
热门标签
热门文章
- 1Android Room DataBase(二)_roomdatabase
- 2两个笔记本如何将一个笔记本作为另一个笔记本的拓展屏_两台笔记本其中一台做扩展屏
- 3如何以银行客户为中心实现自动化,并创造更顺畅的客户体验?
- 4【数据结构与算法-栈、队列、堆经典例题汇总】_栈和队列的经典例题
- 5SelectIO IP 核的创建(Xilinx7)_selectio interface wizard
- 6JAVA习题练习20220430_java初学者接口,继承练习题
- 7postgresql-触发器_postgresql 触发器
- 8Qt多进程间通信方式——共享内存_void dialog::loadfromfile() { if(sharedmemory.isat
- 9eve-ng学习笔记
- 10LLM | 一文搞懂Langchain的概念,相关组件,以及大模型微调~_langchain 微调
当前位置: article > 正文
Flink程序员开发利器本地化WebUI生成_flink ui
作者:笔触狂放9 | 2024-06-30 12:54:07
赞
踩
flink ui
前言
在flink程序开发或者调试过程中,每次部署到集群上都需要不断打包部署,其实是比较麻烦的事情,其实flink一直就提供了一种比较好的方式使得开发同学不用部署就可以观察到flink执行情况。
上代码
第一步:开发之前需要引入在本机支持相关的包
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
第二步:
其实只要在生成环境的时候增加webUI部分
Configuration conf = new Configuration();
//设置WebUI绑定的本地端口
conf.setString(RestOptions.BIND_PORT,"8081");
//使用配置
StreamExecutionEnvironment env= StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
- 1
- 2
- 3
- 4
- 5
当我们跑起来的时候,我们在浏览器上面输入http://localhost:8081/ 就可以访问:
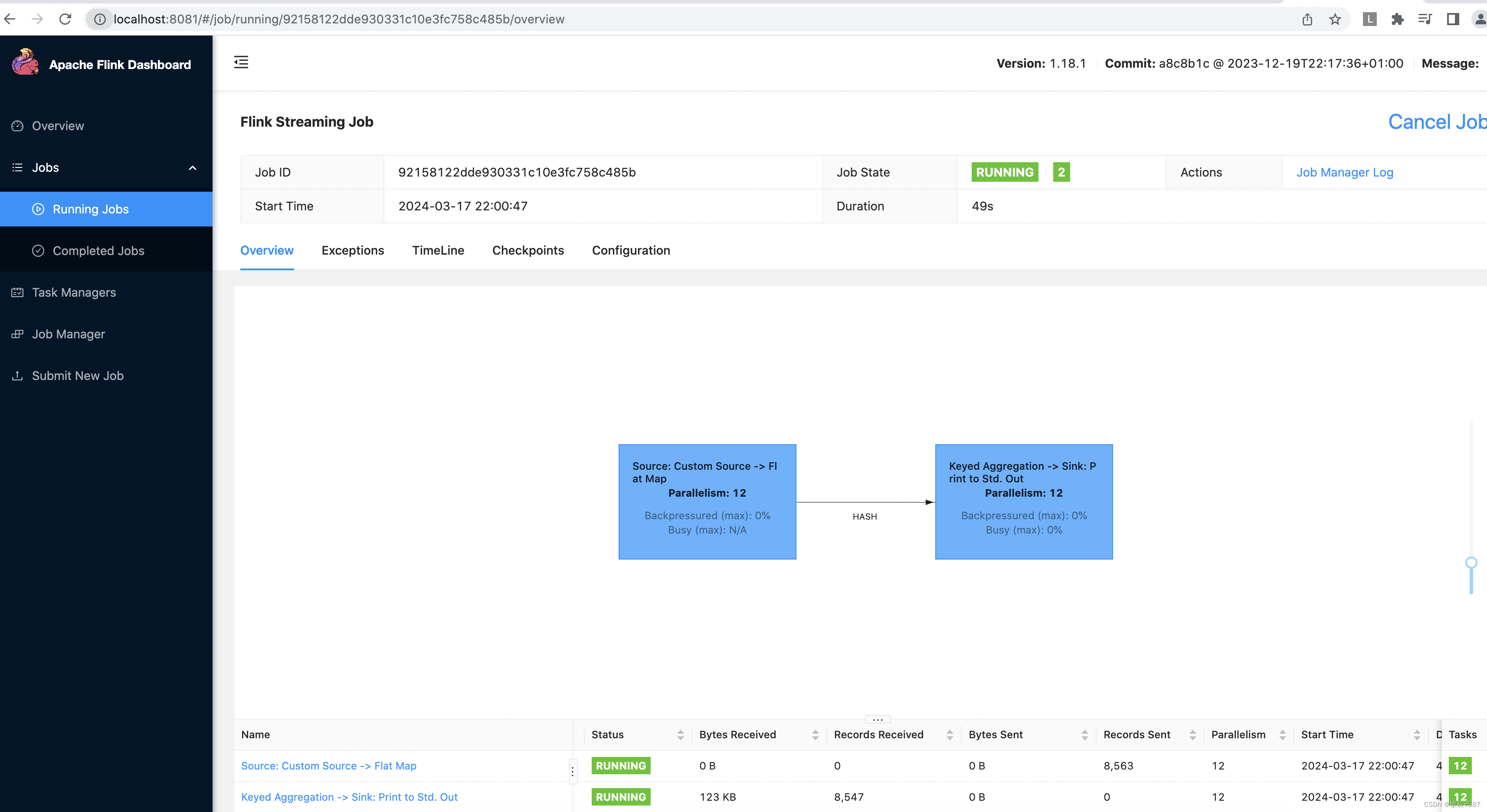
下面是我的Idea程序:
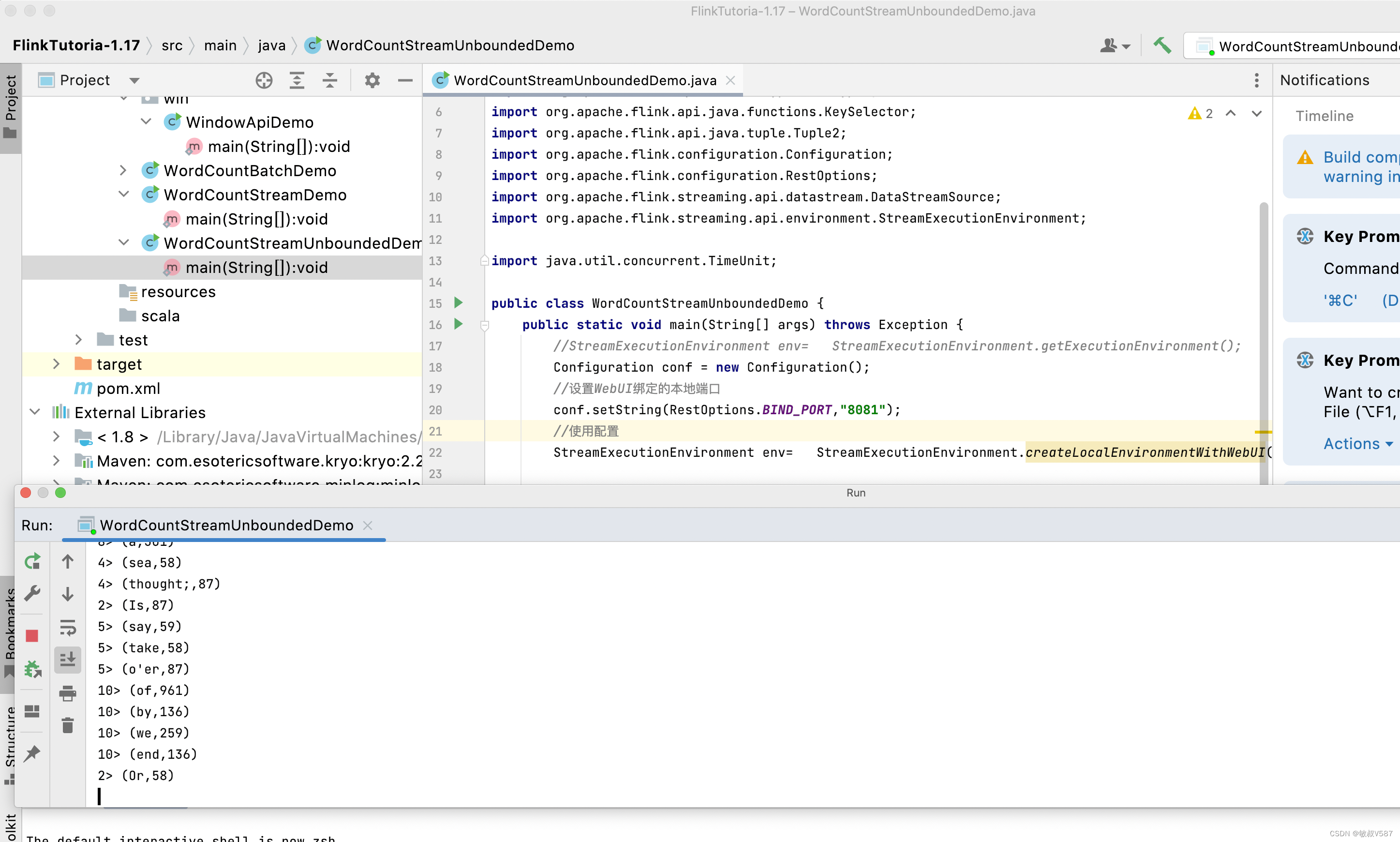
当然:很多小伙伴肯定想速度操作一下,咱讲究一个服务到位,示例代码也给出来:
public class WordCountStreamUnboundedDemo { public static void main(String[] args) throws Exception { //StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment(); Configuration conf = new Configuration(); //设置WebUI绑定的本地端口 conf.setString(RestOptions.BIND_PORT,"8081"); //使用配置 StreamExecutionEnvironment env= StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf); env.setRestartStrategy(RestartStrategies.fixedDelayRestart( 3, // 尝试重启的次数 Time.of(10, TimeUnit.SECONDS) // 间隔 )); DataStreamSource<String> inputDS = env.addSource(new ClickParallelSource()); inputDS.flatMap((FlatMapFunction<String, Tuple2<String, Integer>>) (text, collector) -> { String[] words=text.split("\\s+"); for ( String word:words){ collector.collect(Tuple2.of(word,1)); } }).returns(Types.TUPLE(Types.STRING,Types.INT)).keyBy((KeySelector<Tuple2<String,Integer>,String>) entry -> entry.f0) .sum(1).print(); env.execute(); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
后记
其实做这个事情是因为前文Docker部署Flink的关系,我注意到各个环节上侧重的事情不同,开发环境对我们理解流的一些设计思想很有用,还有各种参数并行的调试都非常有帮助,奈何没有直观可见的东西,有了开发环境的UI界面,丝滑了N个数量级了。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/772639
推荐阅读
相关标签

