
- 1智能加速:AI光模块助力数据中心迈向400G/800G超高速率的新境界
- 2Android Studio学习笔记(二)_android studio笔记(二)
- 3如何安装llvm的比较新的版本_lib库llvmjit.so 升级
- 4中文词向量:使用pytorch实现CBOW_怎样查看torch里有没有cbow
- 5通过 docker-compose 快速部署 DolphinScheduler 保姆级教程_dolphinscheduler docker
- 6java final 修饰变量_Java笔记:final修饰符
- 7Facebook广告投放技巧及思路、如何最大化发挥广告效益!_fb广告先投awareness获得数据再跟帖投转化
- 8安全计算环境(设备和技术注解)_当远程管理云计算平台中设备时,管理终端和云计算平台之间应建立双向身份验证机制
- 951单片机课程设计——基于单片机的AD模数转换设计_51单片机ad是什么
- 10飞桨自然语言处理框架 paddlenlp的 trainer_paddlenlp.trainer中train
LeetCode(力扣)初级算法 字符串篇_力扣 字符串
赞
踩
目录
字符串就是特殊的字符数组,字符数组末尾的元素为 '\0'。和数组一样可以使用arr[i]或*(arr+i)来访问元素。
无论是用数组保存字符串(如:char arr[] = "Hello,World";),还是用指针保存字符串(如:char *brr = "Hello,World";),我们都可以使用字符串函数strlen(),来计算字符串长度。因为这里数组名和指针名保存着字符串在内存中的首地址,并且这里是字符串(存储时末尾有一个隐藏的'\0'),以 '\0' 结尾。这样,对于字符数组:使用sizeof(arr)/sizeof(arr[0]),求出来的长度比strlen求出的长度大1,因为sizeof计算数组大小时包含了'\0',strlen计算时忽略了'\0';对于字符串指针:sizeof(brr)/sizeof(brr[0])计算结果为4,因为brr是指针名,sizeof(brr)计算的是指针的大小为4,再除以元素大小1,所以结果为4。
所以,对于字符串,我们直接使用strlen()来计算其长度。
1.反转字符串
题目要求:
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
作者:力扣 (LeetCode)
链接:https://leetcode.cn/leetbook/read/top-interview-questions-easy/xnhbqj/
来源:力扣(LeetCode)
思路分析:
反转字符串,就是将这个字符串逆序排列,也就是以除了'\0'的字符串中心为对称轴,将对称位置的元素进行交换。这就是此题的核心思路。一般,我们也可以使用另一个O(n+1)大小的字符数组来反着存放字符串来达到目的,但是这就不是出题人想考你的目的了。
