
- 1常见的SQL面试题:经典50例_sql面试必会6题经典
- 2到底哪种滤波算法好?互补滤波和卡尔曼滤波结果比较(转)
- 3我是双非-三本-专科学校的Android开发,我有机会进入大厂吗?
- 4【ChatGPT实战】9.使用ChatGPT-+-Midjourney-帮忙做了个App_chatgpt-midjourney
- 5Python自动化办公:读取Excel数据并批量生成合同
- 6《数据结构》-第六章 图(习题)_图的bfs生成树的树高比dfs生成树的树高()。
- 7头回见!redis业务数据的迁移_redis有必要做数据迁移吗?
- 8痞子衡嵌入式:恩智浦i.MX RT1xxx系列MCU启动那些事(12.A)- uSDHC eMMC启动时间(RT1170)...
- 9算法---移动小球_2022年6月28日,移动的小球。画面中有n多个自由移动的小球;点击小球,小球可以改变
- 10Nftea: 世界杯文化、 NFT与 期权的首度碰撞
数据结构-第七章(最后一部分散列表)
赞
踩
注:散列表这一节的知识不是很多,难度不是很大。
总揽
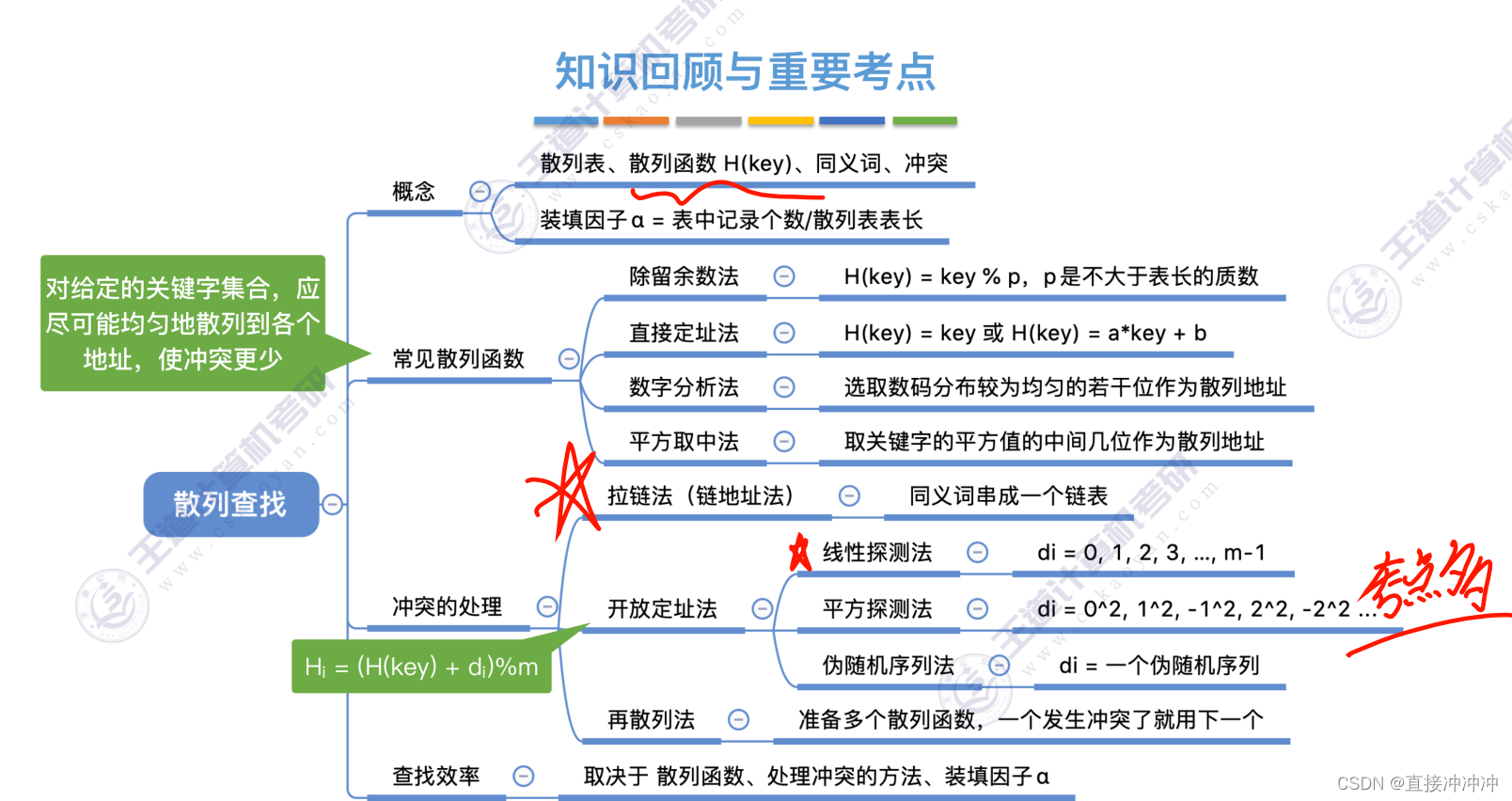
1.散列表的基本概念
从导入引出(从第一章导入需求,是比较有逻辑,使记忆也比较深刻)

