
Vitis初探—1.将设计从SDSoC/Vivado HLS迁移到Vitis上_vitis是把vivado整合到一起了吗
赞
踩
〇、前言
2020.11.25日,Xilinx更新了Vitis2020.2版本。正好之前报名里Xilinx的自适应计算挑战赛,比赛要求使用Vitis平台进行开发,所以今天趁着新版本发布把我之前参加DAC-SDC的项目SkrSkr迁移到Vitis平台上。之前听过一些介绍说Vitis将SDAccel和SDSoC合并到了一起,并使用OpenCL语言,所以在项目迁移之前我还是有点打怵的,但是经过一天的尝试基本搞定了。整个流程走下来感觉Vitis跟SDSoC换汤不换药,只是调用加速器的方式稍有变化,整体的设计思想还是一致的。下面就进入正题,如何一步一步将设计从SDSoC/Vivado HLS迁移到Vitis平台。
一、环境准备
1.安装Vitis,此处省略
2. 安装zcu104的platform
- 下载zcu104的base platform
从https://www.xilinx.com/support/download/index.html/content/xilinx/en/downloadNav/embedded-platforms.html下载ZCU104 Base 2020.2以及ZYNQMP common image - 将ZCU104 Base 2020.2解压到
/tools/Xilinx/Vitis/2020.2/platforms/(Vitis的默认安装目录)
3. 准备sysroot
- 将ZYNQMP common image解压到任意位置,并将rootfs.tar.gz进一步解压
mkdir sysroot
tar -xvf rootfs.tar.gz -C sysroot
- 1
- 2
文件内容如下所示
├── bl31.elf
├── boot.scr
├── Image
├── README.txt
├── rootfs.ext4
├── rootfs.manifest
├── rootfs.tar.gz
├── sdk.sh
├── sysroot
└── u-boot.elf
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
二、创建工程




- sysroot,rootfs,kernel image指向刚才解压出来的那些文件

然后选择空工程,至此新工程创建完毕 SkrSkr/Develop/C下边的5个文件导入
.
├── main.cpp
├── SkyNet.cpp
├── SkyNet.h
├── transform.cpp
└── utils.cpp
- 1
- 2
- 3
- 4
- 5
- 6
将SkyNet.cpp和SkyNet.h复制到SkyNet_kernels/src下,将main.cpp, SkyNet.h, transform.cpp, utils.cpp复制到SkyNet/src下,如图所示

SkyNet/src下存放的是Host端代码,而SkyNet_kernels/src下存放的是FPGA端代码,二者在编译的时候是独立的。对比之前Vivado HLS的开发流程,SkyNet_kernels/src下放的就是Vivado HLS工程里的文件,但是没有testbench,而SkyNet/src放的就是综合出来比特流之后在SDK里开发应用程序的文件。(SDSoC好用就好用在将SDK的应用程序代码跟Vivado HLS里的testbench合并,逻辑上很直观。Vitis这么搞纯粹是为了上层使用OpenCL,个人认为是倒退。但是好处是不会像SDSoC稍微修改一点代码就可能导致整个工程重新编译一遍)
三、修改源代码
1. 修改SkyNet.cpp
SkyNet.cpp的设计基本不用动,唯一需要修改的就是接口定义
void SkyNet(ADT4* img, ADT32* fm, WDT32* weight, BDT16* biasm)
{
#pragma HLS INTERFACE m_axi depth=204800 port=img offset=slave bundle=fm
#pragma HLS INTERFACE m_axi depth=628115 port=fm offset=slave bundle=fm
#pragma HLS INTERFACE m_axi depth=13792 port=weight offset=slave bundle=wt
#pragma HLS INTERFACE m_axi depth=432 port=biasm offset=slave bundle=bm
#pragma HLS INTERFACE s_axilite register port=return
#pragma HLS ALLOCATION instances=PWCONV1x1 limit=1 function
#pragma HLS ALLOCATION instances=DWCONV3x3 limit=1 function
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
将接口定义删掉即可
void SkyNet(ADT4* img, ADT32* fm, WDT32* weight, BDT16* biasm)
{
#pragma HLS ALLOCATION instances=PWCONV1x1 limit=1 function
#pragma HLS ALLOCATION instances=DWCONV3x3 limit=1 function
- 1
- 2
- 3
- 4
2. 修改SkyNet/src/SkyNet.h
kernel端的SkyNet.h无需修改,但是Host端因为要用OpenCL来调用加速器,因此需要在头文件中加入相关代码(就是从案例vadd中复制过来的)
#ifndef SKYNET_H #define SKYNET_H #pragma once #define CL_HPP_CL_1_2_DEFAULT_BUILD #define CL_HPP_TARGET_OPENCL_VERSION 120 #define CL_HPP_MINIMUM_OPENCL_VERSION 120 #define CL_HPP_ENABLE_PROGRAM_CONSTRUCTION_FROM_ARRAY_COMPATIBILITY 1 #include <CL/cl2.hpp> #include <stdlib.h> #include <stdio.h> #include <iostream> #include <vector> #include <memory.h> #include <time.h> #include <sys/time.h> #include <fstream> #include <cstring> #include <math.h> #include "ap_int.h"