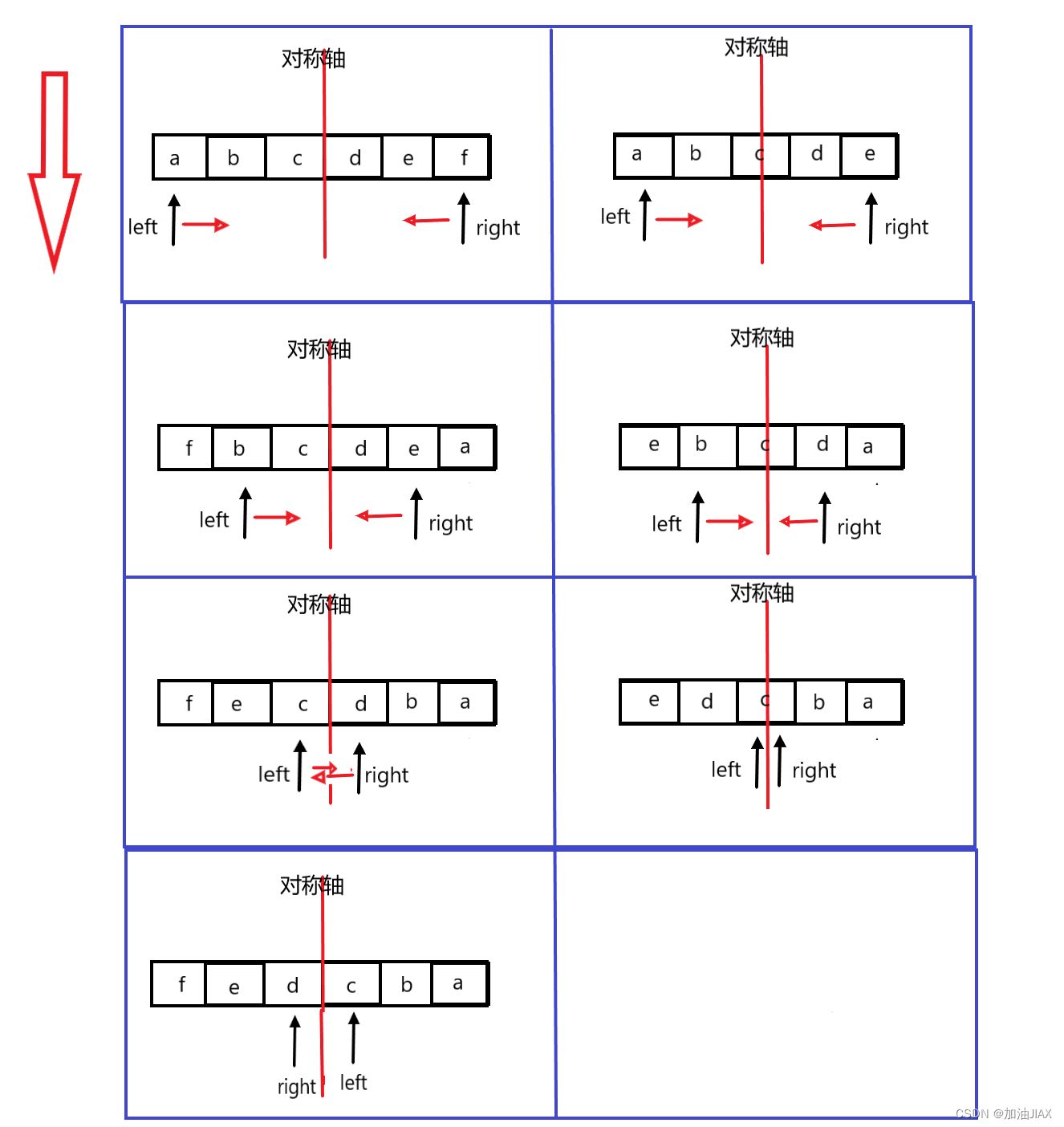
根据核心思路,left从下标0开始,right从下标sSize-1开始借用一字节额外空间,互换元素,然后left向右移动,right同时向左移动,循环往复,直到left遇到right,或者left到达right右边。
- void reverseString(char* s, int sSize){
- char tmp=0;
- for(int left=0,right=sSize-1;left<right;left++,right--){
- tmp=s[left];
- s[left]=s[right];
- s[right]=tmp;
- }
- }
也可以这样写:
- void reverseString(char* s, int sSize){
- char tmp=0;
- for(int i=0;i<sSize;i++,sSize--){
- tmp=s[i];
- s[i]=s[sSize-1];
- s[sSize-1]=tmp;
- }
- }
2.整数反转
题目要求:
给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。
如果反转后整数超过 32 位的有符号整数的范围 [−2^31, 2^31 − 1] ,就返回 0。
假设环境不允许存储 64 位整数(有符号或无符号)。
作者:力扣 (LeetCode)
链接:https://leetcode.cn/leetbook/read/top-interview-questions-easy/xnx13t/
来源:力扣(LeetCode)
思路分析:
这个题本来看题与第一题差不多,只不过要考虑反转后数据超出范围的问题。但是这里传入的参数是一个int型数字,所以我们用数学方法来解决问题。
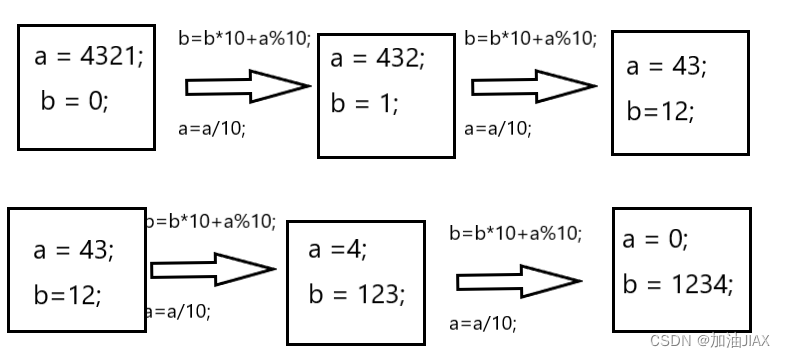
如int a = 4321,对10取余,可以获取其个位1;a = a/10,a==432,432对10取余,可以获取其个位2;循环往复,直到a==0,我们可以从个位到最高位的顺序的到a的全部位数上的数字。再定义一个变量b = 0,在从个位到最高位的顺序的到a的位数上的数字时,使b = b*10 + a%10,这样就将a反转了过来。
对于负数,我们先记录它是负数,然后转换成正数进行处理,最后在转换为负数。
但是如果反转过来的数字超出2^31的范围时,我们需要返回0。所以我们需要知道什么时候数字超出了范围。找所周知,int型的最大值为2^31 - 1,所以当数据大于2^31 - 1时,数据发生进位,超出了int四字节 - 1位大小的内存(最高位是符号位),所以产生数据截断,数据就会和目标数据不一样。所以如果我们nb = b*10 + a%10,然后看(nb-a%10)/10 是否等于b 就可以知道数据是否超出范围。
