
- 1IntelliJ IDEA创建一个spark的项目_idea创建javaspark项目
- 2人工智能的落地对行业针对性以及实际运用成本提出更高要求_人工智能成本高
- 3python爬虫去哪儿网上爬取旅游景点14万条,可以做大数据分析的数据基础_去哪儿网景点数据采集
- 4如何选择合适的北斗短报文模块_北斗短报文模组
- 5HarmonyOS Next,你真的足够了解它么?_harmonyos next 开发语言(2)_arkts与仓颉编程语言
- 6kubelet 命令行参数_--enable_load_reader=true
- 7讨论OOV(新词,也叫未登录词,词典之外的词语)问题的解决方案_oov问题
- 8react 低代码图编辑探索
- 9Harmony鸿蒙南向驱动开发-GPIO
- 10【车间调度】基于GA/PSO/SA/ACO/TS优化算法的车间调度比较(Matlab代码实现)_fjsp中 机器只能同时进行一道加工工序吗
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
赞
踩
前言
在人工智能的宏伟蓝图中,大语言模型(LLM)的预训练是构筑智慧之塔的基石。预训练过程通过调整庞大参数空间以吸纳数据中蕴含的知识,为模型赋予从语言理解到文本生成等多样化能力。本文将深入探讨预训练过程中的技术细节、所面临的挑战、通信机制、并行化策略以及如何通过这些技术的融合提升预训练的效率和性能。
一、预训练流程分析
预训练大语言模型涉及对海量参数的优化。这个过程起始于一个简单的前提:
给定输入(X)和相应的输出(Y),模型通过不断迭代学习,不断更新修改参数,使得其生成的输出尽可能接近真实结果(Y)。
当模型输出与实际结果之间的差距—通常由损失函数量化—减小到一个可接受的阈值时,我们可以认为预训练过程达到预期效果。在这个过程中,模型参数经历从随机初始化到精细调整的转变,逐步捕捉并内化语言的复杂规律。

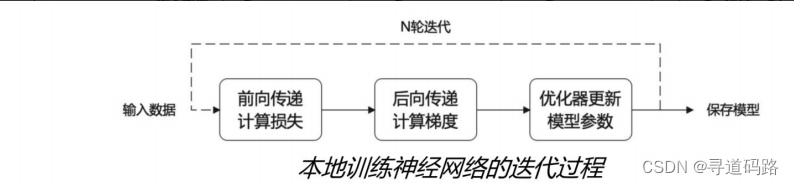
