- 1帕鲁服务器怎么开,palworld,palserver,steamcmd,内存泄露解决_帕鲁 docker 存档
- 2自动驾驶消息传输机制-LCM
- 3如何防止Redis 缓存雪崩、缓存穿透、缓存击穿_请写出来防止缓存穿透的方案
- 4pyecharts导入html数据,数据可视化之pyecharts
- 5Sora了解资料_sora的api端口
- 6抓包程序丢包的问题_pcap_dispatch会丢包吗
- 7微信小程序 之 发布流程_当小程序开发者开发完成小程序并准备发布时,需要先在小程序后台进行域名配置,并通
- 8Unturned未转变者 Windows SteamCMD 2023最新开服教程-全网最全_steamcmd开服教程
- 9常见的几种多线程架构
- 10overleaf 提交arXiv 不成功_overleaf导出arxiv
【数值预测案例】(5) LSTM 时间序列气温数据预测,附TensorFlow完整代码_lstm预测未来七天的数据
赞
踩
大家好,今天和各位分享一下如何使用循环神经网络 LSTM 完成有多个特征的气温预测。上一节中我介绍了 LSTM 的单个特征的预测,感兴趣的可以看一下:https://blog.csdn.net/dgvv4/article/details/124349963
1. 导入工具包
我使用GPU加速计算,没有GPU的朋友可以把调用GPU的代码段去掉。
- import tensorflow as tf
- from tensorflow import keras
- from tensorflow.keras import layers
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
-
- # 调用GPU加速
- gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
- for gpu in gpus:
- tf.config.experimental.set_memory_growth(gpu, True)
2. 读取数据集
数据集地址:https://pan.baidu.com/s/1E5h-imMwdIyPv1Zc7FfC9Q 提取码:9cb5
该数据集10分钟记录一次,有42w行数据,14列特征,选取除时间列以外的前10列特征用于本模型。使用pandas的绘图方法绘制特征随时间的变化曲线。
- #(1)读取数据集
- filepath = 'D:/deeplearning/test/神经网络/循环神经网络/climate.csv'
- data = pd.read_csv(filepath)
- print(data.head()) # 数据是10min记录一次的
-
- #(2)特征选择
- # 选择从第1列开始往后的所有行的数据
- feat = data.iloc[:, 1:11] # 最后4个特征列不要
- date = data.iloc[:, 0] # 获取时间信息
-
- #(3)利用pandas绘图展示每个特征点分布情况
- feat.plot(subplots=True, figsize=(80,10), # 为每一列单独开辟子图,设置画板大小
- layout=(5,2), title='climate features') # 14张图的排序方式,设置标题
数据集信息如下
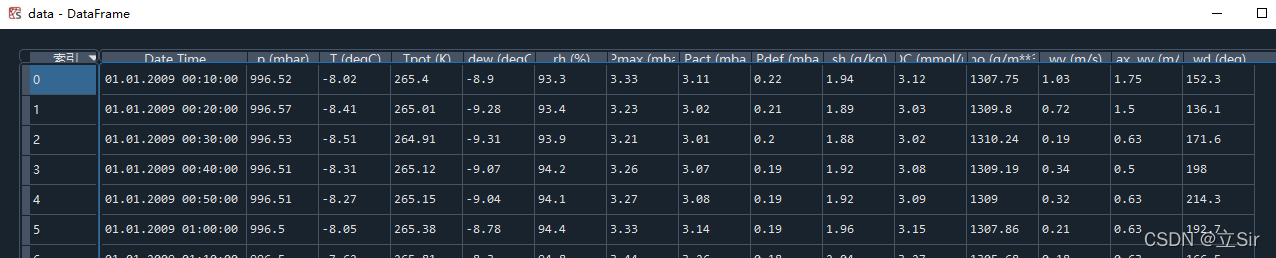
绘制除时间特征DateTime列以外的后10列的特征数据的随时间变化的曲线

3. 数据预处理
由于数据量较大,全部用于训练可能会导致内存占用不足的报错,这里就取前2w个数据用于训练。求训练集中,每个特征列的均值和标准差,对整个数据集使用训练集的均值和标准差进行标准化预处理。以标准化后的气温数据作为标签。
- #(4)特征数据预处理
- train_num = 20000 # 取前2w组数据用于训练
- val_num = 23000 # 取2w-2.3w的数据用于验证
- # 2.3w-2.5w的数据用于验证用于测试
-
- # 求训练集的每个特征列的均值和标准差
- feat_mean = feat[:train_num].mean(axis=0)
- feat_std = feat[:train_num].std(axis=0)
-
- # 对整个数据集计算标准差
- feat = (feat - feat_mean) / feat_std
-
- # 保存所有的气温数据,即标签数据
- targets = feat.iloc[:,1] # 取标准化之后的气温数据作为标签值
4. 时间序列函数提取特征和标签
通过一个滑动窗口在数据集上移动,例如使用当前10个特征的20行数据预测未来某一时间点/段的气温。任务要求使用连续5天的数据预测下一个时间点的气温值,数据是10min记录一次的。
对某一时间点的预测:五天一共有5*24*6=720个数据,窗口每次滑动一步,第一次滑动窗口范围 range(0, 720, 1),预测第720个气温。第二次滑动窗口范围 range(1,721,1),预测第721个气温。range()取值顾头不顾尾
对某一时间段的预测:由于数据集是10min记录一次的,两两数据行之间的差别很小,可以设置一个步长每隔60min取一次特征数据,第一次滑动窗口范围 range(0, 720, 6),预测下一整天的每个小时的气温数据,即 range(720, 720+24*6, 6)。第二次滑动窗口范围 range(1,721,6),预测下一天的小时气温 range(721, 721+24*6, 6)