2.1第一版代码
- int reverse(int x) {
- int flag = 1;//记录正负
- //一个记录原来数据,一个记录计算后的数据
- int re = 0, newre = 0;
- int a = 0;//记录x%10
- if (x < 0) {
- flag = -1;
- x = -x;//负数转为正数
- }
- while (x > 0) {
- a = x % 10;
- newre = re * 10 + a;//这里在vs上正确,但leetcode未通过
- //判断是否超出范围
- if ((newre - a) / 10 != re) return 0;
- re = newre;
- x = x / 10;
- }
-
- return flag * re;
- }

因为计算机无法判断数据截断是因为不正常操作产生的,还是我们人为想要的,所以我们自己标识出来是我们想要的newre=(int)(re*10)+a,但是leetcode还是认为是错误的。
我们再改改思路,将newre定义为long long型,可以放下超过2^31-1的数据。unsigned int f = -1,f是无符号的整型,f = -1 可以看作f = 1 0000 0000 0000 0000 0000 0000 0000 0000 - 1,f 就是四字节二进制位上全是1:f = 1111 1111 1111 1111 1111 1111 1111 1111。f = f >>1,f进行位运算右移一位变成:f = 0111 1111 1111 1111 1111 1111 1111 1111。此时f就是int型数据的最大值2147483647。所以我们可以用比较newre是否大于f,来判断反转后的数据是否超出范围。就哦了。
int(f+1)就是负数的最小值:(int)(f + 1)== 1000 0000 0000 0000 0000 0000 0000 0000 == -2147483648。
较小类型数据转化成较大类型数据可以隐式提升,较大类型数据转化成较小类型数据需要强制转换。
2.2第二版代码
- int reverse1(int x) {
- int flag = 1;
- int re = 0;
- int a = 0;
- unsigned int f = -1;
- f = f >> 1;
- long long newre = 0;
-
- if (x == (int)(f + 1))//对负数最小值特殊处理
- return 0;
- if (x < 0) {
- flag = -1;
- //因为要转换成正数,
- //负数最小值的绝对值比正数最大值大1.
