
GPT-4、百度文心一言摆擂,AI大模型将掀起新一轮AIGC军备竞赛?_大模型大赛
赞
踩
科技云报道原创。
一觉醒来,万众期待的GPT-4来了。OpenAI老板Sam Altman直接开门见山地介绍说:“这是我们迄今为止功能最强大的模型!”仅隔一天,“中国版ChatGPT”百度文心一言正式发布,双方大有摆擂之势。

当深度学习推动AI技术又一次复兴,人类对它的最高期待,就是让AI成为第四次产业革命中的“蒸汽机”。
而近几年身处智能革命前沿的,就是预训练大模型。
ChatGPT的横空出世,不仅在科技圈引起哗然,更是点燃了创投圈的创业激情。
国内企业的大规模预训练模型(以下简称“大模型”)赛道也已经开始进入白热化的竞争阶段。
在过去的两周内,诸多以AI大模型为技术底层的厂商,开始获得资本的青睐。
那么,AI大模型目前的主要技术路径是怎样的?在产业侧的成长如何?
“通用大模型+产业模型”的技术路径
必须正视的是,全球大模型竞赛中,我们看到大模型的参数越来越大,数据集记录不断被刷新。
“在各种专业和学术基准上和人类相当。”对于刚刚发布的GPT-4,OpenAI对于其表现相当满意。
OpenAI在官网表示,GPT-4是一个能接受图像和文本输入,并输出文本的多模态模型,是OpenAI在扩展深度学习方面的最新里程碑。
从性能表现看,GPT-4的语言理解和生成能力均超过了ChatGPT,可以解答ChatGPT无法完成的问题,同时GPT-4可以描述并理解图片,并且可接受的文字输入长度也增加到约2.4万个单词。
升级之后,GPT-4在各种职业和学术考试上表现和人类水平相当。
比如模拟律师考试,GPT-4取得了前10%的好成绩,相比之下GPT-3.5是倒数10%。
做美国高考SAT试题,GPT-4也在阅读写作中拿下710分高分、数学700分(满分800)。
但真正的产业空间里,却很难看到大模型规模化、标准化应用。
这可能是因为大模型与行业知识不相匹配,行业算力基础难以负载大模型部署等等问题。
过去多年的一个市场共识是,如果要实现AI规模化产业落地,底层AI大模型就必须是一个通用的大模型平台,厂商根据用户需求在平台之上,进行多场景、多领域的模型生产,从而实现具体行业模型的落地。
对于厂商而言,这也是一个新的方向。即AI厂商以“通用模型+产业模型”不断赋能企业、产业,从而加速中国的产业数字化进程。
更为重要的是,这种模式一旦落地成功或将快速实现规模化效应,或将为头部AI厂商带来高回报,摆脱当下AI技术落地难,盈利难的现状。
底层AI大模型的研发具有数据规模大、质量参差不齐、模型体积大、训练难度高、算力规模大、性能要求高等挑战。
这样的高研发门槛,不利于人工智能技术在千行百业的推广。
而具有数据、算力、算法综合优势的企业可以将模型的复杂生产过程封装起来,通过低门槛、高效率的生产平台,向千行百业提供大模型服务。
各个行业的企业只需要通过生产平台提出在实际AI应用中的具体需求,生产大模型的少数企业就能够根据应用场景进一步对大模型开发训练,帮助应用方实现大模型的精调,以达到各行业对于AI模型的直接应用。
彼时,AI大模型就会真正意义上实现产业化,成为产业模型。
