
- 1第十一章 大数据技术与实践_大数据技术与实践研究内容
- 2数据结构之堆(优先级队列)
- 32024最新分享Java面试题库万字精华 github上标星80
- 4【鸿蒙】大模型对话应用(一):大模型接口对接与调试_模型 接口
- 51+X大数据平台运维职业技能等级证书中级_+x大数据平台运维职业技能等级证书题
- 6JedisConnectionException: Unexpected end of stream._redis.clients.jedis.exceptions.jedisconnectionexce
- 7本机部署大语言模型:Ollama和OpenWebUI实现各大模型的人工智能自由_ollama本地部署设置中文回复
- 8GradNorm:Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks,梯度归一化_grad norm
- 9【Verilog】期末复习——设计11011序列检测器电路_verilog序列检测器11011
- 10SpringBoot-基于注解实现Redis限流_基于注解实现限流
计算机二级(python)【三】_程序接收用户输入的五个数,以逗号分隔
赞
踩
真题9
1、在考生文件夹下有个文件PY101.py,在横线处填写代码,完成如下功能。程序接收用户输入的五个数,以逗号分隔。将这些数字按照输入顺序输出,每个数字占10个字符宽度,右对齐,所有数字显示在同一行。例如:
输入:
23,42,543,56,71
输出:
23 42 543 56 71
代码
num = input().split(',')
for i in num:
print("{:>10}".format(i),end="")
- 1
- 2
- 3
2、在考生文件夹下有个文件PY102.py,在横线处填写代码,完成如下功能。社会平均工作时间是每天8小时(不区分工作日和休息日),一位计算机科学家接受记者采访时说,他每天工作时间比社会平均工作时间多3小时。如果这位科学家的当下成就值是1,假设每工作1个小时成就值增加0.01%,计算并输出两个结果:这位科学家5年后的成就值,以及达到成就值100所需要的年数。其中,成就值和年数都以整数表示,每年以365天计算。
输出格式示例如下:
5年后的成就值是XXX
XX年后成就值是100
代码
scale = 0.0001 # 成就值增量
def calv(base, day):
val = base * pow((1+scale),day*11)
return val
print('5年后的成就值是{}'.format(int(calv(1, 5*365))))
year = 1
while calv(1, year*365) < 100:
year += 1
print('{}年后成就值是100'.format(year))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3、在考生文件夹下有个文件PY103.py,在横线处填写代码,完成如下功能。程序接收用户输入的一个数字并判断是否为正整数,如果不是正整数,则显示“请输入正整数”并等待用户重新输入,直至输入正整数为止,并显示输出该正整数。例如:
输入:
请输入一个正整数:357
输出:
357
代码
while True:
try:
a = eval(input('请输入一个正整数: '))
if a > 0 and type(a) == int:
print(a)
break
else:
print("请输入正整数")
except:
print("请输入正整数")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4、在考生文件夹下有个文件PY201.py,在横线处填写代码,完成如下功能。根据列表中保存的数据采用turtle库画图直方图,显示输出在屏幕上,效果如下图所示。
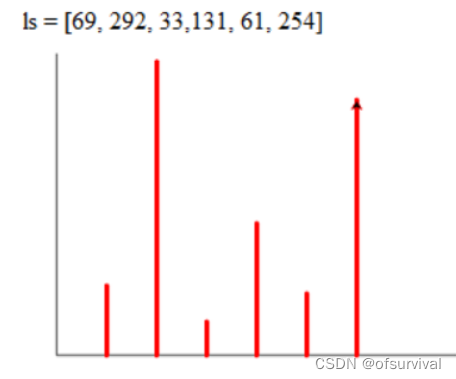
代码
import turtle as t #更简洁地调用turtle库 ls = [69, 292, 33, 131, 61, 254] X_len = 400 Y_len = 300 x0 = -200 y0 = -100 t.penup() t.goto(x0, y0) t.pendown() t.fd(X_len) t.fd(-X_len) t.seth(90) #设置笔的起始角度 t.fd(Y_len) t.pencolor('red') t.pensize(5) for i in range(len(ls)): t.penup() #提起画笔 t.goto(x0 + (i+1)*50, y0) #移到绝对坐标处,这里x坐标动,y坐标不动 t.seth(90) t.pendown() #放下画笔 t.fd(ls[i]) #表示直线爬行的距离 t.done()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
5、在考生文件夹下有个文件PY202.py,在省略号处填写一行或多行代码,完成如下功能。在已定义好的字典pdict里有一些人名及其电话号码。请用户输入一个人的姓名,在字典中查找该用户的信息,如果找到,生成一个四位数字的验证码,并将名字、电话号码和验证码输出在屏幕上,如示例所示。如果查找不到该用户信息,则显示“对不起,您输入的用户信息不存在。”示例如下:
输入:
Bob
输出:
Bob 234567891 1926
输入:bob
输出:
对不起,您输入的用户信息不存在。
代码
import random
random.seed(2)
