
- 1Cortex-M3 启动代码(GCC)详解_cortex-m3的启动汇编代码
- 2使用R语言中的xts包提取时间序列数据是一项常见的任务_r语言xts函数怎么使用
- 30928CSP-S模拟测试赛后总结
- 4华为OD机试真题2023 B卷(JAVA&JS)_od javascript机试题
- 5福利 | 从生物学到神经元:人工神经网络 ( ANN ) 简介
- 6脑电信号的注意机制:基于ViT的情绪识别:论文精读_introducing attention mechanism for eeg signals: e
- 7Vue实现 展开 / 收起 功能_vue展开收起功能
- 8mybatis(超详细,常用)_mybatis常用标签
- 96个技巧帮你提高Python运行效率_提高python运行速度
- 10奇异值分解(SVD)(Singular Value Decomposition)
CNN | 01卷积的前向计算_前向卷积
赞
踩
1卷积的前向计算
1.1卷积的数学定义
1.1.1连续定义
h ( x ) = ( f ∗ g ) ( x ) = ∫ − ∞ ∞ f ( t ) g ( x − t ) d t (1) h(x)=(f*g)(x) = \int_{-\infty}^{\infty} f(t)g(x-t)dt \tag{1} h(x)=(f∗g)(x)=∫−∞∞f(t)g(x−t)dt(1)
卷积与傅里叶变换有着密切的关系。利用这点性质,即两函数的傅里叶变换的乘积等于它们卷积后的傅里叶变换,能使傅里叶分析中许多问题的处理得到简化。
1.1.2离散定义
h ( x ) = ( f ∗ g ) ( x ) = ∑ t = − ∞ ∞ f ( t ) g ( x − t ) (2) h(x) = (f*g)(x) = \sum^{\infty}_{t=-\infty} f(t)g(x-t) \tag{2} h(x)=(f∗g)(x)=t=−∞∑∞f(t)g(x−t)(2)
1.2一维卷积实例
有两枚骰子 f , g f,g f,g,掷出后二者相加为4的概率如何计算?
第一种情况: f ( 1 ) g ( 3 ) , 3 + 1 = 4 f(1)g(3), 3+1=4 f(1)g(3),3+1=4,如图17-9所示。

图17-9 第一种情况
第二种情况: f ( 2 ) g ( 2 ) , 2 + 2 = 4 f(2)g(2), 2+2=4 f(2)g(2),2+2=4,如图17-10所示。

