
- 1java.sql.SQLException No suitable driver 的解决办法_java.sql.sqlexception: no suitable driver
- 2交叉注意力融合时域、频域特征的FFT + CNN-Transformer-CrossAttention轴承故障识别模型_时域频域 transformer
- 3Java实现Excel多表头动态数据导出_java导出excel多级表头
- 4MVVM设计模式时什么?浅谈MVVM设计模式_wpf之mvvm模式描述错误的是
- 5用Eclipse创建一个JavaWeb项目,把资源添加到Tomcat服务器,并运行jsp文件详细过程(附图片)_eclipse创建web项目
- 6云计算实战系列四(Linux文件权限I)
- 7Docker入门指南:从基础到实践_ubuntu docker 入门
- 8vue+vite项目打包生成可以后端修改url ip的相关配置与使用方式_vite 设置后端ip
- 9牛客网-刷题解析2
- 10数学计算机教学课题,《现代信息技术与小学数学教学整合的实践研究》顺利结题...
数据结构初阶 链表详解
赞
踩
一. 为什么使用链表
1.1顺序结构的缺点
在我们的顺序表结构中 有以下这么几个缺陷
1 空间不够了 需要扩容 扩容是有消耗的
2 头部或者中间位置的插入删 除 需要挪动 挪动数据也是有消耗的
3 避免频繁扩容 依次一般都是按倍数去扩 容易造成空间浪费
1.2 链表的诞生及优点
为了解决以上顺序表的缺点 我们设计出了链表
