
- 1机械键盘入门:教你如何正确选择机械键盘!学习&游戏两不误_黑轴用长程键还是短程键
- 2linux文件拷到光盘,制作本地yum源(以redhat5.8通过复制光盘文件到本地)
- 3纯CSS3实现柱状图的3D立体动画效果_3d酷炫柱状图css
- 4如何用java编写小游戏_java小游戏文字描述
- 5如何检查docker和docker compose是否已经安装?_怎么检查是否安装docker-compose成功
- 6【人工智能】VScode中使用ChatGPT之Bito插件_vscode中chgpt
- 7SAP Fiori Elements List Report Smart Table 列项目宽度计算的奥妙_fiori element list
- 8深度学习(19)——informer 详解(1)_informer实战
- 9[Unity][计时器][协程]协程计时器倒计时_unity协成被打断
- 10Kafka中的生产者如何处理消息发送失败的情况?_kafka消息发送失败重试机制
焕新古文化传承之路,AI为古彝文识别赋能_人类使用语言一般包括三个步骤:接受听到或读到的语言->大脑理解->输出要说的语言
赞
踩
1 古彝文与古典保护
彝文指的是云南、贵州、四川等地的彝族人使用的文字,区别于现代意义上的彝文,古彝文指的是在民间流通使用的原生态彝文,多达87046字。古彝文的起源距今至少数千年,是世界上最古老的文字之一。对古彝文字集研究有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护。

古籍是不可再生的宝贵资源,应当得到妥善保护。中国的古籍在历史上迭经水火兵燹等自然灾害、人为灾害受到破坏甚至毁灭,现在的古籍与中华民族在整个历史发展过程中形成的典籍相比已经是万不存一,所以保护古籍就显得更为重要。
目前,包括Google在内,全球已有多家技术厂商正在使用AI技术对古籍进行保护。在国内,合合信息携手上海大学,以校企联合、产研一体的形式攻关古彝文识别工作,为中华传统文化的保护与传承贡献自己的一份力!

2 古文识别的挑战
2.1 西文与汉文OCR
在印刷体的文字识别领域,开展最早,且技术上最成熟的是国外的西方文字识别技术。早在 1929 年,德国的科学家Taushek已经取得了一项光学字符识别(optical character recognition, OCR)专利。自上个世纪五十年代以来,欧美国家就开始研究关于西方各个国家的文字识别技术,以便对日常生活中产生的大量文字材料进行数字化处理。经过长时间的不断研究和完善,西文的OCR技术已经有一套完备的识别方案,并广泛地用在西文的各个领域中。
说到光学字符识别大家可能比较陌生,但或多或少都应该听说过OCR,通俗来讲,OCR技术采用电子设备(例如扫描仪或数码相机)检查纸上打印的字符,然后用字符识别方法将形状翻译成计算机文字。

国内关于印刷体文字识别技术的研究起步于上世纪七十年代末,并且主要关注于汉字的识别。通过借鉴印刷体英文识别和印刷体数字识别的方法和经验,近年我国对印刷体汉字的识别技术研究有了飞速的发展,该识别技术已经相当成熟并成功地应用在实际生活中的各个领域。但国外的研究成果主要集中在英文、法文等文字的识别,国内的研究主要集中在印刷体汉字识别上。 古彝文识别技术的研究相对起步比较晚,而且研究也比较少。尽管古彝文的识别可以借鉴其他文字识别的方法和经验,但由于彝文的特殊性,相关技术也无法完全移植到相关识别任务中
2.2 古彝文识别难点
相对于汉字识别的研究而言,古彝文识别技术难度更大,具体而言
-
版式多样
汉文与彝文古籍的各类原稿的排版风格都不统一,字符间距和行距有密有疏,彝文古籍虽然没有大小字混排、双列夹字的校注传统,但也时常出现加字、替字、整句倒置和文字方向不统一等现象,给文字定位造成挑战;
-
手写识别难
近年来,深度学习由于其卓越的学习能力成为机器学习最流行的技术,被广泛应用在人工智能方面的各个领域中,并产生了革命性的影响。其中,基于端到端(End to End)的深度学习方法可以直接从原始数据的输入到目标结果的输出,减少了因中间环节错误影响整体结果的可能性。端到端的方法在数据量越大时会显示出更好的适应性,它可以减少人工预处理和后续处理的过程,使模型尽可能地从原始输入映射到最终输出。
然而,和汉文古籍一样,不同的彝文缮写员之间手写风格差异很大,这就需要大量的数据库来建立识别模型。古彝文目前没有公开数据集,而通晓此种文字的人越来越少,导致标注工作量大而人手少,数据量严重不足,亟须引入AI技术构建模型,以弥补本项目训练样本不足;