大语言模型预训练过程核心:
1)输入 Batch 数据
2)前向传播计算损失
3)后向传播计算梯度
4)优化器更新大模型参数
5)反复迭代循环
二、预训练两大挑战
随着模型规模向百亿甚至千亿参数迈进,预训练任务面临两大主要挑战:
1.显存效率:模型参数量的巨大使得即便是最先进的GPU也难以单独容纳所有参数,这直接导致了显存溢出的问题。例如,一个具有1750亿参数的GPT-3模型,其参数本身就需要消耗约700GB的显存,加上Adam优化器的状态,总共需要超过2.8TB的显存
2.计算效率:巨大的模型参数和海量的训练数据使得计算量激增,导致单机训练时间长达数年,这对于计算资源的有效利用提出了极大的挑战。
三、预训练网络通信
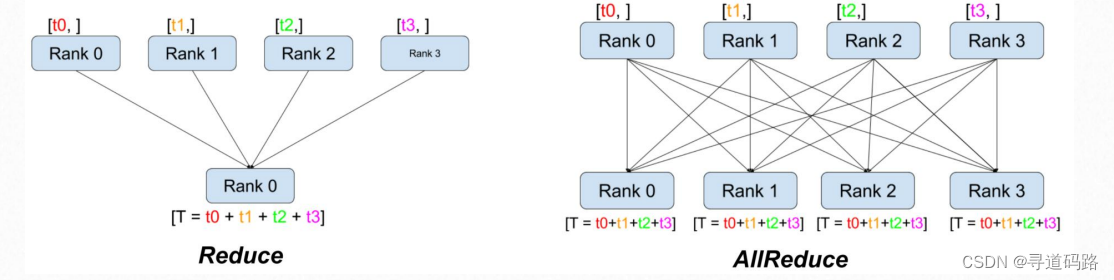
网络通信是多机多GPU预训练过程中不可或缺的环节。点对点通信方式因其一对一的数据交换模式,虽然成本较低,但传输速率较慢,成为速度瓶颈。相对而言,集体通信方式通过同时进行多个进程间的数据传输,大大提升了通信速度,但相应地增加了成本。选择合适的通信方式对于提高预训练效率至关重要。
1.点对点通信:一个进程发送数据,一个进程接收数据,速度慢,成本低。
2.集体通信:多个进程发送数据,多个进程接收数据,速度快,成本高。
四、预训练数据并行
1. 数据并行:数据并行是处理大规模数据集的常用策略,它通过将整个数据集分割成多个子集,每张GPU分配一部分数据独立进行模型训练。
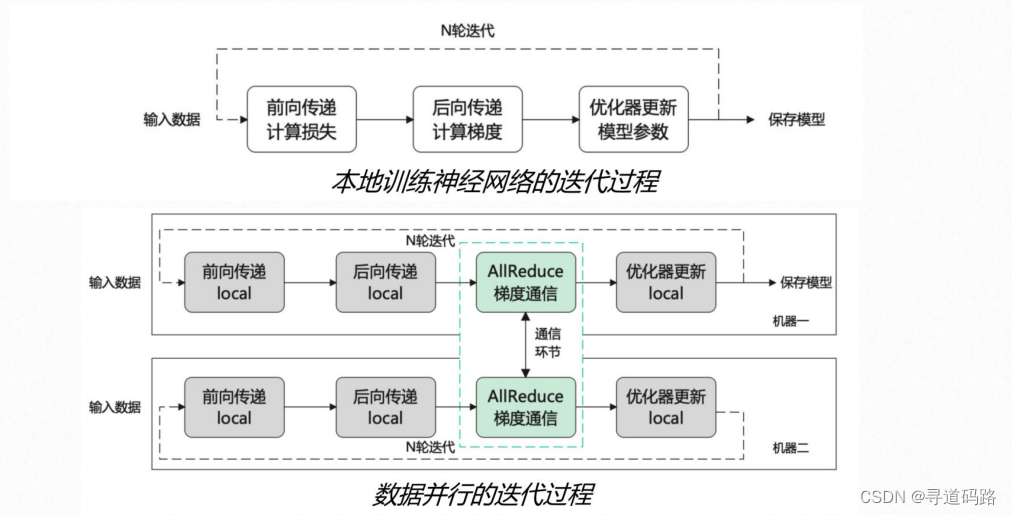
2. 数据并行三个提高效率的技巧
1)梯度分桶:动机是集体通信在大张量上比在小张量上效率更高。
2)计算与通信重叠:有了梯度分桶之后,在等待同一个桶内的梯度计算完后,就可以进行通信操作。
3)跳过梯度同步:梯度累加,减少梯度通信的频次。
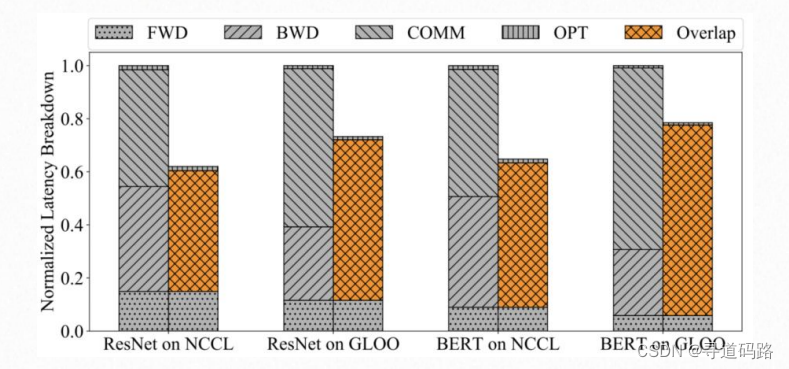
五、预训练模型并行
当单张GPU无法装载整个模型时,模型并行成为解决之道。
1.流水线并行