链表的优点有
1 按需申请空间 不用了就释放空间(更合理的使用空间)
2 头部中间插入删除数据 不需要挪动数据
但是链表其实也是有缺点的
1 每一个数据 都要存一个指针去链接后面的数据节点
2 不支持随机访问
(这里简单解释下随机访问 其实就是能够通过下标直接访问第i个 然而顺序表就支持随机访问 )
这里画个图简单对比下两种数据结构
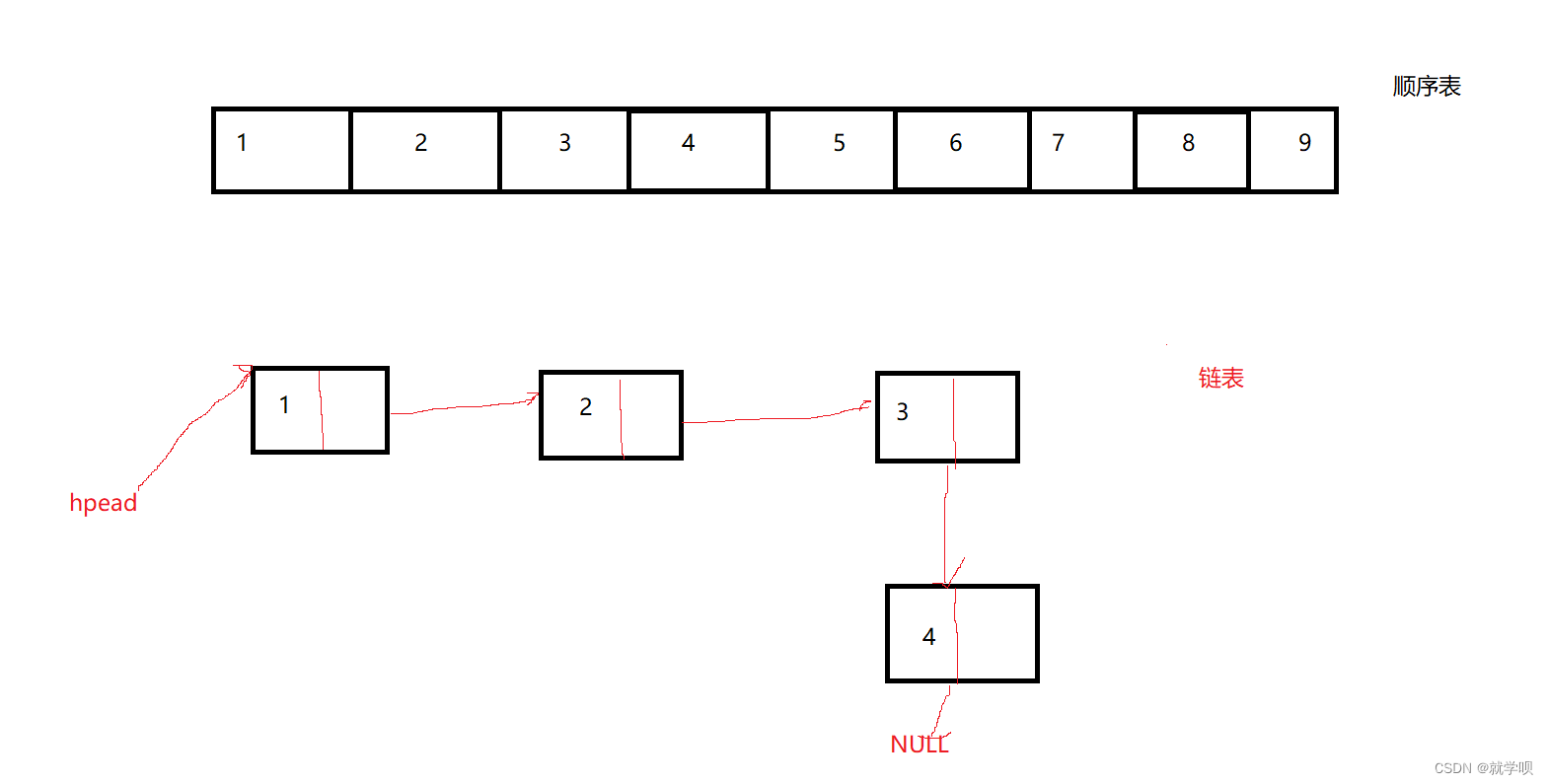
所以说 这里我们就能得出一个结论
顺序表和链表并不是对立的关系 而是互补的关系
二. 链表的接口函数实现
2.1 类型定义
还是和顺序表那一节一样 咱们先来定义类型
- typedef int SLTDateType;
- typedef struct SListNode
- {
- SLTDateType date;
- struct SListNode* next;
- }SLTNode;
首先因为咱们这个链表储存的类型可能不是整型类型的数据
为了防止以后改来改去 我们首先先使用typedef定义一个类型
如果我们以后想要储存其他类型的数据 只需要改变一行就可以了
2.2 遍历(打印)
首先直接上代码
- void SLTPrint(SLTNode* phead)
- {
- SLTNode* cur = phead;
- while (cur)
- {
- printf("%d->", cur->date);
- cur = cur->next;
- }
- printf("NULL\n");