- //在这里会超范围
- x = -x;
- }
- while (x > 0) {
- a = x % 10;
- //re为int型,可能超范围就截断了
- //所以要先转换成long long型
- newre = (long long)re * 10 + a;
- //newre为long long型,f为unsigned int型
- //f会隐式提升为long long型
- if (newre > f) return 0;
- //newre强转为int型
- re = (int)newre;
- x = x / 10;
- }
- return flag * re;
- }
3.字符串中的第一个唯一字符
题目要求:
给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。
思路分析:
首先,我们可以用两个for循环从左到右对一个元素,去判断字符串中是否还有这个元素,找到的第一个满足条件的元素就是题目所求。
3.1第一版代码
- int firstUniqChar(const char* s) {
- int len = strlen(s); int count = 0;
- for (int i = 0; i < len; i++) {
- //记录判断了多少个元素
- count = 0;
- for (int j = 0; j < len; j++) {
- //每次都从头开始
- if (i == j) //碰到自己就跳过
- continue;
- if (s[i] == s[j]){
- //找到相同的就判断下一个i元素
- break;
- }
- count++;
- }
- //如果count==len-1,
- //就意味着在没有找到和他相同的元素
- if (count == len - 1) return i;
- }
- return -1;
- }
其次,我们可以开辟一个数组,遍历字符串,将所有字符按在字符串中的顺序存入数组,碰见相同的元素,该元素数量加一;如果该元素还未存入,就将该元素存入,并保存其下标。然后按数组下标顺序找,看哪个字符的数量是1,这就是那个第一个唯一字符。
这里采用的结构体型变量保存字符信息,并且使用动态内存开辟,开辟连续的一段长度可以存放所有字符的空间,达到数组的目的。(不清楚、有兴趣的朋友可以查看C语言结构体、动态内存开辟、C语言项目自助取款机实现)
3.2第二版代码
- typedef struct HH {
- char a;//保存字符
- int num;//保存字符数量
- int index;//保存字符下标
- }H;
- typedef struct MM {
- H* arr;//结构体型指针,等下动态内存开辟空间
- //保存结构体变量,相当于字符数组
- //一个结构体变量保存一个字符,还有字符的数量
- //还有字符第一次出现的下标。
- int size;//已存入字符数组的元素种类个数
- }M;
-
- int firstUniqChar1(const char* s) {
- M m;
- int len = strlen(s);
- //以字符串长度为结构体指针开辟空间
- m.arr = (H*)malloc(sizeof(H) * len);
- assert(m.arr != NULL);
- m.size = 0;//初始化数量为0
-
- for (int i = 0; i < len; i++) {
- int flag = 0;
- for (int j = 0; j < m.size; j++) {
- //遍历数组,看是否有该字符
- if (s[i] == m.arr[j].a) {
- m.arr[j].num++;
- 如果有就标记 有
- flag = 1;
- break;
- }
- }
- //如果没有,就将这个字符存入
- if (flag == 0) {
- m.arr[m.size].a = (char)s[i];
- m.arr[m.size].index = i;
- m.arr[m.size].num = 1;
- m.size++;
- }
- }
- for (int i = 0; i < m.size; i++) {
- if (m.arr[i].num == 1) {
- //找到第一个唯一字符,返回其下标
- return m.arr[i].index;
- }
- }
- free(m.arr);
- m.arr = NULL;
- return -1;
- }
对第二版思想的优化,自制(哈希表)nums[]字符数量数组长度为26(在字符串所有元素全是小写字符的前提下)(长度可跟情况而定),同时创建相同长度的下标数组index[],用来保存该元素下标(如果该元素只出现一次,那这就是该元素第一次出现的下标)。直接以字符数组的下标对应'a'~'z',数组该下标位置直接存放字母出现的数量。最后an字符串中字符出现的顺序进行遍历,第一个数量为1的字母,就是第一个唯一字母。
3.3第三版代码
- int firstUniqChar2(const char* s) {
- int nums[26] = { 0 };
- int index[26] = { 0 };
- int len = strlen(s);
- for (int i = 0; i < len; i++) {
- nums[s[i] - 'a']++;
- index[s[i] - 'a'] = i;
- }
- for(int i = 0; i < len; i++) {
- if (nums[s[i]-'a'] == 1) {
- return index[s[i] - 'a'];
- }
- }
- return -1;
- }
4.有效的字母异位词
题目要求:
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。
作者:力扣 (LeetCode)
链接:https://leetcode.cn/leetbook/read/top-interview-questions-easy/xn96us/
来源:力扣(LeetCode)
思路分析:
这个题目要求就是比对两个字符串中所有字符的数量是否相同,所以需要计算每一个字符的数量。这就与3.字符串中唯一一个字符十分相似。我们可以开辟两个结构体数组,来保存每个字符,与其个数。最后进行比较。
4.1第一版代码
- typedef struct Arr {
- char a;
- int num;
- }arr;
- typedef struct Has {
- arr* ar;
- int size;
- }has;
-
- bool isAnagram(const char* s,const char* t) {
- has h1; has h2;
- int ls = strlen(s);
- int lt = strlen(t);
- int size = ls < lt ? ls : lt;
- //全是小写字母,一共26个
- h1.ar = (arr*)calloc(26,sizeof(arr) * 26);
- h2.ar = (arr*)calloc(26,sizeof(arr) * 26);
- assert(h1.ar != NULL && h2.ar != NULL);
-
- for (int i = 0; i < ls; i++) {
- //全是小写字符,所以直接保存在其对应
- //26字母顺序的位置
- h1.ar[s[i]%97].a = s[i];
- h1.ar[s[i]%97].num++;
- }
- for (int i = 0; i < lt; i++) {
- //t[i]%97相当于t[i]-'a'.
