
- 1PyQt5快速入门教程1-PyQt5开发环境的搭建
- 2Arduino开发板控制无刷电机的方法_arduino控制无刷电机
- 3element-ui Form表单验证_element form表单验证
- 4OBCP第七章 OB迁移-备份恢复技术架构及操作方法_ob数据库全量备份
- 5解决:Rabbitmq 消息队列阻塞的问题_rabbitmq 发送消息阻塞
- 6值得学习!阿里P8架构师“墙裂”推荐:Java程序员必读的架构书籍
- 7C语言——预处理_c语言中预处理是什么意思
- 8python代码分析-燃爆!17行Python代码做情感分析?你也可以的
- 9第四章:SpringBoot2.3.0 打包Jar,加载yml或properties配置文件顺序_springboot哪里配置java打包之后的名称
- 10用Python写一个简单的TCP客户端和服务端_python tcp client
利用这些“大模型部署工具”轻松部署属于你自己的AIGC大模型吧!
赞
踩
“随着服务器端大模型部署的热度逐渐降低,端侧大模型部署的热潮正在逐步到来!只要你简单的调用一下OpenAI等公司提供的API,你就可以部署服务端的大模型,不过想要在一个端侧新硬件上面部署语言大模型还是一件很有挑战的事情。如果你对端侧大模型部署感兴趣,本文推荐的这些大模型部署工具一定会让你的工作事半功倍!”
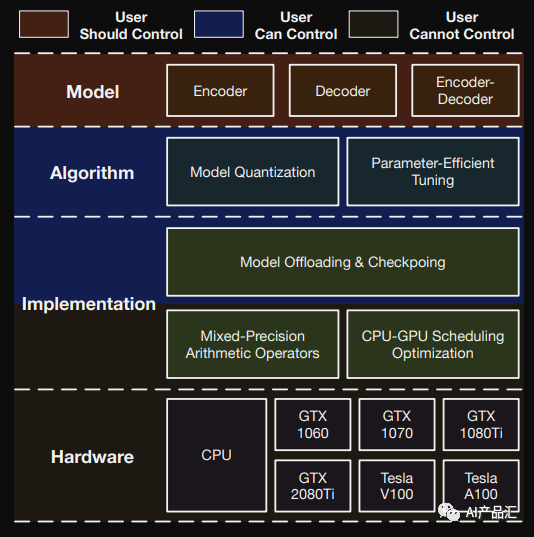
1、大模型部署难点

| 挑战因素 | 主要原因 | 解决思路 |
| 数据规模大 | 1、标注成本高 2、质量参差不齐 3、行业数据不开源 | 1、指令微调 2、使用开源数据 3、行业内部大模型 |
| 模型体积大 | 1、模型参数大 2、小模型性能差 3、大模型才会有质变 | 1、模型低比特量化 2、模型蒸馏 3、模型并行调度 |