这里就预测某一时间点的数据,参数如下,可以自行修改
- '''
- dataset 代表特征数据
- start_index 代表从数据的第几个索引值开始取
- history_size 滑动窗口大小
- end_index 代表数据取到哪个索引就结束
- target_size 代表预测未来某一时间点还是时间段的气温。例如target_size=0代表用前20个特征预测第21个的气温
- step 代表在滑动窗口中每隔多少步取一组特征
- point_time 布尔类型,用来表示预测未来某一时间点的气温,还是时间段的气温
- true 原始气温数据的所有标签值
- '''
-
- def TimeSeries(dataset, start_index, history_size, end_index, step,
- target_size, point_time, true):
-
- data = [] # 保存特征数据
- labels = [] # 保存特征数据对应的标签值
-
- start_index = start_index + history_size # 第一次的取值范围[0:start_index]
-
- # 如果没有指定滑动窗口取到哪个结束,那就取到最后
- if end_index is None:
- # 数据集最后一块是用来作为标签值的,特征不能取到底
- end_index = len(dataset) - target_size
-
- # 滑动窗口的起始位置到终止位置每次移动一步
- for i in range(start_index, end_index):
-
- # 滑窗中的值不全部取出来用,每隔60min取一次
- index = range(i-history_size, i, step) # 第一次相当于range(0, start_index, 6)
-
- # 根据索引取出所有的特征数据的指定行
- data.append(dataset.iloc[index])
-
- # 用这些特征来预测某一个时间点的值还是未来某一时间段的值
- if point_time is True: # 预测某一个时间点
- # 预测未来哪个时间点的数据,例如[0:20]的特征数据(20取不到),来预测第20个的标签值
- labels.append(true[i+target_size])
-
- else: # 预测未来某一时间区间
- # 例如[0:20]的特征数据(20取不到),来预测[20,20+target_size]数据区间的标签值
- labels.append(true[i:i+target_size])
-
- # 返回划分好了的时间序列特征及其对应的标签值
- return np.array(data), np.array(labels)
5. 划分数据集
使用上面的时间序列函数获取训练所需的特征值和标签值。这里以预测下一个时间点的气温值为例,history_size 指定时间序列窗口的大小,即用多少行数据来预测一个时间点的气温值;target_size 代表未来哪个时间点的值,为0代表,如range(0,720,1)的特征用来预测第720+0个时间点的气温值。point_time=False时代表预测某一时间段。
- #(6)划分数据集
- history_size = 5*24*6 # 每个滑窗取5天的数据量=720
- target_size = 0 # 预测未来下一个时间点的气温值
- step = 1 # 步长为1取所有的行
-
- # 构造训练集
- x_train, y_train = TimeSeries(dataset=feat, start_index=0, history_size=history_size, end_index=train_num,
- step=step, target_size=target_size, point_time=True, true=targets)
-
- # 构造验证集
- x_val, y_val = TimeSeries(dataset=feat, start_index=train_num, history_size=history_size, end_index=val_num,
- step=step, target_size=target_size, point_time=True, true=targets)
-
- # 构造测试集
- x_test, y_test = TimeSeries(dataset=feat, start_index=val_num, history_size=history_size, end_index=25000,
- step=step, target_size=target_size, point_time=True, true=targets)
-
- # 查看数据集信息
- print('x_train_shape:', x_train.shape) # (19280, 720, 10)
- print('y_train_shape:', y_train.shape) # (19280,)
6. 构造数据集
将划分好了的特征值和标签值转为tensor类型,对训练集的特征行随机打乱shuffle(),并且每次迭代时每个step训练batchsize=128组数据。设置迭代器 iter(),从数据集中取出一个batch的数据 next()。标签值y_train代表滑动窗口的每720行特征数据对应1个标签气温值。