- h2.ar[t[i]%97].a = t[i];
- h2.ar[t[i]%97].num++;
- }
- for (int i = 0; i < 26; i++) {
- if (h1.ar[i].num != h2.ar[i].num) {
- free(h1.ar);
- free(h2.ar);
- return false;
- }
- }
- free(h1.ar);
- free(h2.ar);
- return 1;
- }
并且,本题字符串中所有字符全是小写英文字母,完美契合了3.3第三版代码的思想。所以按照3.3的方法。过了!
4.2第二版代码
- bool isAnagram1(const char* s, const char* t) {
- int lens = strlen(s);
- int lent = strlen(t);
- //字符串长度不同,其字符个数肯定不相同
- if (lens != lent) return 0;
-
- int numsS[26] = { 0 };
- int numsT[26] = { 0 };
-
- for (int i = 0; i < lens; i++) {
- numsS[s[i] - 'a']++;
- }
- for (int i = 0; i < lent; i++) {
- numsT[t[i] - 'a']++;
- }
- for (int i = 0; i < 26; i++) {
- if (numsS[i] != numsT[i])
- return 0;
- }
- return 1;
- }
5.验证回文串
题目要求:
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个回文串。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是回文串,返回 true ;否则,返回 false 。
作者:力扣 (LeetCode)
链接:https://leetcode.cn/leetbook/read/top-interview-questions-easy/xne8id/
来源:力扣(LeetCode)
思路分析:
在本题中,除了其他字符,所有数字字符与字母字符(不区分大小写)不仅数量要相同,在字符串前后的顺序位置还要对称。这里就要比较字符串前后对称位置的数字字符和字母字符,所以双指针的思想,分左指针和右指针,左指针从左往右走、右指针从右往左,跳过非数字、字母字符,然后将大写字母转成小写,进行比较。循环进行,直到两指针相遇,或者比较的对称位置的字符不相同。
- bool isPalindrome(const char* s) {
- int len = strlen(s);
- char a = 0, b = 0; bool flag = 0, flag2 = 0;
-
- for (int i = 0, j = len - 1; i <= j;) {
- while (i <= j &&(s[i]<'0'||(s[i]>'9'&&s[i] < 'A' )|| (s[i]>'Z' && s[i] < 'a') || s[i]>'z')) i++;
- while (j >= i &&(s[j] <'0'||(s[j] > '9' && s[j] < 'A') || (s[j] > 'Z' && s[j] < 'a') || s[j]>'z')) j--;
- if(i<=j){
- a = s[i] >= 'a' ? s[i] - 'a' + 'A' : s[i];
- b = s[j] >= 'a' ? s[j] - 'a' + 'A' : s[j];
- if (a != b) return 0;
- }
-
- i++,j--;
- }
- return 1;
- }
6.字符串转换整数 (atoi)
题目要求:
请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C++ 中的 atoi 函数)。
函数 myAtoi(string s) 的算法如下:
1.读入字符串并丢弃无用的前导空格
2.检查下一个字符(假设还未到字符末尾)为正还是负号,读取该字符(如果有)。 确定最终结果是负数还是正数。 如果两者都不存在,则假定结果为正。
3.读入下一个字符,直到到达下一个非数字字符或到达输入的结尾。字符串的其余部分将被忽略。
4.将前面步骤读入的这些数字转换为整数(即,"123" -> 123, "0032" -> 32)。如果没有读入数字,则整数为 0 。必要时更改符号(从步骤 2 开始)。
5.如果整数数超过 32 位有符号整数范围 [−231, 231 − 1] ,需要截断这个整数,使其保持在这个范围内。具体来说,小于 −231 的整数应该被固定为 −231 ,大于 231 − 1 的整数应该被固定为 231 − 1 。
6.返回整数作为最终结果。
注意:
1.本题中的空白字符只包括空格字符 ' ' 。
2.除前导空格或数字后的其余字符串外,请勿忽略 任何其他字符。
作者:力扣 (LeetCode)
链接:https://leetcode.cn/leetbook/read/top-interview-questions-easy/xnoilh/
