
- 1LangChain的Memory的4种用法(一)_langchain + memory
- 2独家 | 从零开始用python搭建推荐引擎(附代码)
- 3[LangChain核心模块]模型的输入和输出->Prompts_langchain怎么选择prompt
- 4这7本书Web安全的必须看(附全套PDF)_web安全攻防渗透测试实战指南 pdf
- 5Android系统中Thread,Looper,MessageQueue,Message,Handler相互关系的简单分析_android server new thread looper handlemessage
- 6Linux的虚拟环境下安装GPU版本的torch、torchaudio、torchvision详细过程_linux安装torch
- 7几个数据采集工具分享,都是免费的
- 8Unity 踩坑笔记 两种Animation Clip_unity 给animator里的添加animationclip
- 9蓝屏代码大全(留着自己看)
- 10api-ms-win-core-file-l1-1-0.dll文件找不到的完美解决方法_api-ms-win-core-l1-1-0.dll 丢失
【机器学习】最优化方法:梯度下降法_梯度下降 最优解
赞
踩
1. 概念
梯度下降法(Gradient Descent)又称最速下降法(Steepest descent)是一种常用的一阶优化方法,是一种用于求解无约束最优化问题的最常用的方法。它选取适当的初始值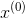
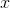
2. 梯度下降的直观解释
以下山法作为类别,我们想要从山的某个位置下山,但我们并不知道山脚的位置,只能走一步算一步。从当前位置出发,往当前位置的负梯度方向走一步,即往最陡峭的方向往下走一步。然后继续求解当前位置的梯度,往负梯度方向走一步。不停走下去,一直走到我们认为已经到了山脚的位置。当然,也有可能,我们没办法到山脚,而是到了一个小山丘底部。
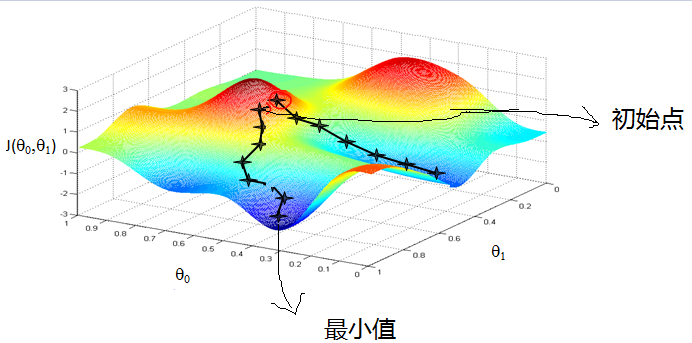
当目标函数是凸函数的时候,梯度下降法可以确保找到全局最优解;否则不一定能找到全局最优解,可能会陷入局部最优解。
3. 梯度下降法的原理
考虑最优化问题
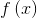
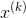
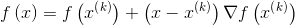

凸函数
的某一小段
由上图黑色曲线表示,可以利用线性近似的思想求出
处的导数。则根据直线方程,很容易得到
这就是一阶泰勒展开式的推导过程,主要利用的数学思想就是曲线函数的线性拟合近似。
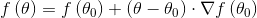
其中,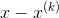
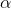


此时,(1)可以化为:
我们希望每次迭代,都能使
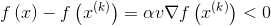
由于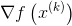
当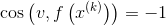
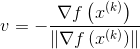
以上解释了为什么局部下降最快的方向就是梯度的负方向。
将(6)中的最优解

由于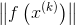
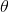
以上就是梯度下降算法公式的数学推导过程。
4. 算法描述
输入:目标函数

输出: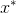
(1)初始化相关参数。取初始值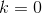
(2)计算当前位置的目标函数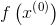
(3)计算当前位置的目标函数的梯度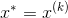
(4)更新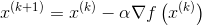
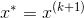
在机器学习中,目标函数
5. 梯度下降法种类
5.1 批量梯度下降法(Batch Gradient Descent,BGD)
批量梯度下降法是梯度下降法最常用的形式。每次更新参数要使用所有的样本进行计算。
假设目标函数为:
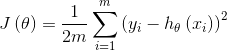
求偏导得:
批量梯度下降法的更新公式为:
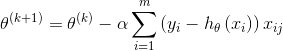
5.2 随机梯度下降法(Stochastic Gradient Descent,SGD)
随机梯度下降法与批量梯度下降法类似。每次更新参数只使用随机的一个样本进行计算。
随机梯度下降法的更新公式为:

批量梯度下降法和随机梯度下降法的区别是什么?
(1)批量梯度下降法每次使用所有数据来更新参数,训练速度慢;
(2)随机梯度下降法每次只使用一个数据来更新参数,训练速度快;但迭代方向变化大,不一定每次都朝着收敛的方向,不能很快地收敛到局部最优解。
5.3 小批量梯度下降法(Mini-Batch Gradient Descent,MBGD)
小批量梯度下降法是批量梯度下降法和随机梯度下降法的一个折中。每次更新参数选择一小部分数据计算。
选择
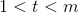
小批量梯度下降法的更新公式为:
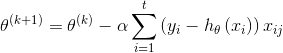
6. 局部最优解解决方法
如第二节(梯度下降的直观解释)中描述的,如果目标函数具有多个局部极小值,不能保证找到的解是全局最优解。为了解决这一问题,常采用以下策略来试图跳出局部最优:
1. 以多组不同参数值进行初始化,这样有可能陷入不同的局部极小,从中进行选择有可能获得更接近全局最小的结果;
2. 使用“模拟退火”技术,在每一步都以一定概率接收比当前解更差的结果,有助于跳出局部极小;
3. 使用随机梯度下降,最小化每个样本的损失函数,而不是最小化整体的损失函数,虽然不是每次迭代得到的损失函数都朝着收敛的方向, 但是整体的方向是朝着全局最优解的,最终的结果往往是在全局最优解附近。
参考文献:
1.《 统计学习方法》附录A梯度下降法——李航