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3.修改SkyNet/src/SkyNet.cpp
这部分改动比较大,主要就是要用OpenCL的方式加载Kernel,分配内存,还是以vadd的案例作为参照。
- 首先把加载kernel部分代码全盘复制过来
int main(int argc, char* argv[]) { if(argc != 2) { std::cout << "Usage: " << argv[0] <<" <xclbin>" << std::endl; return EXIT_FAILURE; } char* xclbinFilename = argv[1]; std::vector<cl::Device> devices; cl::Device device; std::vector<cl::Platform> platforms; bool found_device = false; cl::Platform::get(&platforms); for(size_t i = 0; (i < platforms.size() ) & (found_device == false) ;i++){ cl::Platform platform = platforms[i]; std::string platformName = platform.getInfo<CL_PLATFORM_NAME>(); if ( platformName == "Xilinx"){ devices.clear(); platform.getDevices(CL_DEVICE_TYPE_ACCELERATOR, &devices); if (devices.size()){ device = devices[0]; found_device = true; break; } } } if (found_device == false){ std::cout << "Error: Unable to find Target Device " << device.getInfo<CL_DEVICE_NAME>() << std::endl; return EXIT_FAILURE; } // Creating Context and Command Queue for selected device cl::Context context(device); cl::CommandQueue q(context, device, CL_QUEUE_PROFILING_ENABLE); // Load xclbin std::cout << "Loading: '" << xclbinFilename << "'\n"; std::ifstream bin_file(xclbinFilename, std::ifstream::binary); bin_file.seekg (0, bin_file.end); unsigned n_b = bin_file.tellg(); bin_file.seekg (0, bin_file.beg); char *buf = new char [n_b]; bin_file.read(buf, n_b); // Creating Program from Binary File cl::Program::Binaries bins; bins.push_back({buf,n_b}); devices.resize(1); cl::Program program(context, devices, bins);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 声明kernel
cl::Kernel krnl_SkyNet(program,"SkyNet");
- 1
- 分配kernel端内存
cl::buffer
在SDSoC中我们要给权重、特征图等buffer分配连续内存地址,
img = (ADT4*)sds_alloc(4*160*320*sizeof(ADT4));
weight = (WDT32*)sds_alloc(441344*sizeof(WDT));
biasm = (BDT16*)sds_alloc(432*sizeof(BDT16));
fm = (ADT32*)sds_alloc(32*fm_all*sizeof(ADT));
- 1
- 2
- 3
- 4
在PYNQ框架中我们用xlnk分配连续内存地址
img = xlnk.cma_array(shape=[4,160,320,4], dtype=np.uint8)
fm = xlnk.cma_array(shape=(628115*32), dtype=np.uint8)
weight = xlnk.cma_array(shape=(220672), dtype=np.int16)
biasm = xlnk.cma_array(shape=(432*16), dtype=np.int16)
- 1
- 2
- 3
- 4
其中img和weight对于加速器来说是只读不写,但是biasm和fm既读又写,这一点在SDSoC和PYNQ中都无需刻意区分,但是在OpenCL需要额外注意。
cl::Buffer(按照我的理解)是在DDR中给kernel(FPGA)端分配一段内存,
cl::Buffer buffer_img(context, CL_MEM_READ_ONLY, 160*320*sizeof(ADT16));
cl::Buffer buffer_fm(context, CL_MEM_READ_WRITE, 32*fm_all*sizeof(ADT));
cl::Buffer buffer_wt(context, CL_MEM_READ_ONLY, 441344*sizeof(WDT));
cl::Buffer buffer_bm(context, CL_MEM_READ_WRITE, 432*sizeof(BDT16));
- 1
- 2
- 3
- 4
所以其读写是从kernel端看的,加速器中对img只是读没有写,所以在声明cl::Buffer时用CL_MEM_READ_ONLY,而fm和biasm既有读又有写,所以用CL_MEM_READ_WRITE。