- }
我们这里画图给大家解释一下
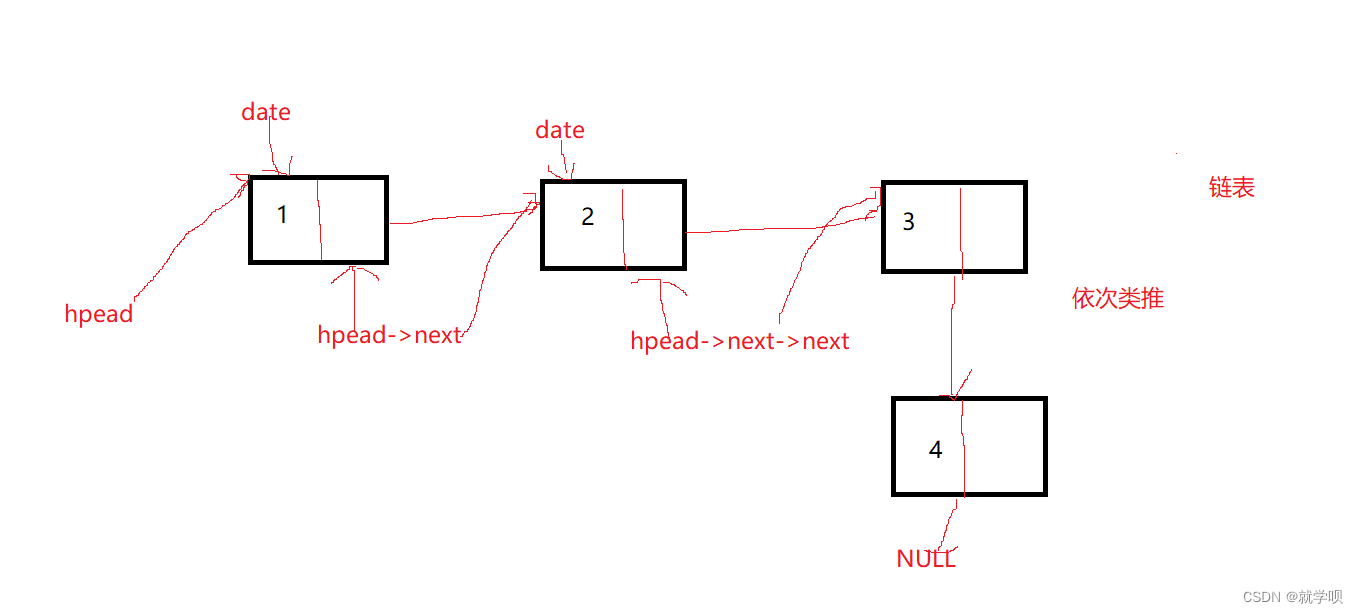
phead是一个指针 它指向着第一个链表数据
第一它可以访问结构体中的date数据 可以对这个数据进行打印 修改等操作
第二 它可以访问结构体中的next指针 而这个指针指向第二个数据
它可以通过这个指针修改自身指向的位置 从而找到链表第二个数据
2.3 尾插数据
首先我们要尾插数据 我们首先要找到尾在哪里
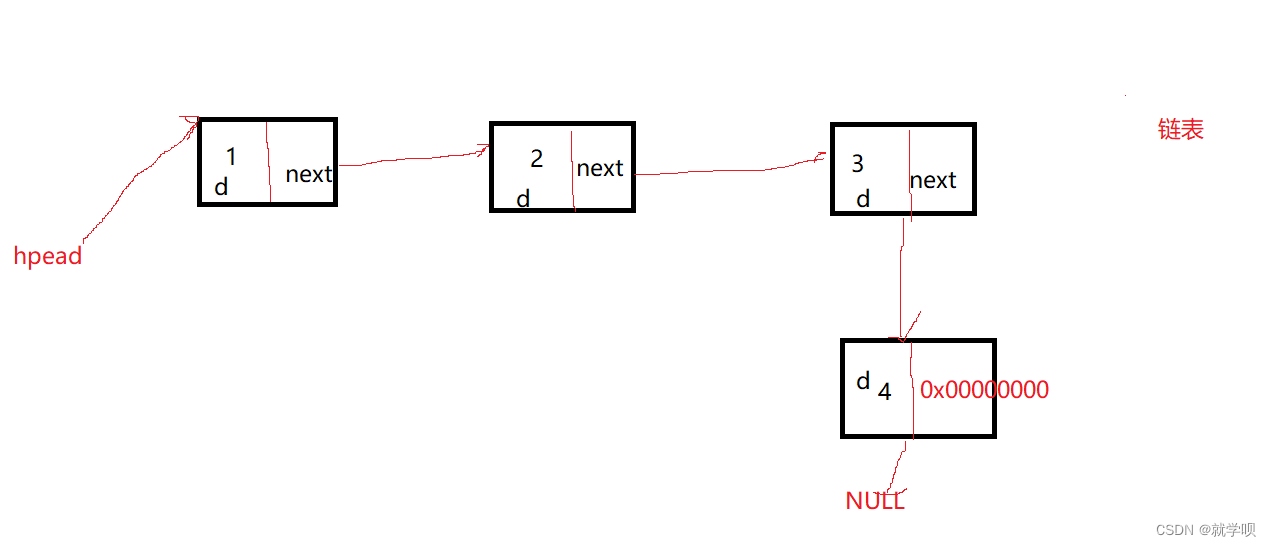
我们观察图可以发现 尾部的数据跟其他的数据有一个明显的
区别就是它最后的指针指向NULL
- int BuySLTNode(SLTDateType x)
- {
- //开辟一个新节点
- SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
- if (newnode == NULL)
- {
- perror("malloc fail");
- return;
- }
- //新节点初始化
- newnode->date = x;
- newnode->next = NULL;
- return newnode;
- }
我们可以封装一个函数BuySLTNode方便我们插入一个节点,然后我们开始考虑是否头函数指向NULL是的话将节点直接插入,不是的话就需要我们找尾并插入
- void SLTPushBack(SLTNode** pphead, SLTDateType x)
