
- 17. Spring Boot 与MyBatis集成
- 2YOLOv8 保姆级教程(训练自己的数据集)
- 3探索文档图像大模型,提升智能文档处理性能_vdu visual document understanding
- 4【微信小程序开发】学习小程序的模块化开发(自定义组件和分包加载)_小程序底下的模块
- 5一文带你安装opencv和常用库(保姆级教程少走80%的弯路)_opencv安装教程
- 6几款强大的GPT类工具_chat gpt 国内版免费
- 7Unity实现简单太阳系_unity 太阳系模型
- 8【Linux操作系统】探秘Linux奥秘:文件系统的管理与使用
- 9从前端Vue到后端Spring Boot:接收JSON数据的正确姿势
- 100 files committed, 1 file failed to commit: On branch dev Your branch is up tIDEA无法用Git提交代码报错解决方法_17:12提交失败,错误 0 files committed, 1 file failed to c
分类问题常用算法之决策树、随机森林及python实现_决策树算法用什么软件实现
赞
踩
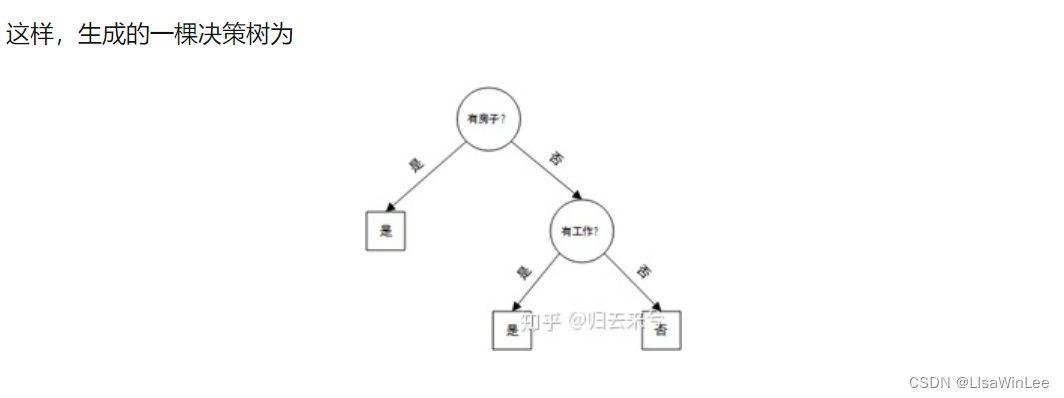
一、决策树
核心:分而治之
三步走:特征选择;决策树的生成;决策树的剪枝
主要算法:ID3(特征选择:信息增益)、C4.5(特征选择:信息增益率)和CART(特征选择:gini指数)
1. 概述
决策树的学习的过程是一个递归选择最优特征的过程,对应着对特征空间的划分。
开始,构建根节点,将所有的训练数据都放在根节点上,选择一个最优特征(特征选择),按照这一特征将训练数据集分割为子集,使得各个子集有一个在当前条件下最好的分类(损失函数优化)。
如果被分割的子集已正确分类,那么构建叶子节点。
如果还有子集不能正确分类,继续从剩下的特征中选择最优特征,继续分割数据集,构建相应的节点。
递归下去,知道所有训练数据子集被基本正确分类或者没有合适的特征为止。
最后每个子集都被分到叶子节点上,即有了明确的分类。
如上生成的决策树可能对训练数据有很好的分类能力,但是对未知的测试数据未必有很好的分类能力,即发生过拟合现象。
需要对已生成的树进行自下而上的剪枝,使模型变得简单,有更好地泛化能力。
具体的就是去掉过于细分的叶节点,使其父节点或更高的节点作为叶节点。
决策树的生成对应于模型的局部选择,决策树的剪枝对应于模型的全局选择。决策树的生成只考虑局部最优,决策树的剪枝考虑全局最优。
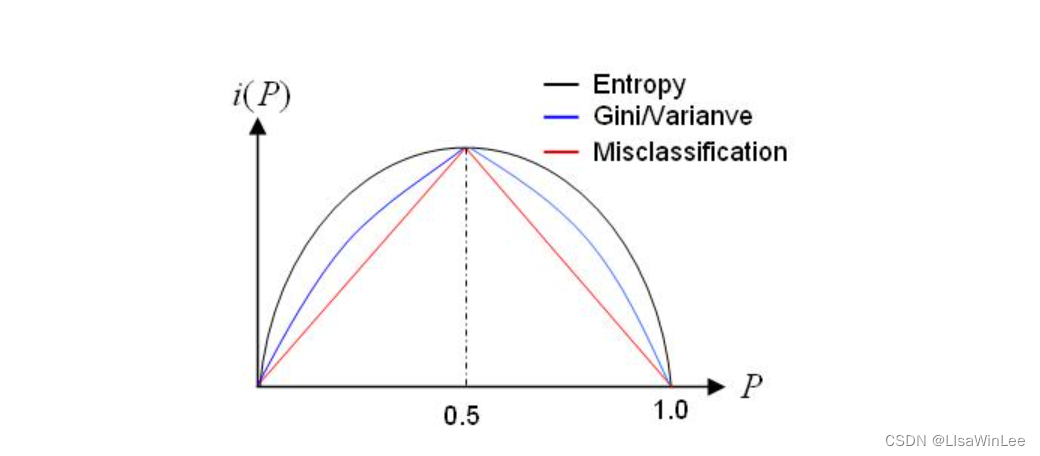
2. 特征选择
2.1. 信息增益

2.2. 信息增益率

2.3.基尼指数




# 对y的各种可能的取值出现的个数进行计数.。其他函数利用该函数来计算数据集和的混杂程度 def uniquecounts(rows): results = {} for row in rows: #计数结果在最后一列 r = row[len(row)-1] if r not in results:results[r] = 0 results[r]+=1 return results # 返回一个字典 # 熵 def entropy(rows): from math import log log2 = lambda x:log(x)/log(2) results = uniquecounts(rows) #开始计算熵的值 ent = 0.0 for r in results.keys(): p = float(results[r])/len(rows) ent = ent - p*log2(p) return ent

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
3. 决策树的生成
决策树的生成算法有很多变形,这里介绍几种经典的实现算法:ID3算法,C4.5算法和CART算法。这些算法的主要区别在于分类结点上特征选择的选取标准不同。下面详细了解一下算法的具体实现过程。
3.1. ID3算法
ID3算法的核心是在决策树的各个结点上应用信息增益准则进行特征选择。具体做法是:
-
从根节点开始,对结点计算所有可能特征的信息增益,选择信息增益最大的特征作为结点的特征,并由该特征的不同取值构建子节点;
-
对子节点递归地调用以上方法,构建决策树;
-