散列表也叫哈希表,这两个字在下面的概念中可以互换。(名词的理解)
散列函数:一个把查找表中的关键字映射成该关键字对应的地址的函数,记为Hash(key)=Addr
(这里的地址可以是数组下标、索引或内存地址等)。
冲突:散列函数可能会把两个或两个以上的不同关键字映射到同一地址,称这种情况为冲突。
同义词:这些发生冲突的不同关键字称为同义词。
散列表:根据关键字而直接进行访问的数据结构。也就是说,散列表建立了关键字和存储地址之间的直接映射关系。
装填因子:散列表的装填因子一般记为α,定义为一个表的装满程度,即:

补充的知识点:

思维推导:
我们之前介绍的线性表和树表的查找,记录在表中的位置与记录的关键字之间不存在确定的关系,因此我们在这些表中进行查找需要进行关键字的比较。
散列查找就是利用散列表进行查找的一种方法。
散列表是怎么构成的呢?它是把关键字与表中的位置进行了关联,这种联系为散列函数。我们通过散列函数即可找到关键字的存储位置。
要直接定位存储位置自然要用数组这样的连续存储地址(或内存地址),所以用一个散列函数把许多不连续的关键字填入数组中,那就不可避免地数组中会有许多空间的浪费。好处是不用比较,时间复杂度为O(1) 。这是“空间换时间”的算法。很容易让我们想到七大基于比较的排序和基数排序、计数排序、桶排序,后三种也是“空间换时间”的算法。
不可能在任何情况下都要求O(1)的时间复杂度而使用巨大的空间,因此我们允许冲突的出现。
所以设计一个散列表,一方面构造散列函数不仅要在空间浪费适度时尽量减少这样的冲突,另一方面,这种冲突一般不可避免,我们还要设计好冲突的处理方法。
2.散列函数的构造方法
构造散列函数的要点:
- 散列函数的定义域包括全部需要存储的关键字,而值域的大小范围要在散列表的大小或地址范围之内。
- 散列函数计算出来的地址应该能等概率、均匀地分布在整个地址空间,从而减少冲突的发生。
- 散列函数应尽量简单,能够在较短的时间内计算出任一关键字对应的散列地址。
计算位置:

注:设计比较时,从目的入手。 有个例子,可以有抓手。注意以空间换时间的思维方式。
2.1直接定址法
直接取关键字的某个线性函数值为散列地址,散列函数为:
H(key)=key 或H(key)=a*key±b
式中,a 和 b 是常数。这种计算方法简单且不会发生冲突。但只适合关键字的分布基本连续的情况。

2.2除留余数法
这是一种同样简单、最常用的方法,假定散列表表长为m,取一个不大于m但最接近或等于m的质数p,散列函数为:
H(key)=key%p 或 H(key)=key MOD p (MOD是取模运算符)
模p为最接近m的质数时造成冲突的可能性最小。
图文理解

2.3数字分析法
比如学号一个班的同学前几位都是2022030XX,后两位每种数码(0,1,2...)出现的机会均等,此时应选取数码分布较为均匀的若干位作为散列地址。该方法适合于已知关键字集合,若更换了关键字(身份号),则需要重新构造新的散列函数。
图文理解

2.4平方取中法
这种方法取关键字的平方值的中间几位作为散列地址。原理是一个数的平方肯定和它的每一位都有联系,我们取中间的几位作为散列地址可以使得散列地址分布比较均匀。具体取多少位要视实际情况而定。这种方法适用于关键字每位取值都不够均匀或均小于散列地址所需位数。
图文理解

3.处理冲突的方法
注:这一节通过做题复习是最好的,因为只有自己昨天,才能模拟这个过程。
3.1开放地址法
用表示处理冲突中第 i 次探测得到的散列地址,假设得到的另一个散列地址仍然产生冲突,我们继续探测,直到不再产生冲突,则 为关键字在表中的位置。
所谓开放定址法,是指可存放新表项的空闲地址既向它的同义词表项开放,又向它的非同义词表项开放。其递推公式为:
![]() =(H(key)+
=(H(key)+![]() ) % m
) % m
式中,H(key)为散列函数;i=0,1,2...,k(k≤m-1);m表示哈希表表长; 为增量序列。
取定某一增量后,对应的处理方法就是确定的,通常有以下四种取法:
3.1.1线性探测再散列法
当![]() 序列为0,1,2,...,m-1时,又为线性探查法。
序列为0,1,2,...,m-1时,又为线性探查法。
线性探查法可能使第 i 个散列地址的同义词存入第 i +1个散列地址,这样原本该存入第 i +1个散列地址的元素就争夺第 i +2个散列地址,....从而造成大量元素在相邻的散列地址上“聚集”(或堆积)起来,大大降低了查找的效率。
3.1.2平方探测法
当序列为![]() 时,称为平方探测法,其中 k ≤m/2,散列表长度m必须是一个可以表示为4k+3的素数,又称二次探测法。
时,称为平方探测法,其中 k ≤m/2,散列表长度m必须是一个可以表示为4k+3的素数,又称二次探测法。
平方探测法是一种处理冲突的较好方法,可以有效避免出现“堆积”问题,它的缺点是不能探测到散列表上的所有单元,但至少能探测到一半单元。
3.1.3双散列法
![]() ,称为双散列法。需要使用两个散列函数,当通过第一个散列函数H(key)得到的地址发生冲突时,则利用第二个散列函数(key)计算该关键字的地址增量。
,称为双散列法。需要使用两个散列函数,当通过第一个散列函数H(key)得到的地址发生冲突时,则利用第二个散列函数(key)计算该关键字的地址增量。
![]()
在双散列法中,最多经过m-1次探测就会遍历表中所有位置,回到位置。
3.1.4伪随机序列法
当![]() =伪随机序列时,称为伪随机序列法。
=伪随机序列时,称为伪随机序列法。
在开放地址法中,不能随便物理删除表中的已有元素,因为若删除元素,则会截断其他具有相同散列地址的元素的查找地址。因此可以设置一个bool型变量对该元素进行逻辑删除。
执行多次删除后,表中空闲位置较多,要维护散列表,把标记为删除的元素物理删除。
3.2拉链法
前引思考:

为了避免非同义词发生冲突,可以把所有的同义词存储在一个线性链表中,这个线性链表由其散列地址唯一标识。
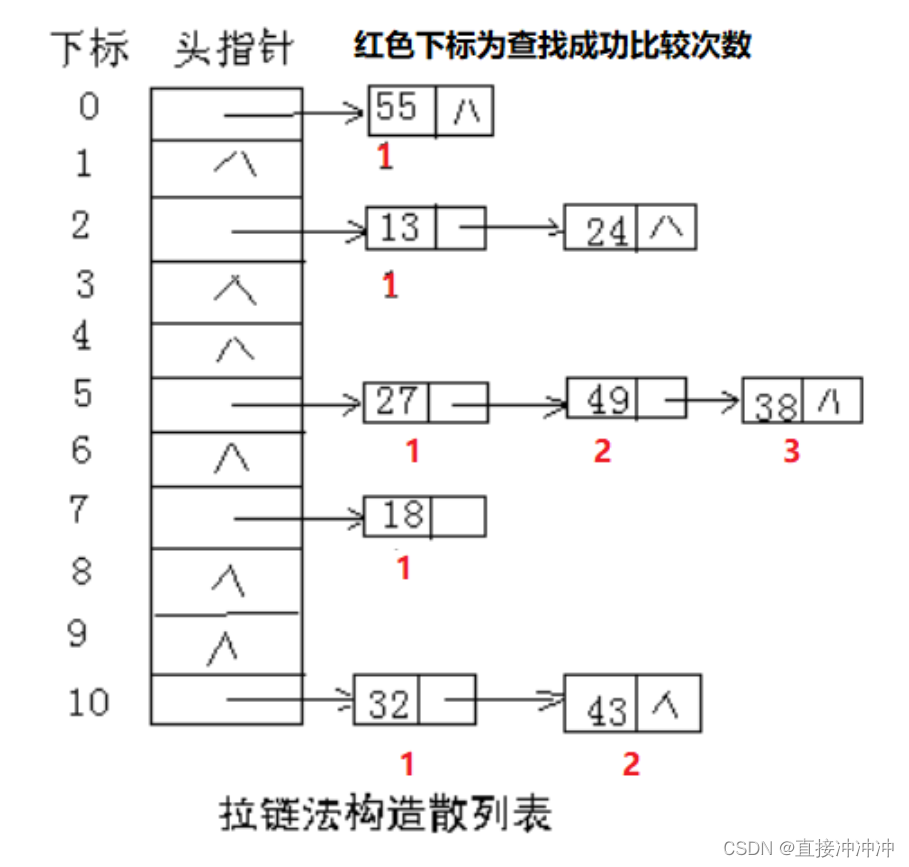
开放地址法探测数组下标空位置也算比较次数。
拉链法不同在于,找到链表指针不算比较次数。
散列表中的链地址法解决冲突时,采用的是顺序存储与链式存储相结合的方式。
4.散列查找及性能分析
- 虽然散列表在关键字与记录的存储位置之间建立了直接映像,但由于冲突的存在,使得散列表的查找过程仍然包含给定值与关键字进行比较的过程。因此,仍需要以平均查找长度作为衡量散列表查找效率的度量。
- 散列表的查找效率取决于三个因素:散列函数、处理冲突的方法和装填因子。

散列表的平均查找长度依赖于散列表的装填因子α,而不直接依赖于n或m。直观来看,α越大,表示装填的记录越“满”,发生冲突的可能性越大,反之发生冲突的可能性越小。
题目:给出散列函数,给出散列表大小边界,给出处理冲突方法。求等概率情况下平均查找长度。
解题方法:
一、画出散列表并记录其比较次数,如

二、
计算成功的ASL是根据查找元素的个数来计算。
计算失败时的ASL是根据哈希函数映射的散列地址的个数来计算。
如H(key)=key mod 7,我们有0,1,2,3,4,5,6共7个。