- #(7)构造数据集
- train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 训练集
- train_ds = train_ds.batch(128).shuffle(10000) # 随机打乱、每个step处理128组数据
-
- val_ds = tf.data.Dataset.from_tensor_slices((x_val, y_val)) # 验证集
- val_ds = val_ds.batch(128)
-
- test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 测试集
- test_ds = test_ds.batch(128)
-
- # 查看数据集信息
- sample = next(iter(train_ds)) # 取出一个batch的数据
- print('x_train.shape:', sample[0].shape) # [128, 720, 10]
- print('y_train.shape:', sample[1].shape) # [128, ]
7. 模型构建
接下来就是自定义LSTM网络,这个无所谓想怎么搭都行,要注意的时 layers.LSTM() 层中有一个参数 return_sequences,代表返回输出序列中的最后一个值,还是所有值。默认False。一般是下一层还是 LSTM 的时候才用 return_sequences=True
- #(8)模型构建
- inputs_shape = sample[0].shape[1:] # [120,10] 不需要写batch的维度大小
- inputs = keras.Input(shape=inputs_shape) # 输入层
-
- # LSTM层,设置l2正则化
- x = layers.LSTM(units=8, dropout=0.5, return_sequences=True, kernel_regularizer=tf.keras.regularizers.l2(0.01))(inputs)
- x = layers.LeakyReLU()(x)
- x = layers.LSTM(units=16, dropout=0.5, return_sequences=True, kernel_regularizer=tf.keras.regularizers.l2(0.01))(inputs)
- x = layers.LeakyReLU()(x)
- x = layers.LSTM(units=32, dropout=0.5, kernel_regularizer=tf.keras.regularizers.l2(0.01))(x)
- x = layers.LeakyReLU()(x)
- # 全连接层,随即正态分布的权重初始化,l2正则化
- x = layers.Dense(64,kernel_initializer='random_normal',kernel_regularizer=tf.keras.regularizers.l2(0.01))(x)
- x = layers.Dropout(0.5)(x)
- # 输出层返回回归计算后的未来某一时间点的气温值
- outputs = layers.Dense(1)(x) # 标签shape要和网络shape一样
-
- # 构建模型
- model = keras.Model(inputs, outputs)
-
- # 查看网络结构
- model.summary()
网络结构如下
- _________________________________________________________________
- Layer (type) Output Shape Param #
- =================================================================
- input_3 (InputLayer) [(None, 720, 10)] 0
- _________________________________________________________________
- lstm_7 (LSTM) (None, 720, 16) 1728
- _________________________________________________________________
- leaky_re_lu_7 (LeakyReLU) (None, 720, 16) 0
- _________________________________________________________________
- lstm_8 (LSTM) (None, 32) 6272
- _________________________________________________________________
- leaky_re_lu_8 (LeakyReLU) (None, 32) 0
- _________________________________________________________________
- dense_4 (Dense) (None, 64) 2112
- _________________________________________________________________
