
- 11.Tomcat和JavaEE入门_tomcatee
- 2Unity性能优化之 - 图集_unity 动态加载的icon需要打图集吗
- 392岁高龄的创始人张忠谋谈台积电发展史
- 4《Git常用命令》详细讲解·第5篇(git log和git blame)(1)_git blame grep
- 5QUARTUS 下载文件到flash中_quartus 程序下载到flash
- 6ARM 处理器 MIPS/DMIPS/MFLOPS_嵌入式arm mflops测试
- 7启明云端分享| 盘点 ESP32-S3到底有哪些功能特性_esp32 s3 awtk
- 8qmake手册(Qt5.9.3)_some exotic name (tested names were: qmake qmake-q
- 9Python计算机视觉编程_03_章毓晋计算机视觉教程python代码实现
- 10接口测试工具有哪些,哪些比较火
【数据结构】B+树_连表查询 b+树结构
赞
踩
目录
在看B+树之前,推荐先看一下B-树的原理
概念
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存实际的时候,只用来作为索引,所有数据都保存在叶子结点。
2.所有叶子结点中包含了全部信息,以及志向含这些元素记录的指针,并且叶子结点本身依靠关键字的大小自小到大按照顺序链接
3.所有中间节点的元素都同时存在于子节点,在子节点元素中是最大(或最小)的元素
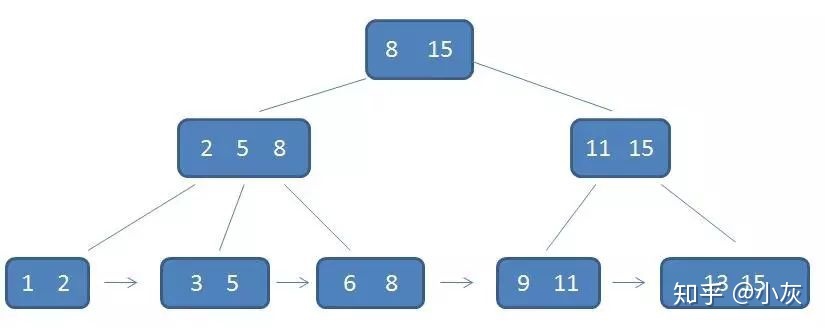
如图就是一个B+树,其中中间节点和根节点都存储的数据不是实际的数据,都是对应孩子节点元素中的最大值,所有元素都存储在叶子结点中,同时叶子结点互相相连,形成一个链表
对于卫星数据的理解
B-树和B+树还有一点明显的区别是,B+树只有叶子结点有卫星数据,中间节点仅仅是索引,没有任何数据
我对于卫星数据的理解是,存储实际数据的结点叫做卫星数据,而作为作为位置的数据不叫卫星数据,比如一个链表结构
- struct Node{
- int data;
- struct Node *next;
- }
其中data就是卫星数据,用于存储整形数据,而*next只是作为链表链接,并不是存储实际的数据,所以不叫卫星数据
指定元素的查找
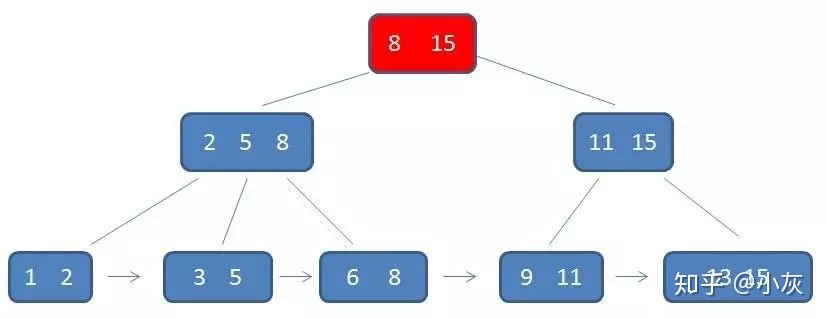
假设要查找的元素为3
第一次查找
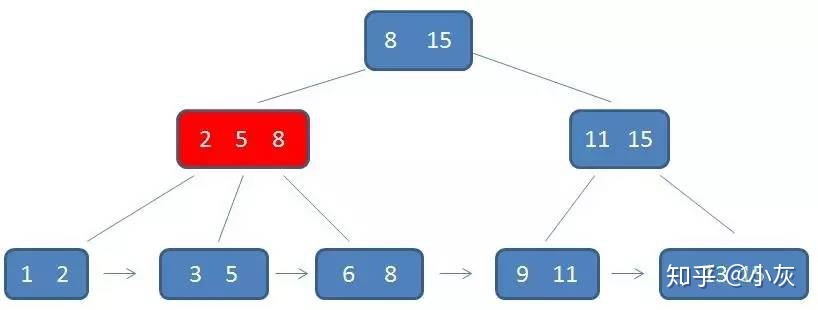
第二次查找
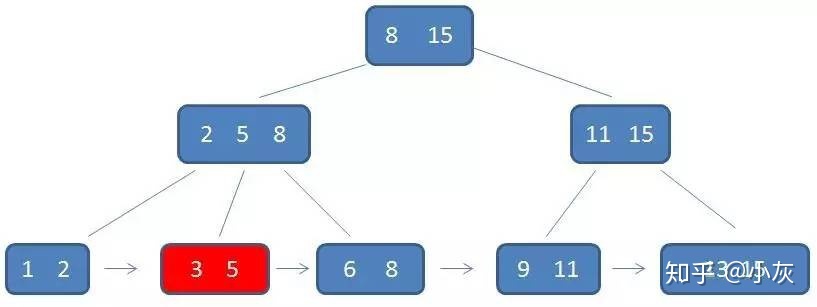
第三次查找
B+树与B-树的区别与好处
1.IO次数更少
因为B+树的中间节点没有卫星数据,只有代表地址的数据,对应的节点就可以省下卫星数据的空间,所以同样大小的磁盘页可以容纳更多的节点元素
代表着数据量相同的情况下B+树比B-树的高度更加低,查询时的IO次数也会更少
2.查询性能更稳定
因为B-树每个节点都存储着数据,B+树只有叶子结点存储着数据,所以B-树的查询性能并不稳定(最好情况是只查跟节点,最坏情况是查到叶子结点),而B+树的每一次查找都是稳定的
3.范围查询更方便
因为B+树底层是链表结构,所以在连续查询时只需要顺着底部的链表进行查询就可以了,而B-树需要在叶子结点、中间节点上反复横跳
参考文章