pdict= {'Alice':['123456789'],
'Bob':['234567891'],
'Lily':['345678912'],
'Jane':['456789123']}
name = input('请输入一个人名:')
if name in pdict:
print("{} {} {}".format(name,pdict.get(name)[0],random.randint(1000,9999)))
else:
print("对不起,您输入的用户信息不存在。")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6、考生文件夹下存在2个Python源文件和2个文本文件。其中,2个python源文件对应2个问题,2个文本文件分别摘自2019年和2018年的政府工作报告。请分别补充2个Python源文件,实现以下功能。
问题1(10分):数据统计。要求:修改PY301-1.py文件中代码,分别统计两个文件中出现次数最多的10词语,作为主题词,要求词语不少于2个字符,打印输出在屏幕上,输出示例如下:(示例词语非答案)
2019:改革:10,企业:9,…(略),深化:2
2018:改革:11,效益:7,…(略),深化:1
注意:输出格式采用英文冒号和英文逗号,标点符号前后无空格,各词语间用逗号分隔,最后一个词语后无逗号。
问题2(10分):数据关联。要求:修改PY301-2.py文件中代码,对比两组主题词的差异,输出两组的共有词语和分别的特有词语。输出示例如下:(示例词语非答案)
共有词语:改革,…(略),深化
2019特有:企业,…(略),加强
2018特有:效益,…(略),创新
注意:输出格式采用英文冒号和英文逗号,标点符号前后无空格,各词语间用逗号分隔,最后一个词语后无逗号。
问题一代码
import jieba fa=open("data2019.txt","r") txt=fa.read() fa.close() words=jieba.lcut(txt) d = {} for word in words: if len(word)==1: continue else: d[word]=d.get(word,0)+1 lt = list(d.items()) lt.sort(key = lambda x:x[1],reverse = True) print("2019:",end="") for i in range(10): word,count=lt[i] if i<9: print("{}:{}".format(word,count),end=",") else: print("{}:{}".format(word,count)) fa=open("data2018.txt","r") txt=fa.read() fa.close() words=jieba.lcut(txt) d = {} for word in words: if len(word)==1: continue else: d[word]=d.get(word,0)+1 lt = list(d.items()) lt.sort(key = lambda x:x[1],reverse = True) print("2018:",end="") for i in range(10): word,count=lt[i] if i<9: print("{}:{}".format(word,count),end=",") else: print("{}:{}".format(word,count))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
问题二代码
import jieba fa=open("data2019.txt","r") txt=fa.read() fa.close() words=jieba.lcut(txt) d = {} for word in words: if len(word)==1: continue else: d[word]=d.get(word,0)+1 lt = list(d.items()) lt.sort(key = lambda x:x[1],reverse = True) da={} for i in range(10): da[i]=lt[i][0] #求2018中的10个主题词,存为db fa=open("data2018.txt","r") txt=fa.read() fa.close() words=jieba.lcut(txt) d = {} for word in words: if len(word)==1: continue else: d[word]=d.get(word,0)+1 lt = list(d.items()) lt.sort(key = lambda x:x[1],reverse = True) db={} for i in range(10): db[i]=lt[i][0] #求m个共有词存入gy,并将da、db中原共有的改为空 gy={} m=0 for i in range(10): for j in range(10): if da[i]==db[j]: gy[m]=da[i] da[i]="" db[j]="" m=m+1 break print("共有词语:",end="") for i in range(m): if i<m-1: print("{}".format(gy[i]),end="") else: print("{}".format(gy[i])) print("2019特有:",end="") j=0 for i in range(10): if da[i]!="": if j<10-m-1: print("{}".format(da[i]),end=",") else: print("{}".format(da[i])) j=j+1 print("2018特有:",end="") j=0 for i in range(10): if db[i]!="": if j<10-m-1: print("{}".format(db[i]),end=",") else: print("{}".format(db[i])) j=j+1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