来源:力扣(LeetCode)
思路分析:
这就是C语言和C++的字符串转整型函数,如果写过的朋友就很容易理解了,可能只在比较数据是否超出范围的地方有点问题。
本题题意就是,如果有一个字符串如" -12.3"或" +12a3":
1、跳过前面的空格。
2、记录其正负。
3、将字符型数字转化成整型数字。
4、在遇到除数字字符的其他字符时停止。
这两个字符串的运行结果就是-12和12。如果在遇见数字前,遇见了除数字字符或’+‘和’-‘外的其他字符,就返回0。如" a123"、" .123"的结果就是0。有多个正负号也算错误,返回0。如" +-123"。
如果转化出来的数字超出范围,正数就返回正数最大值,负数就返回负数最小值。 在这里比较是否超出范围还是采用2.2中unsigned int -1的方法。
- int myAtoi(char * s){
- if(strlen(s)==0) return 0;
- int flag = 1;//记录正负
- int flag2 = 0;//负数最小值需要减一
- long long num = 0;//记录转化出来的数值
- int result=0;//最终结果
- unsigned int a=-1;a=a>>1;//int型的最大值
- //跳过空格
- while (*s == ' ') { s++; }
- //记录正负,只记录一个;
- //如果有多个,下方while进不去
- if (*s == '+' || *s == '-') {
- if (*s == '-')flag = -1;
- s++;
- }
- //转化数字,最多使num比正数最大值大1倍,避免无用功
- //a<<1,相当于a*2
- while (*s >= '0' && *s <= '9'&&num<(a<<1)) {
- num = num * 10 + *s - '0';
- s++;
- }
- //如果超范围就进行赋值
- if(num>a){
- result=(int)a;
- //负数最小值的绝对值比正数最大值大1
- if(flag==-1) flag2=-1;
- }
- //没超范围,进行正常强转赋值
- else result=(int)num;
- //有在负数极限时,需要-1
- return flag * result+ flag2;
- }
7.实现 strStr() 函数。
题目要求:
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串出现的第一个位置(下标从 0 开始)。如果不存在,则返回 -1 。
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java 的 indexOf() 定义相符。
作者:力扣 (LeetCode)
链接:https://leetcode.cn/leetbook/read/top-interview-questions-easy/xnr003/
来源:力扣(LeetCode)
思路分析:
本题就是要找在第一个字符串中是否存在第二个字符串(字符串匹配),如字符串s中是否存在字符串t。所以我们要先在s中找到字符串 t 的第一个字符,记录出现的位置如index,再比较后续字符是否相同。如果后续 strlen(t)-1长度的两个字符串字符都相同,则返回index;如果有不同,就在s上从index位置往后继续找 t 的第一个字符,重复上述操作。直到找字符串t,或者找完整个字符串s都没找到字符串t。
7.1第一版代码
- int strStr1(char* haystack, char* needle) {//一个一个比较,不够快//回溯
- if (needle == NULL) return 0;
- int lenh = strlen(haystack);
- int lenn = strlen(needle);
- int index = 0;
- int i = 0,j = 0;
-
- while(i < lenh&&j < lenn) {
- if (haystack[i] == needle[0]) {
- j = 0; //将j重置为0
- index = i;//记录当前i的位置
- while (i < lenh && j < lenn) {
- //比较是否相同,不同就退出
- if (haystack[i] != needle[j]) {
- break;
- }
- i++; j++;
- }
- //如果j==lenn就意味着字符串n在字符串h中
- if (j == lenn) return index;
- //否则回到i原来位置继续往后找
- else i = index ;
- }
- i++;
- }
- return -1;
- }
上面用了两个循环,也可以用一个循环。
7.2第二版代码
- int strStr1(char* haystack, char* needle) {
- if (needle == NULL) return 0;
- int lenh = strlen(haystack);
- int lenn = strlen(needle);
- int index = 0;//标记0下标
- int i = 0,j = 0;