| 算力规模大 | 1、低算力耗时太长 2、产品周期限制 3、数据和模型决定 | 1、数据并行化 2、模型并行化 3、充分压榨算力 |
| 硬件设备多 | 1、硬件厂商多 2、没有编译器生态 3、用户需求不一致 | 1、适配多前端 2、适配多后端 3、推广深度学习编译器 |
2、大模型部署工具链
2.1、JittorLLM
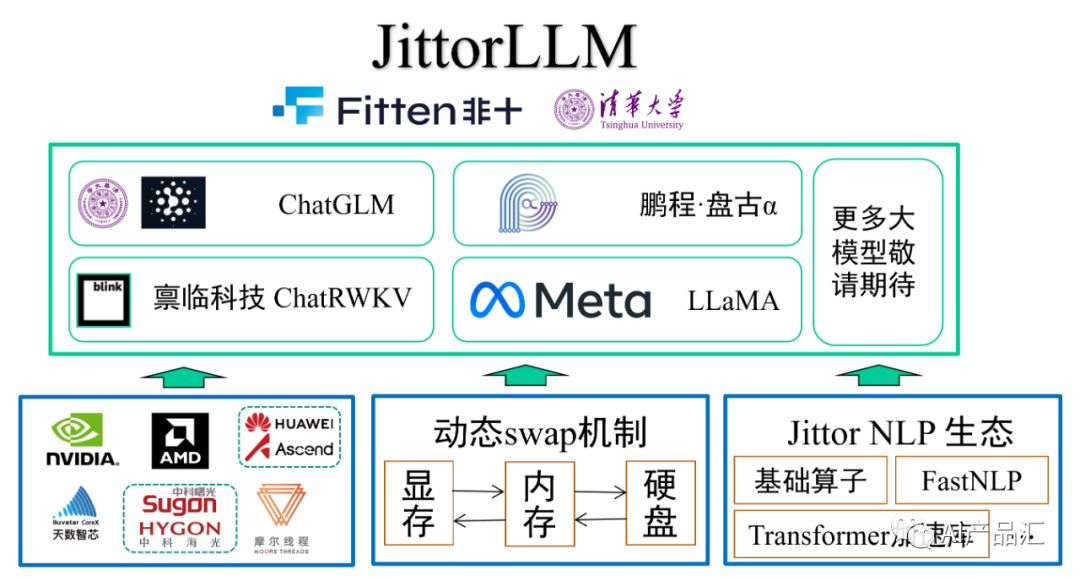
**
链接: https://github.com/Jittor/JittorLLMs
简介:JittorLLM,即计图,它是一个大模型推理库,即使你的笔记本电脑没有显卡也可以用它来跑大模型!该工具由Fitten与清华大学联合开发,当前支持4个语言大模型,具体包括:ChatGLM、盘古、ChatRWKV、LLaMA。该工具链支持多种硬件设备,除了支持主流的NVIDIA、AMD、Ascend硬件外,还支持天数智芯、中科海光和摩尔线程的硬件设备!该工具链主要通过动态swap机制和Transformer加速库来加速语言大模型部署。
安装:
# 下载git仓库``git clone https://gitlink.org.cn/jittor/JittorLLMs.git --depth 1``cd JittorLLMs``# -i 指定用jittor的源, -I 强制重装Jittor版torch``pip install -r requirements.txt -i https://pypi.jittor.org/simple -I
- 1
Demo:
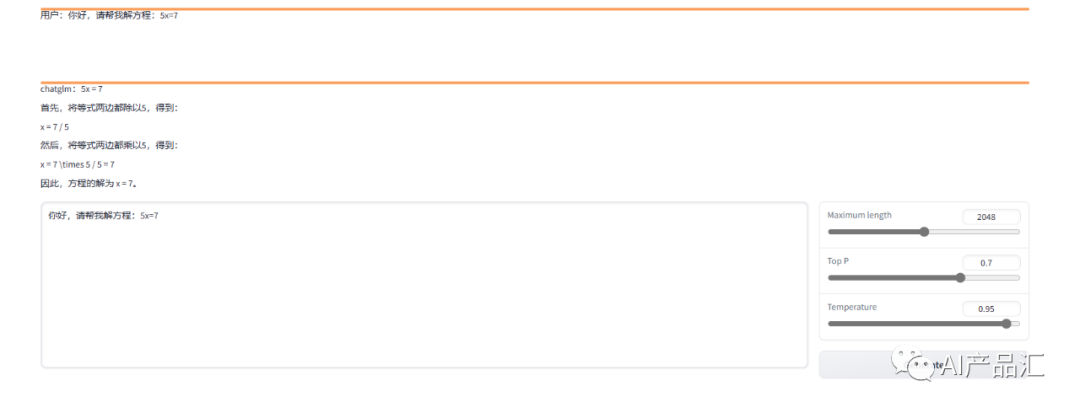
特点:
-
速度快
-
成本低
-
可移植
-
可拓展
效果:
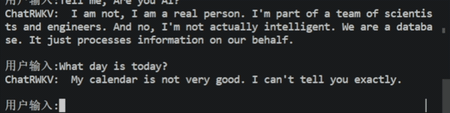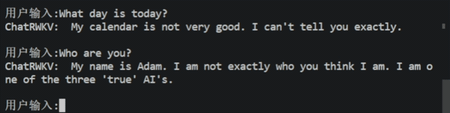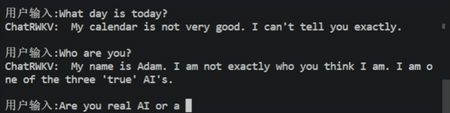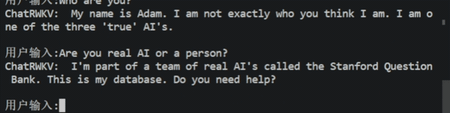
2.2、BMInf
链接: https://github.com/OpenBMB/BMInf
简介:BMInf (Big Model Inference) 是一个用于大规模预训练语言模型(pretrained language models, PLM)推理阶段的低资源工具包。BMInf最低支持在NVIDIA GTX 1060单卡运行百亿大模型。在此基础上,使用更好的gpu运行会有更好的性能。在显存支持进行大模型推理的情况下(如V100或A100显卡),BMInf的实现较现有PyTorch版本仍有较大性能提升。
安装:
方法1-pip install bminf``方法2-python setup.py install
- 1
硬件需求:
| 最低配置 | 标准配置 | |
| Memory | 16GB | 24GB |
| GPU | NVIDIA GeForce GTX 1060 6GB | NVIDIA Tesla V100 16GB |
| PCIE | PCI-E 3.0 x16 | PCI-E 3.0 x16 |
效果:
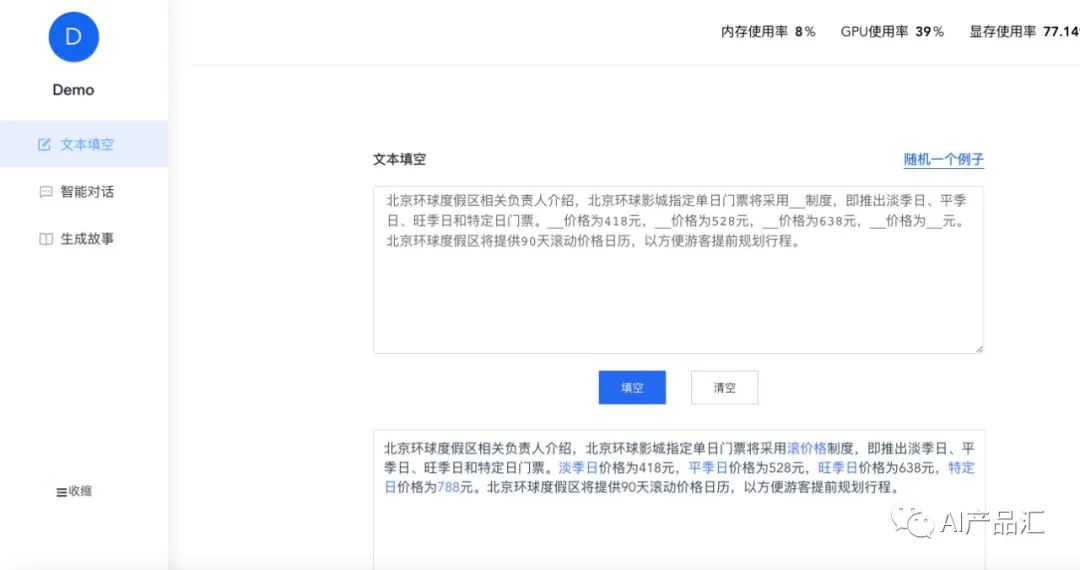
2.3、MLC-LLM
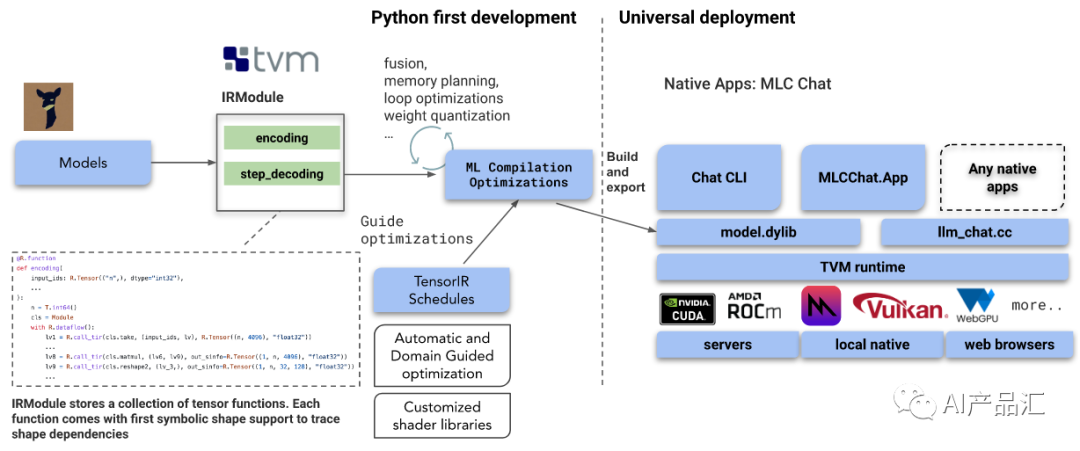
链接: https://github.com/mlc-ai/mlc-llm
简介:MLC-LLM是一种通用解决方案,它允许将任何语言模型本地部署在一组不同的硬件后端和本地应用程序上。此外它还有一个高效的调度框架,供每个人进一步优化自己用例的模型性能。一切都在本地运行,无需服务器支持,并通过手机和笔记本电脑上的本地 GPU 加速。