-
图像质量差
由于彝文古籍的保存环境更为艰苦,文本呈现墨色深浅不一、字符间距和行距大小不一的情况。
-
笔画相近,异体众多
彝文字从来没有统一过,不仅异体字(两个或多个视觉上完全不同的字)很多,还存在大量的“变体字”,也即各个地方的布摩为防止敌方破译其经书而故意在现有字形上增加或减少一两个笔画产生的,如下图所示的四个字都表示“种类”的意思

3 合合信息:古彝文保护新思路
在过去的十几年中,合合信息以智能文字识别技术为核心,在图像的复杂版式识别、结构化智能理解层面做了大量的研究,并取得优秀的应用效果,为古彝文识别提供了技术支持;合合信息智能文字识别技术可对图像质量进行增强,提升文字识别效率与准确性。
3.1 图像矫正
因为相机硬件不符合理论上透视相机模型针孔无限小的假设,所以真实图像会产生明显的径向失真——场景中的线条在图像中显示为曲线。径向畸变(Radial Distortion)有两种类型:筒体畸变(Barrel Distortion)与枕形失真(Pincushion Distortion)。此外由于相机组装过程中,透镜不能和成像面严格平行,会引入切向畸变(Tangential Distortion),再加上视觉文档图像的拍摄视角一般不垂直于文档平面,产生文档图像的变形和扭曲。例如比较厚重的书籍在展开后其书脊两侧文字区会出现向内弯曲的情况。由此可见,扭曲文档的形变情况要比平面文档要复杂,对其分析和矫正的难度也比平面文档图像要高。
传统扭曲文档的校正方式是对选择的区域进行特征提取 ,以分类回归的方式得到最后的文本区域。例如:
- 基于连通域的方法。使用边缘的文本检测以及字符的检测方式来分离文本像素和非文本像素。利用图像的底层特征如色彩、亮度、灰度值、纹理、梯度等特点,将图像中具有最类似特征的像素点汇总作为文本候选区域的连通域,再对候选区域进行分类、合并进而来获取文本区域;
- 基于滑动窗口的方法。采用自顶向下检测方式,利用设计的算法来产生文本候选区域,根据阈值将划分为文本或非文本区域。这种方法的关键是采用随机森林、自适应增强等算法对复杂特征进行提取。
然而,面对古文古籍这类很复杂的文本场景时,图像受遮挡、模糊等因素的影响,加上文本在纵横比、比例、方向呈现的方式不同,传统算法的稳定性变差。
合合信息采用基于偏移场的学习方法大大改善了上述缺陷。偏移场是一种具有中间监督的堆叠U-Net网络,用于直接预测从扭曲图像到校正图像的正向映射。通过扭曲未失真的图像创建高质量的图像合成数据集,而数据驱动和学习的方法可以极大地涵盖各种真实世界条件,提高了模型泛化能力,达到商用级别。偏移场学习对网络进行端到端训练,因此没有使用手工制作的低级特征,所以在提供大规模训练数据的前提下,它可以处理各种文档类型——包括古彝文等古籍文档;且可以作为一种有效的方法部署在现实世界中应用。
3.2 图像增强
因为古籍的物理局限性,往往存在斑点、阴影等影响文字提取和识别的噪声,此时需要借助图像增强技术进行预处理。
从 2017 年开始,生成对抗网络在图像阴影去除方向的应用陆续被人提出并不断完善,以达到图像阴影去除效果进一步的提升。
GAN网络由生成器网络与判别器网络两部分共同构成。其核心思想是通过两个子网各自的最优变化,达到全局的最优效果。生成器网络的核心作用是通过一系列的网络结构生成可以骗过判别器网络的数据,判别器网络的核心作用是通过网络设计可以不被生成器网络生成的数据所骗过。生成器网络与判别器网络二者互相制约,共同成长,形成表现良好的网络结构。有时,网络内部还借助空洞卷积、注意力机制、特征融合、编码器等方法的一个或多个特性进行优化。生成器网络与判别器网络共同训练的过程如图所示
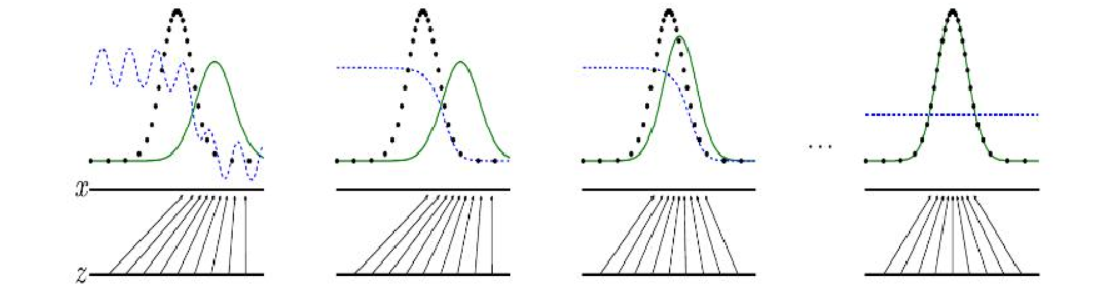
图中蓝色虚线代表判别器分布,黑色虚线代表真实数据,绿线实线代表生成器生成的数据。从左往右依次展示了生成对抗网络模型训练的过程中,生成器网络与判别器网络的变化过程。可见随着训练迭代次数的增加,生成器网络生成的数据逐渐接近数据库中原始的真实数据。直到判别器网络已经不能很好的判断出,它接收到的两种数据,哪个是生成器生成的数据,哪个是数据库中真实的数据,此时,生成对抗网络达到最佳效果,停止迭代。下面展示的是GAN网络对缺失信息、遮挡信息的修复效果。