真题10
1、在考生文件夹下有个文件PY101.py,在横线处填写代码,完成如下功能。接收用户输入的一个小于20的正整数,在屏幕上逐行递增显示从01到该正整数,数字显示的宽度为2,不足位置补0,后面追加一个空格,然后显示’>‘号,’>'号的个数等于行首数字。例如:
输入:
3
输出:
01 >
02 >>
03 >>>
代码
n = input('请输入一个正整数:')
for i in range(int(n)):
print('{:0>2} {}'.format(i+1, ">"*(i+1)))
- 1
- 2
- 3
2、在考生文件夹下有个文件PY102.py,在横线处填写代码,完成如下功能。让用户输入一串数字和字母混合的数据,然后统计其中数字和字母的个数,显示在屏幕上。例如:
输入:
Fda243fdw3
输出:
数字个数:4,字母个数:6
代码
ns = input("请输入一串数据:")
dnum,dchr = 0,0 #双变量赋值方式
for i in ns:
if i.isnumeric(): #如果是数字字符
dnum += 1
elif i.isalpha():
dchr += 1
else:
pass #空语句,为了保持程序结构的完整性,用于占位
print('数字个数:{},字母个数:{}'.format(dnum,dchr))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3、在考生文件夹下有个文件PY103.py,在横线处填写代码,完成如下功能。将程序里定义好的std列表里的姓名和成绩与已经定义好的模板拼成一段话,显示在屏幕上。例如:
亲爱的张三,你的考试成绩是英语90,数学87,Python语言95,总成绩272。特此通知。
…(略)
代码
std = [['张三',90,87,95],['李四',83,80,87],['王五',73,57,55]]
modl = "亲爱的{}, 你的考试成绩是: 英语{}, 数学{}, Python语言{}, 总成绩{}.特此通知."
for st in std:
cnt = 0 #总成绩初始值
for i in range(3): #循环三科成绩
cnt += st[i+1] #成绩求和
print(modl.format(st[0],st[1],st[2],st[3],cnt))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4、在考生文件夹下有个文件PY201.py,在横线处填写代码,完成如下功能。利用random库和turtle库,在屏幕上绘制5个圆圈,圆圈的半径和圆心的坐标由randint()函数产生,圆的X和Y坐标范围在[-100,100]之间;半径的大小范围在[20,50]之间,圆圈的颜色随机在color列表里选择。效果如下图所示。
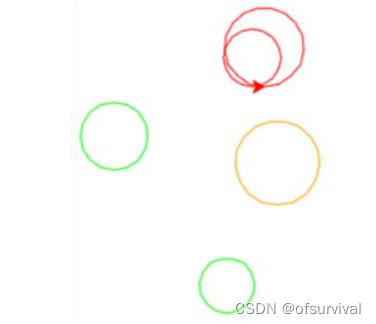
代码
import turtle as t #对turtle库中函数调用采用更简洁的形式
import random as r
color = ['red','orange','blue','green','purple']
r.seed(1)
for i in range(5):
rad = r.randint(20,50) #在[20,50]之间生成一个半径值
x0 = r.randint(-100,100)
y0 = r.randint(-100,100)
t.color(r.choice(color))
t.penup() #提起画笔
t.goto(x0,y0) #移到绝对坐标处
t.pendown() #放下画笔
t.circle(rad)
t.done()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
45、在考生文件夹下有个文件PY202.py,定义了一个6个浮点数的一维列表lt1和一个包含3个数的一维列表lt2。
示例如下:
lt1=[0.69,0.292,0.33,0.131,0.61,0.254]
lt2=[0.1,0.8,0.2]
在横线处填写代码,完成如下功能。计算lt1列表跟lt2列表的向量内积,两个向量X=[x1,x2,x3]和Y=[y1,y2,y3]的内积计算公式如下:
k=x1y1+x2y2+x3*y3
将每次计算的两组对应元素的值、以及对应元素乘积的累计和(k)的值显示在屏幕上格式如下所示。
k=0.069,lt2[0]=0.100,lt1[0+0]=0.690
k=0.303,lt2[1]=0.800,lt1[0+1]=0.292
k=0.369,It2[2]=0.200,lt1[0+2]=0.330
… (略)
计算方式如下:
第一步计算第一个k, 分为3次累加计算:
k=lt2[0]* lt1[0+0];
k=lt2[0]* lt1[0+0]+lt2[1]* lt1[0+1]; .
