
热门标签
热门文章
- 1APP测试Adb操作命令与Monkey使用、查错流程(入门+精通级)_monkey命令忽略崩溃
- 2HTML5前端开发学习路线建议,学习前端的必备知识点_html学习的建议
- 3打造明厨亮灶工程,需要哪些AI视频智能算法助力?
- 4第十章 重积分
- 5探索生物世界的奥秘:深度学习助力AlphaFold2预测蛋白质结构
- 6uniapp开发抖音小程序监听键盘弹起keyboardheightchange,并获取键盘高度(全网第一唯一成功案例,你问ai都没用)_小程序获取键盘高度
- 7大学四年学计算机最值得看的技术书,要读就读最好的书,程序员精品书单!(1)_c++算法书籍推荐 csdn
- 8如何使用 GitHub Action 在 Android 中构建 CI-CD_github actions 实现cicd
- 9xc_oracle 1047 error,Error: DPI-1047: Cannot locate a 64-bit Oracle Client library: "问题
- 10kafka监控工具----cmak安装_cmak 3.0.0.6配置
当前位置: article > 正文
hadoop集群读、写数据的流程_hadoop集群只会上传数据到datanode吗
作者:小小林熬夜学编程 | 2024-05-23 14:37:39
赞
踩
hadoop集群只会上传数据到datanode吗
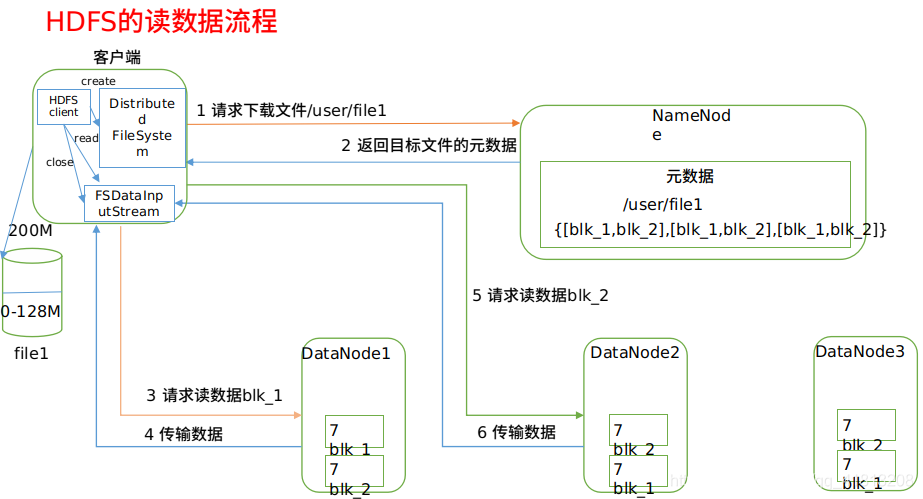
1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
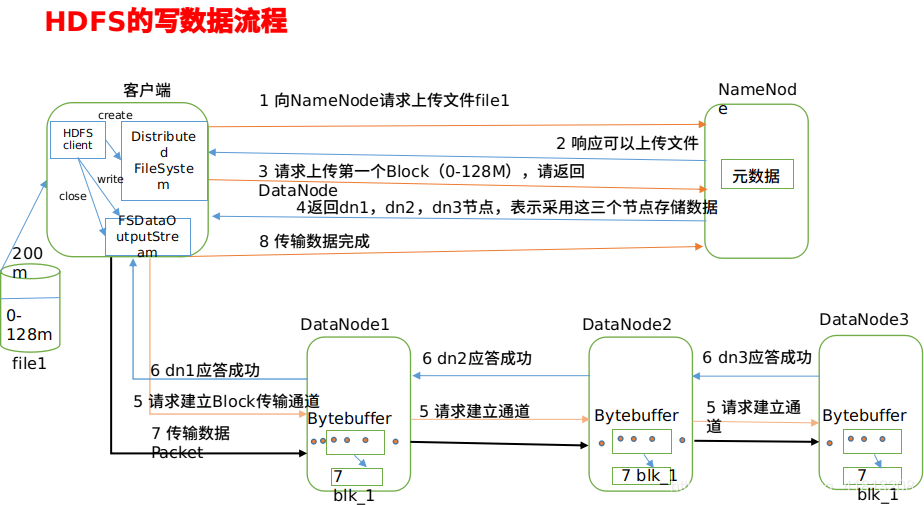
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读

相关标签

