选手必备技能之一,不会用可以先放放。
Stress 这个页面是用来对拍的。
点击 “Add Stress” 就可以添加一组对拍,“Script pattern” 是一个生成数据的脚本,其中可以使用 “[10…100]” 之类的来表示在一个范围内随机选择。
然后运行对拍,如果拍出错就会显示 “Crashed”,并且可以一键把这组数据加到 Tests 中。
10).标程代码
这个页面是用来放解这道题的代码的,可以是正解也可以是错解。将错解传上来可以便捷地卡掉它们,也可以提醒自己需要卡掉它们。
11).运行测试
Innvocations是用来运行 solutions 的。
选择代码和测试点就可以运行了,之后可以在列表里点进去(“View”)查看详细信息。
评测状态 “FL” 表示评测出错了,一般是数据没有过 validate 或者 validator/checker/interactor 之类的 RE 了。“RJ” 有两种情况,一种是出现了 “FL”,另一种是这份代码第一个测试点就没有通过。
如果用时在时限的一半到两倍之间,会用黄色标识出来。
如果数据中存在变量没有达到最小值或最大值,会在最下方提醒。
12).提出问题
可以在Issue页面向作者提问题,可以是题目的缺陷等等。
13).题目包
Package 包含了一道题的全部信息,在出 CF 时是 CF 评测的依据(例如,如果赛时要修锅,更新了 package 才会影响到 CF),其它时候可以用来导出。
“Verify” 是测试所有 solution 都符合标签(AC、WA、TLE),并且 checker 通过 checker tests,validator 通过 validator tests。
14).命题实例
略
3.Online Judge后台结构简介
JXNUOJ是基于Laravel框架实现的在线评测系统(为NOJ扩展分支),评测机由QDUOJ扩展分支开发。由南京邮电大学(NJUPT)、方糖智行开发,江西师范大学计算机科学协会JXNUASC负责运营。
JXNUOJ将评测端作为扩展组件,支持V-Judge(虚拟评测)、Local Judge(本地评测)。
五、技巧篇
生成数据过程:
样例的小数据、这部分一般可以通过手模样例写出。
一般来说是直接生成随机数就可以作为样例
1.极限数据(反正劣于预期复杂度的暴力做法通过)
2.corner case 、比如当n1或n2的时候需要特判,而当n>=3是统一标准做法时需要特殊做法的数据单独列出
3.针对一些会出现错误答案的做法需要写对拍程序出数据
\#include<bits/stdc++.h> using namespace std; int main() { for (int i=1;i<=1000;i++) { system("make.exe");//随机生成数据的程序 cerr<<"make"<<i<<endl; system("1005.exe");//暴力保证的正确程序,用freopen打开数据 cerr<<"1005"<<i<<endl; system("test.exe");//待验证的程序,用freopen打开数据 cerr<<"test."<<i<<endl; printf("%d : ",i); if (system("fc test.out 1005.out")) {//两个都用freopen输出到文件 printf("WA\n"); return 0; } else printf("AC\n"); } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