k=lt2[0]* lt1[0+0]+ lt2[1]* lt1[0+1]+ lt2[2]*lt1[0+2]
最终得到最后一个k值保存
第二步计算第二个k,分为3次累加计算:
k=lt2[0]* lt1[1+0];
k=lt2[0]* lt1[1+0]+ lt2[1]* lt1[1+1];
k=lt2[0]* lt1[1+0]+ lt2[1]* lt1[1+1]+lt2[2]*lt1[1+2]
最终得到最后一个k值保存,依照此规律依次计算。
代码
img = [0.244, 0.832, 0.903, 0.145, 0.26, 0.452]
filter = [0.1,0.8,0.1]
res = []
for i in range(len(img)-2):
k=0 #有多个和,所以每次赋初始值0
for j in range(3): #求3次累计和
k+=filter[j]*img[i+j] #求3次累计和
print('k={:.3f},filter[{}]={:.3f},img[{}+{}]={:.3f}'.format(k,j,filter[j],i,j,img[i+j]))
res.append(k)
for r in res:
print('{:<10.3f}'.format(r),end = '')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6、考生文件夹下,存在2个Python源文件和1个文本文件。其中,2个Python源文件对应2个问题,文本文件“data.txt”中包含一篇从互联网上下载的关于“德国工业4.0战略规划实施建议摘要”的文章。请分别补充2个Python源文件,完成以下功能。
问题1(10分):文件内容清洗。要求:在文件PY301-1.py中补充代码,对文件data.txt的内容进行清理,去除中文标点符号,换行符和中英文空格,只保留中文、英文、数字、英文标点符号等字符,将结果输出到文件clean.txt中。示例如下:
德国工业4.0战略计划实施建议摘编机械工业信息研究院战略与规化研究所一德国实施工业…(略)
问题2(10分):提取主题词及其出现频次。要求:在文件PY301-2.py中补充代码,提取clean.txt文件中长度不少于3个字符的词语并统计词频,将词频最高的10个词语作为主题词,并将主题词及其频次输出到屏幕。示例如下:
4.0:10,制造业:9,…(略)
注意:输出格式采用英文冒号和英文逗号,标点符号前后无空格,各词语中间用逗号分隔,最后一个词语后无逗号。
问题一代码
f = open('data.txt','r',encoding='utf-8')
fi=open('clean.txt','w')
txt = f.read()
s = ''
for i in txt:
if i not in ',。?!——《》()【】;:‘’“”、¥ \n':
s+=i
fi.write(s)
fi.close()
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
问题二代码
import jieba
f=open('clean.txt','r')
data=f.read()
l=jieba.lcut(data)
d = {}
for i in l:
if len(i)>=3:
d[i] = d.get(i,0)+1
lt = list(d.items())
lt.sort(key = lambda x:x[1],reverse = True)
for i in lt[:9]:
print(i[0],':',i[1],end=',',sep='')
print(lt[9][0],':',lt[9][1],sep='')
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
真题11
1、考生文件夹下存在一个文件PY101.py,请写代码替换横线,不修改其他代码,实现以下功能:
接收用户输入的一个大于10小于10的8次方十进制正整数,输出这个正整数各字符的和,以25为宽度,居中显示,采用等号=填充。
例如:键盘输入1357,屏幕输出=16==
代码
s = input("请输入一个正整数: ")
cs=0 #求和初始值
for c in s:
cs += int(c) #字符转整型
print('{:=^25}'.format(cs))
- 1
- 2
- 3
- 4
- 5
- 6
2、 考生文件夹下存在一个文件PY102.py, 请写代码替换横线, 不修改其他代码,实现以下功能:
接收用户输入的数据,该数据仅由字母和中文混合构成,无其他类型字符,统计并输出中文字符出现的个数。
例如输入wor1d世界peace和平,输出4
代码
s = input("请输入中文和字母的组合: ")
count=0 #求和初始值
for c in s:
if u'\u4e00' <= c <= '\u9fff':
count += 1
print(count)
- 1
- 2
- 3
- 4
- 5
- 6
3、考生文件夹下存在一个文件PY103.py, 请写代码替换横线, 不修改其他代码,实现以下功能:
接收用户输入的以英文逗号分隔的一组数据,其中,每个数据都是整数或浮点数,打印输出这组数据中的最大值。
例如输入1,3,5,7,9,7,5,3,1
输出9
代码
s = input("请输入一组数据: ")
ls = s.split(",")
lt = []
for i in ls:
lt.append(eval(i))