图17-10 第二种情况
第三种情况: f ( 3 ) g ( 1 ) , 1 + 3 = 4 f(3)g(1), 1+3=4 f(3)g(1),1+3=4,如图17-11所示。
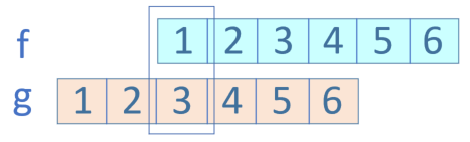
图17-11 第三种情况
因此,两枚骰子点数加起来为4的概率为:
h
(
4
)
=
f
(
1
)
g
(
3
)
+
f
(
2
)
g
(
2
)
+
f
(
3
)
g
(
1
)
=
f
(
1
)
g
(
4
−
1
)
+
f
(
2
)
g
(
4
−
2
)
+
f
(
3
)
g
(
4
−
3
)
符合卷积的定义,把它写成标准的形式就是公式2:
h ( 4 ) = ( f ∗ g ) ( 4 ) = ∑ t = 1 3 f ( t ) g ( 4 − t ) h(4)=(f*g)(4)=\sum _{t=1}^{3}f(t)g(4-t) h(4)=(f∗g)(4)=t=1∑3f(t)g(4−t)
1.3单入单出的二维卷积
二维卷积一般用于图像处理上。在二维图片上做卷积,如果把图像Image简写为 I I I,把卷积核Kernal简写为 K K K,则目标图片的第 ( i , j ) (i,j) (i,j)个像素的卷积值为:
h ( i , j ) = ( I ∗ K ) ( i , j ) = ∑ m ∑ n I ( m , n ) K ( i − m , j − n ) (3) h(i,j) = (I*K)(i,j)=\sum_m \sum_n I(m,n)K(i-m,j-n) \tag{3} h(i,j)=(I∗K)(i,j)=m∑n∑I(m,n)K(i−m,j−n)(3)
可以看出,这和一维情况下的公式2是一致的。从卷积的可交换性,我们可以把公式3等价地写作:
h ( i , j ) = ( I ∗ K ) ( i , j ) = ∑ m ∑ n I ( i − m , j − n ) K ( m , n ) (4) h(i,j) = (I*K)(i,j)=\sum_m \sum_n I(i-m,j-n)K(m,n) \tag{4} h(i,j)=(I∗K)(i,j)=m∑n∑I(i−m,j−n)K(m,n)(4)
公式4的成立,是因为我们将Kernal进行了翻转。在神经网络中,一般会实现一个互相关函数(corresponding function),而卷积运算几乎一样,但不反转Kernal:
h ( i , j ) = ( I ∗ K ) ( i , j ) = ∑ m ∑ n I ( i + m , j + n ) K ( m , n ) (5) h(i,j) = (I*K)(i,j)=\sum_m \sum_n I(i+m,j+n)K(m,n) \tag{5} h(i,j)=(I∗K)(i,j)=m∑n∑I(i+m,j+n)K(m,n)(5)
在图像处理中,自相关函数和互相关函数定义如下:
- 自相关:设原函数是f(t),则 h = f ( t ) ⋆ f ( − t ) h=f(t) \star f(-t) h=f(t)⋆f(−t),其中 ⋆ \star ⋆表示卷积
- 互相关:设两个函数分别是f(t)和g(t),则 h = f ( t ) ⋆ g ( − t ) h=f(t) \star g(-t) h=f(t)⋆g(−t)
互相关函数的运算,是两个序列滑动相乘,两个序列都不翻转。卷积运算也是滑动相乘,但是其中一个序列需要先翻转,再相乘。所以,从数学意义上说,机器学习实现的是互相关函数,而不是原始含义上的卷积。但我们为了简化,把公式5也称作为卷积。这就是卷积的来源。
结论:
- 我们实现的卷积操作不是原始数学含义的卷积,而是工程上的卷积,可以简称为卷积
- 在实现卷积操作时,并不会反转卷积核
在传统的图像处理中,卷积操作多用来进行滤波,锐化或者边缘检测啥的。我们可以认为卷积是利用某些设计好的参数组合(卷积核)去提取图像空域上相邻的信息。
按照公式5,我们可以在4x4的图片上,用一个3x3的卷积核,通过卷积运算得到一个2x2的图片,运算的过程如图17-12所示。

图17-12 卷积运算的过程
1.4单入多出的升维卷积
原始输入是一维的图片,但是我们可以用多个卷积核分别对其计算,从而得到多个特征输出。如图17-13所示。

图17-13 单入多出的升维卷积
一张4x4的图片,用两个卷积核并行地处理,输出为2个2x2的图片。在训练过程中,这两个卷积核会完成不同的特征学习。
1.5多入单出的降维卷积
一张图片,通常是彩色的,具有红绿蓝三个通道。我们可以有两个选择来处理:
- 变成灰度的,每个像素只剩下一个值,就可以用二维卷积
- 对于三个通道,每个通道都使用一个卷积核,分别处理红绿蓝三种颜色的信息
显然第2种方法可以从图中学习到更多的特征,于是出现了三维卷积,即有三个卷积核分别对应书的三个通道,三个子核的尺寸是一样的,比如都是2x2,这样的话,这三个卷积核就是一个3x2x2的立体核,称为过滤器Filter,所以称为三维卷积。

图17-14 多入单出的降维卷积
在上图中,每一个卷积核对应着左侧相同颜色的输入通道,三个过滤器的值并不一定相同。对三个通道各自做卷积后,得到右侧的三张特征图,然后再按照原始值不加权地相加在一起,得到最右侧的白色特征图,这张图里面已经把三种颜色的特征混在一起了,所以画成了白色,表示没有颜色特征了。
虽然输入图片是多个通道的,或者说是三维的,但是在相同数量的过滤器的计算后,相加在一起的结果是一个通道,即2维数据,所以称为降维。这当然简化了对多通道数据的计算难度,但同时也会损失多通道数据自带的颜色信息。
1.6多入多出的同维卷积
在上面的例子中,是一个过滤器Filter内含三个卷积核Kernal。我们假设有一个彩色图片为3x3的,如果有两组3x2x2的卷积核的话,会做什么样的卷积计算?看图17-15。