-
- while(i < lenh&&j < lenn) {
- if (haystack[i] != needle[j]) {
- //在不相同时,j重置为0
- j = 0;
- //i回到index之后
- i=index+1;
- //标记点往后挪
- index++;
- }
- else {//相同
- //如果j==0,
- //这就是字符串n的第一个字符的出现位置
- if(j==0) index = i;//标记i
- i++; j++;
- //j后+1,如果j==lenn意味着
- //比较完所有字符串n的字符都与字符串h相同,
- //也就是字符串n在h中
- if (j == lenn) return index;
- }
- }
- return -1;
- }
在在字符串h中找到字符串n的首字符后,继续比较后续字符是否相同时,我们可以记录下来后面是否还有字符串n的首字符出现,记录其在字符串h中的下标位置,设为index2;如果这次没有匹配上字符串n,那就直接让i返回到index2的位置。这样就省下了再从 i 原来位置往后找到index2位置的一部分时间。这就是对上方算法的优化。
我们需要记录的是在字符串h中,除了j = 0位置外,最左边的那一个(字符串n的首字符)。
- int strStr2(char* haystack, char* needle) {
- if (needle == NULL) return 0;
- int lenh = strlen(haystack);
- int lenn = strlen(needle);
- int index = 0, index2 = -1;
- bool count = 0;//标记是否是第一个n的首字符
- int i = 0, j = 0;
-
- while (i < lenh && j < lenn) {
- if (haystack[i] == needle[0]) {
- //找到n第一个元素
- index = i;//记录位置
- j = 1; i++;//i,j直接往后走一位
- count = 0;//重置标记
- while (i < lenh && j < lenn) {
- if (haystack[i] != needle[j]) {
- i--;
- break;
- }
- //记录第一个字符
- if (haystack[i] == needle[0]&&count==0) {
- index2 = i;
- count= 1;//标记后面的不是第一个了
- }
- i++; j++;
- }
- //如果相等,就是匹配上了,返回index
- if (j == lenn) return index;
- else{
- //如果index!=-1,就是n的首字符还出现过
- if (index2 != -1) {//并被记录下了
- //i返回到这个位置之前,退出本循环,i还要+1
- i = index2 - 1;
- index2 = -1;//重置记录
- }
- }
- }
- i++;
- }
- return -1;
- }
8.外观字符串
题目要求:
给定一个正整数 n ,输出外观数列的第 n 项。
「外观数列」是一个整数序列,从数字 1 开始,序列中的每一项都是对前一项的描述。
你可以将其视作是由递归公式定义的数字字符串序列:
countAndSay(1) = "1"
countAndSay(n) 是对 countAndSay(n-1) 的描述,然后转换成另一个数字字符串。
提示:
1 <= n <= 30
作者:力扣 (LeetCode)
链接:https://leetcode.cn/leetbook/read/top-interview-questions-easy/xnpvdm/
来源:力扣(LeetCode)
题目解释:
输入:n = 4
输出:"1211"
解释:
countAndSay(1) = "1"
countAndSay(2) = 读 "1" = 一 个 1 = "11"
countAndSay(3) = 读 "11" = 二 个 1 = "21"
countAndSay(4) = 读 "21" = 一 个 2 + 一 个 1 = "12" + "11" = "1211"
我们可以把这个题看做是每一级都是对上一级中字符按顺序的记录,起始在n为1时,字符串arr为"1",比如:
n=2时,对arr进行字符记录为1个1,所以,此时arr变为"11";
n=3时,对arr进行字符记录为2个1,所以,此时arr变为"21";
n=4时,对arr进行字符记录为1个2,加上一个1,所以,此时arr变为"1211";
如果n=5时,对arr进行字符记录就是为1个1,1个2,2个1,所以,此时arr变为"111221";
n=6时,对arr进行字符记录为3个1,2个2,1个1,所以,此时arr变为"312211";
以n为停止条件进行递归,或者循环。
思路分析:
在这里记录字符数量时,只记录连续的相同字符的数量。所以就是双指针(快慢指针)的方法。left,right同时从字符串头部出发,left指向一个元素,right向右边找到和left指向元素不同的元素时停下,此时right与left的差值就是left指向元素的连续重复个数,将其记录下来,再记录下left指向元素;然后让left走到right的位置;循环此操作,直到left越界。这样就已题目要求的方式,记录下了这个字符串。