- {
- SLTNode* newnode = BuySLTNode(x);
- if (*pphead == NULL)
- {
- *pphead = newnode;
- }
- else
- {
- //找尾
- SLTNode* tail = *pphead;
- while (tail->next != NULL)
- {
- tail = tail->next;
- }
- tail->next = newnode;
- }
- }

这里我们还需要考虑一个问题 是传值进去还是传地址进去
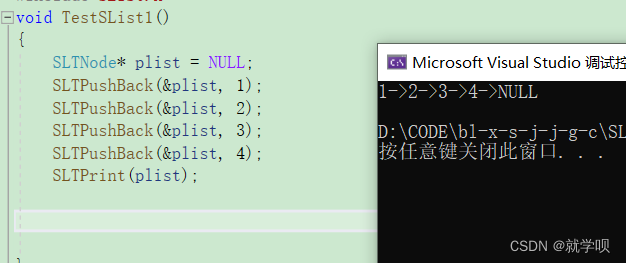
- void TestSList1()
- {
- SLTNode* plist = NULL;
- SLTPushBack(&plist, 1);
- SLTPushBack(&plist, 2);
- SLTPushBack(&plist, 3);
- SLTPushBack(&plist, 4);
- SLTPrint(plist);
-
- SLTPrint(plist);
-
- }
我们要想改变PList的值 我们必须要将它的地址传进去
这样子我们就需要用二级指针来接受
然后打印试试
我们发现就可以完美运行
2.4 头插
这里我们只需要改变两个数据
一个是新链表的next
一个是phead指向的位置
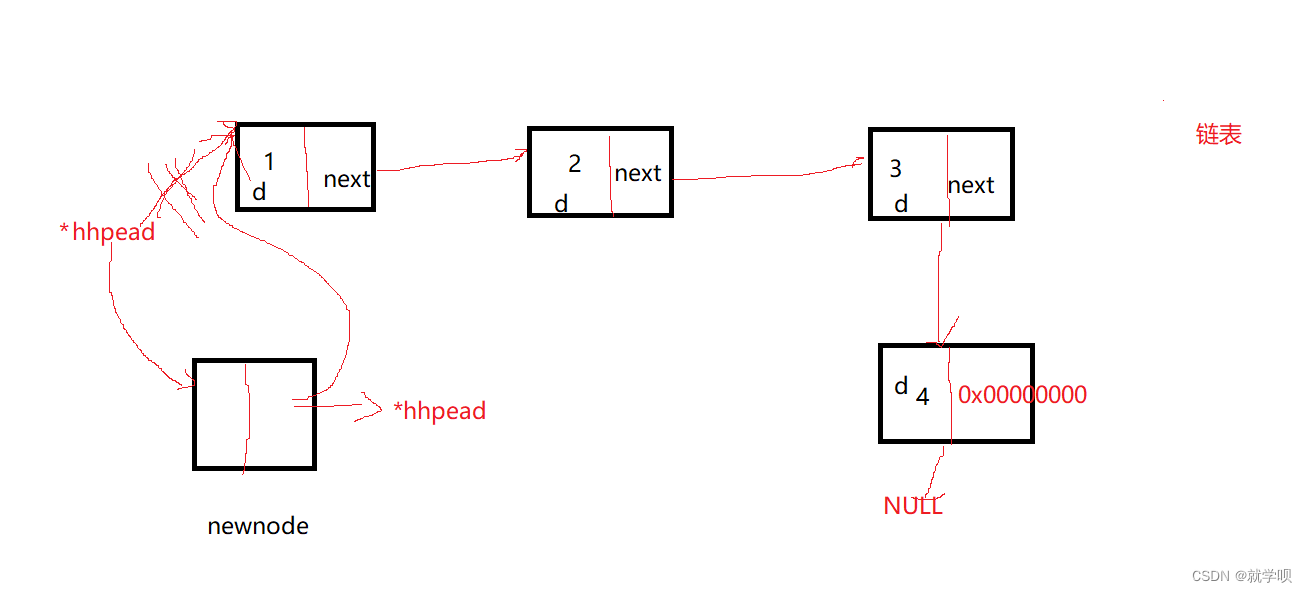