目前,国内布局AI大模型厂商百度、阿里、腾讯、商汤、华为等企业,正在不断夯实通用大模型,打造产业模型,助力AI大模型产业化。
其中,百度以文心大模型+飞桨PaddlePaddle深度学习平台;腾讯以HunYuan大模型+太极机器学习平台;阿里以通义大模型+M6-OFA;华为以盘古大模型+ModelArts,都打造了自然语言处理大模型、计算机视觉大模型以及多模态大模型方面。
值得注意的是,各个厂商AI大模型的布局,有所差异。
百度由于多年在AI领域的深耕,其文心大模型涵盖基础大模型、任务大模型、行业大模型的三级体系,打造大模型总量约40个,产业应用也较为广泛,例如电力、燃气、金融、航天等,构建了国内业界较大的产业大模型。
目前来看,属于国内大模型厂商的第一梯队中的佼佼者。

腾讯产业化应用方向则主要是腾讯自身生态的降本增效,其中广告类应用表现出色。
阿里更重技术,例如M6大模型基于阿里云、达摩院打造的硬件优势,可将大模型所需算力压缩到极致;另外其底层技术优势还有利于构建AI的统一底层。
目前,主要应用方向是为下游任务提质增效,例如在淘宝服饰类搜索场景中实现了以文搜图的跨模态搜索。

华为的优势则在于其训练出业界首个2000亿参数以中文为核心的预训练生成语言模型。
目前发布了盘古气象大模型、盘古矿山大模型、盘古OCR大模型三项较为重磅的行业大模型。
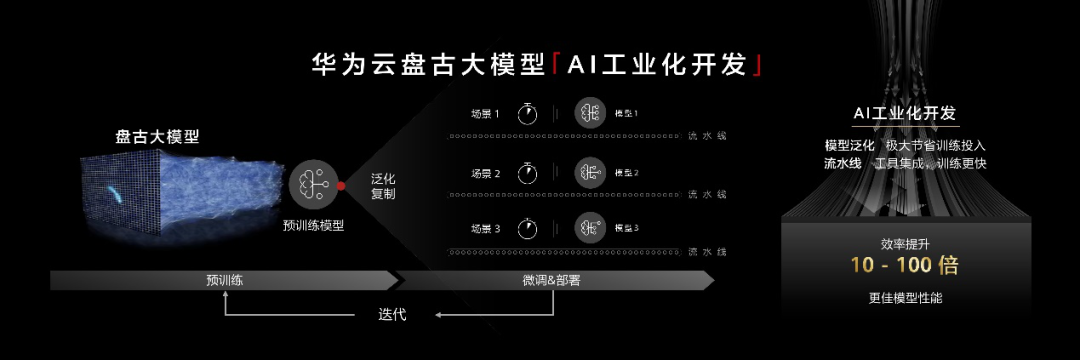
可以发现,在商业模式上各个厂商都是通用大模型路径,在通用大模型架构之上,搭建具体行业模型。
映射到产业层面,即“通用大模型+产业模型”的路径。
然而,手握入场券,并不代表能跑到终点。
对于厂商而言,其可以搭建通用大模型,并不意味着其能把通用大模型搭建的好;其有能力打通大模型到产业模型到具体场景的应用,并不意味着其可以打造出有真正价值的智能决策。AI大模型产业化落地的瓶颈需要被正视。
首先,国内大模型缺少数据训练场景。类似ChatGPT的训练场景尤为缺乏。
ChatGPT之所以短时间之内进步神速,因大量用户为其充当了免费的数据标注员。
不过,已目前情况来看,可与ChatGPT相较的数据训练场景在国内还鲜有见到。
其次,产业界对大模型有着浓烈的观望情绪。
业界普遍存在这样的忧虑:目前大模型应用不成熟,骤而上马将会对原有业务造成冲击。
以电商售后和银行电话客服场景为例,目前行业内仍采用主流智能客服公司推出的QA问答库技术。
客户企业希冀大模型产品能够解决QA库无法承担的长尾问题,覆盖到检索式问答路径无法涉足的领域,但金融行业的语料库等数据又不对外开放,让大模型企业不得不重头开始。
这都延迟了大模型进军具体行业的时间表。
总结而言,通用智能企业需要客单价高、数据训练场景丰富的派单需求,但这个问题又与企业的现实考量和预算投入相互矛盾。
没得数据用来训练、没有大钱养活产品,是摆在现实的两大难题。
一场属于巨头的游戏
如今,在大模型赛道中,挤满了巨头派、海归派、创业公司转型派、学院派等各路选手。
抢占大模型赛道头牌的战争已经彻底打响,但花落谁家还尚未可知。