print(max(lt))
- 1
- 2
- 3
- 4
- 5
- 6
4、考生文件夹下存在一个文件PY201.py,请写代码替换横线,不修改其他代码,实现以下功能:
利用random库和turtle库,在屏幕上绘制4个小雪花,雪花的中心点坐标由列表points给出,雪花的半径长度由randint()函数产生。
雪花的颜色是红色,效果如下图所示

代码
import turtle as t import random as r r.seed(1) t.pensize(2) t.pencolor('red') #设置笔的颜色 angles = 6 points= [[0,0],[50,40],[70,80],[-40,30]] for i in range(len(points)): x0,y0 = points[i] t.penup() #提起画笔,与pendown配对使用 t.goto(x0,y0) #移到绝对坐标处 t.pendown() #放下画笔 length = r.randint(6, 16) for j in range(angles): t.forward(length) #沿着当前方向前面指定距离 t.backward(length) #沿着当前相反方向前进指定距离 t.right(360 / angles) t.done()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
5、考生文件夹下存在一个文件PY202.py,该文件是本题目的代码提示框架,其中代码可以任意修改。请在该文件中编写代码,以实现如下功能:
data. txt,其中记录了2019年QS全球大学排名前20名的学校信息,示例如下:
1,麻省理工学院,美国
2,斯坦福大学,美国
3,哈佛大学,美国
第一列为排名,第2列为学校名称,第3列为学校所属的国家,字段之间用逗号’,'隔开
程序读取data.txt文件内容,统计出现的国家个数以及每个国家上榜大学的数量及名称,输出结果格式示例如下:
美国: 11 : 麻省理工学院 斯坦福大学 哈佛大学 加州理工学院 芝加哥大学 普林斯顿大学 康奈尔大学 耶鲁大学 哥伦比亚大学 宾夕法尼亚大学 密歇根大学安娜堡分校
英国: 5 : 牛津大学 剑桥大学 帝国理工学院 伦敦大学学院 爱丁堡大学
代码
f = open('data.txt','r',encoding='utf-8')
dic={}
for line in f:
l=line.strip().split(',')
if len(l)<3:
continue
dic[l[-1]]=dic.get(l[-1],[])+[l[1]]
unis=list(dic.items())
unis.sort(key=lambda x:len(x[1]),reverse=True)
for d in unis:
print('{:>4}: {:>4} : {}'.format(d[0],len(d[1]),' '.join(d[1])))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6、考生文件夹下存在2个文本文件,文本文件“红楼梦. txt”中包含了《红楼梦》小说前20章内容,“ 停用词. txt”包含了需要排除的词语。请修改模板,实现以下功能
1、对“红楼梦. txt”中文本进行分词,并对人物名称进行归一化处理,仅归一化以下内容:
凤姐、凤姐儿、凤丫头归一为凤姐
宝玉、二爷、宝二爷归一为宝玉
黛玉、颦儿、林妹妹、黛玉道归一为黛玉
宝钗、宝丫头归一为宝钗
贾母、老祖宗归一为贾母
袭人、袭人道归一为袭人
贾政、贾政道归一为贾政
贾链、琏二爷归一为贾琏
2、不统计“停用词.txt"文件中包含词语的词频。
3、提取出场次数不少于40次的人物名称,将人物名称及其出场次教按照递减排序,保存到result.csv文件中,出场次数相同的.则按照人物名称的字符顺序排序。
输出示例
宝玉,597
凤姐,296
一个,179
如今,132
黛玉,113
一面,112
代码
import jieba f = "红楼梦.txt" sf = "停用词.txt" txt = jieba.lcut(open(f, 'r', encoding = 'utf-8').read()) stop_words = [] with open(sf, 'r', encoding = 'utf-8') as f: for i in f.read().splitlines(): stop_words.append(i) #剔除停用词 txt0 = [x for x in txt if x not in stop_words] #统计词频 counts = {} for word in txt0: if len(word) == 1: continue elif word == '凤姐儿' or word == '凤丫头': rword = '凤姐' elif word == '二爷' or word == '宝二爷': rword = '宝玉' elif word == '颦儿' or word == '林妹妹' or word == '黛玉道': rword = '黛玉' elif word == '宝丫头': rword = '宝钗' elif word == '老祖宗': rword = '贾母' elif word == '袭人道': rword = '袭人' elif word == '贾政道': rword = '贾政' elif