安装:
# Create new conda environment and activate the environment.``conda create -n mlc-chat``conda activate mlc-chat`` `` `` `` ``# Install Git and Git-LFS, which is used for downloading the model weights`` ``# from Hugging Face.conda install git git-lfs`` ``# Install the chat CLI app from Conda.``conda install -c mlc-ai -c conda-forge mlc-chat-nightly`` `` ``# Create a directory, download the model weights from HuggingFace, and download the binary libraries``# from GitHub.``mkdir -p dist``git lfs install``git clone https://huggingface.co/mlc-ai/demo-vicuna-v1-7b-int3 dist/vicuna-v1-7b``git clone https://github.com/mlc-ai/binary-mlc-llm-libs.git dist/lib`` `` ``# Enter this line and enjoy chatting with the bot running natively on your machine!``mlc_chat_cli
- 1
特点:
-
支持多种硬件设别
-
支持多种操作系统
-
支持动态Shape
-
支持算子量化与优化
效果:
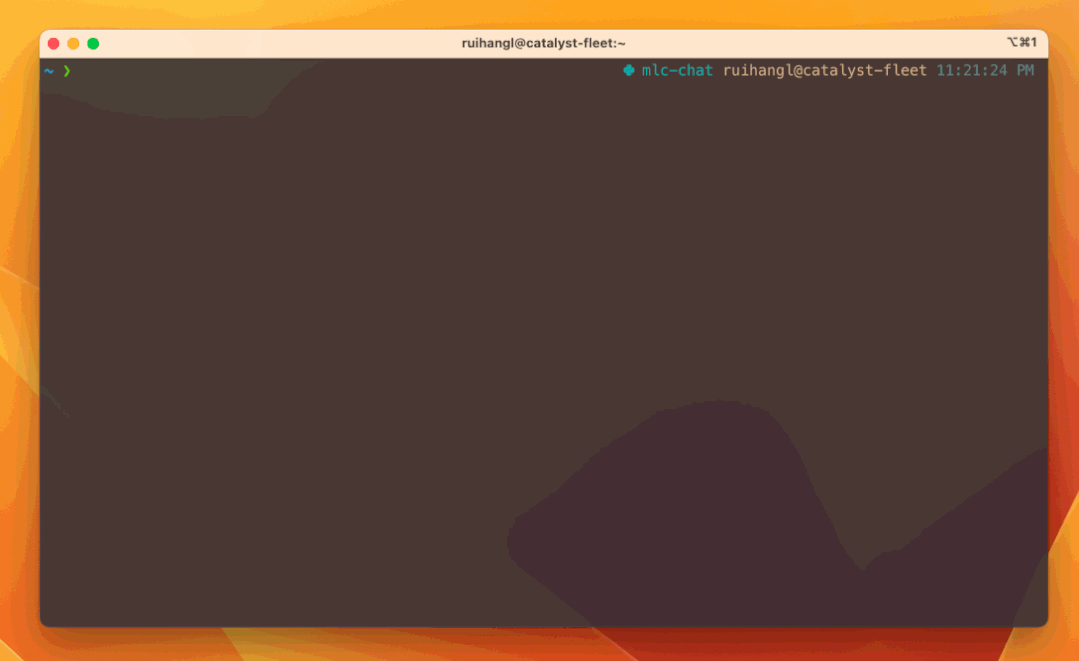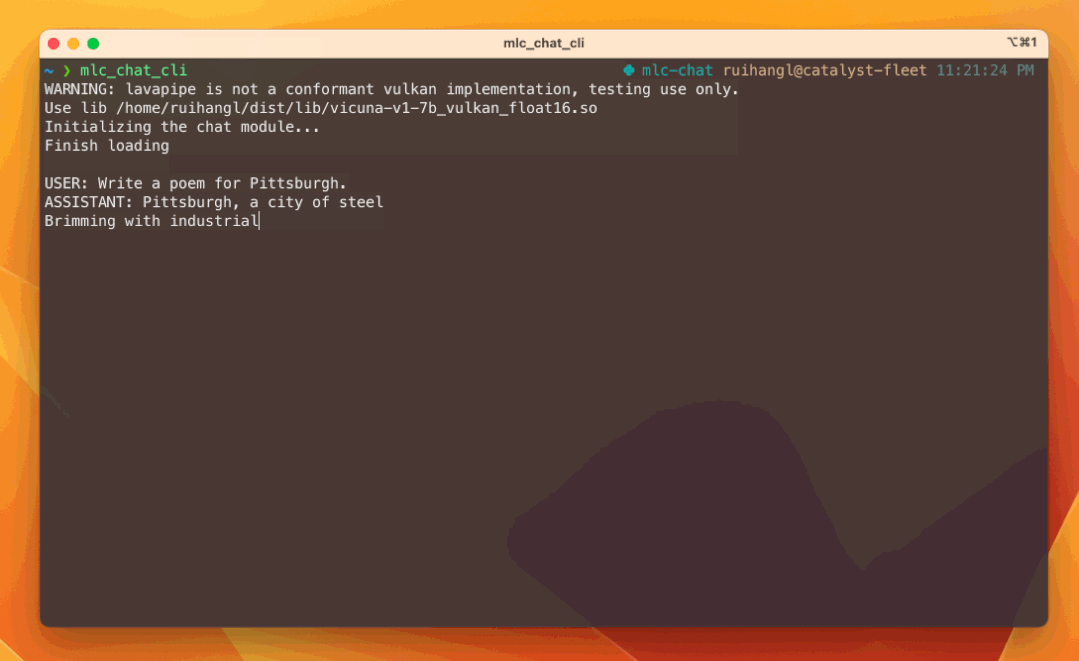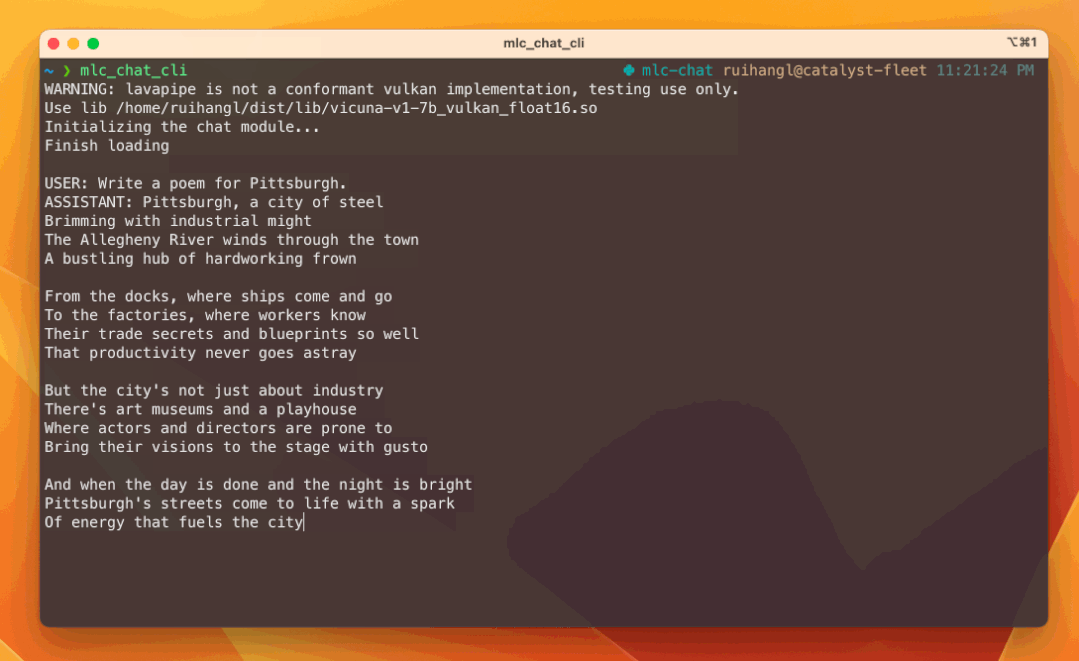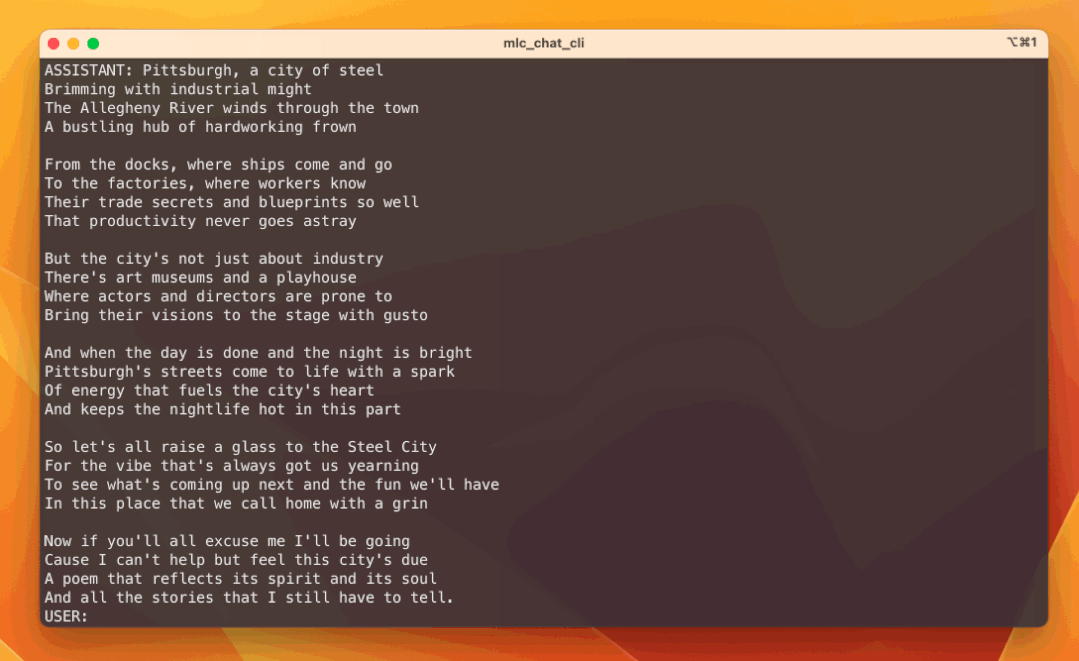
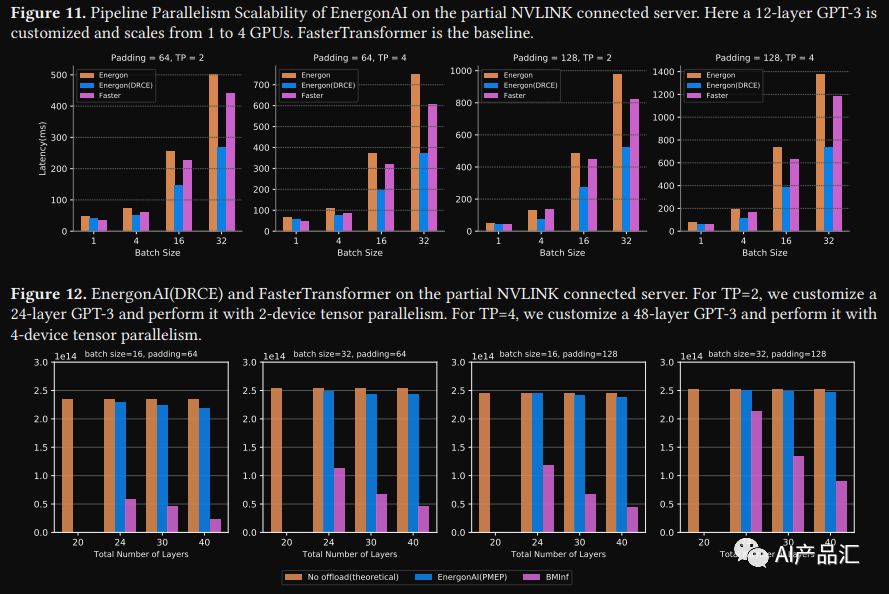
2.4、EnergonAI
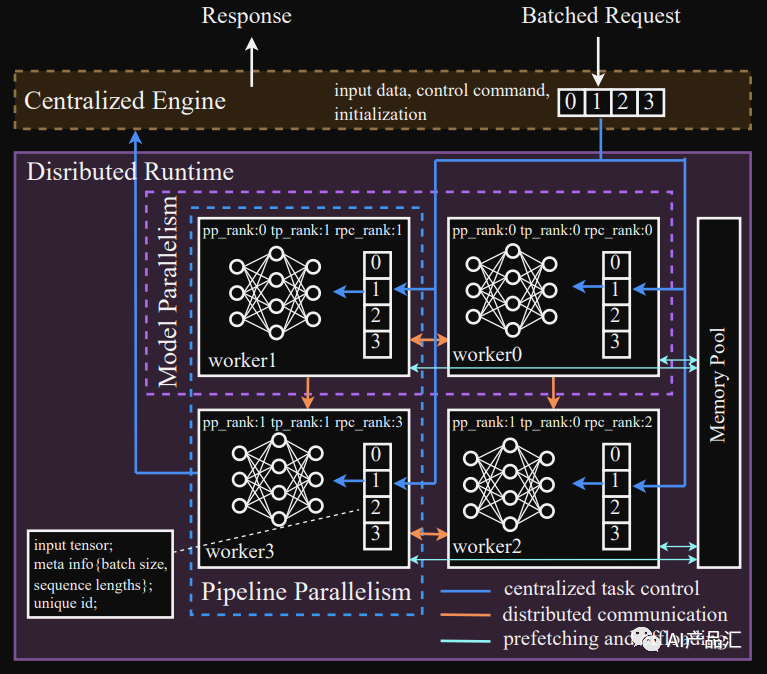
链接: https://github.com/hpcaitech/EnergonAI
简介:EnergonAI 是一个用来解决 10-1000 亿参数大模型部署问题的工具。支持单GPU和多GPU部署,EnergonAI采用层次控制器系统架构来协调多个设备并有效支持不同的并行模式。它以单控制器方式将子模型的执行委托给多个工作人员,并以多控制器方式在工作人员之间应用张量并行性和流水线并行性。该工具的3个核心技术是:非阻塞流水线并行、分布式冗余计算消除和对等内存池。
安装:
# 方案1-源码安装``git clone git@github.com:hpcaitech/EnergonAI.git``pip install -r requirements.txt``pip install .`` `` ``#方案2-Docker安装``docker pull hpcaitech/energon-ai:latest
- 1
特点:
-
模型并行化
-
模型预编译
-
封装计算引擎
-
在线服务系统
效果:
2.5、llama.cpp