直到所有特征的信息增益均很小或者没有特征可选时为止。
3.2. C4.5算法
C4.5算法与ID3算法的区别主要在于它在生产决策树的过程中,使用信息增益比来进行特征选择。
3.3. CART算法
分类与回归树(classification and regression tree,CART)与C4.5算法一样,由ID3算法演化而来。CART假设决策树是一个二叉树,它通过递归地二分每个特征,将特征空间划分为有限个单元,并在这些单元上确定预测的概率分布。
CART算法中,对于回归树,采用的是平方误差最小化准则;对于分类树,采用基尼指数最小化准则。


#定义节点的属性 class decisionnode: def __init__(self,col = -1,value = None, results = None, tb = None,fb = None): self.col = col # col是待检验的判断条件所对应的列索引值 self.value = value # value对应于为了使结果为True,当前列必须匹配的值 self.results = results #保存的是针对当前分支的结果,它是一个字典 self.tb = tb ## desision node,对应于结果为true时,树上相对于当前节点的子树上的节点 self.fb = fb ## desision node,对应于结果为true时,树上相对于当前节点的子树上的节点 # 基尼不纯度 # 随机放置的数据项出现于错误分类中的概率 def giniimpurity(rows): total = len(rows) counts = uniquecounts(rows) imp =0 for k1 in counts: p1 = float(counts[k1])/total for k2 in counts: # 这个循环是否可以用(1-p1)替换? if k1 == k2: continue p2 = float(counts[k2])/total imp+=p1*p2 return imp # 改进giniimpurity def giniimpurity_2(rows): total = len(rows) counts = uniquecounts(rows) imp = 0 for k1 in counts.keys(): p1 = float(counts[k1])/total imp+= p1*(1-p1) return imp #在某一列上对数据集进行拆分。可应用于数值型或因子型变量 def divideset(rows,column,value): #定义一个函数,判断当前数据行属于第一组还是第二组 split_function = None if isinstance(value,int) or isinstance(value,float): split_function = lambda row:row[column] >= value else: split_function = lambda row:row[column]==value # 将数据集拆分成两个集合,并返回 set1 = [row for row in rows if split_function(row)] set2 = [row for row in rows if not split_function(row)] return(set1,set2) # 以递归方式构造树 def buildtree(rows,scoref = entropy): if len(rows)==0 : return decisionnode() current_score = scoref(rows) # 定义一些变量以记录最佳拆分条件 best_gain = 0.0 best_criteria = None best_sets = None column_count = len(rows[0]) - 1 for col in range(0,column_count): #在当前列中生成一个由不同值构成的序列 column_values = {} for row in rows: column_values[row[col]] = 1 # 初始化 #根据这一列中的每个值,尝试对数据集进行拆分 for value in column_values.keys(): (set1,set2) = divideset(rows,col,value) # 