
- 1anaconda 安装、配置、开机启动和基本操作 (windows+linux 详细)
- 2力扣--python两数之和--哈希表法(适合初学者,超级详细,保姆级讲解)_两数之和哈希表python
- 3农夫安全-安全网站导航 farmsec_农夫导航
- 4一文详解MySQL——索引篇_分布式mysql索引
- 5Android向服务器的数据库MySQL传输数据:经过修正的 Android + HTTP + xampp +mysql : Post / Get_android studio 做一个界面输入文本往mysql写入数据
- 6都说测试行业饱和了,为什么我们公司给初级测试开到了12K?_武汉测试开发12k
- 7[kubeadm] v1.24之前的Kubernetes集群搭建——使用Docker作为容器运行时(后附一键安装脚本)_kubeadm 1.24 使用docker 部署
- 8基于Springboot+Vue的Java项目-学生读书笔记共享平台系统(附演示视频+源码+LW)
- 94 OpenCV实现多目三维重建(多张图片增量式生成稀疏点云)【附源码】_opencv多目三维重建
- 10Flutter之通知 Notification_flutter notificationlistener
【论文阅读】Learning Transferable Visual Models From Natural Language Supervision
赞
踩
CLIP,从自然语言监督中学习可转移的视觉模型
paper:https://arxiv.org/pdf/2103.00020.pdf![]() https://arxiv.org/pdf/2103.00020.pdf
https://arxiv.org/pdf/2103.00020.pdf
总结:是一个 zero-shot 的视觉分类模型,预训练的模型在没有微调的情况下在下游任务上取得了很好的迁移效果。是在跨模态训练无监督中的开创性工作。
zero-shot:是指零样本学习,在别的数据集上学习好了,直接迁移做分类
CLIP算法的核心是利用自然语言包含的监督信号来训练视觉模型。CLIP 是涉及文字和图片的多模态领域的工作,从文本中得到监督信号,引导视觉分类的任务。
预训练网络的输入是文字与图片的配对,每一张图片都配有一小句解释性的文字。将文字和图片分别通过一个编码器,得到向量表示。这里的文本编码器就是 Transformer;而图片编码器既可以是 Resnet,也可以是 Vision transformer。
为什么CLIP要采用对比学习的方法
- OpenAI是一家从来不愁计算资源的公司,他们喜欢将一切都gpt化(就是做生成式模型);
- 以往的工作表明(ResNeXt101-32x48d, Noisy Student EfficientNet-L2),训练资源往往需要很多,何况这些都只是在ImageNet上的结果,只是1000类的分类任务,而CLIP要做的是开发世界的视觉识别任务,所以训练的效率对于自监督的模型至关重要;
- 而如果任务改为给定一张图片去预测一个文本(或者给定一个文本去预测一张图片),那么训练效率将会非常低下(因为一个图片可能对应很多种说法,一个文本也对应着很多种场景);
- 所以与其做默写古诗词,不如做选择题!(只要判断哪一个文本与图片配对即可);
- 通过从预测任务改为只预测某个单词到只选出配对的答案,模型的训练效率一下提升了4倍;

训练

- 一个图片经过Image_encoder得到特征If,一个文本经过text_encoder得到特征 Tf;
- 两个特征分别经过不同的FC层(目的是将单模态的特征转化为多模态,因为图片的特征可能本身就与文本的不一致,需要转换,但是这里没接激活函数,因为作者发现在多模态下接不接都一样);
- 再做一次L2归一化;
- 计算余弦相似度,得到logits;
- logits与GT计算交叉熵目标函数;
- 而这里的GT就是一个单位阵(因为目标是配对样本之间相似性最强为1,而其他为0);
- 最后将图片的loss与文本的loss加起来求平均即可;
整体架构
主干模型
在文本方面就是Transformer;
在图像方面选择了5中ResNets(ResNet-50,ResNet-101,3个EfficientNet的变体,ResNet-50x4,ResNet-50x16,ResNet-50x64)和三种VIT(分贝是VIT-B/32,VIT-B/16,VIT-L/14)