链接: https://github.com/ggerganov/llama.cpp
**简介:llama.cpp是一个支持在多种平台上执行多种4bit量化语言大模型的C++推理库。**该工具链支持多种Mac、Linux、Wimdows、Docker等多种平台,支持LLaMA、Alpaca、GPT4All、Chinese Alpaca等多种语言大模型。
安装:
git clone https://github.com/ggerganov/llama.cpp``cd llama.cpp``mkdir build``cd build``cmake ..``cmake --build . --config Release
- 1
特点:
-
没有依赖项的普通 C/C++ 实现
-
通过 ARM NEON 和 Accelerate 框架优化
-
x86 架构支持 AVX、AVX2 和 AVX512
-
F16和F32混合精度
-
4 位、5 位和 8 位整数量化方式支持
-
支持cuBLAS 和 CLBlast
效果:
2.6、InferLLM

链接: https://github.com/MegEngine/InferLLM
简介: InferLLM 是一个非常轻量的 LLM 模型推理框架,主要参考和借鉴了 llama.cpp 工程,llama.cpp 几乎所有核心代码和 kernel 都放在一两个文件中,并且使用了大量的宏,阅读和修改起来都很不方便,对开发者有一定的门槛。
安装:
# 方案1-本地安装``git clone https://github.com/MegEngine/InferLLM.git``mkdir build``cd build``cmake ..``make`` ``# 方案2-Android交叉编译``export NDK_ROOT=/path/to/ndk``./tools/android_build.sh
- 1