word == '琏二爷': rword = '贾琏' else: rword = word counts[rword] = counts.get(rword,0) + 1 li = list(counts.items()) li.sort(key=lambda x:x[1], reverse=True) print(li) #列出词频超过40的结果 with open(r'result.csv','a', encoding = 'gbk') as f: for i in li: key,value = i if value < 40: break f.write(key + ',' + str(value) + '\n') print(key + ',' + str(value))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
真题12
1、考生文件夹下存在一个文件PY101.py,请写代码替换横线,不修改其他代码,实现以下功能:
接收用户输入的一个浮点数,输出这个浮点数的小数部分各字符的和,以10为宽度,靠右显示,采用星号*填充。
例如:键盘输入1234.5678,屏幕输出********26
代码
s = input("请输入一个小数: ")
s = s[::-1] #将s字符串倒序,再赋值给s
cs=0 #求和初始值
for c in s:
if c == '.': #如果等于.
break #退出循环
cs += eval(c)
print('{:*>10}'.format(cs)) #按格式输出
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2、考生文件夹下存在一个文件PY102.py, 请写代码替换横线, 不修改其他代码,实现以下功能:
time库是Python语言中与时间处理相关的标准库,time库 中ctime()函数能够将一个表示时间的浮点数变成人类 可以理解的时间格式。
例如输入
import time
print(time. ctime (1519181231))
输出结果是: Wed Feb 21 10:47:11 2018
获取用户输入的时间,提取并输出时间中“小时”的信息。例如输入1519181231,应输出10。
代码
import time
t = input("请输入一个浮点数时间信息: ")
s = time.ctime(float(t))
ls = s.split()
print(ls[3][0:2])
- 1
- 2
- 3
- 4
- 5
3、考生文件夹下存在一个文件PY103.py, 请写代码替换横线, 不修改其他代码,实现以下功能:
以26个小写字母和0~9数字为基础,以用户输入的数字为种子,随机生成10个8位密码,并将每个密码在单独一行打印输出。
代码
import random
s = input("请输入随机种子: ")
ls = []
for i in range(26): #向ls中添加26个字母
ls.append(chr(ord('a')+i))
for i in range(10): #向ls中添加10个数字
ls.append(chr(ord('0')+i))
random.seed(eval(s))
for i in range(10):
for j in range(8):
print(random.choice(ls),end='') #从ls序列中随机选择一个元素
print()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4、考生文件夹下存在一个文件PY201.py,请写代码替换横线,不修改其他代码,实现以下功能:
利用random库和turtle库,在屏幕上绘制3个黑色的正方形,正方形的左下角点坐标和正方形边长由randint函数产生,参数在代码中给出。
效果如下图所示
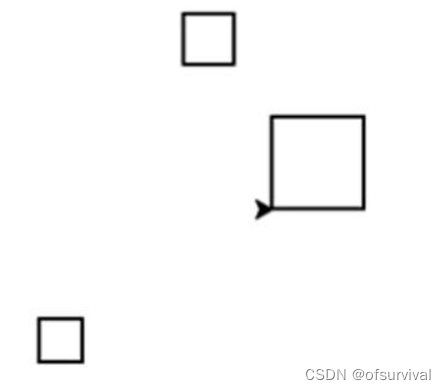
代码
import turtle as t import random as r r.seed(1) t.pensize(2) for i in range(3): length = r.randint(20,80) x0 = r.randint(-100, 100) y0 = r.randint(-100, 100) t.penup() t.goto(x0,y0) t.pendown() for j in range(4): t.forward(length) t.setheading(90*(j+1)) t.done()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5、考生文件夹下存在一个文件PY202.py,该文件是本题目的代码提示框架,其中代码可以任意修改。请在该文件中编写代码,以实现如下功能:
out.txt,其中有一些数据库操作功能的执行时间信息,如下所示:
示例
starting,0.000037,2.102
After opening tables,0.000008,0.455
System lock,0.000004,0.227
其中第1列是操作的名字,第2列是操作所花费的时间,单位是秒,第3列是操作时间占全部过程的百分比,字段之间用逗号’,'隔开。
读取out.txt文件里的内容,统计所有操作所花费的时间总和,并输出操作时间百分比最多的三个操作所占百分比的值,及其对应的操作名称,显示在屏幕上, 如下所示: .