目前,谷歌、微软、亚马逊、百度、阿里、腾讯等科技巨头公司在大模型发展方面具有显著的优势,均有相关雄厚的技术资源和能力,且都在通用大模型上进行了布局与投资。
总体而言,大模型的分水岭主要集中在技术研发、数据和算法资源、商业化能力、人才储备和管理能力四个方面。
首先,在技术研发能力方面。就目前来看,巨头拥有更强的技术研发能力和更丰富的资源,可以投入更多的人力、物力和财力来开展大模型的研究和开发。
他们拥有更完善的数据、算法和硬件等技术支持,能够更快速地推进大模型的研究和应用。
对比巨头和创业公司,技术上的差距在一定程度上取决于人工智能领域内的领先者和后来者。
巨头公司如Google、Facebook、Microsoft等在人工智能领域拥有大量的数据、计算资源和技术经验,因此有更多的能力来训练和优化大模型,推动人工智能技术的发展。
其次,在数据和算法资源方面,巨头拥有更丰富和更完善的数据和算法资源,能够更好地支持大模型的训练和推理。
他们能够利用自身的平台和业务优势来积累海量的数据,并在此基础上进行算法研发和优化。而创业公司通常无法获得这样的数据和算法资源,需要通过自己的努力来积累数据和优化算法,这需要更多的时间和精力。
以OpenAI发布于2020年的GPT-3来看,其具有1750亿个参数的大模型。
在算力方面,人工智能模型的训练和使用需要强大的算力,这就需要大量高性能的GPU来支撑。
在数据方面,据了解,ChatGPT的训练使用了大约45TB数据,其中包含多达近1万亿个单词的文本内容。
但是,由于大型模型需要大量的计算和存储资源,对于初创公司来说,资金和技术限制可能成为了限制因素。
另外,在商业化能力方面,巨头拥有更强的商业化能力和更完善的商业化渠道,能够更好地将大模型应用于商业领域,实现商业价值。
他们可以借助自身的品牌和用户基础,将大模型应用于搜索、推荐、广告等领域,并实现商业化变现。由于创业公司大多缺乏这样的商业化能力和渠道,需要花费更多的时间和精力来探索商业化路径和拓展商业合作。
最后,在人才储备和管理能力方面,巨头拥有更强的人才储备和更完善的管理能力,能够更好地吸引和管理高端人才,构建更具竞争力的团队。
他们可以通过自身的品牌和声誉,吸引到更多的高端人才,并通过自身的管理经验和制度建设,提升团队的协作效率和创新能力。而创业公司通常需要付出更多的努力来构建高端团队和提升管理能力。
虽然,随着技术的不断成熟,越来越多的创业公司也开始利用云计算、分布式计算等技术来加速大模型的训练和优化,不断挑战巨头公司的技术垄断。
创业公司在人工智能领域也有很多机会,但需要更多的创新和勇气来打破技术壁垒和市场垄断。
总之,大模型作为人工智能领域内的重要技术,已经成为了热门的创业领域。
巨头公司拥有更多的资源和技术经验,而创业公司面对这个“烧钱”的领域,不宜盲目跟风,可以通过创新和勇气来不断挑战技术垄断,找到适合自己的业务发展之路。
【关于科技云报道】
专注于原创的企业级内容行家——科技云报道。成立于2015年,是前沿企业级IT领域Top10媒体。获工信部权威认可,可信云、全球云计算大会官方指定传播媒体之一。深入原创报道云计算、大数据、人工智能、区块链等领域。