- void SLTPushFront(SLTNode** pphead, SLTDateType x)
- {
- SLTNode* newnode = BuySLTNode(x);
- newnode->next = *pphead;
- *pphead = newnode;
- }
2.5 尾删
尾删的话我们就需要断言了,那为什么尾插的时候不断言纳?
因为尾插的时候即使头函数指向NULL我们也可以插入,但尾删的话头函数指向NULL我们没有数据删除所以无法执行,这时候我们就需要断言了
- //暴力检查
- assert(*pphead);//需要断言 单链表为NULL则没有删除的节点,不能执行
- 温柔检查
- //if (*pphead == NULL)
- //{
- // return;
- //}
接下来考虑两个问题
1.只有一个节点
2.多个节点
还要考虑将最后一个节点删除后,前一个节点是否成了野指针
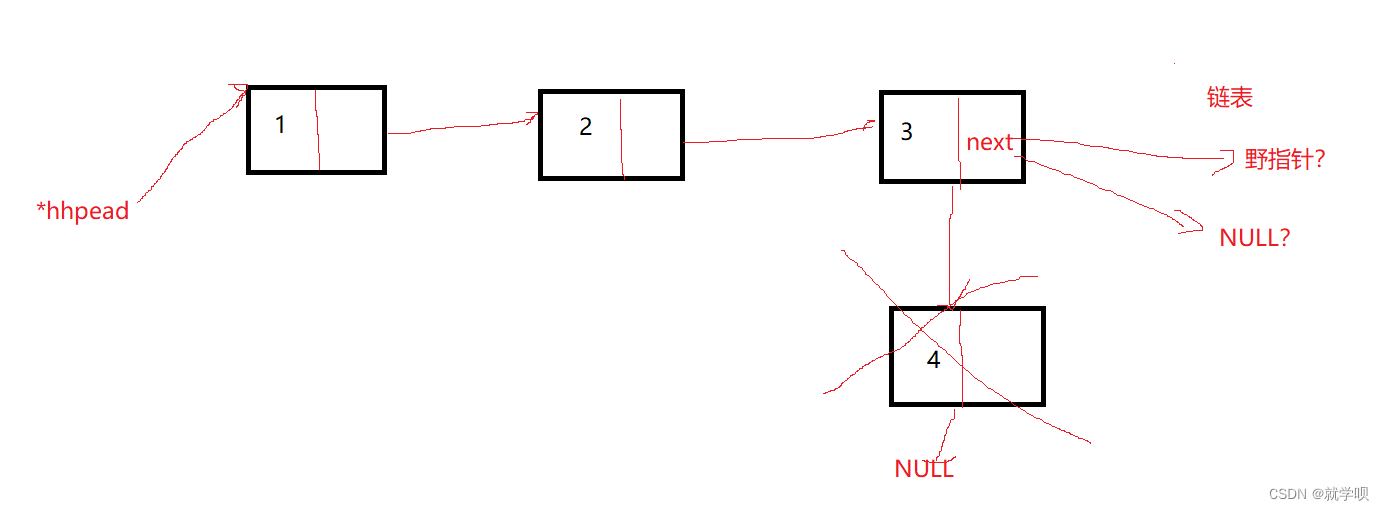
我们要做到尾删的话首先要找到最后一个数据存储的空间 然后将它释放掉
类似这样子操作
但是呢 这样子就会出现一个问题
前面一个数据的next还是指向这一片空间 这就形成了经典的野指针问题
为此我们就必须要使用一个指针储存tail的上一个值
这样子在tail->next->next找到最后一个数据的时候 tail->next就能够找到倒数第二个数据的位置
代码表示如下
- void SLTPopBack(SLTNode** pphead)
- {
- //暴力检查