假设有N 个图片和 N 个文本的编码。需要对它们进行对比学习(contrastive learning)。配对的句子和文本就是一对正样本(也就是对角线上的);不配对的就是负样本(对角线之外的)。预训练网络的目标,就是最大化正样本对的余弦相似度,并最小化负样本的余弦相似度。
推理过程
CLIP 文章的核心 = Zero-shot Transfer
作者研究迁移学习的动机:
之前自监督or无监督的方法,主要研究 frature 学习的能力,model的目标是学习泛化性能好的特征,虽然学习到good-feature,但down-owrk中,还是需要有标签数据做微调。作者想仅训练一个model,在down-work中不再微调。
给定一张图片,如何利用预训练好的网络去做分类呢?给网络一堆分类标签,利用文本编码器得到向量表示。分别计算这些标签与图片的余弦相似度;最终相似度最高的标签即是预测的分类结果。
相比于单纯地给定分类标签,给定一个句子的分类效果更好。比如一种句子模板 A photo of a ...,后面填入分类标签。这种句子模板叫做 prompt(提示)。

-
将要做的分类以填空的形式填进一句话中,以ImageNet为例就是1000句话输入Text Encoder得到输出;
-
将要识别的图片经过Image Encoder得到图片输出,比较文本的输出与图片的输出,选择最相似的那句话就是图片的类别;
代码:
当使用训练好的CLIP模型进行推理时,首先需要使用clip.load()加载模型,然后分别对图像和文本进行前处理。文字前处理是对数据集中的所有类别进行prompt engineering处理,将每个类别转换成句子,clip.tokenize()将句子长度padding到77个token长度。下面的代码中,图像选取了CIFAR100数据集中的其中一张。接下来,将图像和文字分别喂入图像编码器和文字编码器,提取图像特征和文字特征,分别将图像特征和文字特征正则化之后,计算图像特征和文字特征之间的相似度,并对相似度进行softmax操作。
- # 下面代码使用CLIP进行zero shot预测,从CIFAR-100数据集中挑选一张图片,预测这张图像最有可能与此数据集中100个标签中哪一个标签最相似。
- import os
- import clip
- import torch
- from torchvision.datasets import CIFAR100
-
- # Load the model
- device = "cuda" if torch.cuda.is_available() else "cpu"
- model, preprocess = clip.load('ViT-B/32', device) # 加载模型,返回的preprocess中包含一个torchvision transform依次执行Resize,CenterCrop和Normalization等操作。
-
- # Download the dataset
- cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)
-
- # Prepare the inputs
- image, class_id = cifar100[3637]
- image_input = preprocess(image).unsqueeze(0).to(device) # 图像前处理
- text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 文字前处理
-
- # Calculate features
- with torch.no_grad():
- image_features = model.encode_image(image_input) # 图像编码器提取输入图像的特征
- text_features = model.encode_text(text_inputs) # 文字编码器提取输入文字的特征
-
- # Pick the top 5 most similar labels for the image
- image_features /= image_features.norm(dim=-1, keepdim=True) # 正则化
- text_features /= text_features.norm(dim=-1, keepdim=True) # 正则化
- similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) #计算图像特征与文字特征之间的相似度
- values, indices = similarity[0].topk(5)
-
- # Print the result
- print("\nTop predictions:\n")
- for value, index in zip(values, indices):
- print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
- The output will look like the following (the exact numbers may be slightly different depending on the compute device):
- Top predictions:
- snake: 65.31%
- turtle: 12.29%
- sweet_pepper: 3.83%
- lizard: 1.88%
- crocodile: 1.75%