注意,在记录时要用另一个字符数组brr(初始化里面全部为'\0')来记录,否则会覆盖原字符串的字符。记录结束使用strcpy()函数将字符数组的字符拷贝给原字符串。
以循环形式循环上述操作n-1次即可达到目的。
可以以另一个函数进行递归求解,但是循环更好理解。
- char* countAndSay(int n) {
- //因为要将最终字符串返回出去,所以我选择使用动态内存
- //以calloc开辟时同时进行初始化为默认值'\0'
- char* a = (char*)calloc(5000,sizeof(char) * 5000);
- if (a == NULL) exit(1);
- a[0] = '1';//初始化'1'
- //创建b数组,全部元素初始化为'\0'
- char b[5000] = { 0 };//局部变量部分初始化
-
- for (int i = 0; i <n-1; i++) {
- //每次重新计算a的长度
- int len = strlen(a);
- for (int left = 0, right = 0, indexb = 0; left < len;) {
- //字符相同时,right往后走
- if (right < len&&a[left] == a[right]) right++;
- else {
- //indexb为数组b的元素下标
- b[indexb++] = right - left + '0';
- b[indexb++] = a[left];
- left = right;
- }
- }
- strcpy(a, b);
- }
- return a;
- }
9.最长公共前缀
题目要求:
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
提示:
1. 1 <= strs.length <= 200
2. 0 <= strs[i].length <= 200
3. strs[i] 仅由小写英文字母组成
作者:力扣 (LeetCode)
链接:https://leetcode.cn/leetbook/read/top-interview-questions-easy/xnmav1/
来源:力扣(LeetCode)
思路分析:
公共前缀,就是每个字符串都共有的前缀(部分字符串)。所以就要比较从一个字符串开头开始往后的字符是否在其他所有字符串的开头都有。如果每个字符串都有,就将其保存进公共前缀数组,向后继续判断;只要一个字符串开头没有该字符,那这个字符就不属于公共前缀,并且包括这个字符之后的所有字符都不会属于公共前缀。已存入公共前缀数组的字符组成的就是最长公共前缀;如果公共前缀中一个字符有没有,那么这些字符串就没有公共前缀。
最长公共前缀的长度不会超过所有字符串中最短的字符串的长度。
- char* longestCommonPrefix(char** strs, int strsSize) {
- int min = 200;//用来存储最短字符串的长度。
- //如果有任何一个字符串为空,
- //这些字符串的公共前缀也是空
- for (int i = 0; i < strsSize; i++) {
- if (strs[i] == NULL) {//判断是否为空
- char* q = NULL;
- return q;//返回一个空指针
- }//同时找到最短字符串长度
- int len = strlen(strs[i]);
- min = len < min ? len : min;
- }
- //根据最短字符串长度开辟空间,存储最长公共前缀
- //注意结尾要有'\0',所以min+1,
- //以calloc开辟同时所有空间初始化为'\0'
- char* Pre = (char*)calloc(min+1, sizeof(char) * (min + 1));
- if (Pre == NULL) exit(1);
-
- for (int i = 0; i < min; i++) {
- int j = 0; bool flag = 1;
- for (; j < strsSize; j++) {
- if (strs[j][i] != strs[0][i]) {
- flag = 0;//标记该字符不属于公共前缀
- break;
- }
- }
- if (flag) Pre[i] = strs[0][i];
- else break;
- }
- return Pre;
- }
10.总结
字符串与数组大体相同,只不过会多出一个隐藏的'\0'。并且用指针存储字符串的话,与数组不同,系统会去查找,看这个字符串是否已经被存入内存的数据区(字符串是常量),如果已经存入的话,就将这个字符串的地址返回给指针;如果没存入,就将该字符串存入,然后将地址返回给指针。这就是使用指针存储字符串的原理。
同样多写,多想,多看别人题解。
可能一次发五个左右比较合适。十个太多,自己写的篇幅太长,也可能还没讲清楚,没多少人看,没啥动力,太费时间了。开学了就写得少了,会写写一些笔试、面试可能会会碰到的简单技巧题。