层间划分,将不同的层划分到不同的 GPU 上;比如:前 3 层在 0 号卡上,后 3 层在 1 号卡上
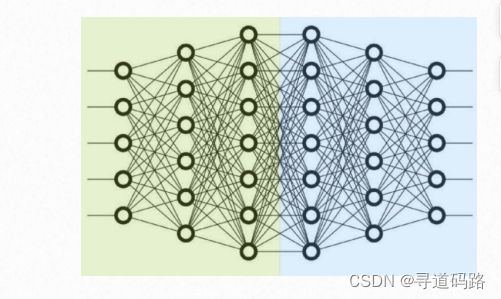
2.张量并行
层内划分,切分一个独立的层划分到不同的 GPU 上;比如:0 号卡和 1 号卡分别计算某个层的不同部分
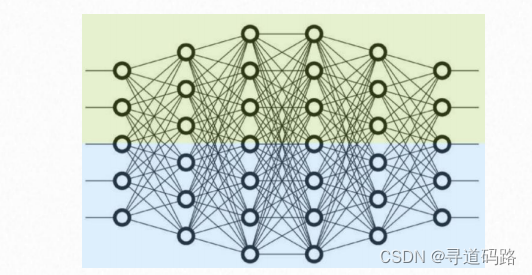
六、预训练3D并行
3D并行是一种综合性策略,它结合了数据并行、张量并行和流水线并行的优势,以平衡显存利用率和计算效率。在此框架下,每种并行方法承担着不同的角色:数据并行提供高效的计算利用率,张量并行减少单个层的显存占用,而流水线并行则降低跨层通信的频率。
1. 数据并行:计算效率高、实现简单。
• 显存效率:每张卡上都保存了完整的模型、梯度、优化器状态,因此显存效率不高。
• 计算效率:当增加并行度时,单卡的计算量是保持恒定的,可以实现近乎完美的线性扩展。但规约梯度的通信开销,与模型大小成正相关。
2. 张量并行:因模型结构而异,实现难度大。
• 显存效率:随着并行度增加,成比例地减少显存占用。是减少单层神经网络中间激活的唯一方法。
• 计算效率:频繁的通信,限制了两个通信阶段之间的计算量,影响了计算效率,计算效率很低。
3. 流水线并行:通信成本最低
• 显存效率:减少的显存与流水线并行度成正比。但流水线并行不会减少每层中间激活的显存占用。
• 计算效率:成本更低的点对点(P2P)通信。通信量与流水线各个阶段边界的激活值大小成正比。
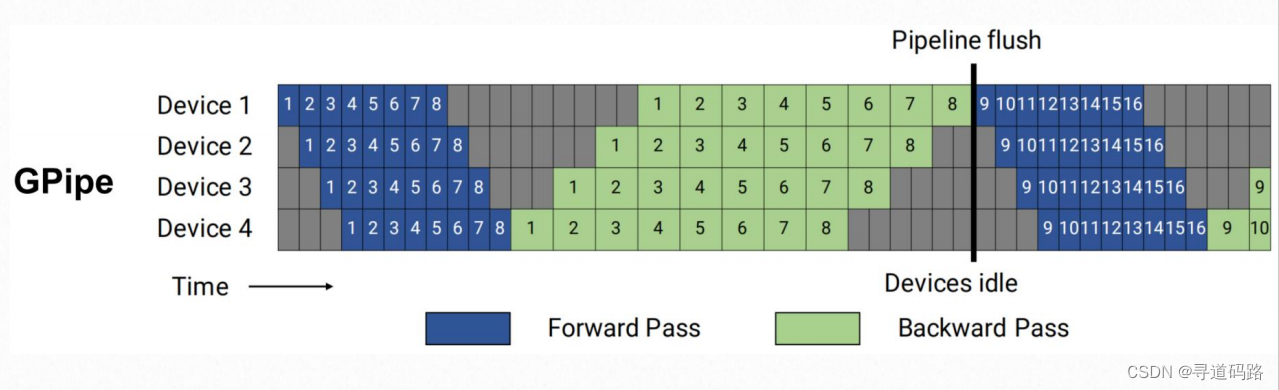
4. 3D并行实例
Bloom-176B模型的预训练实施了这种3D并行策略,在NVIDIA A100 GPU上实现了对数万亿Token的训练工作。
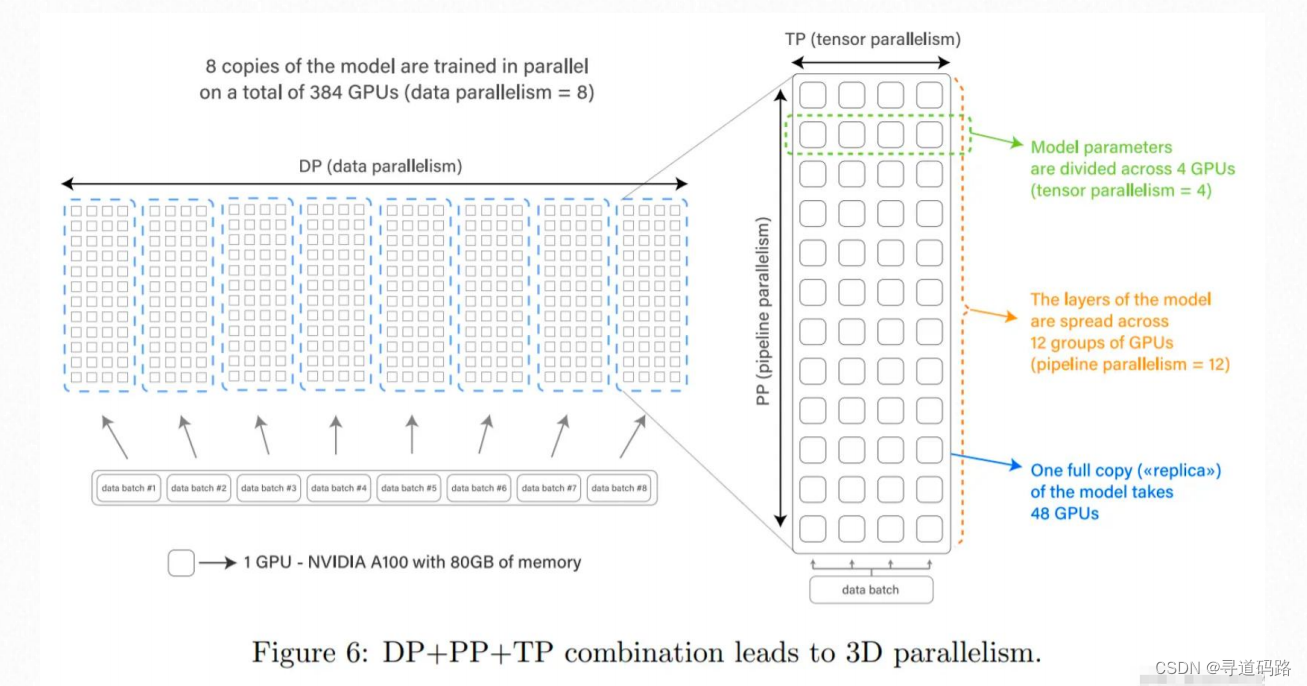
5. 3D 并行训练框架
同时支持数据并行 、流水线并行、张量并行的3D并行训练框架:Microsoft DeepSpeed 和NVIDIA Megatron