- 配置加速器
在PYNQ框架里我们要把加速器各个端口对应对物理地址传给加速器
SkyNet = overlay.SkyNet
SkyNet.write(0x10, img.physical_address)
SkyNet.write(0x1c, fm.physical_address)
SkyNet.write(0x28, weight.physical_address)
SkyNet.write(0x34, biasm.physical_address)
- 1
- 2
- 3
- 4
- 5
在SDSoC中这个步骤工具会自动生成相应的代码,但是在OpenCL中需要手动指定,需要注意参数的顺序要跟function的顺序一致。
//set the kernel Arguments
int narg=0;
krnl_SkyNet.setArg(narg++,buffer_img);
krnl_SkyNet.setArg(narg++,buffer_fm);
krnl_SkyNet.setArg(narg++,buffer_wt);
krnl_SkyNet.setArg(narg++,buffer_bm);
- 1
- 2
- 3
- 4
- 5
- 6
- 分配Host端内存
在PYNQ框架中我们并不能直接访问属于加速器的内存片段,因此在Host端都是操作numpy数组,然后将numpy数组的数据复制到属于加速器的内存片段
parameter = np.fromfile("SkyNet.bin", dtype=np.int16)
np.copyto(weight, parameter[0:220672])# 从numpy数组复制到加速器内存
np.copyto(biasm[0:428*16], parameter[220672:])
print("Parameters loading done")
bbox_origin = np.empty(64, dtype=np.int16)
bbox = np.zeros((4,4),dtype=np.float32)
result= open('predict.txt','w+')
batch_buff = None
image = np.zeros((4,160,320,4),np.uint8)
image_buff = np.zeros((4,160,320,4),np.uint8)
...
np.copyto(bbox_origin, biasm[428*16:])# 从加速器内存复制到numpy数组
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
再次强调一下在SDSoC中不区分Host端内存和Kernel端内存
img = (ADT4*)sds_alloc(4*160*320*sizeof(ADT4));
weight = (WDT32*)sds_alloc(441344*sizeof(WDT));
biasm = (BDT16*)sds_alloc(432*sizeof(BDT16));
fm = (ADT32*)sds_alloc(32*fm_all*sizeof(ADT));
- 1
- 2
- 3
- 4
在OpenCL中要将Kernel端内存映射到Host端内存
ADT32* img = (ADT32*) q.enqueueMapBuffer (buffer_img , CL_TRUE , CL_MAP_WRITE , 0, 160*320*sizeof(ADT32));
ADT32* ofm_blob32 = (ADT32*) q.enqueueMapBuffer (buffer_fm , CL_TRUE , CL_MAP_READ | CL_MAP_WRITE , 0, fm_all*sizeof(ADT32));
WDT32* weight = (WDT32*) q.enqueueMapBuffer (buffer_wt , CL_TRUE , CL_MAP_WRITE , 0, 441344*sizeof(WDT));
BDT16* biasm = (BDT16*) q.enqueueMapBuffer (buffer_bm , CL_TRUE , CL_MAP_READ | CL_MAP_WRITE , 0, 432*sizeof(BDT16));
- 1
- 2
- 3
- 4
需要说明的是此时对读写是从Host端开过来的,所以与Kernel端配置反过来。
- 启动加速器
在PYNQ里我们用如下代码控制加速器启动与停止
SkyNet.write(0x00, 1)
isready = SkyNet.read(0x00)
while( isready == 1 ):
isready = SkyNet.read(0x00)
- 1
- 2
- 3
- 4
在OpenCL中对应的代码稍微复杂一点点,如下所示
q.enqueueMigrateMemObjects({buffer_img,buffer_wt},0/* 0 means from Host*/);
q.enqueueTask(krnl_SkyNet);
q.enqueueMigrateMemObjects({buffer_fm,buffer_bm},CL_MIGRATE_MEM_OBJECT_HOST);
q.finish();
- 1
- 2
- 3
- 4
在这里又一次出现了对内存的配置,q.enqueueMigrateMemObjects的用法我不是非常清楚,但是大概意思就是CL_MIGRATE_MEM_OBJECT_HOST选项表示Host在启动加速器之后还得回去接收数据,而0就不用。加速器运行完后边的数据处理跟SDSoC里是完全一致的。
- 回收内存
q.enqueueUnmapMemObject(buffer_img, img);
q.enqueueUnmapMemObject(buffer_fm, ofm_blob32);
q.enqueueUnmapMemObject(buffer_wt, weight);
q.enqueueUnmapMemObject(buffer_bm, biasm);
q.finish();
- 1
- 2
- 3
- 4
- 5
四、编译工程
1. 选择硬件函数
现在的工程并没有选择硬件函数加速