信息增益 p = float(len(set1))/len(rows) gain = current_score - p*scoref(set1) - (1-p)*scoref(set2) if gain>best_gain and len(set1)>0 and len(set2)>0: best_gain = gain best_criteria = (col,value) best_sets = (set1,set2) #创建子分支 if best_gain>0: trueBranch = buildtree(best_sets[0]) #递归调用 falseBranch = buildtree(best_sets[1]) return decisionnode(col = best_criteria[0],value = best_criteria[1], tb = trueBranch,fb = falseBranch) else: return decisionnode(results = uniquecounts(rows)) # 决策树的显示 def printtree(tree,indent = ''): # 是否是叶节点 if tree.results!=None: print str(tree.results) else: # 打印判断条件 print str(tree.col)+":"+str(tree.value)+"? " #打印分支 print indent+"T->", printtree(tree.tb,indent+" ") print indent+"F->", printtree(tree.fb,indent+" ") # 对新的观测数据进行分类 def classify(observation,tree): if tree.results!= None: return tree.results else: v = observation[tree.col] branch = None if isinstance(v,int) or isinstance(v,float): if v>= tree.value: branch = tree.tb else: branch = tree.fb else: if v==tree.value : branch = tree.tb else: branch = tree.fb return classify(observation,branch)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
# test my_data=[['slashdot','USA','yes',18,'None'], ['google','France','yes',23,'Premium'], ['digg','USA','yes',24,'Basic'], ['kiwitobes','France','yes',23,'Basic'], ['google','UK','no',21,'Premium'], ['(direct)','New Zealand','no',12,'None'], ['(direct)','UK','no',21,'Basic'], ['google','USA','no',24,'Premium'], ['slashdot','France','yes',19,'None'], ['digg','USA','no',18,'None'], ['google','UK','no',18,'None'], ['kiwitobes','UK','no',19,'None'], ['digg','New Zealand','yes',12,'Basic'], ['slashdot','UK','no',21,'None'], ['google','UK','yes',18,'Basic'], ['kiwitobes','France','yes',19,'Basic']] divideset(my_data,2,'yes') giniimpurity(my_data) giniimpurity_2(my_data) tree = buildtree(my_data) printtree(tree = tree) classify(['(direct)','USA','yes',5],tree)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
0:google? T-> 3:21? T-> {'Premium': 3} F-> 2:yes? T-> {'Basic': 1} F-> {'None': 1} F-> 0:slashdot? T-> {'None': 3} F-> 2:yes? T-> {'Basic': 4} F-> 3:21? T-> {'Basic': 1} F-> {'None': 3} Out[3]: {'Basic': 4}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4. 决策树的剪枝
- 预剪枝:决策树生成中,每个节点划分前进行估计,如果不能带来决策树预测泛化能力的提升,则停止划分并将当前节点标记为叶节点。训练开销和测试开销小,但是可能带来欠拟合。
- 后剪枝:先训练完一棵完整的树,自底向上对非叶节点进行考虑,如果该非叶节点替换为叶节点后带来决策树预测泛化能力的提升,则将子树替换为叶节点。训练开销大,欠拟合风险小,泛化能力强。


# 决策树的剪枝 def prune(tree,mingain): # 如果分支不是叶节点,则对其进行剪枝 if tree.tb.results == None: prune(tree.tb,mingain) if tree.fb.results == None: prune(tree.fb,mingain) # 如果两个子分支都是叶节点,判断是否能够合并 if tree.tb.results !=None and tree.fb.results !=None: #构造合并后的数据集 tb,fb = [],[] for v,c in tree.tb.results.items(): tb+=[[v]]*c for v,c in tree.fb.results.items(): fb+=[[v]]*c #检查熵的减少量 delta = entropy(tb+fb)-(entropy(tb)+entropy(fb)/2) if delta < mingain: # 合并分支 tree.tb,tree.fb = None,None tree.results = uniquecounts(tb+fb) # test tree = buildtree(my_data,scoref = giniimpurity) prune(tree,0.1) printtree(tree)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
{‘None’: 7, ‘Premium’: 3, ‘Basic’: 6}
5. Sklearn实现
from sklearn.tree import DecisionTreeClassifier
- 1
-
一个不纯度参数:criterion:{gini,entropy}
-
一个调节样本均衡参数:class_weight:{ {“标签的值 1”:权重 1,“标签的 值 2”:权重 2} ,balanced},搭配基于权重的剪枝参数min_weight_ fraction_leaf使用
-
两个随机参数:random_state(随机参数选取不同特征输入),splitter:{best:选择最优特征,random:随机选择特征}
-
五个普通剪枝参数:max_depth(最大深度), min_samples_split(最小分裂样本数) , min_samples_leaf(最小叶节点样本数) , max_feature (可使用最多特征数), min_impurity_decrease(最小信息增益)
-
一个特征重要性属性:feature_importances_
-
四个接口:fit(拟合训练集),score(准确率),apply(返回预测叶子节点索引),predict(预测样本标签),predict_proba(预测样本标签的概率)
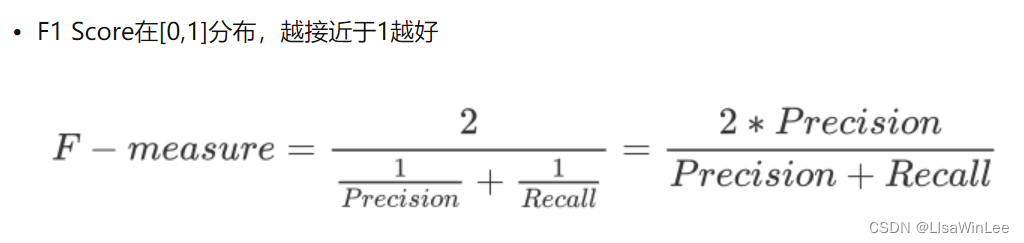
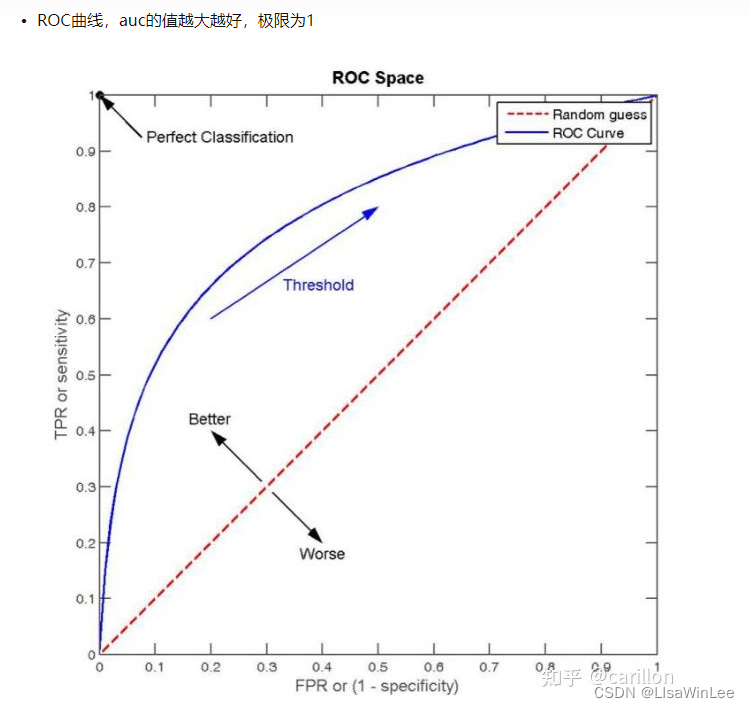
6. 评价指标
F1 Score
ROC曲线,AUC值
7. 优缺点
优点
- 易于理解和解释,甚至比线性回归更直观;
- 与人类做决策思考的思维习惯契合;
- 模型可以通过树的形式进行可视化展示;