图17-15 多入多出的卷积运算
第一个过滤器Filter-1为棕色所示,它有三卷积核(Kernal),命名为Kernal-1,Keanrl-2,Kernal-3,分别在红绿蓝三个输入通道上进行卷积操作,生成三个2x2的输出Feature-1,n。然后三个Feature-1,n相加,并再加上b1偏移值,形成最后的棕色输出Result-1。
对于灰色的过滤器Filter-2也是一样,先生成三个Feature-2,n,然后相加再加b2,最后得到Result-2。
之所以Feature-m,n还用红绿蓝三色表示,是因为在此时,它们还保留着红绿蓝三种色彩的各自的信息,一旦相加后得到Result,这种信息就丢失了。
1.7卷积编程模型
上图侧重于解释数值计算过程,而图17-16侧重于解释五个概念的关系:
- 输入 Input Channel
- 卷积核组 WeightsBias
- 过滤器 Filter
- 卷积核 kernal
- 输出 Feature Map

图17-16 三通道经过两组过滤器的卷积过程
在此例中,输入是三维数据(3x32x32),经过2x3x5x5的卷积后,输出为三维(2x28x28),维数并没有变化,只是每一维内部的尺寸有了变化,一般都是要向更小的尺寸变化,以便于简化计算。
对于三维卷积,有以下特点:
- 预先定义输出的feature map的数量,而不是根据前向计算自动计算出来,此例中为2,这样就会有两组WeightsBias
- 对于每个输出,都有一个对应的过滤器Filter,此例中Feature Map-1对应Filter-1
- 每个Filter内都有一个或多个卷积核Kernal,对应每个输入通道(Input Channel),此例为3,对应输入的红绿蓝三个通道
- 每个Filter只有一个Bias值,Filter-1对应b1,Filter-2对应b2
- 卷积核Kernal的大小一般是奇数如:1x1, 3x3, 5x5, 7x7等,此例为5x5
对于上图,我们可以用在全连接神经网络中的学到的知识来理解:
- 每个Input Channel就是特征输入,在上图中是3个
- 卷积层的卷积核相当于隐层的神经元,上图中隐层有2个神经元
- W ( m , n ) , m = [ 1 , 2 ] , n = [ 1 , 3 ] W(m,n), m=[1,2], n=[1,3] W(m,n),m=[1,2],n=[1,3]相当于隐层的权重矩阵 w 11 , w 12 , . . . . . . w_{11},w_{12},...... w11,w12,......
- 每个卷积核(神经元)有1个偏移值
1.8步长 stride
前面的例子中,每次计算后,卷积核会向右或者向下移动一个单元,即步长stride = 1。而在图17-17这个卷积操作中,卷积核每次向右或向下移动两个单元,即stride = 2。

图17-17 步长为2的卷积
在后续的步骤中,由于每次移动两格,所以最终得到一个2x2的图片。
1.9填充 padding
如果原始图为4x4,用3x3的卷积核进行卷积后,目标图片变成了2x2。如果我们想保持目标图片和原始图片为同样大小,该怎么办呢?一般我们会向原始图片周围填充一圈0,然后再做卷积。如图17-18。

图17-18 带填充的卷积
1.10输出结果
综合以上所有情况,可以得到卷积后的输出图片的大小的公式:
H O u t p u t = H I n p u t − H K e r n a l + 2 P a d d i n g S t r i d e + 1 H_{Output}= {H_{Input} - H_{Kernal} + 2Padding \over Stride} + 1 HOutput=StrideHInput−HKernal+2Padding+1
W O u t p u t = W I n p u t − W K e r n a l + 2 P a d d i n g S t r i d e + 1 W_{Output}= {W_{Input} - W_{Kernal} + 2Padding \over Stride} + 1 WOutput=StrideWInput−WKernal+2Padding+1
以图17-17为例:
H O u t p u t = 5 − 3 + 2 × 0 2 + 1 = 2 H_{Output}={5 - 3 + 2 \times 0 \over 2}+1=2 HOutput=25−3+2×0+1=2
以图17-18为例:
H O u t p u t = 4 − 3 + 2 × 1 1 + 1 = 4 H_{Output}={4 - 3 + 2 \times 1 \over 1}+1=4 HOutput=14−3+2×1+1=4
两点注意:
- 一般情况下,我们用正方形的卷积核,且为奇数
- 如果计算出的输出图片尺寸为小数,则取整,不做四舍五入