点击Hardware Functions里的蓝色按钮将SkyNet添加为硬件函数,并勾选Max Memory Ports。

2. 编译工程
将Activation build configuration改为Hardware,点击左侧的菜单栏SkyNet_system,然后点击小锤子,整个工程就开始编译了。在R7 3700X上大概20分钟就能编译完成。

SkyNet文件夹存放Host端调用加速器的代码,SkyNet_kernels文件夹存放FPGA端的加速器代码,但是加速器端代码还只是代码,并不是一个比特流,SkyNet_system_hw_link文件夹用来存放Vivado工程,生成的比特流就在这个文件夹下。编译完毕我们可以在SkyNet_system_hw_link找到Vivado工程

打开看一下block diagram,可以发现勾选Max Memory Ports生效了,加速器总共生成了4个M_AXI接口,如果不勾选Max Memory Ports那么四个接口就会bundle到一起,影响加速器的传输性能。

五、上板测试
1. 烧写SD卡
在编译好的工程下我们可以看到如下文件

我们把sd_card.img文件复制到windows电脑上烧写进SD卡,具体怎么烧写之前的博文中有提到,在此不再重复
2. 准备文件
用Mobaxterm登录板子,默认用户名和密码都是root。将SkyNet,init.sh,binary_container_1.xclbin以及SkrSkr/Develop/C/blob和SkrSkr/Develop/C/weight复制到/home/root下,如图所示

配置一下xrt环境
./init.sh
- 1
然后就可以开始测试啦

至此移植工作全部结束。目前的linux系统是Vitis自动生成的(其实应该是Petalinux构建出来的),可用性很差,后边会尝试把Vitis跟PYNQ结合,将Vitis生成的可执行文件放在PYNQ提供的运行环境下执行。
六、与PYNQ框架结合
- 首先设置XILINX_XRT环境
sudo -i
export XILINX_XRT=/usr
- 1
- 2
- 使用pynq.Overlay()加载比特流
- 运行执行文件
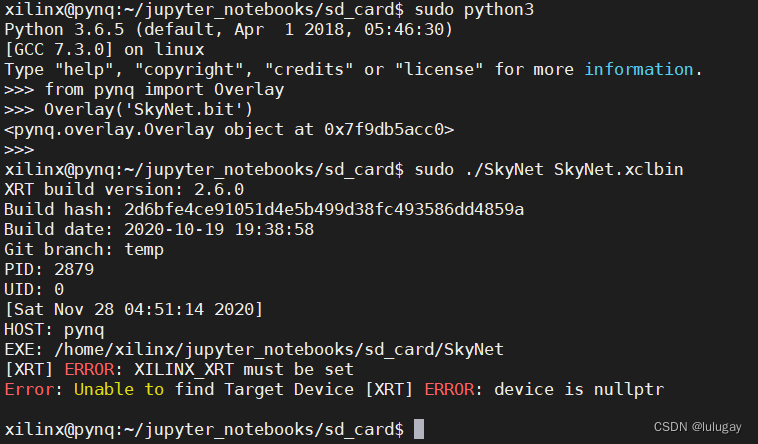
按照Vitis的标准流程,将Vitis生成的img烧写进SD卡,这个img文件是包含了比特流的,开发板启动时会自动加载比特流,并且rootfs中也配置好了XRT的环境,所以可以直接运行可执行文件。但是在PYNQ框架下,没有这个比特流,所以需要用Overlay先把比特流加载进来。