1)Microsoft DeepSpeed:微软开发的优化库,专门用于简化和提高深度学习分布式训练的效率。它通过结合数据并行和其他并行技术,如流水线并行,实现了一种基于3D并行的训练方法。
2)NVIDIA Megatron:由NVIDIA的研究团队开发的一个专为大型Transformer模型设计的训练框架。
七、预训练代码示例
预训练代码简单示例:
import torch from transformers import AutoTokenizer, AutoModelForMaskedLM # 加载预训练模型和分词器 model_name = "bert-base-uncased" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForMaskedLM.from_pretrained(model_name) # 准备输入数据 input_text = "This is an example sentence." inputs = tokenizer(input_text, return_tensors="pt") # 进行前向传播 outputs = model(**inputs) # 提取预测结果 predictions = outputs.logits # 输出预测结果 print(predictions)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
总结
预训练大语言模型是一项既富有挑战又极具价值的工作。随着模型规模的不断扩大和数据量的激增,如何高效地进行预训练已经成为了AI研究的核心议题。3D并行作为一种先进的预训练框架,不仅解决了单一GPU资源限制的问题,还通过合理的资源分配和优化手段显著提高了预训练的性能。未来的预训练技术将继续沿着这条道路前进,不断探索新的边界,并将机器学习模型推向前所未有的高度。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