- dropout_2 (Dropout) (None, 64) 0
- _________________________________________________________________
- dense_5 (Dense) (None, 1) 65
- =================================================================
- Total params: 10,177
- Trainable params: 10,177
- Non-trainable params: 0
- _________________________________________________________________
8.网络训练
使用平均绝对误差作为回归损失函数,训练完成后对整个测试集评估.evaluate(),计算整个测试集的损失。
- # 网络编译
- model.compile(optimizer = keras.optimizers.Adam(0.001), # adam优化器学习率0.001
- loss = tf.keras.losses.MeanAbsoluteError()) # 计算标签和预测之间绝对差异的平均值
-
- epochs = 15 # 网络迭代次数
-
- # 网络训练
- history = model.fit(train_ds, epochs=epochs, validation_data=val_ds)
-
- # 测试集评价
- model.evaluate(test_ds) # loss: 0.1212
训练过程如下:
- Epoch 1/15
- 151/151 [==============================] - 11s 60ms/step - loss: 0.8529 - val_loss: 0.4423
- Epoch 2/15
- 151/151 [==============================] - 9s 56ms/step - loss: 0.3999 - val_loss: 0.2660
- ------------------------------------------
- ------------------------------------------
- Epoch 14/15
- 151/151 [==============================] - 9s 56ms/step - loss: 0.1879 - val_loss: 0.1442
- Epoch 15/15
- 151/151 [==============================] - 9s 56ms/step - loss: 0.1831 - val_loss: 0.1254
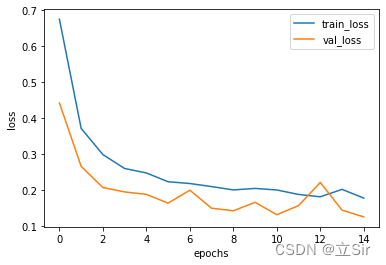
9. 训练过程可视化
history 中保存了网络训练过程的所有指标,这里只使用了平均绝对误差损失,将损失指标随着每次迭代的变化曲线绘制出来。
- #(10)查看训练信息
- history_dict = history.history # 获取训练的数据字典
- train_loss = history_dict['loss'] # 训练集损失
- val_loss = history_dict['val_loss'] # 验证集损失
-
- #(11)绘制训练损失和验证损失
- plt.figure()
- plt.plot(range(epochs), train_loss, label='train_loss') # 训练集损失
- plt.plot(range(epochs), val_loss, label='val_loss') # 验证集损失
- plt.legend() # 显示标签
- plt.xlabel('epochs')
- plt.ylabel('loss')
- plt.show()
10. 预测阶段
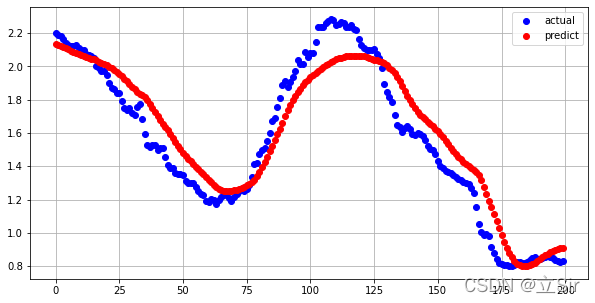
为了绘图清晰,只对测试集的前200组特征(每一组有720行10列,720代表一个滑窗大小,10代表特征列个数)进行预测,使用.predict()函数 得到每组对应下一时刻的气温预测值。
- #(12)预测阶段
- # x_test[0].shape = (720,10)
- x_predict = x_test[:200] # 用测试集的前200组特征数据来预测
- y_true = y_test[:200] # 每组特征对应的标签值
-
- y_predict = model.predict(x_predict) # 对测试集的特征预测
-
- # 绘制标准化后的气温曲线图
- fig = plt.figure(figsize=(10,5)) # 画板大小
- axes = fig.add_subplot(111) # 画板上添加一张图
- # 真实值, date_test是对应的时间
- axes.plot(y_true, 'bo', label='actual')
- # 预测值,红色散点
- axes.plot(y_predict, 'ro', label='predict')
-
- plt.legend() # 注释
- plt.grid() # 网格
- plt.show()
预测值和真实值的对比如下