与之前Zero-shot模型的对比
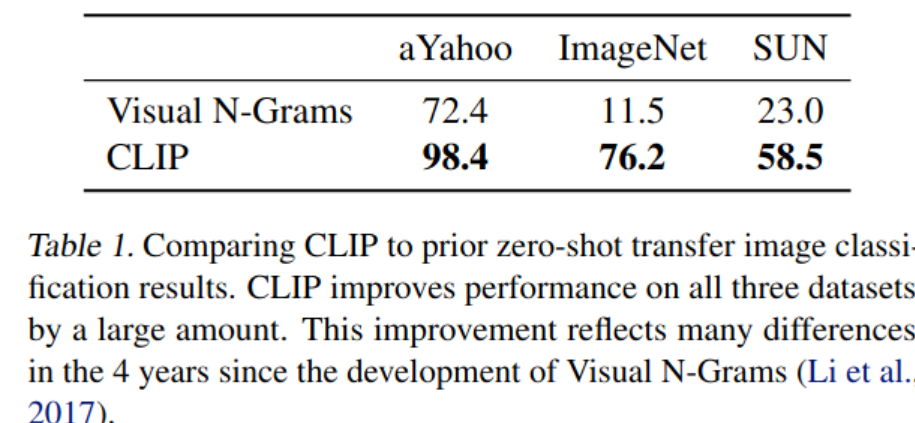
Prompt 方法在什么时候用:
Prompt是提示的意思,对model进行微调和直接做推理时有效;
为什么要用 prompt engineering and ensembling:
由于一个word 具有多义性,图片和文字匹配容易出错,所以作者将word放在语境中,来提高匹配度;
Prompt不仅能做匹配;
一旦加入这个prompt engineering and ensembling,准确度上升了1.3%;
最后在CLIP中,总共用了80个prompt template之多;
实验
大范围数据集结果:
做了27个数据集的分类任务,baseline是ResNet-50,ResNet-50是有监督模型在各个数据集上训练好的, 然后两个模型在其他数据集上zero-shot;

在大多数分类任务,给车、食物等做分类的问题上CLIP都表现的很好, 但是在DTD这种纹理进行分类或CLEVRCounts给物体计数的任务,对于CLIP无监督模型来说就很难了;
所以作者认为在这些更难的数据集做few-shot可能比zero-shot更好;
推理过程中最关键的一点,在于我们有很高的自由度去设置“多项选择题”。从前的分类网络的类别数量是固定的,一般最后一层是跟着 softmax 的全连接层;如果要更改类别数量,就要更换最后一层;并且预测的内容是固定的,不能超过训练集的类别范围。
但对于 CLIP 来说,提供给网络的分类标签不仅数量不固定,内容也是自由的。如果提供两个标签,那就是一个二分类问题;如果提供1000个标签,那就是1000分类问题。标签内容可以是常规的分类标签,也可以是一些冷门的分类标签。我认为这是 CLIP 的一大主要贡献——摆脱了事先定好的分类标签。
模型的泛化性
当数据有distribution shift的时候,模型的表现如何,这是CLIP最惊艳的结果:

可以看出CLIP在数据分布的偏移样本上,远远超过ResNet101,而且结果保持地依旧稳健;
以及作者构造了WebImageText (WIT) 数据集。包含4亿个图片-文本对。
不足
- Zero-shot的CLIP比基于ResNet-50特征的线性分类器相比具有优势,但在很多任务上,仍逊色于SOTA模型。
- CLIP在细分类数据集上表示不好;CLIP不擅长处理抽象任务,比如数一数图像中物体的个数;CLIP对一些不包含预训练集中的新型任务,表现也不好, 比如对一张图像中到最近汽车的距离进行分类。
- 对于一些真正的分布外的数据,CLIP的泛化性能很差。
- CLIP本质上还是在有限的类别中进行推理,相比于image caption直接能生成新的输出,还是具有局限性的。一个值得尝试的简单想法是将对比和生成目标进行联合训练,整合CLIP的有效性和caption模型的灵活性。
- CLIP仍然没有解决深度学习中的poor data efficiency问题。CLIP与自监督和自训练结合训练会是一个提高数据效率方面的方向。
- CLIP 虽然一直强调zero-shot,但是在训练过程中,也反复以数据集的validation performance指导CLIP的表现,并不算真实的zero shot。如果能够创造一个验证zero-shot的迁移能力的新数据集,将会解决这种问题。
- 4亿图像文本对,不论图像和文本都是从网上爬下来的。而是这些图像文本对没有进行过滤和处理,难,难免会携带一些社会性偏见。
- 很多复杂的任务和视觉概念很难仅仅通过文本指定。未来的工作需要进一步开发一种将CLIP强大的zero shot性能与few shot学习相结合的方法。
作者想要:
把一切都GPT(生成式模型)化,因为CLIP还是根据给定的1000个选项去选择到底是那个类比,作者更像直接一张图片,然后生成对应的标题。但受限于计算资源,作者没法做成 ” 自动生成模型 “ 的网络。(以后的DALL)
总结:CLIP 的最大贡献在于打破了固定种类标签的桎梏,让下游任务的推理变得更灵活。在 zero-shot 的情况下效果很不错。可以拓展到其他领域应用,包括物体检测、物体分割、图像生成、视频动作检索等。