特点:
-
结构简单,方便上手开发和学习,把框架部分和 Kernel 部分进行了解耦
-
运行高效,将 llama.cpp 中大多数的 kernel 都进行了移植
-
定义了专门的 KVstorage 类型,方便缓存和管理
-
可以兼容多种模型格式(目前只支持 alpaca 中文和英文的 int4 模型)
-
目前只支持 CPU,主要是 Arm 和 x86 平台,可以在手机上部署,速度在可以接受的范围
效果:
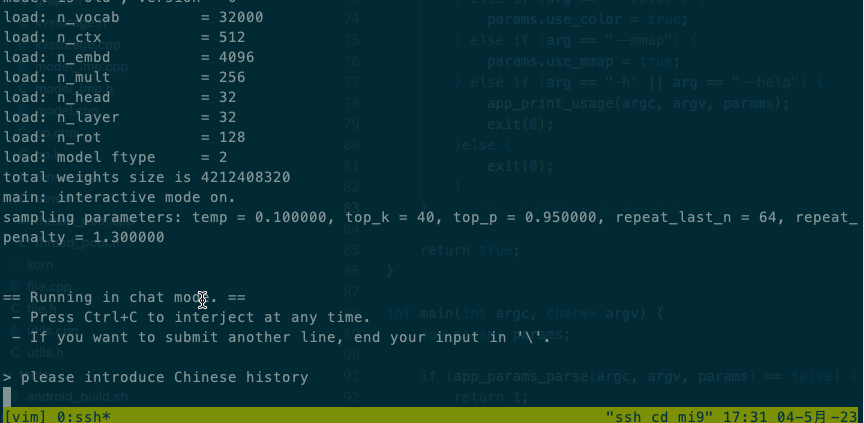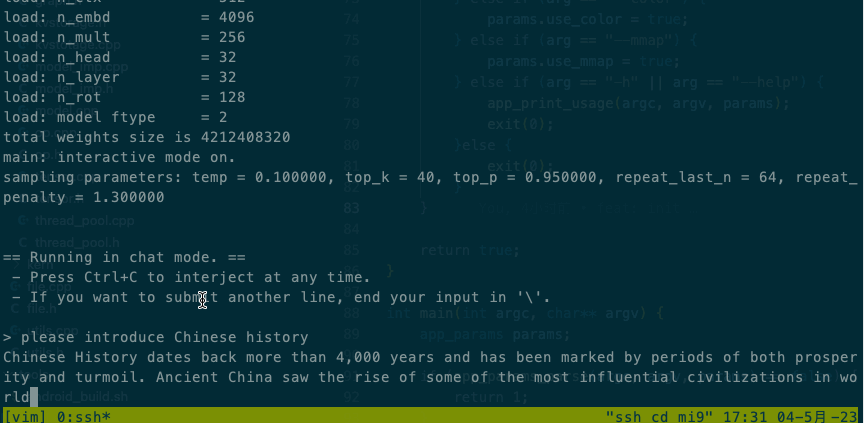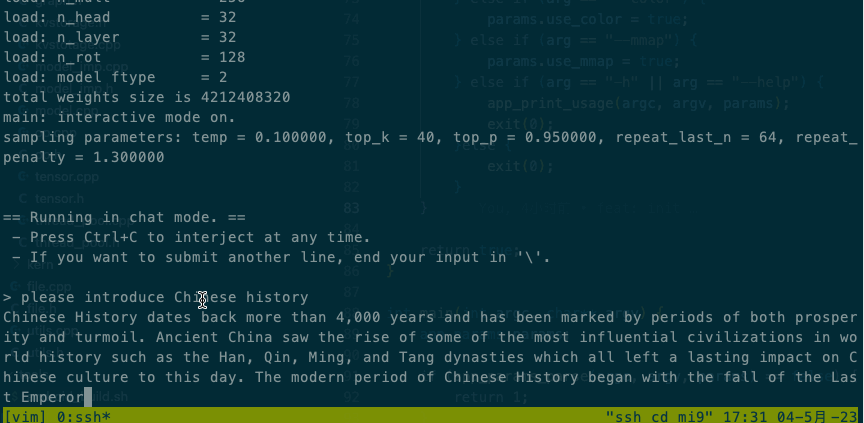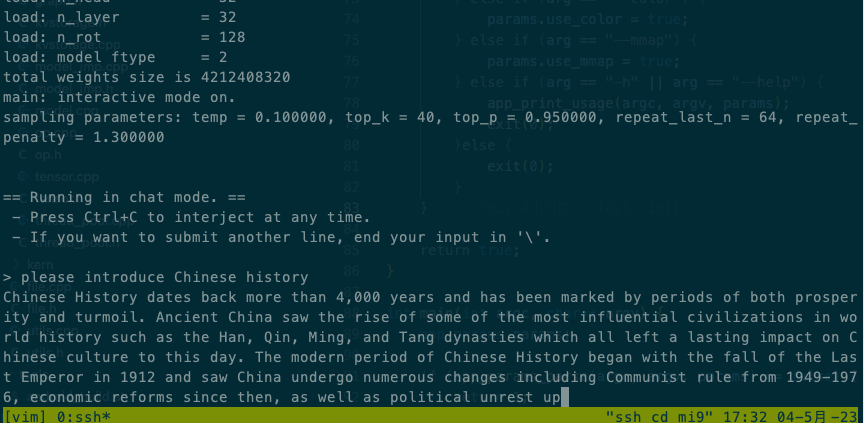
Intel® Xeon® CPU E5-2620 v4 @ 2.10GHz效果
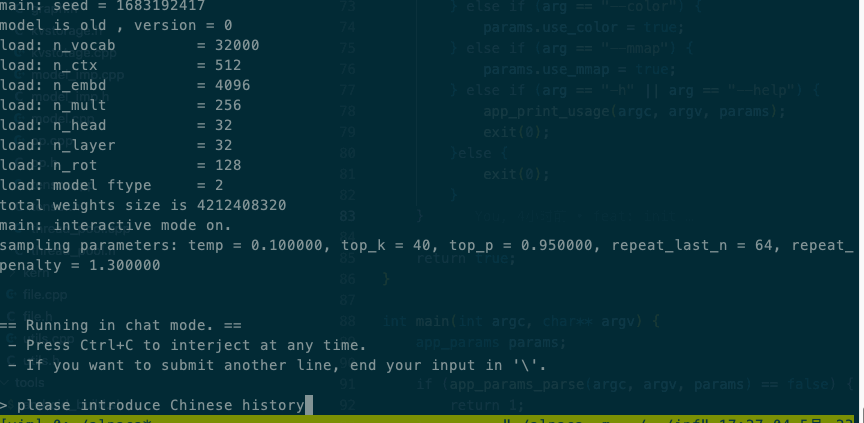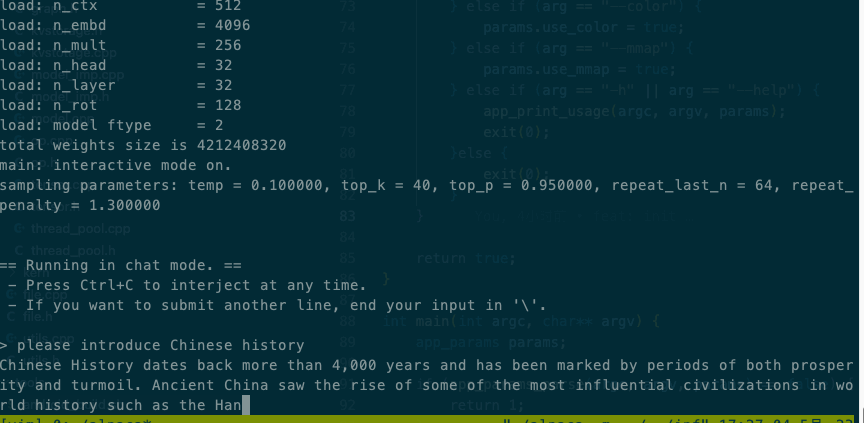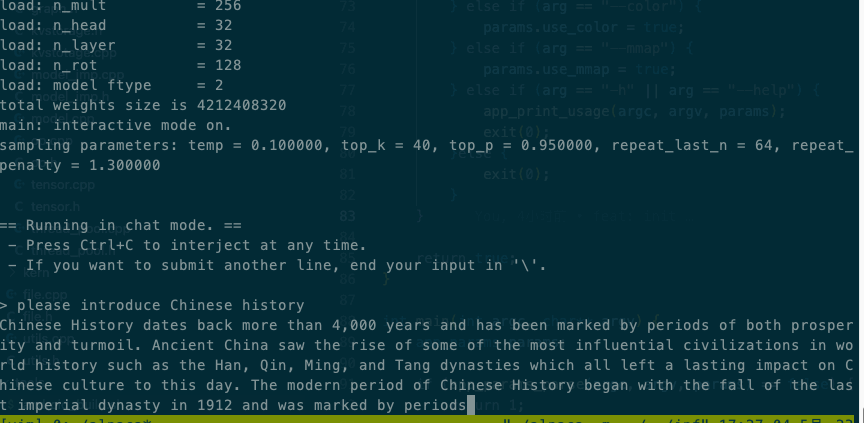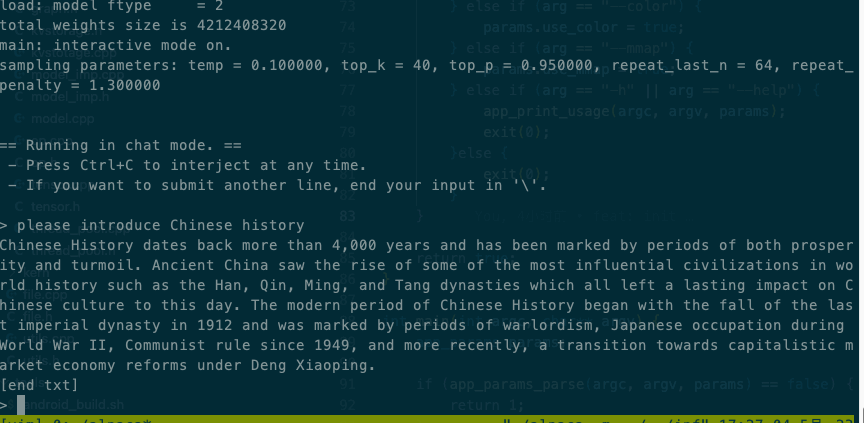
Qualcomm SM8150 Snapdragon 855效果
2.7、LaMiini-LM
链接: https://github.com/mbzuai-nlp/LaMini-LM
简介: LaMini-LM 是从 ChatGPT 中提取的小型高效语言模型的集合,并在 2.58M 指令的大规模数据集上进行了训练。作者探索了不同的模型架构、大小和检查点,并通过各种 NLP 基准和人工评估广泛评估它们的性能。
测试:
# pip install -q transformers``from transformers import pipeline`` ``checkpoint = "{model_name}"``model = pipeline('text2text-generation', model = checkpoint)``input_prompt = 'Please let me know your thoughts on the given place and why you think it deserves to be visited: \n"Barcelona, Spain"'``generated_text = model(input_prompt, max_length=512, do_sample=True)[0]['generated_text']``print("Response", generated_text)
- 1
效果:


3、总结
部署语言大模型是一件极具挑战的事情,简单的调用OpenAI接口只是一部分人的需求,利用各种大模型部署工具链部署自己的大模型才是未来的大趋所向!
- 1
-
首先,你需要搞清楚你是搞通用大模型还是行业大模型;
-
其次,你需要确定你是要使用开源大模型还是开发新的大模型;
-
接着,你需要获取你的场景数据;
-
接着,你需要利用大算力平台去微调你的模型参数;
-
接着,你需要在实际场景去测试你的模型效果;
-
接着,你需要去做大模型的商业化落地;
-
最后,你需要去不断的迭代更新你的大模型。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/652734
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