- 可以直接处理非数值型数据,不需要进行哑变量的转化,甚至可以直接处理含缺失值的数据;
缺点
- 对于有大量数值型输入和输出的问题,决策树未必是一个好的选择;
- 特别是当数值型变量之间存在许多错综复杂的关系,如金融数据分析;
- 决定分类的因素取决于更多变量的复杂组合时;
- 模型不够稳健,某一个节点的小小变化可能导致整个树会有很大的不同。
8. 参考资料
https://zhuanlan.zhihu.com/p/410790016
https://zhuanlan.zhihu.com/p/20794583
https://zhuanlan.zhihu.com/p/42164714
二、随机森林
1. 概念理解
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。
随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。
“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想–集成思想的体现。
”随机“一词体现在每棵树的生成过程中。
1.1. 每棵树的按照如下规则生成:
1)如果训练集大小为N,对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本(这种采样方式称为bootstrap sample方法),作为该树的训练集;
从这里我们可以知道:每棵树的训练集都是不同的,而且里面包含重复的训练样本(理解这点很重要)。
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的,这样的话完全没有bagging的必要;
为什么要有放回地抽样?
我理解的是这样的:如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是"有偏的",都是绝对"片面的"(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决,这种表决应该是"求同",因此使用完全不同的训练集来训练每棵树这样对最终分类结果是没有帮助的,这样无异于是"盲人摸象"。
2)如果每个样本的特征维度为M,指定一个常数m<<M,随机地从M个特征中选取m个特征子集,每次树进行分裂时,从这m个特征中选择最优的;
3)每棵树都尽最大程度的生长,并且没有剪枝过程。
随机森林中的“随机”就是指的这里的两个随机性。两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力(比如:对缺省值不敏感)。
1.2. 随机森林分类效果(错误率)与两个因素有关:
森林中任意两棵树的相关性:相关性越大,错误率越大;
森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。
减小特征选择个数m,树的相关性和分类能力也会相应的降低;
增大m,两者也会随之增大。
所以关键问题是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
2. 袋外错误率(oob error)
构建随机森林的关键问题就是如何选择最优的m,要解决这个问题主要依据计算袋外错误率oob error(out-of-bag error)。
随机森林有一个重要的优点就是,没有必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计。
我们知道,在构建每棵树时,我们对训练集使用了不同的bootstrap sample(随机且有放回地抽取)。所以对于每棵树而言(假设对于第k棵树),大约有1/3的训练实例没有参与第k棵树的生成,它们称为第k棵树的oob样本。
而这样的采样特点就允许我们进行oob估计,它的计算方式如下:
(note:以样本为单位)
1)对每个样本,计算它作为oob样本的树对它的分类情况(约1/3的树);
2)然后以简单多数投票作为该样本的分类结果;
3)最后用误分个数占样本总数的比率作为随机森林的oob误分率。
oob误分率是随机森林泛化误差的一个无偏估计,它的结果近似于需要大量计算的k折交叉验证。
3. python实现