示例
the total execute time is 0.001724
the top 0 percentage time is 46.023, spent in “Filling schema table” operation
the top 1 percentage time is 36.932, spent in “Sending data” operation
代码
sumtime = 0
percls = []
ts = {}
with open('out.txt', 'r') as f:
for i in f:
i=i.strip().split(',')
ts[i[0]]=i[2]
sumtime+=eval(i[1])
print('the total execute time is ', sumtime)
tns = list(ts.items())
tns.sort(key=lambda x: x[1], reverse=True)
for i in range(3):
print('the top {} percentage time is {}, spent in "{}" operation'.format(i, tns[i][1],tns[i][0]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
6、请按照源文件内部说明修改代码,实现以下功能:
附件中保存1个文本文件,分别对应2个问题
其中,文本文件“八十天环游地球.txt”是法国作家儒勒. 凡尔纳《八十天环游地球》长篇小说的网络版本,请修改源文件实现以下功能。
问题1:提取章节题目并输出到文件。
要求:在模板中补充代码, 提取“八十天环游地球. txt” 中所有章节的题目,并且将提取后的题目输出到“八十天环游地球-章节. txt"文件中,每行一个标题,示例如下:
第一章 斐利亚·福克和路路通建立主仆关系
第二章 路路通认为他总算找到了理想的工作
第三章 一场可能使福克先生破财的争论
第四章 斐利亚·福克把路路通吓得目瞪口呆
第五章 伦敦市场上出现了一种新的股票
问题2:统计每章节的高频词并打印输出。
要求:在模板补充代码,统计“八十天环游地球. txt”中每一章的标题和内容中,出现次数最多的词语(词语长度不少于2个字符)及其次数,输出格式为章节名、 词语及其出现的次数,以空格分隔,示例如下:
第一章 福克 26
第二章 路路通 18
第三章 福克 27
第四章 福克 28
第五章 福克 31
问题一代码
f = open("八十天环游地球.txt", encoding="utf-8") # 读取源文件
fi = open("八十天环游地球-章节.txt", "w", encoding="utf-8") # 打开新文件
for i in f: # 遍历文本
text = i.split(" ")[0] # 章节中有空格进行分割 例如:第二章 路路通认为他总算找到了理想的工作
if text[0] == "第" and text[-1] == "章": # 取出第一段文本,如果首字符是第尾字符是章,代表是章节
fi.write("{}\n".format(i.replace("\n", ""))) # 格式化保存
fi.close()
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
问题二代码
import jieba f1 = open("八十天环游地球.txt",'r',encoding="utf-8") ls = f1.read().split('□ 作者:儒勒·凡尔纳') f1.close() Ls1 = [] for i in range(len(ls)-1): d = {} lt = jieba.lcut(ls[i]) for word in lt: if 2 <= len(word): d[word] = d.get(word,0)+1 items = list(d.items()) items.sort(key = lambda x:x[1],reverse = True) Ls1.append(items[0]) f2 = open('八十天环游地球-章节.txt','r',encoding = 'utf-8') Ls0 = [] for line in f2.readlines(): Ls0.append(line.strip('\n').split(' ')[0]) for j in range(len(Ls0)): print('{} {} {}'.format(Ls0[j],Ls1[j][0],Ls1[j][1])) f2.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
真题来源:小黑课堂计算机二级python题库

