
- 1快速入门Win+R命令(附图)_win r
- 2入门篇:如何快速安装和破解Confluence, 打造您的完美知识库_confluence安装
- 3Python实现新年快乐的效果_python新年快乐代码
- 4人工智能、机器学习、深度学习和神经网络的关系_人工智能 机器学习 神经网络 关系
- 5linux java setting,setting java_home and path environmental variables in linux [duplicate]
- 6抓包工具:Fiddler下载、安装、使用 教程
- 7字符集编码转换--MFC_mfc判断char字符串编码
- 8tf.keras 11: 时间序列预测之LSTM天气预测_lstm预测未来多天数据
- 9VS + QT安装及配置开发环境_vs+qt
- 10嵩天python语言程序设计Python123_python编程:如果输入值大于0,以两个字符一行方式输出"hello world"(空格也是字符)
BP算法和RNN_模型CNN-RNN-LSTM和GRU简介
赞
踩
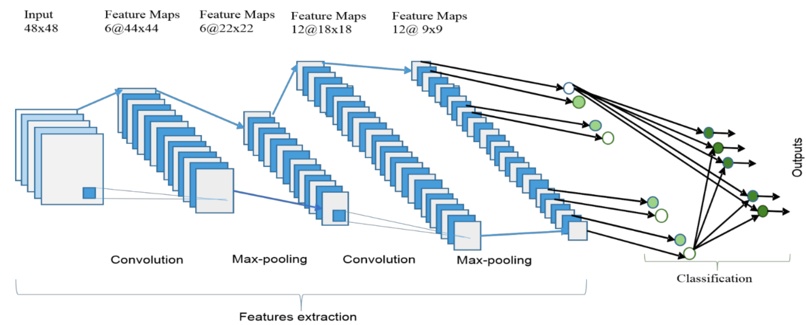
深度学习自从2006年以后已经“火”了十多年了,目前大家看到的,最普遍的应用成果是在计算机视觉、语音识别和自然语言处理(NLP)。最近工业界也在努力地扩展它的应用场景,比如游戏、内容推荐和广告匹配等等。
深度模型架构分三种:
- 前向反馈网络:MLP,CNN;
- 后向反馈网络:stacked sparse coding, deconvolutional nets;
- 双向反馈网络:deep Boltzmann machines, stacked auto-encoders。
卷积神经网络(Convolutional Neural Network, CNN) 应该是最流行的深度学习模型,在计算机视觉也是影响力最大的。下面介绍一下深度学习中最常用的CNN模型,以及相关的RNN模型,其中也涉及到著名的LSTM和GRU。
基本概念
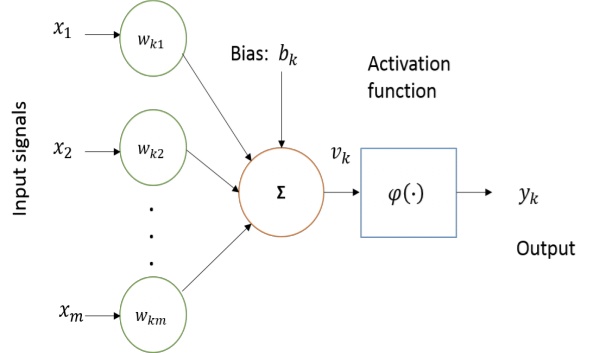
计算神经生物学对构建人工神经元的计算模型进行了重要的研究。试图模仿人类大脑行为的人工神经元是构建人工神经网络的基本组成部分。基本计算元素(神经元)被称为节点(或单元),其接收来自外部源的输入,具有产生输出的一些内部参数(包括在训练期间学习的权重和偏差)。 这个单位被称为感知器。感知器的基本框图如下图所示。
图显示神经元的基本非线性模型,其中 1, 2, 3,... 是输入信号; 1, 2, 3,⋯ 是突触权重; 是输入信号的线性组合; φ(∙)是激活函数(例如sigmoid), 是输出。 偏移 与输出的线性组合器相加,具有应用仿射变换的效果,产生输出 。 神经元功能可以用数学表示如下:
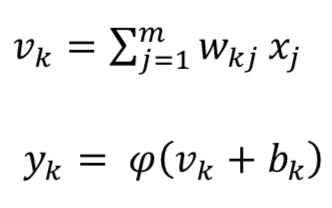
人工神经网络或一般神经网络由多层感知器(MLP)组成,其中包含一个或多个隐藏层,每层包含多个隐藏单元(神经元)。 具有MLP的NN模型如图所示。
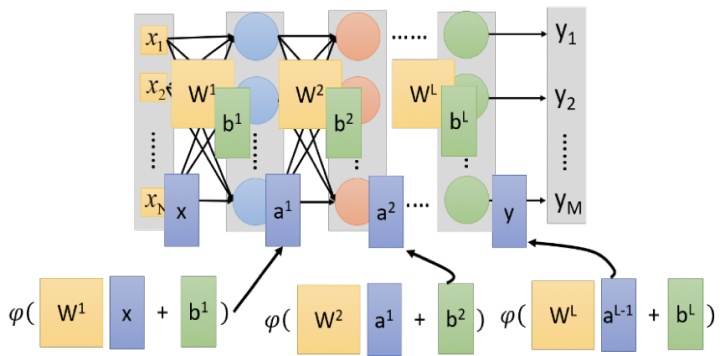
多层感知器输出
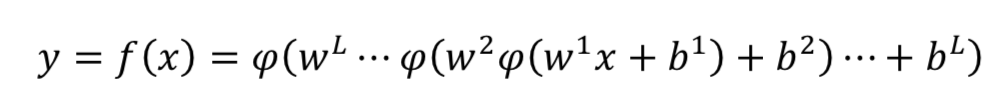
学习率(learning rate)是训练DNN的重要组成部分。它是训练期间考虑的步长,使训练过程更快。但是,选择学习率是敏感的。如果为η较大,网络可能会开始发散而不是收敛;另一方面,如果η选择较小,则网络需要更多时间收敛。此外它可能很容易陷入局部最小值。
有三种常用方法可用于降低训练期间的学习率:常数、因子和指数衰减。首先,可以定义一个常数ζ,基于定义的步长函数手动地降低学习率。 其次,可以在训练期间根据以下等式调整学习率:
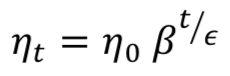
指数衰减的步进函数格式为:
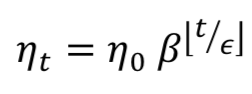
梯度下降法是一阶优化算法,用于寻找目标函数的局部最小值。算法1解释了梯度下降的概念:
算法1 梯度下降
输入:损失函数ε,学习率η,数据集 , 和模型F(θ, )
输出:最小化ε的最优θ
重复直到收敛:

结束
由于训练时间长是传统梯度下降法的主要缺点,因此随机梯度下降(Stochastic Gradient Descent ,SGD)方法用于训练深度神经网络(DNN)。 算法2详细解释了SGD。
算法2 随机梯度下降
输入:损失函数ε,学习率η,数据集 , 和