from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier import pandas as pd import numpy as np iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75 df['species'] = pd.Factor(iris.target, iris.target_names) df.head() train, test = df[df['is_train']==True], df[df['is_train']==False] features = df.columns[:4] clf = RandomForestClassifier(n_jobs=2) y, _ = pd.factorize(train['species']) clf.fit(train[features], y) preds = iris.target_names[clf.predict(test[features])] pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
与其他分类学习结果对比:
(关于数据部分就用自己的吧,示例中就是为了展示说明问题)
import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn.cross_validation import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.datasets import make_moons, make_circles, make_classification from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier from sklearn.naive_bayes import GaussianNB from sklearn.lda import LDA from sklearn.qda import QDA h = .02 # step size in the mesh names = ["Nearest Neighbors", "Linear SVM", "RBF SVM", "Decision Tree", "Random Forest", "AdaBoost", "Naive Bayes", "LDA", "QDA"] classifiers = [ KNeighborsClassifier(3), SVC(kernel="linear", C=0.025), SVC(gamma=2, C=1), DecisionTreeClassifier(max_depth=5), RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1), AdaBoostClassifier(), GaussianNB(), LDA(), QDA()] X, y = make_classification(n_features=2, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=1) rng = np.random.RandomState(2) X += 2 * rng.uniform(size=X.shape) linearly_separable = (X, y) datasets = [make_moons(noise=0.3, random_state=0), make_circles(noise=0.2, factor=0.5, random_state=1), linearly_separable ] figure = plt.figure(figsize=(27, 9)) i = 1 # iterate over datasets for ds in datasets: # preprocess dataset, split into training and test part X, y = ds X = StandardScaler().fit_transform(X) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.4) x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5 y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # just plot the dataset first cm = plt.cm.RdBu cm_bright = ListedColormap(['#FF0000', '#0000FF']) ax = plt.subplot(len(datasets), len(classifiers) + 1, i) # Plot the training points ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright) # and testing points ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6) ax.set_xlim(xx.min(), xx.max()) ax.set_ylim(yy.min(), yy.max()) ax.set_xticks(()) ax.set_yticks(()) i += 1 # iterate over classifiers for name, clf in zip(names, classifiers): ax = plt.subplot(len(datasets), len(classifiers) + 1, i) clf.fit(X_train, y_train) score = clf.score(X_test, y_test) # Plot the decision boundary. For that, we will assign a color to each # point in the mesh [x_min, m_max]x[y_min, y_max]. if hasattr(clf, "decision_function"): Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()]) else: Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1] # Put the result into a color plot Z = Z.reshape(xx.shape) ax.contourf(xx, yy, Z, cmap=cm, alpha=.8) # Plot also the training points ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright) # and testing points ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6) ax.set_xlim(xx.min(), xx.max()) ax.set_ylim(yy.min(), yy.max()) ax.set_xticks(()) ax.set_yticks(()) ax.set_title(name) ax.text(xx.max() - .3, yy.min() + .3, ('%.2f' % score).lstrip('0'), size=15, horizontalalignment='right') i += 1 figure.subplots_adjust(left=.02, right=.98) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
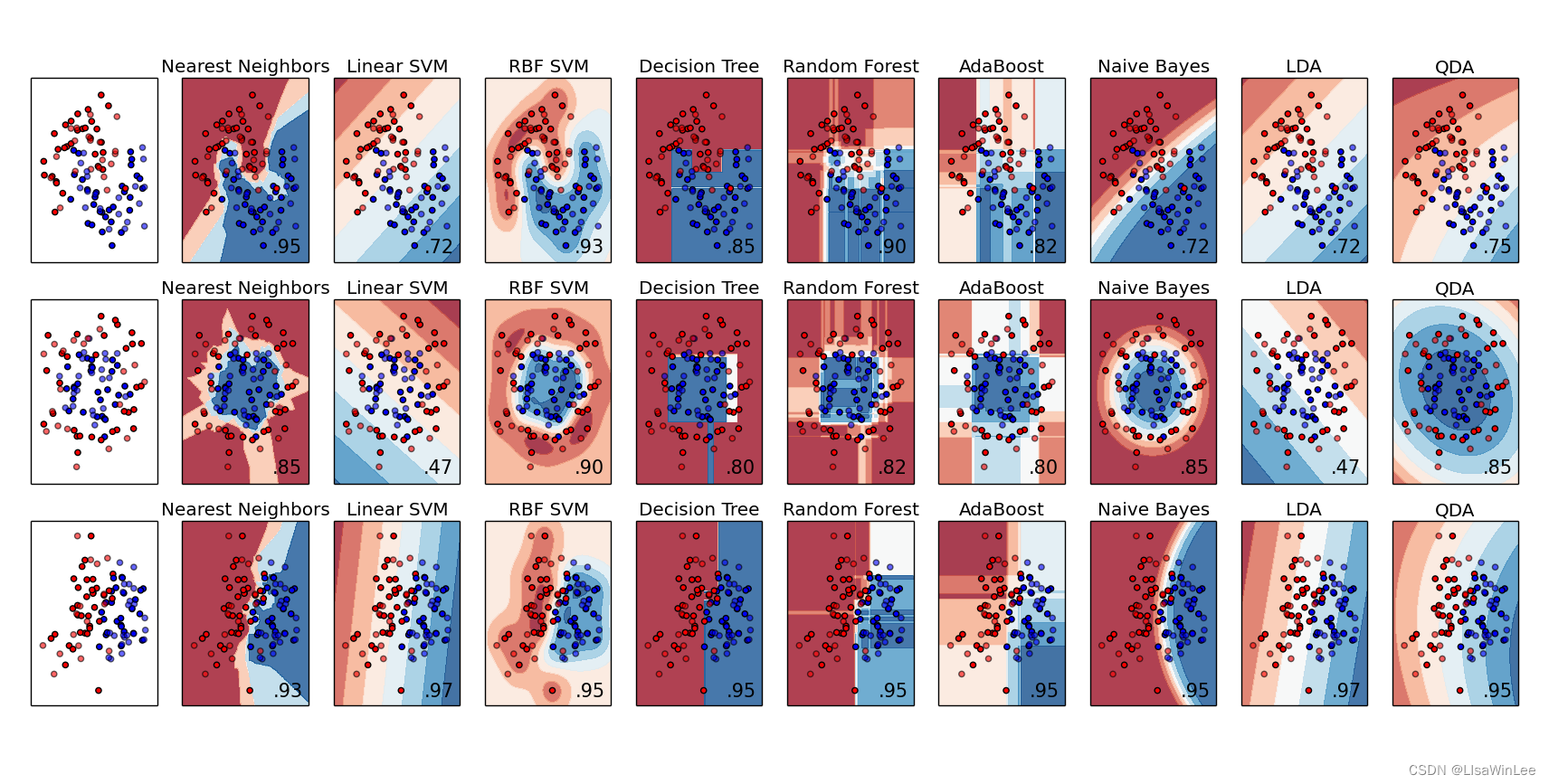
这里随机生成了三个样本集,分割面近似为月形、圆形和线形的。我们可以重点对比一下决策树和随机森林对样本空间的分割:
1)从准确率上可以看出,随机森林在这三个测试集上都要优于单棵决策树,90%>85%,82%>80%,95%=95%;
2)从特征空间上直观地可以看出,随机森林比决策树拥有更强的分割能力(非线性拟合能力)。
4. 更多有关随机森林的代码
Fortran版本
OpenCV版本
Matlab版本
R版本
5. 参考原文提炼
https://www.cnblogs.com/maybe2030/p/4585705.html#_labelTop
原文写的超级棒,推荐大家去看看!!!我提炼出来一是为了让更多人看到,二是为了在这做个学习记录,就此方便你我。
先写到这里啦~
基于决策树的算法除了随机森林外,还有bagging、GBDT等,下次再说了。