3.3 语义理解
编解码的概念广泛应用于各个领域,在 NLP 领域,人们使用语言一般包括三个步骤:
接受听到或读到的语言 -> 大脑理解 -> 输出要说的语言。
语言是一个显式存在的东西,但大脑是如何将语言进行理解、转化、存储的,则是一个目前仍未探明的东西。因此,大脑理解语言这个过程,就是大脑将语言编码成一种可理解、可存储形式的过程,这个过程就叫做语言的编码。相应的,把大脑中想要表达的内容,使用语言表达出来,就叫做语言的解码。在语言模型中,编码器和解码器都是由一个个的Transformer组件拼接在一起形成的
具体到古彝文识别中,就是将输入的古文单词图像的多帧序列转化成一个固定长度的背景向量,完成编码工作,将生成的固定长度的向量再通过一定的方式转化为对应的输出字母序列,完成解码工作
而在这种模型中,输入的古文单词图像往往是一个包含多帧图像的序列,在进行编码解码工作时,要想从输入的一系列信息中关注到与图像对应的输出最相关的显著区域,显然是很困难的。近年来,注意力机制被广泛的应用在图像识别和NLP领域
举例:将"who are you"翻译为"你是谁",传统的模型处理方式是一个seq-to-seq的模型,其包含一个encoder端和一个decoder端,其中encoder端对"who are you"进行编码,然后将整句话的信息传递给decoder端,由decoder解码出"我是谁"。在这个过程中,decoder是逐字解码的,在每次解码的过程中,如果接收信息过多,可能会导致模型的内部混乱,从而导致错误结果的出现。而在生成"你"的时候和单词"you"关系比较大,和"who are"关系不大,所以我们更希望在这个过程中能够使用Attention机制,将更多注意力放到"you"上,而不要太多关注"who are",从而提高整体模型的表现
在古彝文识别中,合合信息就借助了注意力机制完成语义理解。
3.4 工程技巧
像这类大型深度学习项目,往往需要辅以一系列工程技巧达到良好的落地效果,其中很普遍但重要的方法是模型蒸馏。
为什么需要蒸馏?在神经网络的轻量化技术中,蒸馏作为模型压缩类别内的一种举足轻重的技术流派,它的核心思想是让一个性能强大但网络复杂体积庞大不便于移动部署的模型作为教师模型,去引导一个性能较弱但网络简单体积较小易于在移动设备上部署的学生模型,知识从教师模型提取后直接迁移到学生模型中,此期间不经过另外的模型对知识重新提取优化。直接知识蒸馏一般模型数量相对较少,计算要求简单,在实际的任务场景中有广泛的应用。
由于知识的转移不受模型结构的限制,该方法具有很强的灵活性,因此,自 2015年,Hinton等人系统总结了知识蒸馏的概念后,知识蒸馏受到了国内外研究者的广泛关注并不断被后续的研究者所改进。
合合信息借助这些工程方法,在不损失或少量损失性能的基础上,将古文识别的推断速度大大提升。
4 总结
近三年来,合合信息智能文字识别技术先后在ICDAR、ICPR等人工智能国际竞赛中斩获15项冠军,学术成果在CVPR、AAAI、ACL等顶会上发表,相关项目获中国图象图形学学会(CSIG)科技进步奖二等奖。
合合信息深耕人工智能16年,C端产品全球累计用户下载量超过23亿,享有国内外发明专利113项,为超过30个行业提供智能解决方案。合合信息提供了深受全球用户喜爱的效率工具,例如C端的名片全能王、扫描全能王、启信宝等。

合合信息在古文字识别领域已有了一定的积累和成果。在2021年、2022年的世界人工智能大会上,合合信息展现了智能文字识别技术在甲骨文、西周钟鼎文(金文)中的应用,获得了包括央视、人民日报、新华社等上百家主流媒体的关注。相信在不远的将来,合合信息会通过古彝文识别项目,为文物保护、文化传承带来更多期待。
- html>[详细] -->
赞
踩