- assert(*pphead);//需要断言 单链表为NULL则没有删除的节点,不能执行
- 温柔检查
- //if (*pphead == NULL)
- //{
- // return;
- //}
- //找尾
- //1.一个节点
- //2.多个节点
- if ((*pphead)->next == NULL)
- {
- free(*pphead);
- *pphead = NULL;
- }
- else
- {
- SLTNode* tail = *pphead;
- while (tail->next->next != NULL)
- {
- tail = tail->next;
- }
- free(tail->next);
- tail->next = NULL;
- }
- }
结果表示如下
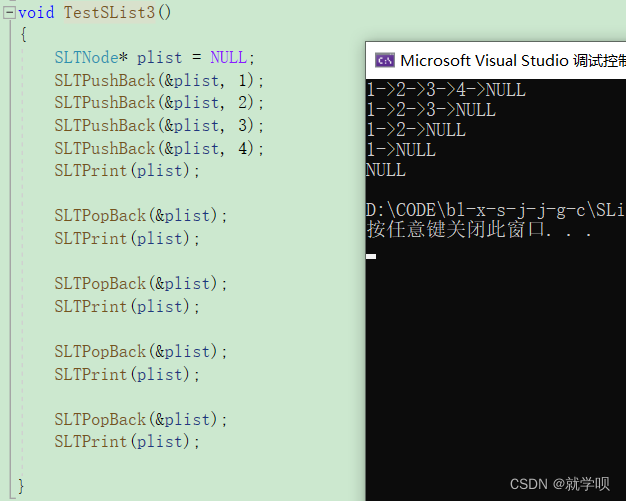
2.6 头删
对比来说头删就简单很多了,还是要考虑断言

- void SLTPopFront(SLTNode** pphead)
- {
- //暴力检查
- assert(*pphead);
-
- SLTNode* first = *pphead;
- *pphead = first->next;
- free(first);
- first = NULL;
- }
结果如下
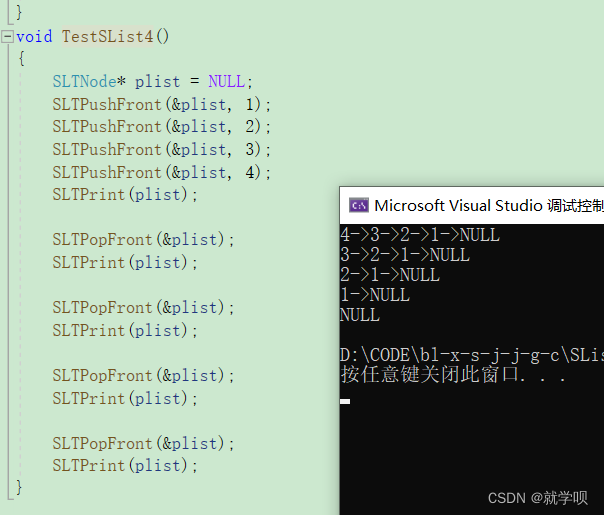
以上便是本文所有内容了,如有错误请各位大佬不吝赐教,感谢留言

