
- 1《STM32 HAL库》中断相关函数详尽解析——外部中断服务函数
- 2Stable Diffusion——stable diffusion基础原理详解与安装秋叶整合包进行出图测试
- 3第二弹!又来5个Jupyter Notebook使用技巧!
- 4Spring框架中涉及的设计模式_spring 代码设计
- 5探索 StableDiffusion:生成高质量图片学习及应用
- 6前端面试八股文 - 面试必备_前端八股文面试题2023
- 7测试老鸟分享:掌握2项技能,轻松拿到软件测试工程师offer...
- 8缓存相关问题:雪崩、穿透、预热、更新、降级的深度解析
- 9Kimi创始人套现4000万美元疑云|「商汤」大模型一体机可节约80%推理成本,完成云端边全栈布局|中国AI活化石,熬成AIGC第一股| 谁在制造小米汽车?_商汤 kimi
- 10微信小程序 java ssm 17.微信小程序跑腿平台的设计与实现(完整源码+数据库文件+万字文档+保姆级视频部署教程+配套环境)
“全网最全”LLM推理框架集结营 | 看似微不足道,却决定着AIGC项目的成本、效率与性能!_fastchat 并行推理
赞
踩
00-前序

随着ChatGPT、GPT-4等大语言模型的出现,彻底点燃了国内外的学者们与企业家们研发LLM的热情。国内外的大语言模型如雨后春笋一般的出现,这些大语言模型有一部分是开源的,有一部分是闭源的。
伴随着大语言模型的出现,国内外基于大语言模型的上层应用产品更是层出不穷,Huggingface上每天都会有大量新奇的应用出现在我们的眼前。对于任何一个大语言模型产品而言,都会涉及到一个很关键的步骤,如何低成本、稳定、高效的将某个大语言模型部署在特定的硬件平台上面,为了完成大语言模型的部署,LLM推理框架应运而生!
与传统的AI推理框架不同,基于LLM的推理框架的硬件规模更大、底层算子的复杂度更高、上层的推理形态更加多样。随着众多优质的大语言模型逐渐开源,算法端的门槛正在逐步降低,因而不同厂家的产品壁垒主要体现在不同的LLM推理框架上面。
虽然当前已经出现了众多开源的LLM推理框架,但是不同的LLM推理框架有着不同的侧重点,有着不同的特点。为了更好的节约项目成本、提升项目开发效率,根据自己的项目需求选择一个合适的LLM推理框架成为了一个至关重要的问题!由于大家可能都有自己的圈层,每个人知道或者了解到的LLM推理框架不尽相同,但是你并不能保证你了解到的就一定是最适合你的LLM推理框架!本文小编耗费了大量的精力帮你把国内外主流的LLM推理框架整理了出来,更多的细节请看下文。
01-vLLM
01.01-简介
链接-https://github.com/vllm-project/vllm
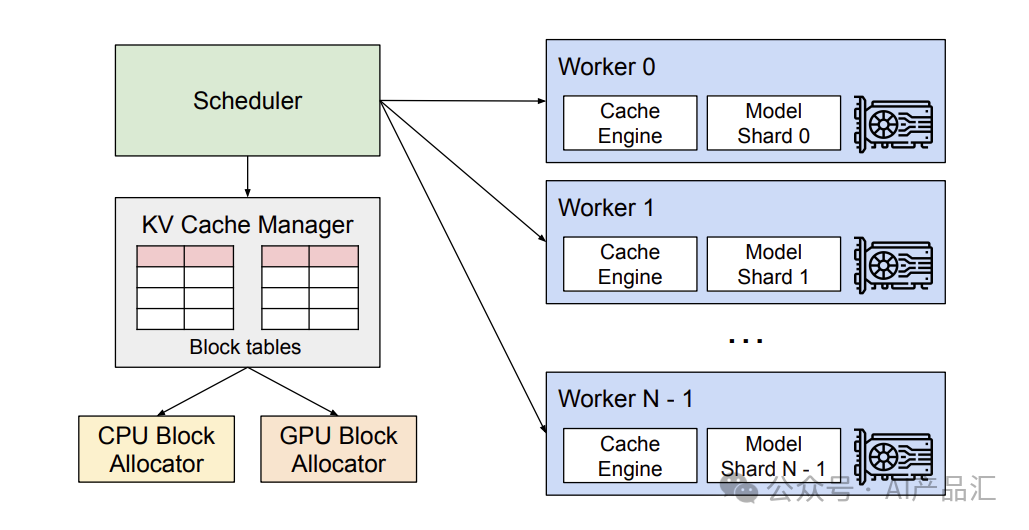
上图展示了vLLM的整体架构。vLLM采用集中式调度器来协调分布式GPU工作程序的执行。KV缓存管理器通过PagedAttention以分页方式有效地管理KV缓存。具体来说,KV缓存管理器通过集中式调度器发送的指令来管理GPU工作程序上的物理KV缓存
01.02-特点
- 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/583494
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

